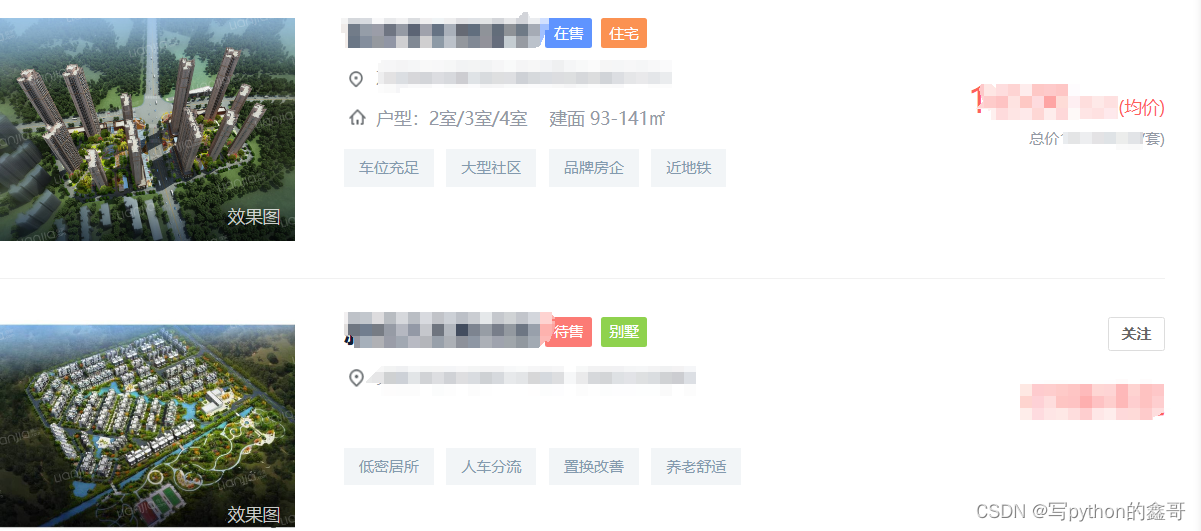
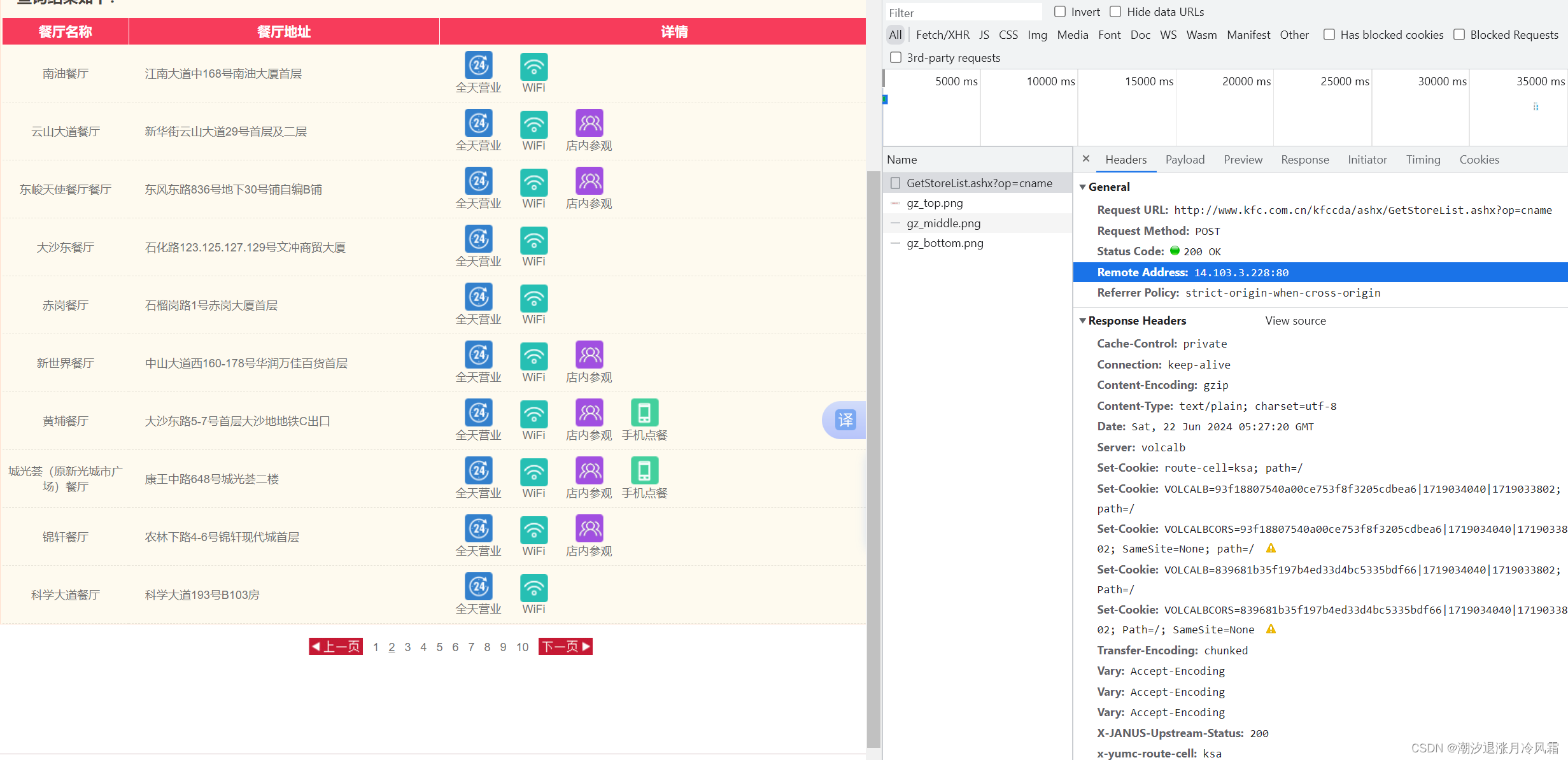
本文主要是介绍爬虫的目的是做什么,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 通过网站域名获取HTML数据
- 解析数据,获取想要的信息
- 存储爬取的信息
- 如果有必要,移动到另一个网页重复过程

这本书上的代码的网址是 : GitHub - REMitchell/python-scraping: Code samples from the book Web Scraping with Python http://shop.oreilly.com/product/0636920034391.do
如何下载代码:
1、登录上面的网站,复制网址
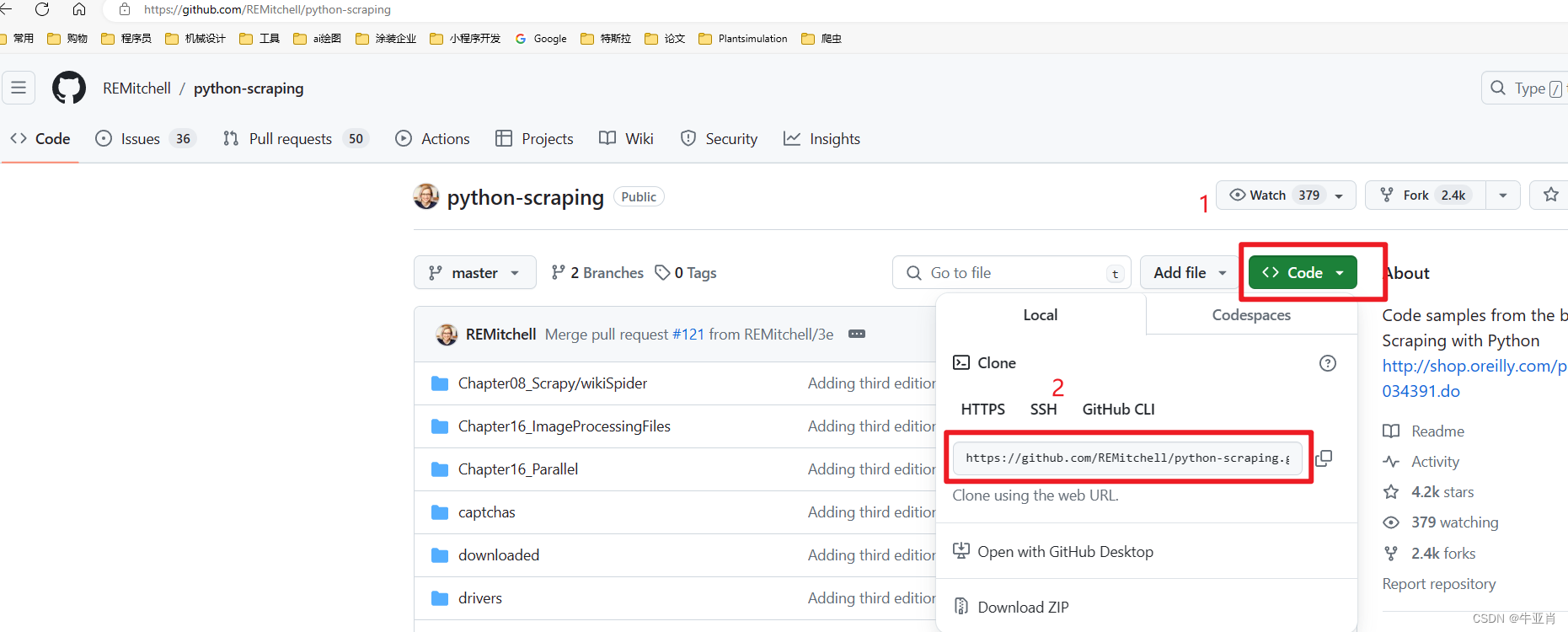
2、使用git

3、输入git clone 上面复制的网址,敲回车就可以了。
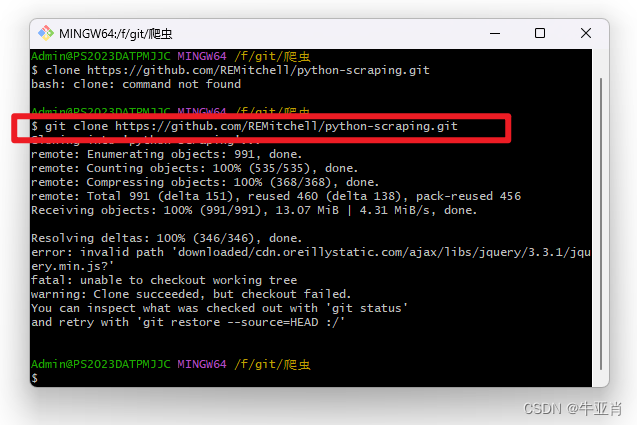
这篇关于爬虫的目的是做什么的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!