本文主要是介绍数据蒋堂 | JOIN提速 - 外键指针化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

来源:数据蒋堂
作者:蒋步星
本文长度为1520字,建议阅读4分钟
本文为你讲解重新定义JOIN后如何能够提高运算性能。

我们来看重新定义JOIN后如何能够提高运算性能,先看外键式JOIN的情况。
设有两个表:

其中sales表中的productid是指向products表中id字段的外键,id是products表的主键。
现在我们想计算销售额有多少(为简化讨论,就不再设定条件了),用SQL写出来:
SELECT SUM(sales.quantity*products.price) FROM sales JOIN products ON sales.productid=products.id
基于笛卡尔积定义的JOIN,原则上只能两层循环全遍历来计算,不过这个计算量实在太大,关系数据库一般采用HASH分段方法优化,即分别计算两表关联字段的HASH值,将HASH同值记录拼到一起再做小范围遍历。网上有很多文章介绍这个算法,这里就不详述了。这样做后的复杂度能显著降低,但仍然要做多次HASH值计算和比对。

我们再用前述简化的JOIN语法写出这个运算:
SELECT SUM(quantity*productid.price) FROM sales
而这个写法其实也预示了它还可以有更好的优化方案,下面来看看怎样实现。
我们先考虑全内存的情况,如果所有数据都能够装入内存,我们可以实现外键指针化。
将事实表sales中的外键字段productid,转换成指向维表products记录的指针,即productid的取值就已经是某个products表中的记录,那么就可以直接引用记录的字段进行计算了。
用SQL不方便描述这个运算的细节过程了,我们采用过程式语法、并用文件作为数据源来说明计算过程:
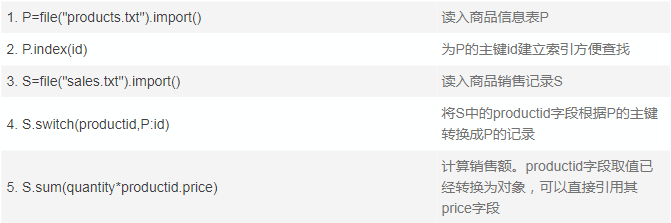
上面算法中,第2步建主键索引一般也是用HASH办法,对id计算HASH值,第4步转换指针还是计算productid的HASH值与P的HASH索引表对比。这样的话,如果只做一次关联运算,指针化的方案和传统HASH分段方案的计算量基本上一样,没有根本优势。
但不同的是,如果数据能在内存中放下,这个指针一旦建立起来之后可以复用,也就是说第2和第4步只要做一次,下次再做关于这两个字段的关联运算时就不必再计算HASH值和比对了,性能就能大幅提高。而关系代数体系下没有对象指针这个概念,并且基于笛卡尔积定义的JOIN运算也无法假定外键指向记录的唯一性,没办法使用外键指针化的方法,每次关联时都要计算HASH值并比对。
而且,如果事实表中有多个外键分别指向多个维表,传统的HASH分段JOIN方案每次只能解析掉一个,有N个JOIN要执行N遍动作,每次关联后都需要保持中间结果供下一轮使用,计算过程复杂得多,数据也会被遍历多次。而外键指针化方案在面对多个外键时,只要对事实表遍历一次, 没有中间结果,计算过程要清晰很多。
还有一点,内存本来应当是很适合并行计算的,但HASH分段JOIN算法却不容易并行。即使把数据分段并行计算HASH值,但要把相同HASH值的记录归聚到一起供下一轮比对,就会发生共享资源冲突的事情,这会把并行计算的优势完全抵消掉。而外键式JOIN模型下,关联两表的地位不对等,明确区分出维表和事实表后,只要简单地将事实表分段就可以并行计算。
将HASH分段技术参照外键属性方案进行改造后,也能一定程度地改善多外键一次解析和并行能力,有些数据库能在工程层面上实施这种优化。不过,这种优化在只有两个表JOIN时问题不大,在有很多表及各种JOIN混在一起时,数据库并不容易识别出应当把哪个表当作事实表去并行遍历、而把其它表当作维表建立HASH索引,这时优化并不总是有效的。所以我们经常会发现当JOIN的表变多时性能会急剧下降的现象(常常到四五个表时就会发生,结果集并无显著增大)。而从JOIN模型上引入外键概念后,将这种JOIN专门处理时,就总能分清事实表和维表,更多的JOIN表只会导致性能的线性下降。
内存数据库是当前比较火热的技术,但上述分析表明,采用SQL模型的内存数据库在JOIN运算上是很难快起来的!
专栏作者简介

润乾软件创始人、首席科学家
清华大学计算机硕士,著有《非线性报表模型原理》等,1989年,中国首个国际奥林匹克数学竞赛团体冠军成员,个人金牌;2000年,创立润乾公司;2004年,首次在润乾报表中提出非线性报表模型,完美解决了中国式复杂报表制表难题,目前该模型已经成为报表行业的标准;2014年,经过7年开发,润乾软件发布不依赖关系代数模型的计算引擎——集算器,有效地提高了复杂结构化大数据计算的开发和运算效率;2015年,润乾软件被福布斯中文网站评为“2015福布斯中国非上市潜力企业100强”;2016年,荣获中国电子信息产业发展研究院评选的“2016年中国软件和信息服务业十大领军人物”;2017年, 自主创新研发新一代的数据仓库、云数据库等产品即将面世。
数据蒋堂
《数据蒋堂》的作者蒋步星,从事信息系统建设和数据处理长达20多年的时间。他丰富的工程经验与深厚的理论功底相互融合、创新思想与传统观念的相互碰撞,虚拟与现实的相互交织,产生出了一篇篇的沥血之作。此连载的内容涉及从数据呈现、采集到加工计算再到存储以及挖掘等各个方面。大可观数据世界之远景、小可看技术疑难之细节。针对数据领域一些技术难点,站在研发人员的角度从浅入深,进行全方位、360度无死角深度剖析;对于一些业内观点,站在技术人员角度阐述自己的思考和理解。蒋步星还会对大数据的发展,站在业内专家角度给予预测和推断。静下心来认真研读你会发现,《数据蒋堂》的文章,有的会让用户避免重复前人走过的弯路,有的会让攻城狮面对扎心的难题茅塞顿开,有的会为初入行业的读者提供一把开启数据世界的钥匙,有的甚至会让业内专家大跌眼镜,产生思想交锋。
往期回顾:
数据蒋堂 | JOIN简化 - 意义总结
数据蒋堂 | JOIN简化-消除关联
数据蒋堂 | JOIN简化 - 维度对齐
数据蒋堂 | JOIN运算剖析
数据蒋堂 | 迭代聚合语法
数据蒋堂 | 非常规聚合
数据蒋堂 | 再谈有序分组
数据蒋堂 | 有序分组
数据蒋堂 | 非等值分组
数据蒋堂 | 还原分组运算的本意
数据蒋堂 | 有序遍历语法
数据蒋堂 | 常规遍历语法
数据蒋堂 | 从SQL语法看离散性
数据蒋堂 | 从SQL语法看集合化
数据蒋堂 | SQL用作大数据计算语法好吗?
数据蒋堂 | SQL的困难源于关系代数
数据蒋堂 | SQL像英语是个善意的错误
数据蒋堂 | 开放的计算能力为数据库瘦身
数据蒋堂 | 计算封闭性导致臃肿的数据库
数据蒋堂 | 怎样看待存储过程的移植困难
数据蒋堂 | 存储过程的利之弊
数据蒋堂 | 不要对自助BI期望过高
数据蒋堂 | 报表的数据计算层
数据蒋堂 | 报表应用的三层结构
数据蒋堂 | 列式存储的另一面
数据蒋堂 | 硬盘的性能特征
数据蒋堂 | 我们需要怎样的OLAP?
数据蒋堂 | 1T数据到底有多大?
数据蒋堂 | 索引的本质是排序
数据蒋堂 | 功夫都在报表外--漫谈报表性能优化
数据蒋堂 | 非结构化数据分析是忽悠?
数据蒋堂 | 多维分析的后台性能优化手段
校对:王红玉
为保证发文质量、树立口碑,数据派现设立“错别字基金”,鼓励读者积极纠错。
若您在阅读文章过程中发现任何错误,请在文末留言,或到后台反馈,经小编确认后,数据派将向检举读者发8.8元红包。
同一位读者指出同一篇文章多处错误,奖金不变。不同读者指出同一处错误,奖励第一位读者。
感谢一直以来您的关注和支持,希望您能够监督数据派产出更加高质的内容。

这篇关于数据蒋堂 | JOIN提速 - 外键指针化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





