本文主要是介绍Java并发——关于Java内存模型(JMM),你需要知道什么?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、JMM采用的什么内存模型?我们这个内存模型看起来是怎么样的?
并发编程中有两个主要的问题,一个是不同的线程之间怎么通信;二个是如何保证不同线程之间的同步。如果一个模型能够解决这两个问题,那么就可以用来描述并发编程模型。
在命令式编程中,线程之间通信的方式有两种,一种是通过共享内存在实现通信,称为共享式的并发模型;另一种是显式的发送消息来实现通信,称为消息传递式的并发模型。
在内存共享式的并发模型中,线程之间存在公共变量,通过公共变量的“写-读”操作进行隐式的通信;消息传递式的并发模型中,线程之间没有公共的变量,因此需要显式的发送消息来进行通信。
同步是指“程序中不同线程之间的操作发生相对顺序的机制”。在共享式并发模型中,必须要显式的制定哪些方法、代码块需要互斥执行;在消息传递式的并发模型中,因为消息的发送必须在接收之前,因此实现了隐式的同步。
JMM采用的就是共享式的并发模型。
那么JMM看起来是怎么样的呢?接下来我们看一看抽象的JMM模型。
在Java中,实例变量、静态域和数组元素都存储在堆内存中,堆内存在线程之间共享;局部变量、方法定义参数和异常处理线程参数不会在线程之间共享,因此也不会有内存可见性问题。
Java线程间的通信由JMM控制,它决定了一个线程对共享变量的写入何时对其它的线程可见,抽象的来看,JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存中,每个线程都有一个私有的本地内存,这个本地内存用来存储共享变量的副本线程一般对本地存储的共享变量进行操作,要必要的时候把本地存储的变量刷新到主内存中,或者从主内存中下载最新的共享变量值,这个时候,不同的线程之间就实现了通信。
*注意:JMM是一个抽象的概念,并不是真实存在的,本地存储也不是真实存在的一个内存区域,他涵盖了缓存,写缓冲区,寄存器等。
二、关于重排序
在执行程序时,为了提高性能,编译器和处理器会对指令进行重排序。有以下3种重排序:编译器重排序、指令集并行的重排序、内存系统的重排序,实际的指令执行的顺序都是源代码经过这3中重排序后的顺序,其中第一个属于编译器重排序,后两者属于处理器重排序。
对于编译器重排序,Java编译器会禁止特定类型的重排序;
对于指令集重排序,JMM重排序规则在生成字节码的时候,为保证内存可见性,会插入特定类型的内存屏障阻止处理器重排序。
JMM把内存屏障分为4类:
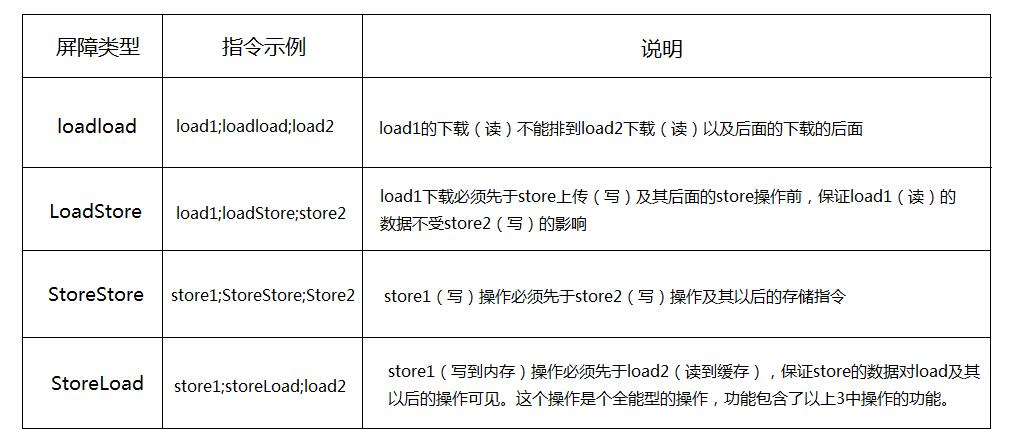
编译器和处理器在重排时会遵守“数据依赖性”,不会改变存在数据依赖的操作的执行顺序,这里的数据依赖性指在单个处理器中执行时的数据依赖性,对在多个处理器中执行的有数据依赖的操作不予考虑。
三、happenbefore规则
JMM使用happen-before概念来阐述操作之间的内存可见性,在JMM中,如果要一个操作对另一个操作可见,就必须要让这两个操作之间有happen-before关系。happen-before的规则如下:
1、程序顺序规则:在同一个线程中,线程中的每个操作happen-before于其后的每个操作;
2、监视器规则:对于一个监视器,锁的释放happen-before于该锁的下一次获取;
3、volatile变量规则:对于volatile变量,写操作happen-before于对这个变量的随后的读;
4、传递性规则:如果A happen-before B,B happen-before C, 那么A happen-before C;
*注意:A happen-before B不是说A必须要在B前面执行,只是A的操作对B可见即可,也就是说A、B操作重排序后结果不发生改变即可。
四、什么是顺序一致性?
顺序一致性模型是一个理论上的模型,在设计的时候,处理器和编译器的内存模型都会参考这个模型。
在发生数据竞争时,比如一个线程要对共享变量进行写操作,另一个线程要对该变量进行读操作,那么如果程序正确同步了,就会保证程序的执行具有“顺序一致性”,否则不具有。
顺序一致性模型可以理解为把并行的操作串行化,任意一个时刻只能有一个线程链接到主内存,并对主内存中的共享变量进行操作。
具有顺序一致性的模型看起来基础油一下特点:
虽然经过重排序以后整体上的操作看似无序,但是对于所有线程来说,看到的操作执行顺序一定是一致的。而JMM中本身是不具有顺序一致性的,也就是说,在未同步的JMM中,整体顺序看起来是无序的,每个线程看到的顺序号可能是不一样的,这样每次执行的结果都可能不一样,常常超出预期。
五、同步原语(Synchronized、volatile、final)的同步语义
volatile语义解析:
Synchronized语义解析:
final语义解析:
(未完待续。。。)
这篇关于Java并发——关于Java内存模型(JMM),你需要知道什么?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





