本文主要是介绍中国新质生产力水平(原始+测算+结果)-企业和各省数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
新质生产力是一个至少涵盖科技、绿色和数字三大方面的集成体,对其评价测度需要依托多属性综合评价方法。文章构建了包含3个一级指标、6个二级指标和18个三级指标的综合体系,采用改进的熵权-TOPSIS方法对指标进行赋权,从而得到全国新质生产力发展水水平,力求揭示我国新质生产力的总量水平和结构、区域差异和现状
一、新质生产力水平-地区排名2021
| 排名 | 省份 | 新质生产力水平 |
| 1 | 广东 | 0.804 |
| 2 | 江苏 | 0.730 |
| 3 | 浙江 | 0.556 |
| 4 | 上海 | 0.507 |
| 5 | 北京 | 0.496 |
| 6 | 山东 | 0.467 |
| 7 | 河南 | 0.397 |
| 8 | 福建 | 0.397 |
| 9 | 四川 | 0.391 |
| 10 | 甘肃 | 0.391 |
| 11 | 重庆 | 0.380 |
| 12 | 安徽 | 0.377 |
| 13 | 湖北 | 0.377 |
| 14 | 湖南 | 0.372 |
| 15 | 天津 | 0.370 |
| 16 | 河北 | 0.340 |
| 17 | 江西 | 0.340 |
| 18 | 陕西 | 0.316 |
| 19 | 辽宁 | 0.315 |
| 20 | 云南 | 0.312 |
| 21 | 广西 | 0.310 |
| 22 | 贵州 | 0.308 |
| 23 | 海南 | 0.304 |
| 24 | 吉林 | 0.295 |
| 25 | 黑龙江 | 0.276 |
| 26 | 青海 | 0.273 |
| 27 | 新疆 | 0.268 |
| 28 | 山西 | 0.265 |
| 29 | 内蒙古 | 0.258 |
| 30 | 宁夏 | 0.231 |
二、新质生产力水平区域差异
全国新质生产力水平具有显著的区域性差异特征,东部地区的新质生产力领先于中西部地区。不同梯队之间的差距较大,反映了中国新质生产力的区域异质性
2021年,广东省、江苏省位居全国第一和第二,归档为第一梯队,是我国新质生产力发展的双引擎,广东省新质生产力水平达到0.8
第二梯队包括浙江省、上海市、北京市和山东省,其新质生产力水平均超过0.4
河南省、福建省、四川省、甘肃省、重庆市、安徽省、湖南省、湖北省和天津市9个省市位居第三梯队,其新质生产力水平均超过0.35
河北省、江西省、陕西省、辽宁省、云南省、广西壮族自治区、贵州省、海南省8个省市自治区位居第四梯队,其新质生产力水平均高于0.3
吉林省、黑龙江省、青海省、新疆维吾尔自治区、山西省、内蒙古自治区和宁夏回族自治区位于第五梯队
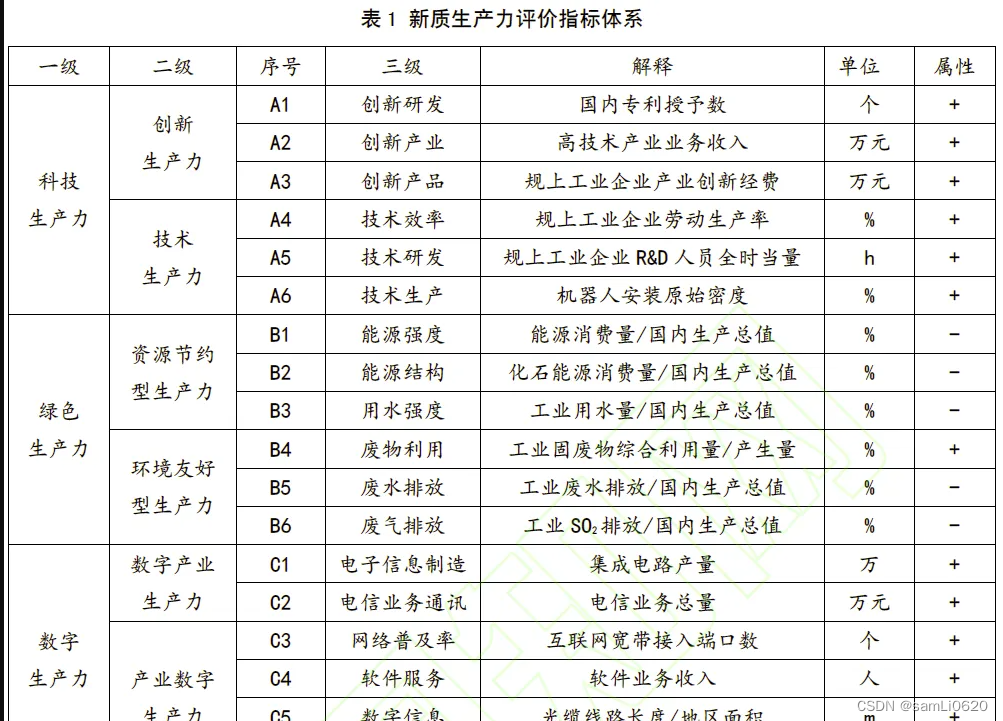
三、新质生产力评价指标体系
四、参考文献
卢江,郭子昂,王煜萍.新质生产力发展水平、区域差异与提升路径[J/OL].重庆大学学报(社会科学版),1-16[2024-03-21].
五、下载链接:
1、企业新质生产力水平-原始+测算+结果(2010-2022年):
包含内容:


下载链接(存放网盘,链接包含提取码,永久有效):https://download.csdn.net/download/samLi0620/89150259
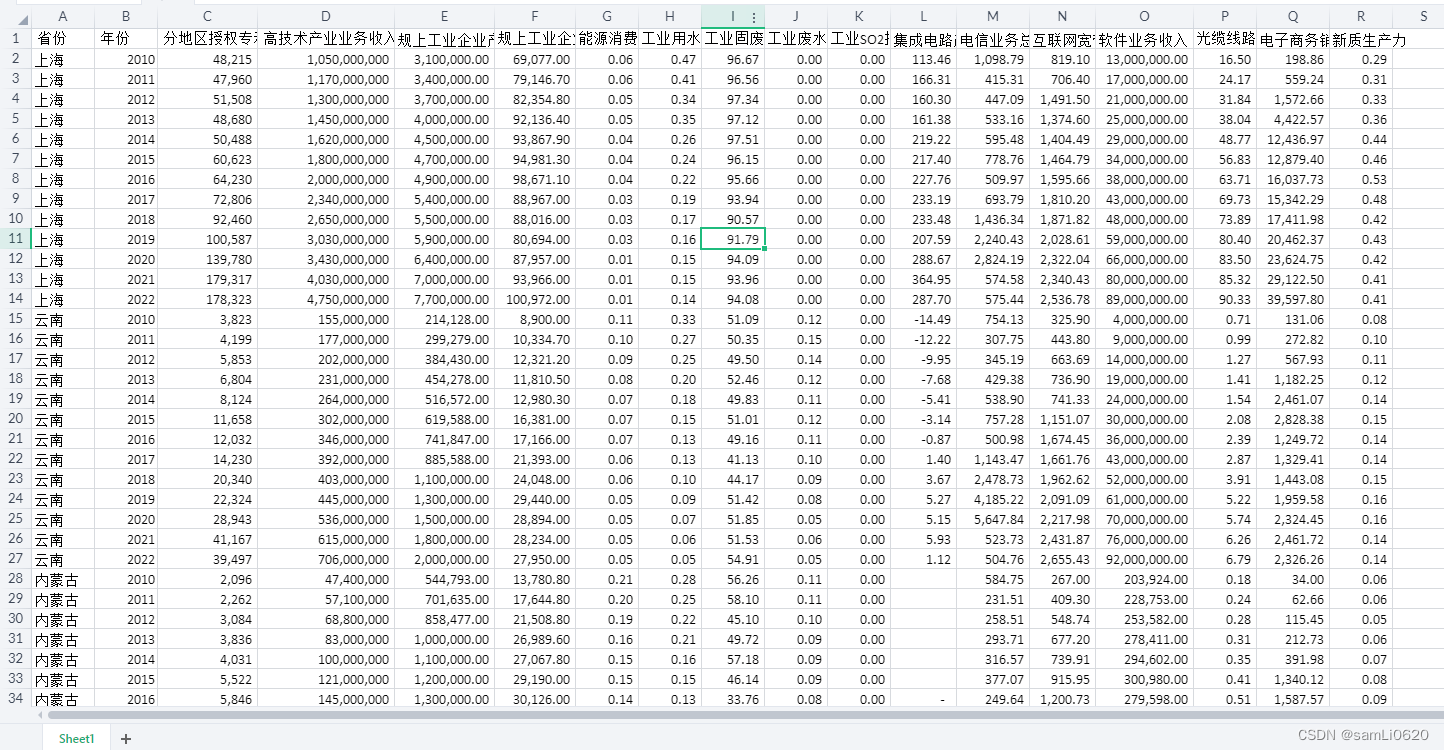
2、各省新质生产力水平-原始+测算+结果(2010-2022年)
包含内容:
下载链接(存放网盘,链接包含提取码,永久有效):https://download.csdn.net/download/samLi0620/89150260
这篇关于中国新质生产力水平(原始+测算+结果)-企业和各省数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








