本文主要是介绍图像生成/编辑应用落地必不可少!MuLAn:首个实例级RGBA分解数据集(华为诺亚),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

文章链接:https://arxiv.org/pdf/2404.02790.pdf
数据集链接:https://MuLAn-dataset.github.io/
文本到图像生成已经取得了令人惊讶的成果,但精确的空间可控性和prompt的保真度仍然是极具挑战性的。通常通过繁琐的prompt工程、场景布局条件或图像编辑技术来解决这一限制,这些技术通常需要手绘mask。然而,现有的工作往往难以利用场景的自然实例级组合性,因为栅格化的 RGB 输出图像通常是平面的。
为了解决这一挑战,本文介绍了MuLAn:一个新颖的数据集,包含超过 44K 个RGB图像的MUlti-Layer ANnotations,作为多层、实例级别的RGBA分解,并包含超过100K个实例图像。 为了构建MuLAn,本文开发了一个无需训练的pipeline,将单目RGB图像分解为包含背景和孤立实例的RGBA层堆栈。通过使用预训练的通用模型,并开发了三个模块:图像分解用于实例发现和提取,实例补全用于重建被遮挡区域,以及图像重组。使用pipeline创建了MuLAn-COCO和MuLAn-LAION数据集,这些数据集包含各种风格、构图和复杂度的图像分解。通过MuLAn,提供了第一个提供实例分解和遮挡信息的逼真资源,为高质量图像开辟了新的文本到图像生成AI研究途径。通过这一举措,旨在鼓励开发新型的生成和编辑技术,特别是层级解决方案。
图像分解可视化展示




介绍
大规模生成diffusion model 现在能够根据文本prompt词描述生成高质量的图像。这些模型通常在包含多种风格和内容的标注RGB图像的大型数据集上进行训练。虽然这些技术已经极大地推动了文本引导图像生成领域的发展,但图像外观和构成(例如局部图像属性、可计数性)的精确可控性仍然是一个挑战。Prompt指令经常缺乏精确性或被误解(例如计数错误、空间位置错误、概念混淆、未能添加或删除实例),因此需要复杂的prompt工程来获得期望的结果。甚至稍微改变prompt都可以通过微调生成的图像而导致显著不同的样本,需要进一步的努力,才能获取高质量的所需图像。

为了解决这些限制,一些努力考虑了额外的条件,例如姿态、分割图、边缘图以及基于模型的图像编辑策略。前者改善了空间可控性,但仍需要繁琐的prompt工程来调整图像内容;而后者通常无法理解空间指令,因此难以准确修改所需的图像区域,而不影响其他区域或引入不必要的形态学变化。
本文推测一个关键障碍是典型的栅格化RGB图像通常具有平坦的特性,无法充分利用场景内容的组成性质。相反,将实例和背景隔离在单独的RGBA层上具有潜力,可以精确控制图像的组合,因为在单独的层上处理实例可以保证内容的保留。这可以简化图像操作任务,例如调整大小、移动或添加/删除元素,而这些任务对于当前的编辑方法仍然是一个挑战。
Collage Diffusion 和 Text2Layer 已经显示出多层可组合图像生成的好处的初步证据。Collage Diffusion 通过组合任意输入层来控制图像布局,例如通过采样可组合的前景和背景层,而 Text2Layer 探索将图像分解为两个单独的层(分组前景实例和背景)。尽管对无需训练的分层和复合生成越来越感兴趣,但在这个有希望的方向上进行研究开发的主要障碍是缺乏公开可用的逼真的多层数据,以训练和评估生成和编辑方法。
在这项工作中,本文旨在填补这一空白,引入了一个名为MuLAN的新型数据集,其中包含自然图像的多层RGBA分解标注(请参见下图中的RGBA分解示意图)。为了实现这一目标,本文设计了一个图像处理pipeline,它将单个RGB图像作为输入,并输出其背景和单个对象实例的多层RGBA分解。本文提出利用大规模预训练的基础模型来构建一个强大的通用pipeline,而不产生额外的模型训练成本。

本文将分解过程分为三个子模块,重点放在:
-
实例发现、排序和提取;
-
遮挡外观的实例补全;
-
将图像重新组装为RGBA堆栈。
每个子模块都经过精心设计,以确保通用适用性、高实例和背景重建质量,并确保输入图像与组合的RGBA堆栈之间的最大一致性。本文使用本文的新型pipeline处理了来自COCO 和 LAION Aesthetics 6.5 数据集的图像,为超过44,000张图像和超过100,000个实例生成了多层实例标注。生成的分解示例如下图所示:每个分解的图像包括一个背景层,提取的实例是具有透明度 alpha 层的独立RGBA图像。可以从RGBA堆栈中删除实例,产生几种中间表示形式;其中通过修补完成结果遮挡的区域。

本文发布MuLAn的目标是通过提供全面的场景分解信息和场景实例一致性,促进生成图像作为RGBA堆栈的技术的开发和训练。本文旨在促进寻求以下研究的进展:(i) 提高生成图像结构的可控性,以及 (ii) 通过精确的逐层实例编辑来改善局部图像修改质量。本文通过两个应用案例展示了本数据集的潜在效用和逐层表示的优势:1) RGBA图像生成和 2) 实例添加图像编辑。总体上,本文的主要贡献是:
-
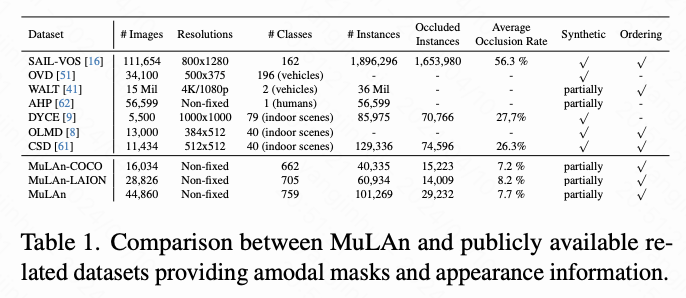
MuLAn的发布是一个新颖的多层标注数据集,包括来自COCO和LAION Aesthetics 6.5的逾44,000张图像的RGBA分解。据本文所知,MuLAn是其类别中的第一个数据集,为各种场景、风格(包括逼真的真实图像)、分辨率和目标类型提供了实例分解和遮挡信息。
-
本文提出了一种新颖的模块化pipeline,将单个RGB图像分解为实例化的RGBA堆栈,无需额外的训练成本。本文的想法以创新的方式利用了大型预训练模型,并包括排序和迭代修补策略,以实现本文的图像分解目标。这进一步使本文能够深入了解大型模型在实际应用中的行为。
-
本文通过两个应用展示了MuLAn的潜力,这两个应用以不同的方式利用了本文丰富的标注信息。
相关工作
Amodal completion 旨在自动估计部分遮挡对象的真实结构和外观。这项具有挑战性的任务已经得到了深入研究,通常建立在在合成或富有标注的数据集上训练的模型基础之上。这些数据集通常包括包含遮挡区域的实例分割mask。此外,与MuLAn最接近的数据集包括遮挡区域的外观信息和实例排序信息。本文在下表中提供了这些数据集与本文的详细比较。生成真实的遮挡标注的时间和成本要求限制了先前研究仅限于合成、小型或高度专业化的数据集,如室内场景、人类、车辆和目标以及人类等。相比之下,MuLAn包括了各种场景、风格(包括逼真的真实图像)、分辨率和目标类型的图像,并且建立在流行数据集之上,以支持生成式 AI 研究。本文强调本文使用真实图像相对于现有数据集对遮挡率的影响,其中合成场景被设计得有很高的遮挡率。
RGBA图像分解 需要在单独的透明层上识别和隔离图像实例,并估计遮挡区域的形状和外观。这项具有挑战性的任务通常需要使用额外的输入(超出单个RGB图像),例如不完全遮挡的分割、立体图像和时间视频帧。后者极大地促进了分解任务,因为视频帧可以提供缺失的遮挡信息。最近,基于层的生成建模受益于初步探索。
Text2Layer 将自然图像分解为两个层的RGBA分解。图像被分解为背景和显著的前景层,其中背景使用无prompt的最先进的diffusion model进行修补。与本文的方法相比,这种方法的主要限制在于两层分解:所有实例都提取在同一个前景层中,这严重缺乏本文所需的实例分解的灵活性。本文的目标是单独分解每个实例,这带来了额外的挑战,如实例排序、实例修补和不完全遮挡补全。与本文的分解目标相邻,PCNet 学习预测实例排序、不完全遮挡mask和对象补全。然而,该方法的适用性受限于前述的不完全遮挡完成数据集的限制。据本文所知,本文的分解流程是唯一能够分解单目RGB图像的通用技术。
与本文的工作相辅相成的是一种用于diffusion model 的图像拼贴策略——Collage Diffusion,它具有类似的实例级模块化目标。虽然本文的目标是从图像中提取实例,但他们的方法旨在将单个实例组装成一个同质的复合图像。这个先前工作的一个限制涉及到在拼贴实例的外观保持和复合图像的同质性之间取得平衡的挑战,这可以被认为是非平凡的,并且随着实例数量的增加而变得更加困难。
图像分解pipeline
本文的目标是将单个RGB图像 分解为一个实例级的 N 个RGB-A图像层的堆栈,其中A层(Alpha)描述了每个RGB实例的透明度。如前图2所示,每个层 包括一个背景图像或一个具有全透明度的单个实例在非实例区域。展开 应该得到本文原始的图像 。由于缺乏提供这种粒度信息的大型通用数据集,本文以无需训练的方式,利用了一系列专门的大规模预训练模型来实现这个目标。
本文构建了一个由三个主要模块组成的pipeline。首先,分解模块包括实例的发现和提取。它专注于场景理解,包括一系列目标检测、分割和深度估计模型。该模块将图像 分解为一个背景图像和一系列带有相关分割mask的提取实例。在这个阶段,由于遮挡,背景和提取的实例缺少信息。这个问题通过本文的第二个主模块来解决:实例补全。这第二个组件旨在单独重建每个实例,使其看起来好像没有遮挡。这一步利用深度和相对遮挡信息来建立实例顺序,并利用最先进的文本到图像生成模型来修补遮挡区域。最后,图像重新组装模块生成具有遮挡感知的Alpha层,并构建本文的RGBA堆栈,使得将堆栈展平有效地重建了图像 。
本文的流程概述如下图所示,可以在补充材料中找到进一步的详细示意图,它显示了所有组件的实例化。

图像分解模块
本文的分解模块旨在提取并隔离图像中的所有实例。本文首先使用目标检测和分割模型识别和分割实例。与此同时,本文依靠深度估计和遮挡排序模型构建相对遮挡图,并建立实例的提取、修补和重新组装顺序。
目标检测。准确地检测图像中的所有相关实例是本文的pipeline的第一步。为了实现良好的质量分解,本文必须能够检测和分离场景中的所有实例。为此,本文利用了视觉语言目标检测技术,它输入要检测的类别列表以及输入图像。这样的模型具有吸引力,因为它们可以轻松实现开放集检测,意味着本文不限于特定数据的预先存在的类别集。本文使用了detCLIPv2,这是一个具有以下特点的最先进的模型:它能够利用类别定义(而不仅仅是类别名称)来提高检测准确性。
本文精心构建了文本输入(类别列表),以确保从图像中检测和提取所有所需的类别。本文使用了来自THINGS 数据库的概念列表,并手动更新和简化它,以获得更通用的类别名称(例如,合并船型、饮料、坚果等),并删除同音词和本文不想提取的概念(例如,不可移动的目标、服装、螺栓和铰链)。本文强调,这个列表构成了pipeline的一个输入,可以轻松地定制要检测的实例。除此之外,本文还使用了WordNet 数据库的定义,以识别图像中的所有相关实例。pipeline的这一步输出了一系列带有相应类别名称的边界框。
分割。本文的下一步是精确分割检测到的实例。为了处理大量的类别、领域和图像质量,本文寻求利用一个强大的通用分割模型。其中一个这样的模型是SAM ,它已经经过了所需的多样性和规模的训练,在大量领域中取得了良好的稳健性和可转移性。利用边界框作为分割预测的基础的能力,使得这类模型成为与本文的 detCLIPv2 检测器结合的优秀选择。
深度估计。理解图像中实例的相对位置对于实现本文的RGBA分解目标至关重要。深度估计提供了关键信息,指示了拍摄时相机到目标的距离。本文使用 MiDaS 模型,选择它是因为它的稳健性:它在12个不同的数据集上进行了训练,使其在不同类型的场景和图像质量下都能可靠地工作。一旦计算完成,本文将深度图分成多个宽度为250的相对深度单元的box,以便进行跨实例的比较。
实例提取。本文将实例提取定义为将二进制mask应用到完整图像上,以将检测到的实例与图像的其余部分隔离开来。本文采用一系列策略来增强这一关键步骤的稳健性。首先,本文通过基于它们的边界框重叠来对实例进行聚类,估计一个原始顺序,并使用边界框大小和平均深度值(在分割mask内)来对它们进行排序。其次,本文使用本文的原始顺序来强制执行不相交的实例分割mask,通过将后续实例的提取区域排除在分割mask之外。最后,如果实例的最大连通分量小于20像素或占整个图像的0.1%,则不提取该实例。
深度和遮挡图。本文进一步计算深度和遮挡实例图,以实现更全面的场景理解。具体而言,本文使用了 模型,它能够联合预测实例之间的遮挡和深度关系。该模型使用原始图像和实例分割作为输入,预测实例之间的成对关系。有向遮挡图描述了实例之间的相对遮挡信息。图中的节点代表图像实例,从实例A到实例B的有向边(A → B)表示A遮挡了B。本文注意到,在两个实例相互遮挡的情况下存在有效的双向边(A ↔ B)。类似地,有向深度图也将实例表示为节点,A → B表示A比B更靠近相机,由实例的平均深度值定义。双向边(A ↔ B)表示两个实例具有相同的平均深度。
实例排序。为了最大化实例补全的质量,使用原始图像的上下文信息对遮挡区域进行修补是必要的。因此,建立精确的实例补全计划对于逐步丰富图像上下文而不遮挡相关区域至关重要。本文通过以下三个步骤生成实例排序,依赖于本文在分解步骤中获取的深度排序和遮挡信息。首先,根据它们的深度信息对实例进行排序,从最远到最近(根据实例的平均深度值)。这可以通过使用实例深度图轻松实现:通过计算节点出度,即离开节点的有向边的数量,即在本文的节点后面的实例的数量。其次,本文依靠本文的遮挡图来优化本文的排序:如果实例A遮挡实例B,则实例B将系统地在实例A之前排序。最后,相互遮挡的实例根据它们的最大深度值重新排序。实例排序算法的详细信息在原文补充材料中提供。
实例补全模块
在实例补全之前,本文已成功地从背景图像中检测、隔离和排序了所有实例。但还存在一个重要挑战:对每个图像层 (包括背景)单独重建遮挡区域,以便移除或隐藏任何图层都能显现出遮挡区域。由于本文正在分解自然图像,这些信息并不对本文可见。本文依靠最先进的生成模型,利用图像补全技术从现有上下文中想象这些遮挡区域。
基于 Diffusion model 的图像修补技术相比传统的图像修补技术已经树立了新的标准,因为它们不仅利用了图像内容,还利用了学习到的图像先验和文本条件。即便如此,本文的设置也存在着独特的困难:
-
与精心设计手工prompt的常见策略相反,本文只能依靠自动生成的描述
-
实例图像包括具有均匀颜色背景的实例,这种图像模式通常不会被这些模型所见
-
本文寻求简单、准确且高质量的补全,而不是获得美丽或创意的图像。接下来,将详细介绍本文的图像修补过程以及如何解决这些困难。
图像修补过程。本文的图像修补过程概述如下图所示。给定预定义的实例顺序,本文迭代地修补一个实例的遮挡区域,从背景图像开始,直到最近的实例。对于给定的实例,本文的图像修补过程如下进行:首先,本文利用遮挡顺序信息和遮挡实例的分割mask来估计一个修补mask。其次,本文通过将不完整的实例重新整合到中间背景图像中来构建一个上下文修补图像。这个背景图像包含了在先前迭代中处理的已修补实例。第三,利用最先进的修补生成模型和自动生成的描述作为prompt,对实例进行修补。第四,本文使用本文的分割模型和遮挡分割mask来重新提取已完成的实例,有效地获取完整的实例图像,这将成为本文多层表示的一部分。最后,本文通过将新修补的实例整合到背景修补图像中来更新下一次迭代的背景修补图像。
重要的是,本文的目标是在最大程度地保留场景上下文和防止引入无关的图像内容之间取得平衡。这对于相互遮挡的实例尤为重要:例如,考虑一个人手持手机,手是上下文,当修补手机的遮挡区域时,手指将被重建。为了防止这种情况发生,本文通过用一个常数值替换具有比下一个实例的最大深度更高的像素的信息来“隐藏”潜在的误导性上下文。

修补mask。估计一个准确的修补mask,即描述哪些图像区域将被覆盖,对于实现准确的实例补全至关重要。如果未能包含关键的遮挡区域,则有可能产生不完整的结果,而mask过大则可能改变原始图像的外观。理想情况下,通过模态完成技术来估计一个准确的完整实例形状。然而,现有方法往往针对特定的数据集或对象类别,具有有限的泛化能力。本文提出利用大型生成模型的内在偏差,提供一个大的修补mask,包括遮挡对象可能存在的区域。这通过构建一个包含所有遮挡实例的分割mask的修补mask来实现。
修补prompt保持简单,因为本文寻求一种完全自动化的分解策略。对于实例修补,本文利用自动生成的实例描述。对于背景图像的修补,本文使用一个简单的通用prompt(“一个空场景”),确保生成的修补背景尽可能简单。重要的是,在所有负面prompt中包含所有其他实例的类名,以避免重新引入已提取的实例。这增加了对不完美分割的鲁棒性。
图像重组模块
最后一个也是最简单的模块将所有单独的RGB图像重新组装成一个有序的RGBA堆栈,一旦展开,就会产生一个尽可能接近原始输入图像的图像。实例RGB图像根据本文的修补顺序进行排序,因此最后修补的实例位于堆栈的顶部,而背景位于底部。按照这个顺序,本文通过细化实例分割mask来迭代地为每个堆栈元素生成Alpha层。
本文使用图像抠图模型VitMatte 对修补后的SAM分割进行后处理,以改善Alpha混合质量,处理透明对象,并解决SAM的欠分割倾向。虽然在前两个模块中欠分割是首选的,以避免在修补时引入邻近内容和错误的先验,但是在这个最后阶段,本文需要准确的分割。VitMatte优化了SAM的输出,提供了更平滑的非二进制分割,并允许本文以更自然的方式混合修补后的实例。在存在相互遮挡的情况下(即较低级别的实例创建遮挡),本文通过将遮挡区域设置为透明来进一步调整Alpha层。这最后一个模块最终输出本文的RGBA堆栈图像分解。
描述策略
本文为所有图层(背景、实例)、中间展开的RGBA堆栈以及完整图像生成描述。本文使用LLaVa 为标准图像生成详细的描述。由于实例图像的独特性(实例在统一的白色背景上),像LLaVa这样冗长的描述模型往往会产生图像特征的幻觉。为了解决这个问题,本文利用BLIP-2模型为实例生成描述,并进行了参数搜索以选择一组限制冗长和幻觉的参数集。此外,本文使用受限束搜索来生成多个描述,并使用CLIP 选择最佳描述。使用LLaVa标注的组件也会使用BLIP进行标注,以确保完整性。
MuLAn数据集
基础数据集
本文在两个数据集上运行本文的完整方法,这些数据集提供了足够的场景组合性来充分利用本文的流程:COCO 数据集和 LAION 数据集的 Aesthetic V2 6.5 子集。Aesthetic 子集对完整的 LAION 数据集进行了筛选,仅选择了美学分数至少为 6.5 的图像,包括 625K 张图像。为了限制场景复杂性并且便于检查,本文只考虑包含一到五个实例的图像,这是通过本文的目标检测器的输出来确定的。本文处理所有的 COCO 图像(58K 张图像),以及一个随机子集的 100K 张 LAION 图像,以限制计算成本。
数据筛选
本文的目标是构建一个包含高质量分解的数据集,并排除潜在的失败模式。为此,本文手动检查和标记本文处理过的数据,确定了分解失败的六个主要原因:
-
目标检测:在图像中缺少关键实例,或者同一对象多次检测。
-
分割:原始图像上的不正确的实例分割,或修补后的分割。
-
背景修补:背景图像的错误修补。这可能是由于不完美的分割造成的,以及本文的pipeline没有考虑到场景中的因果视觉实例效果(例如阴影)。
-
实例修补:实例的不正确或不完整的修补。这通常是由于mask形状或姿态偏差(例如人手持吉他)造成的。
-
截断实例:图像抠图过度侵蚀了非常小实例的 Alpha mask。
-
无关分解:不适合实例逐个分解的场景(例如错误检测到部分景观的场景)。
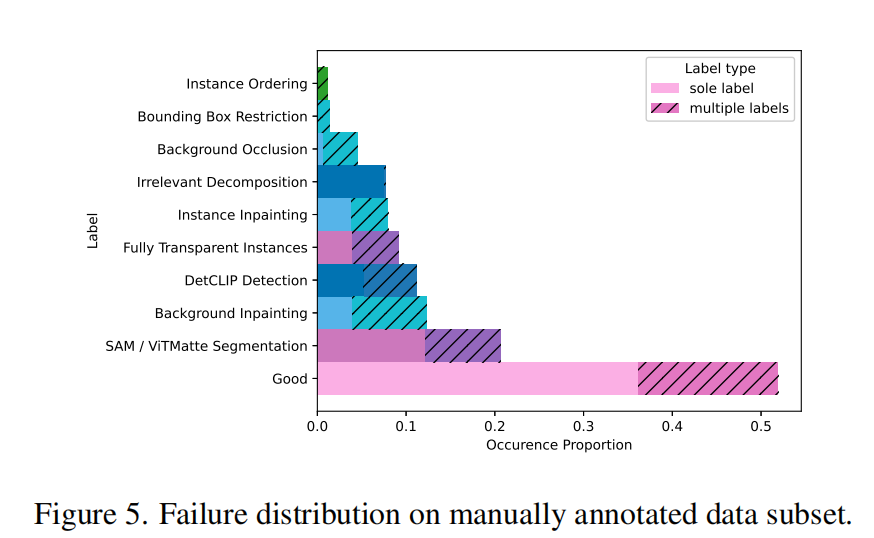
此外,为了分析目的,本文标注了一些例子,其中实例排序不正确,背景元素遮挡实例,并且实例完成受到本文边界框约束重新分割的限制。本文在补充材料中提供了失败模式的视觉示例。使用 Voxel FiftyOne ,本文从本文处理过的 LAION Aesthetic 6.5 图像中随机选择了 5000 张图像进行标注,为成功的分解添加了 “good” 标签。为了减少偏见,标注由 3 位标注者独立完成。本文强调,可以为单个图像分配多个标签,并且当缺陷较小且不影响分解的整体有效性时,特别将 “good” 标签与其他标签关联。下图中显示了手动标注集中各种失败模式的分布,突出显示总体成功率为 36%(带有轻微缺陷的为 52%)。
本文可以看到,分割问题是最大的失败模式,其次是修补和目标检测。本文的新排序失败,以及边界框限制和背景遮挡的失败是最罕见的问题。
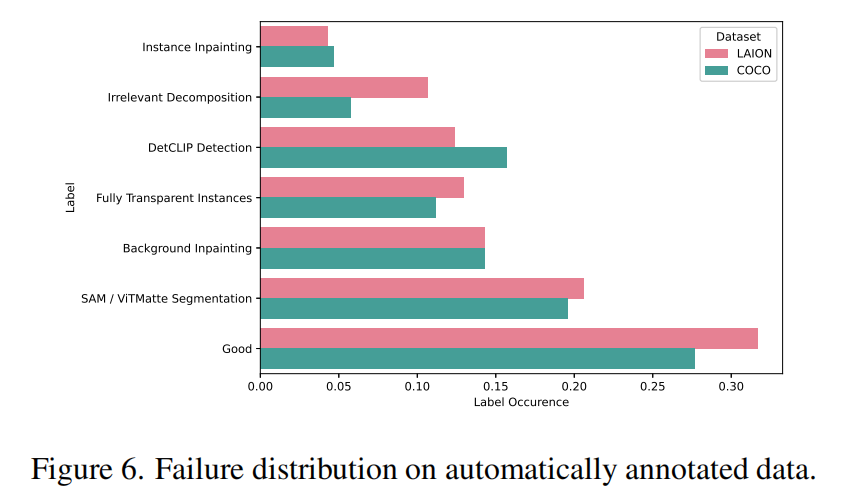
本文利用本文的手动标注来训练两个分类器,以自动标注本文处理过的其余数据:一个图像级别的分类器标记背景和无关的分解问题,一个实例级别的多标签分类器标识剩余的失败模式。有关本文分类器架构和训练过程的详细信息,请参阅原文补充材料。下图显示了 LAION 和 COCO 数据集的结果标签分布。本文采取保守的方法,只选择具有确信的 “good” 标签的图像作为成功的分解,并且仅在图6中报告此部分的 “good” 标签。这样,在 COCO 数据集中获得了 16K 个分解,而在 LAION 中获得了 28.9K 个分解,总共为本文的 MuLAn 数据集提供了 44.8K 个标注。本文的 LAION 自动失败模式分布与本文手动标注的部分非常相似,其中分割和修补始终是突出的问题。COCO 的分布类似,但目标检测错误更多。这是预期的,因为众所周知,COCO 是一个具有挑战性的目标检测基准(具有 COCO 和 LVIS 标注),场景复杂。相比之下,LAION 包含了较简单的场景,实例较少。
数据集分析
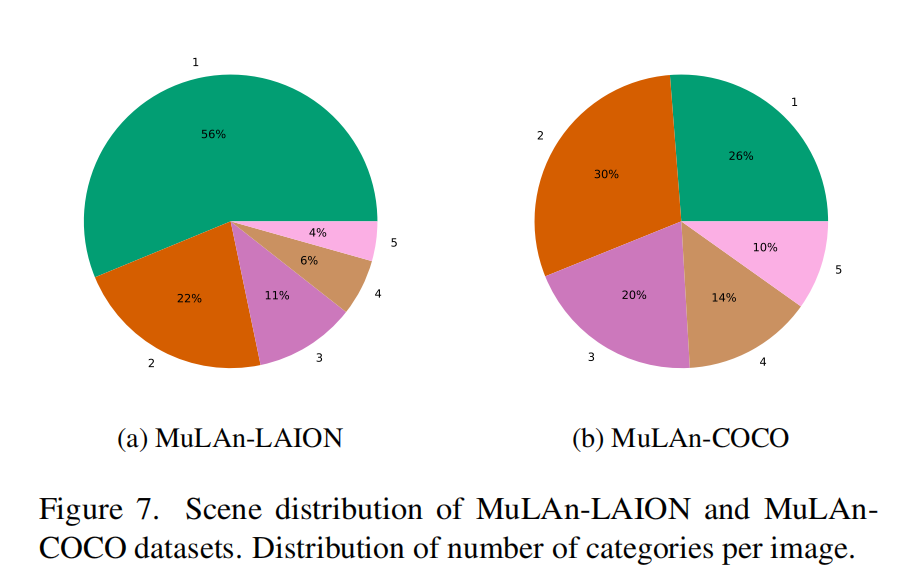
通过本文精心策划的高质量标注,本文进一步分析了本文 44.8K 个已标注图像的场景分布和多样性。下图显示了 MuLAn 中场景的分布情况,以每个图像中的实例数量为单位。本文可以看到,LAION 数据集中大多数图像都是单个实例图像,这可能与高度美学化的图像往往是简单场景有关(例如肖像 - 这也在原文补充图 S2 中有所突出)。尽管如此,MuLAn-LAION 包含足够复杂的场景,其中 21%(约 6K)的图像每个图像都有三个以上的实例。MuLAn-COCO 实现了良好的场景多样性,其中 10% 的数据集包含五个实例,几乎一半的数据集(44% ≃ 7K)包含三个以上的实例,而仅有 28%(≃ 4.5K)的单实例图像。
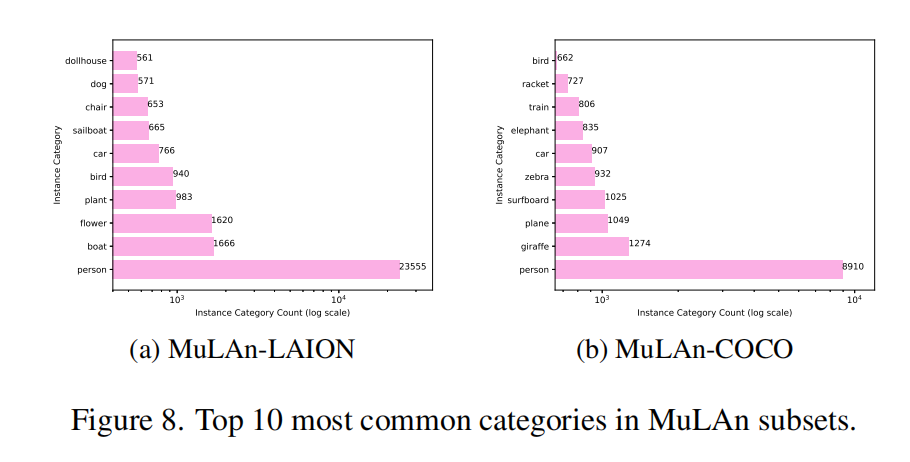
接下来,本文将从实例类型的角度调查场景的多样性。在 942 个检测类别中,本文分别在 MuLAn-COCO 和 MuLAn-LAION 中获得了 662 和 705 个类别,总共在 MuLAn 中有 759 个类别。下图展示了每个数据集中前十个最常见的类别。虽然人类别在两者中都是占主导地位的类别,但在 LAION 中占绝大多数。除了人类别外,MuLAn-LAION 主要包括无生命和装饰目标,而 COCO 包括更活跃的场景,尤其是动物和体育运动。在前十个类别中,只有三个类别同时出现在两个数据集中(人、汽车和鸟类)。这些结果突显了两个数据集子集的互补性,MuLAn-LAION 专注于更简单、高质量和视觉上令人愉悦的场景,而 MuLAn-COCO 展示了更多样化的场景类型。每个子数据集的完整、排序的类别列表详见补充材料。
最后,图12 展示了来自 MuLAn 的 RGBA 分解的其他视觉示例,展示了各种场景组成、风格和类别类型。额外的示例可在补充材料中找到。

数据集应用
为了展示本文的 MuLAn 数据集的潜在用途,本文提供了两个实验,展示了不同的示例场景,可以在这些场景下利用本文的数据集。
RGBA 图像生成。本文的第一个应用利用 MuLAn 实例,通过微调 Stable Diffusion (SD) v1.5 模型的 VAE 和 Unet,使其能够生成具有透明通道的图像。在下图中,本文提供了使用附加了“在黑色背景上”的prompt,并在本文的数据集上进行微调的 SD v1.5 生成的图像的视觉比较,与一个在多个抠图数据集中微调了 15,791 个实例的模型进行比较。本文可以看到,本文的数据集能够生成质量更好的 RGBA 实例,因为它对透明通道的理解更好。

实例添加。本文的第二个应用考虑了一项图像编辑任务,其目标是向图像中添加实例。本文微调了InstructPix2Pix 模型,利用本文能够无缝地向本文的 RGBA 堆栈中添加或移除实例的能力。本文为InstructPix2Pix 的训练数据包括三元组,其中是第 i + 1 层的实例描述,是通过将不完整的 RGBA 堆栈展平到第 层得到的 RGB 图像。为了评估性能,本文使用 EditVal 的实例添加评估策略。本文引入的基准测试上报告结果(该测试在没有属性的情况下添加对象),并构建了一个额外的属性驱动的评估基准。有关评估指标和本文基准测试的详细信息,请参阅原文补充材料。下图1强调了本文的模型在整个光谱中具有更好且更一致的性能,特别是在场景保护方面。这在下图2中进一步得到了证明,可以清楚地看到本文的模型具有更低的属性渗漏和更好的背景保留。这可以归因于本文的训练设置保证了背景的保留,而 InstructPix2Pix 使用 Prompt-to-prompt 编辑结果。


结论
本文介绍了 MuLAn,这是一个包含超过 44,000 个 RGB 图像的多层标注的新型数据集,旨在用于生成式人工智能开发。本文通过使用一种新颖的pipeline处理 LAION Aesthetic 6.5 和 COCO 数据集中的图像来构建 MuLAn,这种pipeline能够将 RGB 图像分解为多层 RGBA 堆栈。MuLAn 提供了各种场景类型、图像风格、分辨率和对象类别。通过发布 MuLAn,旨在为构图性文本到图像生成研究开辟新的可能性。构建 MuLAn 的关键在于本文的图像分解pipeline。详细分析了pipeline的失败模式,尤其是分割、检测和修补。未来的工作将探索改进性能并增加 MuLAn 大小的解决方案。本文可以利用pipeline的模块化特性来引入性能更好的模型,例如分割器或修补器。此外,该pipeline可以作为一个独立的解决方案来分解图像,并利用常见软件来进行编辑。为了支持这一点,本文还研究了人机循环扩展。
参考文献
[1]MULAN: A Multi Layer Annotated Dataset for Controllable Text-to-Image Generation
更多精彩内容,请关注公众号:AI生成未来

欢迎加群交流AIGC技术,添加小助手

这篇关于图像生成/编辑应用落地必不可少!MuLAn:首个实例级RGBA分解数据集(华为诺亚)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







