本文主要是介绍AI根据视频画面自动配音 ,真假难辨 !(附数据集),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

本文经AI新媒体量子位(公众号ID:qbitai)授权转载,转载请联系出处
本文长度为3216字,建议阅读7分钟
本文为你分享实现AI自动为视频配音的流程。
先来做个“真假美猴王”的游戏。
你将看到两段画面相同的视频,请判断哪段来自视频原声,哪段是AI根据视频画面配上的假声?
class="video_iframe" data-vidtype="2" allowfullscreen="" frameborder="0" data-ratio="1.3529411764705883" data-w="368" scrolling="no" data-src="http://v.qq.com/iframe/player.html?vid=f13294bd2je&width=670&height=502.5&auto=0" style="display: block; width: 670px !important; height: 502.5px !important;" width="670" height="502.5" data-vh="502.5" data-vw="670" src="http://v.qq.com/iframe/player.html?vid=f13294bd2je&width=670&height=502.5&auto=0"/>
class="video_iframe" data-vidtype="2" allowfullscreen="" frameborder="0" data-ratio="1.3529411764705883" data-w="368" scrolling="no" data-src="http://v.qq.com/iframe/player.html?vid=h1329cc2z8v&width=670&height=502.5&auto=0" style="display: block; width: 670px !important; height: 502.5px !important;" width="670" height="502.5" data-vh="502.5" data-vw="670" src="http://v.qq.com/iframe/player.html?vid=h1329cc2z8v&width=670&height=502.5&auto=0"/>
莫非两个都是真的?不可能,答案文末揭晓。(还有更多真假难辨的视频原声和配音大对比)
真假难辨,简直让人怀疑耳朵。模型合成的假音效,什么时候都这么逼真了?一切还得从这个自动为自然环境下的视频配音的项目说起。

视听关联
看闪电,知雷声。
对人类来说,声音和视觉通常会打包出现传递信息。就像一个孩子看到闪电会下意识捂住耳朵,看到沸腾的水会想起水汽呼呼的声音。
在论文(Visual to Sound: Generating Natural Sound for Videos in the Wild)中,北卡罗来纳大学的博士生Yipin Zhou,其导师Tamara L. Berg联合Adobe公司的Zhaowen Wang、Chen Fang和Trung Bui三人,想做出一个计算模型来学习视觉和声音间的关系,减少繁琐的音频编辑流程。

论文一作Yipin Zhou
要做出这样一个模型,那第一步肯定是找出一个合适的数据集来训练。
这个数据集可没有那么好找。
加工数据集
研究人员掐指一算,觉得AudioSet不错。

这是今年3月谷歌开放的一个大规模的音频数据集,包含了632个类别的音频及2084320条人工标记的音频,每段音频长度均为10秒。人与动物、乐器与音乐流派、日常环境的声音均覆盖在数据集内。
数据集代码地址:
https://github.com/audioset/ontology
但由于AudioSet中很多的音频与视频的关联松散,目标声音可能被音乐等其他声音覆盖,这些噪音会干扰模型学习正确的声音和图像间的映射(mapping),因此也不是很理想。研究人员先清理了数据的一个子集,让它们适应生成任务。
研究人员从AudioSet中选择10个类别进行进一步的清理,分别为婴儿啼哭、人打鼾、狗、流水、烟火、铁路运输、打印机、打鼓、直升机和电锯。每个类别中包含1500-3000个随机抽取的视频。

其中4个类别的视频帧及相应波形。图像边界颜色与波形上的标记标记一致,表示整个视频中当前帧的位置
之后,研究人员用亚马逊众包平台Mechanical Turk(AMT)清理数据。值得一提的是,李飞飞在建立ImageNet数据集时,也是借助这个可以把任务分发给全世界坐在电脑前的人的平台做起来的。
在这个任务中,研究人员借助AMT上兼职的力量验证在图像和音频形态下,视频片段中关注的物体或动作是否存在。如果在视听两种环境下都存在,则认为它是一个噪音较少的可用视频。为了尽可能保留更多数据,研究人员将每段视频分割成两秒钟的短视频,分别标注标签。
这样一来,图像和音频模式上共标注了132209个片段,每个都被3个兼职做了标记,并从原始数据中删除了34392个片段。研究人员在合并相邻的短片段后,总共得到了28109个筛选后的视频。这些视频平均长度为7秒,总长度为55小时。
下图左表显示了视频数量和每个类别的平均长度,而饼图展示了长度的分布。由图中可见大多数视频的长度超过8秒。
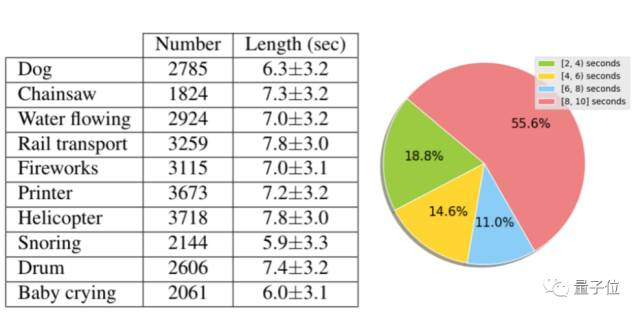
左:每个类别视频数量及平均长度/右:视频长度的分布
研究人员将这个数据集命名为VEGAS(Visually Engaged and Grounded AudioSet ) 。
准备模型
数据集搞定后,研究人员开始了模型研究。
研究人员将任务当成一个条件生成问题,通过训练条件生成模型从一个输入视频合成原始波形样本。条件概率如下:
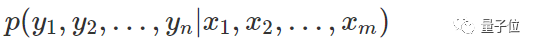
在这个概率中,x1,……,Xm为输入视频帧的表示,y1,……,yn为输出的波形值,是0到255之间的整数序列。值得注意的是,m通常远远小于n,因为音频的采样率远高于视频的采样率,因此音频波形序列比同步视频的视频帧序列长得多。
大体来说,这个模型由两部分构成,即声音生成器和视频编码器。
声音生成器
研究人员想直接用生成模型合成波形样本。为了得到音效说得过去的音频,他们选用了16kHz的音频采样频率。这就导致序列相当长,给生成器出了个难题。最后,研究人员选择了Yoshua Bengio团队在去年发表的论文《SampleRNN: An Unconditional End-to-End Neural Audio Generation Model》中提出的SampleRNN来合成声音。
论文地址:
https://arxiv.org/abs/1612.07837
SampleRNN是一种递归神经网络,它由粗到细的结构使模型产生极长的序列,而且每一层的周期性结构都能捕捉到关联不紧密的样本间的依赖关系。
SampleRNN已经应用于语音合成和音乐生成任务。在这个项目中,研究人员用它来为自然条件下的视频生成声音。这意味着变化更大、结构模式更少和比语音或音乐数据更多的噪音。
确实是个挑战。
SampleRNN模型的简化结构如下图所示。

声音生成器的简化架构
图中将示例结构简化到2层,但在实际操作中可能包含更多层次。该模型由多个层、细层(底层)是一个多层感知器(MLP),它从下一个粗层(上层)和前一个k样本中输出,生成一个新样本。
3种编码视觉信息和系统的变体
之后,研究人员提出了三种类型的编码器-解码器结构,这些信息可以与声音生成网络相结合,形成一个完整的框架。这三种变体分别为帧到帧法(Frame-to-frame method)、序列到序列法(Sequence-to-sequence method)和基于流的方法(Flow-based method)。
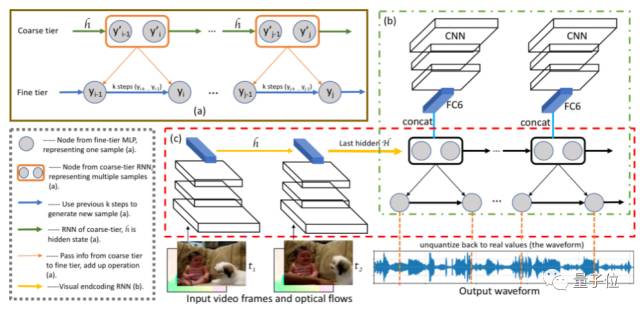
三种变体结构
帧到帧法如上图绿色虚线框内所示。在这种方法中,研究人员将图像表示(蓝色的FC6立方体)与最粗层的节点联系起来。
研究人员将视频帧表示为xi=V(fi),其中fi为第i帧,V(.)是提取VGG19网络中FC6特征的操作,它已经在ImageNet上进行过预训练,xi是一个4096维向量。
在序列到序列的模型中,视频编码器和声音生成器明显是分开的,并通过一个bottleneck来表示连接,它将编码的可视信息提供给声音生成器。如上图中红色框的(c)区所示,研究人员建立了一个递归神经网络来编码视频特征。
这个声音生成任务就变成了:
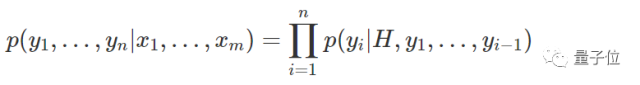
其中H代表视频编码RNN的最后一个隐藏状态,相当于声音生成器最粗一级的RNN的初始隐藏状态。
为了更好地显示运动信号,研究人员在视觉编码器中加入了一个基于光流的深度特征,并将此方法称为基于流的方法。这种方法的总体架构与序列到序列模型完全相同(如(c)所示),通过RNN反复编码视频特征xi,并用SampleRNN进行解码。
唯一的区别是,生成任务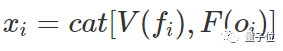 中的oi表示第i帧的光流,而F(.)是提取基于光流的深层特征的函数。
中的oi表示第i帧的光流,而F(.)是提取基于光流的深层特征的函数。
开始训练,Go!
终于开始训练模型了。
研究人员分别用上述三种模型训练筛选出来的10个类别的视频。此时,这些视频已经经过复制和拼接,时长均被填补到10秒。
研究人员用15.6 FPS(156帧10秒)的采样率采集视频,并在约16kHz的采样率对音频采样,具体为159744次每10秒。帧到帧的方法中,将步长s设置为1024。
多维评估结果
训练结果如何?研究人员对模型进行了定性可视化。
下面这张图显示了三种场景,分别为小狗、烟火、敲鼓和铁路。在每个场景中,研究人员拿出了两幅关键帧来作对比,下面的四种波形从上到下分别为帧到帧、序列到序列和基于流的方法生成的结果及原始音频。生成的音频与视频中的关键帧对齐。

对比结果的可视化
前三个场景对音画同步很敏感,但可以发现,波形并没有和真实感知的波形一致,但视频中的关键点处理得还不错。
之后,研究人员从损失值和检索实验两方面对模型进行了定量评估。
通过平均交叉熵损失,可以看到,基于流和序列方法的训练和测试损失值比帧到帧的方法低。

3种方法的训练和测试平均交叉熵损失
之后,研究人员又设计了一个检索实验,利用视觉特征,来查询具有最大抽样可能性的音频。在这个实验中,他们把所有测试视频中的音频都合并到一起,构成一个包含1280段音频的数据库,并对每个测试视频进行音频检索性能测试。
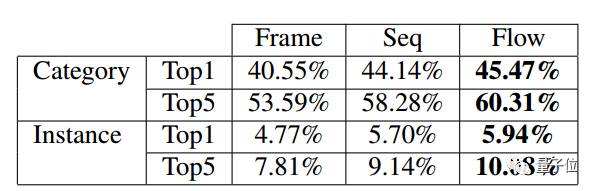
Top 1和Top 5音频检索的准确性。“类别”用来测试检索到的音频是否属于正确类别,“实例”显示了所检索的音频是否与输入视频相匹配
其实对于生成结果来说,最主观的评价方法可能也是最正确的评价方法。研究人员找来了一群人,判断哪种编码器解码器结构的效果更好。
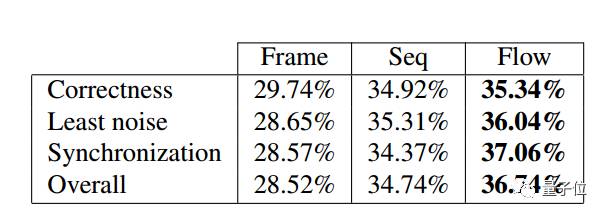
 人类测评结果
人类测评结果
研究人员从正确性、少噪音和同步性的维度,对三种变体的效果进行测试。结果可以看出,帧到帧方法的效果明显落后于其他两个,基于流的方法效果最好。
最后,最一颗赛艇的时刻到了。被调查人员能否在真假视频对中找出合成的“假猴王”呢?来看看研究人员的统计结果。
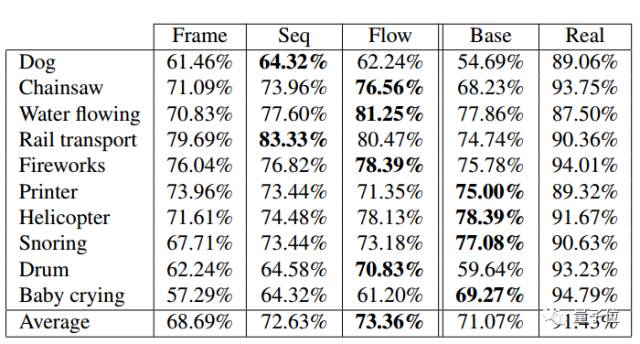
人类测试结果:让人类去判断视频时真实的还是合成的/百分比表示以假乱真的概率
从结果中可以看出,超过70%的生成模型会让人觉得是真实的。
所以,开头判断不出真假的你,也属于这70%的大军啦。
相关资料
项目地址:
http://bvision11.cs.unc.edu/bigpen/yipin/visual2sound_webpage/visual2sound.html
论文地址:
https://arxiv.org/abs/1712.01393
此外,一作YiPin Zhou在项目介绍中表示,过一阵子将开放VEGAS数据集。
对了,开头的短视频中,上面是合成的,下面是真实的,你猜对了吗?
不仅如此。下面这段视频包括打鼓的青年、哭叫的孩子、燃放的烟火、和飞驰的火车等,涵盖了很多自然界中的声音。
每个场景的配音均为一真一假,当场揭晓答案,猜猜你能对几个——
class="video_iframe" data-vidtype="2" allowfullscreen="" frameborder="0" data-ratio="1.7647058823529411" data-w="480" scrolling="no" data-src="http://v.qq.com/iframe/player.html?vid=q0515jcyp49&width=670&height=376.875&auto=0" style="display: block; width: 670px !important; height: 376.875px !important;" width="670" height="376.875" data-vh="376.875" data-vw="670" src="http://v.qq.com/iframe/player.html?vid=q0515jcyp49&width=670&height=376.875&auto=0"/>
编辑:文婧

这篇关于AI根据视频画面自动配音 ,真假难辨 !(附数据集)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







