本文主要是介绍基于大数据的全国热门景点数据可视化分析系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :)
1. 项目简介
本文将介绍如何使用Python中的Pandas库进行数据挖掘,并结合Flask Web框架实现一个旅游景点数据分析系统。该系统将包括以下功能模块:热门景点概况、景点星级与评分分析、景点价格分析、景点客流量销量分析以及景点地理空间分析。通过对数据的深入挖掘和可视化展示(包括柱状图、散点图、箱型图和地图),用户可以轻松了解各个景点的特点和趋势,为旅游规划和决策提供有力支持。
基于大数据的全国热门景点数据可视化分析系统
2. 基于大数据的全国热门景点数据可视化分析系统
2.1 系统首页与注册登录
2.2 热门景点概况
热门景点概况模块分析全国各省、直辖市、自治区的热门景点数量分布情况,景点宣传标语的词云可视化:
@app.route('/spot_intro_wordcloud')
def spot_intro_wordcloud():"""景点简介词云分析"""wordclout_dict = {}for text in spot_df['简介'].values:if not text:continuetry:words = jieba.cut(text)for word in words:if word not in STOPWORDS and word not in {'位于'}:if word not in wordclout_dict:wordclout_dict[word] = 0else:wordclout_dict[word] += 1except:passwordclout_dict = [(k, wordclout_dict[k]) for k in sorted(wordclout_dict.keys()) if wordclout_dict[k] > 8]wordclout_dict = [{"name": k[0], "value": k[1]} for k in wordclout_dict]return jsonify({'词云数据': wordclout_dict})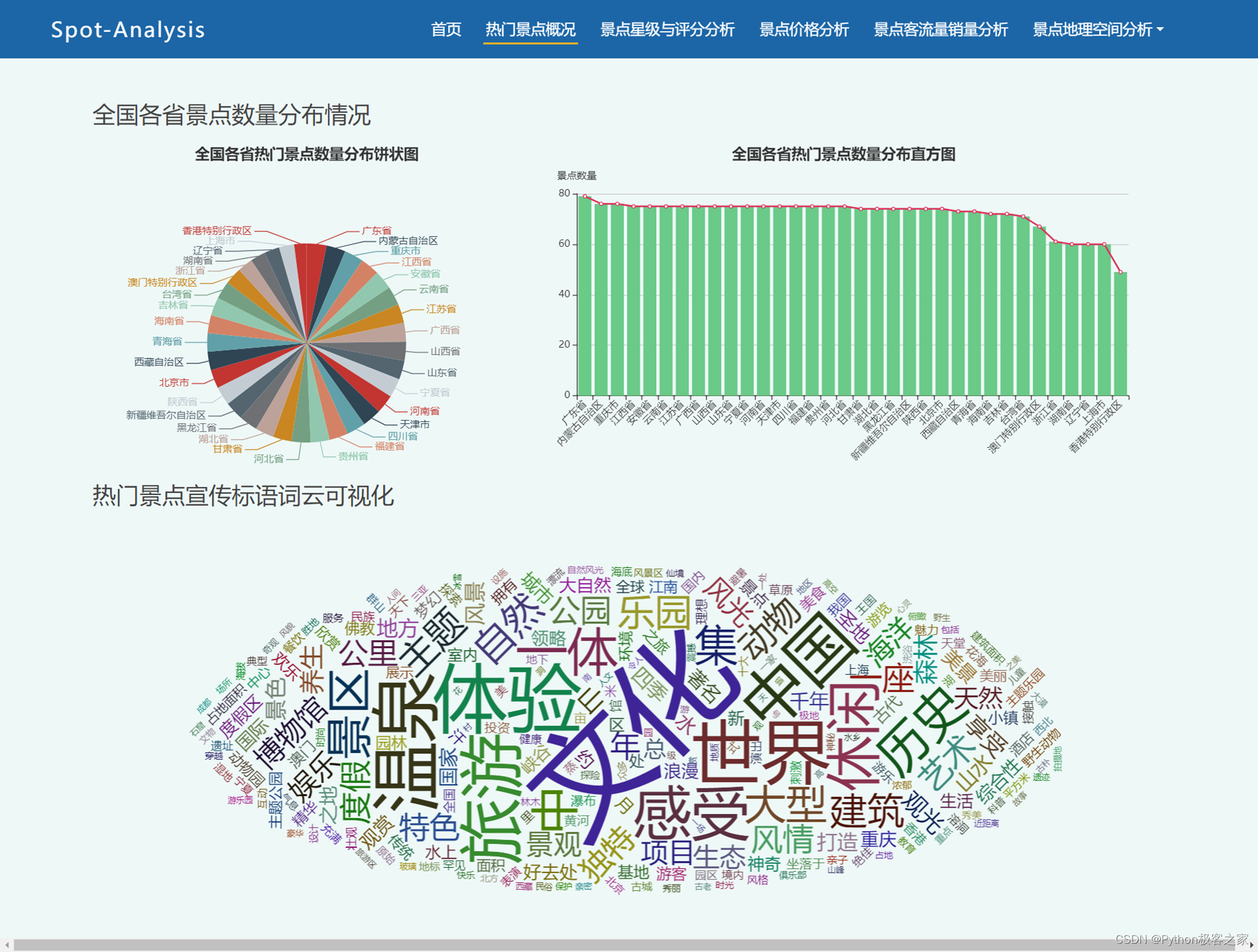
2.3 景点星级与评分分析
分析不同省份景点的星级与评分分布,对景点数据进行深入的挖掘和分析,统计不同星级与评分的景点数量,以及不同省份评分分布箱型图。

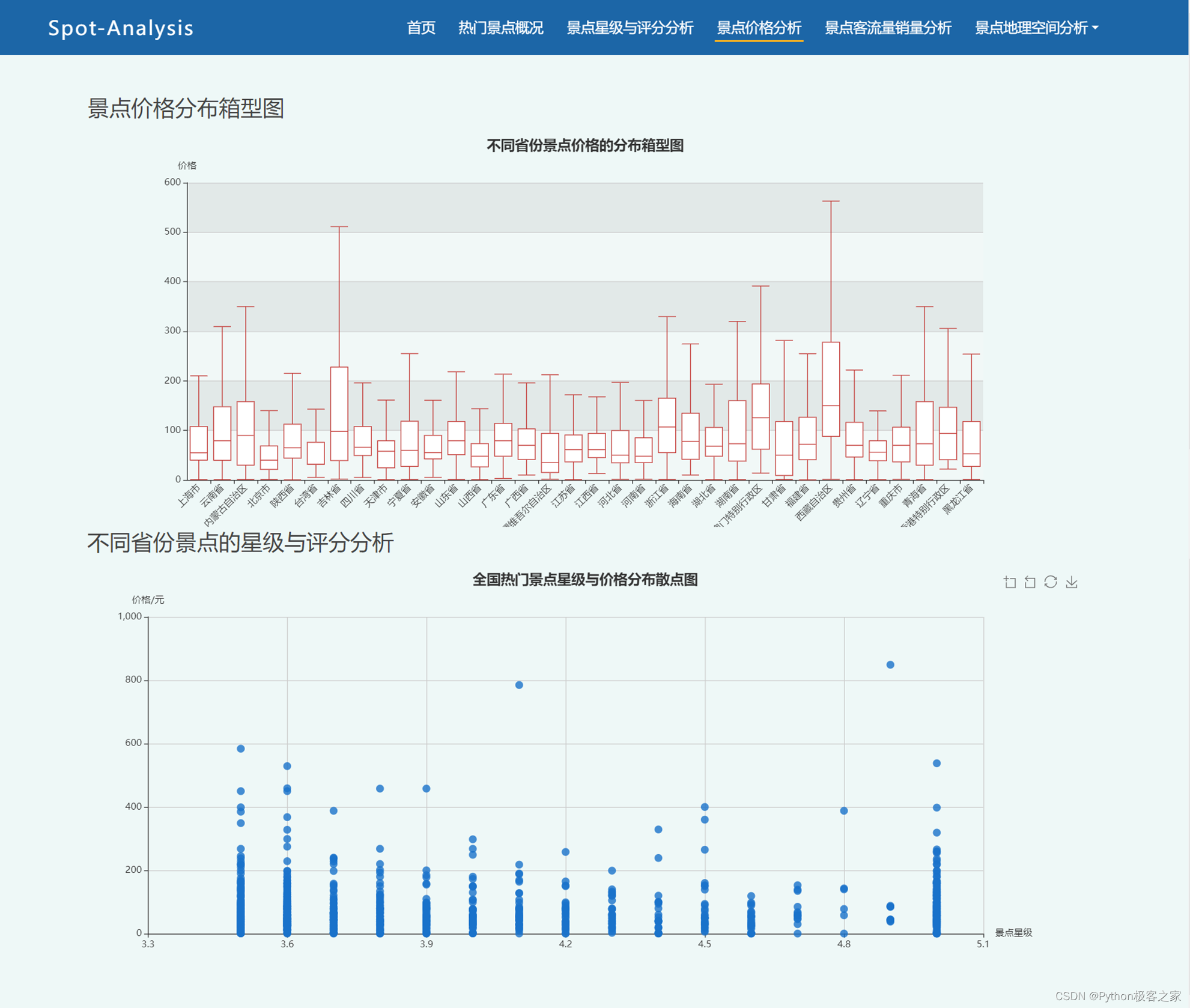
2.4 景点价格分析
利用pandas从CSV文件中加载景点价格数据,并进行预处理,通过数据探索性分析,深入了解价格数据的特性和分布。
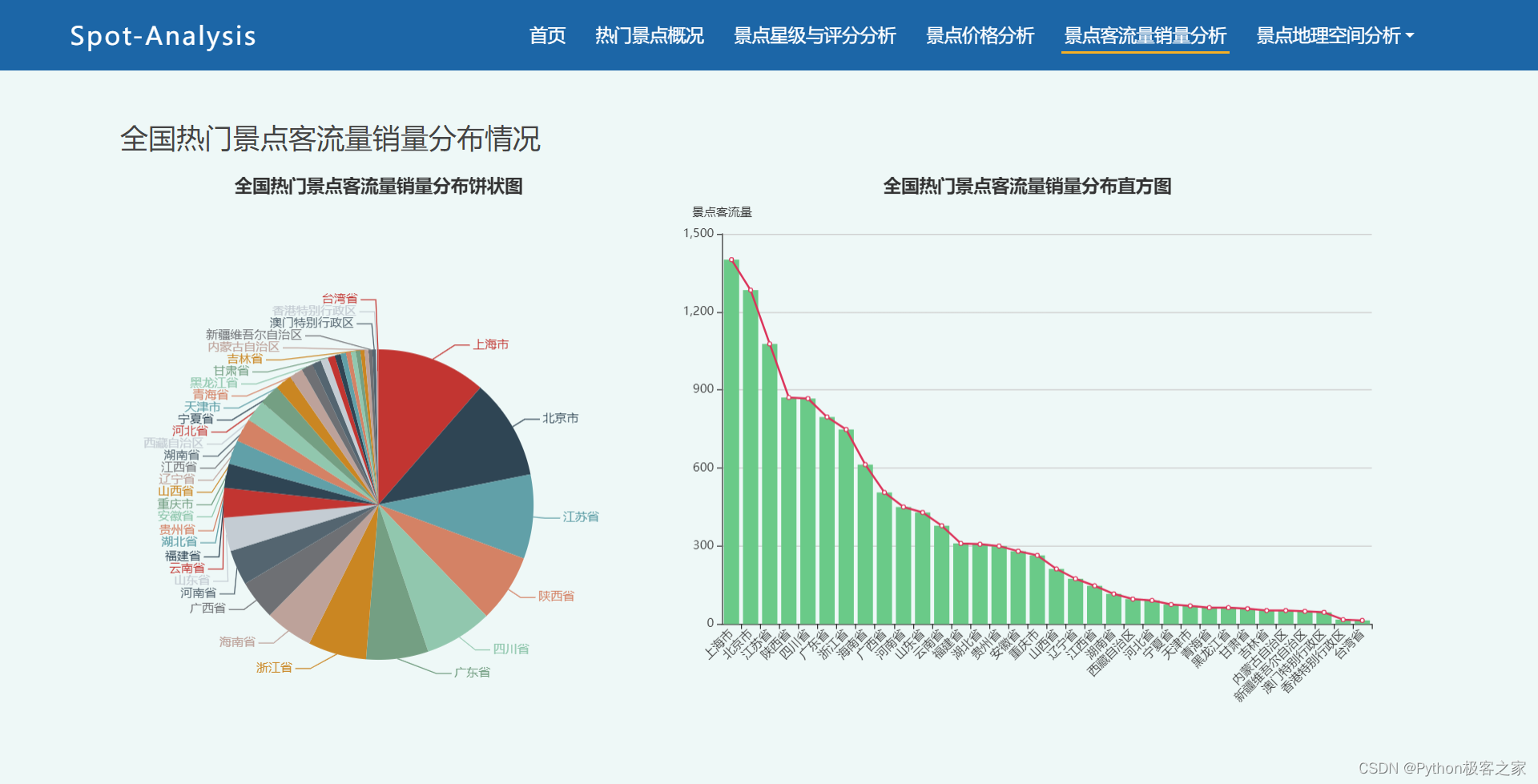
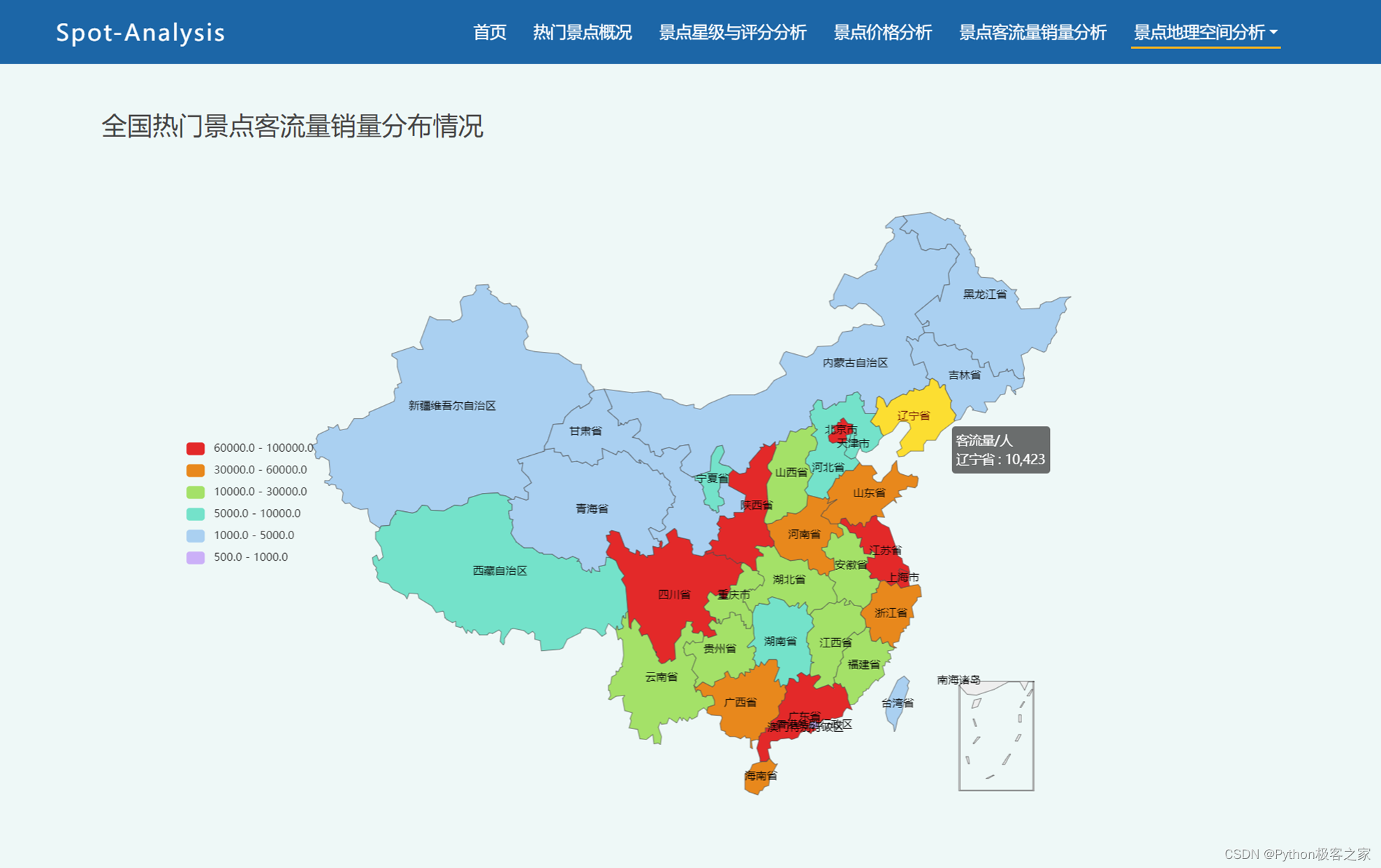
2.5 景点客流量销量分析
通过景点客流量和销量的深度数据挖掘分析,并利用 Echarts 进行数据可视化,帮助用户更好地理解和解读客流量和销量数据。
2.6 景点地理空间分析
通过对景点的地理空间数据进行深入分析,揭示景点分布规律以及与其他因素的关联性,为旅游规划、资源优化等方面提供有价值的参考信息。
@app.route('/spot_volume_loc_map')
def spot_volume_loc_map():"""景点客流量,结合经纬度的地图可视化"""spot_volume = []city_region = {}for i, row in spot_df.iterrows():name = str(row['名称'])volume = row['销量']longitude, latitude = row['坐标'].split(',')spot_volume.append({'name': name, 'value': volume})city_region[name] = [float(longitude), float(latitude)]......return jsonify(results)
3. 总结
本文将介绍如何使用Python中的Pandas库进行数据挖掘,并结合Flask Web框架实现一个旅游景点数据分析系统。该系统将包括以下功能模块:热门景点概况、景点星级与评分分析、景点价格分析、景点客流量销量分析以及景点地理空间分析。通过对数据的深入挖掘和可视化展示(包括柱状图、散点图、箱型图和地图),用户可以轻松了解各个景点的特点和趋势,为旅游规划和决策提供有力支持。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。技术交流、源码获取认准下方 CSDN 官方提供的学长 QQ 名片 :)
精彩专栏推荐订阅:
1. Python数据挖掘精品实战案例
2. 计算机视觉 CV 精品实战案例
3. 自然语言处理 NLP 精品实战案例

这篇关于基于大数据的全国热门景点数据可视化分析系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






