本文主要是介绍韩顺平 | 零基础快速学Python(16) 文件处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文件
输入与输出
输入:数据从数据源(文件)到程序(内存);
输出:数据从程序(内存)到数据源(文件)。
I/O类型
Python用于处理各种I/O类型(Input/Output 类型),主要的I/O类型分别为:文件I/O,二进制I/O,对应处理的文件对象类别:文件文本、二进制文件
文件文本:通常是记事本可以直接打开的 .py .txt;
二进制文件:图片、音频、视频等。
不同类型文件需要用对应方式打开。
文件编码
文件编码/字符编码:规定了如何将内容翻译成二进制,以及如何将二进制翻译成可识别的内容。
常见编码:UTF-8(使用最多)、GBK、BIG5、GB2312、ANSI国标码(根据系统,中文简体对应GBK)
查看编码函数:hex(ord("字符")) 16进制转为10进制
编码转换工具
常见的文件操作
open(file, mode='r', encoding=None)
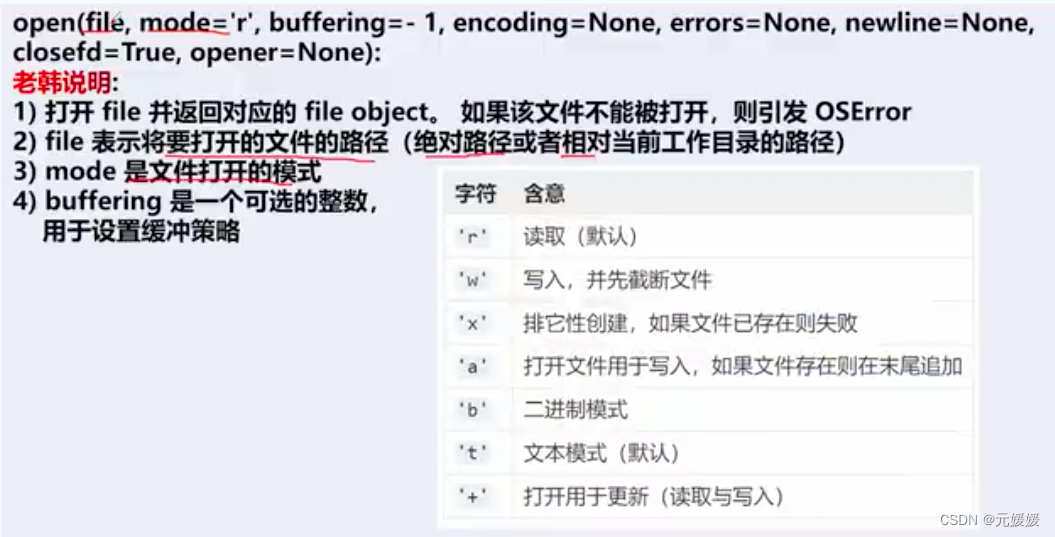



创建文件
创建文件,以mode=“w”-写入形式打开文件,如果文件不存在,系统会自动创建。encoding不能少,因为和参数位置不对应,无法按参数位置传递。
f1 = open("d://a/hi.txt:", "w", encoding="utf-8)" #前提是目录存在
print(f"文件创建成功类型是:{type(f1)}") #<class '_io.TextIOWrapper'>
读文件
读取文件:mode=“r”-读取(默认)
f = open("d://a/hi.txt:", "r", encoding="utf-8)# 读取方式1:read()content = f.read() # 一次返回整个文件的内容#content = f.read(6) #读取6个字符print(content)# 读取方式2:readline() 字符串末尾保留换行符\n
while True:line_content = f.readline # 循环读取整个文件 一行行读if line_content == "": #读取完毕breakprint(line_content, end="") #print不输出换行 # 读取方式3:readlines() 列表形式读取文件中所有行
lines = f.readlines()
for line in lines:print(line, end="")
print(lines) #["line1\n", "line2\n"...]# 读取方式4:直接遍历打开文件获取的文件对象
for line in f:print(line, end="")# 关闭文件,释放文件占用的系统资源
f.close()
写文件
创建文件,以mode=“w”-写入形式打开文件,如果文件不存在,系统会自动创建;如果文件已存在,会先截断打开的文件,也就是清空文件内容(!!!)
· mode=“a”:追加写入
f1 = open("d://a/hi.txt:", "w", encoding="utf-8)" #前提是目录存在
i = 1
while i <= 10:f.write(f"hello, world!\n"))i += 1
f.close()
删除文件
import os
if os.path.exists("d://a/abc.txt") #判断指定路径文件是否存在os.remove("d://a/abc.txt") #如果存在,删除文件
else:print("不存在")
对目录的操作
import osif os.path.isdir("d://aaa") #判断目录是否存在print("已存在")
else:os.mkdir("d://aaa") # 创建单级目录if os.path.isdir("d://bbb//ccc")print("已存在")
else:os.makedirs("d://bbb//ccc") #递归创建多级目录if os.path.isdir("d://aaa") os.rmdir("d://aaa") # 删除单级目录
else:print("不存在")if os.path.isdir("d://bbb//ccc")os.removedirs("d://bbb//ccc") #删除多级目录
else:print("不存在")获取文件的相关信息
import os
import time
#time.ctime() # 将返回的时间戳转为字符串格式
f_stat = os.stat("d:/python/hello.py") # 获取文件或文件描述符的状态,返回一个stst_result对象
print(f"文件大小->{time.ctime(f_stat.st_atime)} \n"f"最近访问时间->{time.ctime(f_stat.st_atime)} \n"f"最近修改时间->{time.ctime(f_stat.st_mtime)} \n"f"文件创建时间->{time.ctime(f_stat.st_ctime)} \n")
f.flush():刷新流的写入缓冲区到文件。
调用f.write()内容先积攒到缓存区,刷新后才真正写入文件,避免频繁操作硬盘,导致低效率
f.close:刷新并关闭流。
with open() as f:在处理文件对象时,子句体结束后,文件会自动关闭
with open("d://a//hello.txt", "r", encoding="UTF-8") as f:lines = f.readlines()for line in lines:print(line, end="")
print("\n文件是否关闭->", f.closed) #true
关于目录分隔符号:为兼容,推荐/
windows:/ //
linux/unix: /
应用实例
拷贝文件
使用原生方法 read() write()读取
1 打开源文件,读取文件的数据
2 打开目标文件,把读取的文件数据写入
3 注意:若二进制文件需以二进制方式打开
f_src_path = "C:/srcpath/pig.jpg"
f_dst_path = "d:/dstpath/pig.jpg"# 方式1
f_src = open(f_src_path, "rb") #r读取 b二进制文件 编码默认和系统保持一致
data = f_src.read()
f_dst = open(f_src_path, "wb")
f_dst.write(data)
f_src.close()
f_dst.close()#方式2 with子句方式完成文件拷贝 读一行写一行(文件大,减轻内存压力)
with open (f_src_path, "rb") as f_src:with open (f_dst_path, "wb") as f_dst:for data in f_src:f_dst.write(data)
遍历目录
判断是目录还是文件
1 获取文件夹(目录)所有内容(元素),所有文件和目录
2 判断是目录还是文件
3 化繁为简:先考虑单级目录,再考虑多级目录
3.1 如果是目录,输出信息再递归处理
3.2 如果是文件,输出对应信息即可
import os
dir_path = "d:/a"# 判断单级目录
content_list = os.listdir(dir_path) #列表形式返回目录内所有内容
print("content_list:", content_list)
for ele in content_list:child_ele = dir_path + "/" + eleif os.path.isdir(child_ele):print(f"目录:{child_ele}")else:print(f"文件:{child_ele}")# 递归遍历多级目录
def print_dir_all_content(dir_path):content_list = os.listdir(dir_path) for ele in content_list:child_ele = dir_path + "/" + eleif os.path.isdir(child_ele):print(f"目录:{child_ele}")print_dir_all_content(chile_ele) #递归操作else:print(f"文件:{child_ele}")
这篇关于韩顺平 | 零基础快速学Python(16) 文件处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




