本文主要是介绍谷歌、阿里们的杀手锏:3大领域,10大深度学习CTR模型演化图谱(附论文),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

来源:知乎
作者:王喆
本文约4000字,建议阅读8分钟。
本文为你介绍近3年来的所有主流深度学习CTR模型。
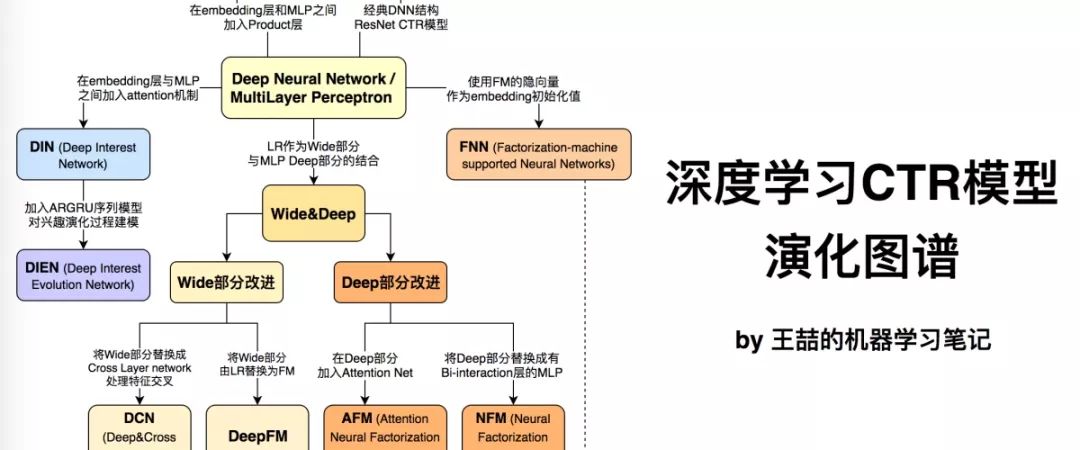
今天我们一起回顾一下近3年来的所有主流深度学习CTR模型,也是我工作之余的知识总结,希望能帮大家梳理推荐系统、计算广告领域在深度学习方面的前沿进展。
随着微软的Deep Crossing,谷歌的Wide&Deep,以及FNN,PNN等一大批优秀的深度学习CTR预估模型在2016年被提出,计算广告和推荐系统领域全面进入了深度学习时代,时至今日,深度学习CTR模型已经成为广告和推荐领域毫无疑问的主流。在进入深度学习时代之后,CTR模型不仅在表达能力、模型效果上有了质的提升,而且大量借鉴并融合了深度学习在图像、语音以及自然语言处理方向的成果,在模型结构上进行了快速的演化。
本文总结了广告、推荐领域最为流行的10个深度学习CTR模型的结构特点,构建了它们之间的演化图谱。选择模型的标准尽量遵循下面三个原则:
在业界影响力较大的;
已经被谷歌,微软,阿里等知名互联网公司成功应用的;
工程导向的,而不是仅用实验数据验证或学术创新用的。
下面首先列出这张深度学习CTR模型的演化图谱,再对其进行逐一介绍:
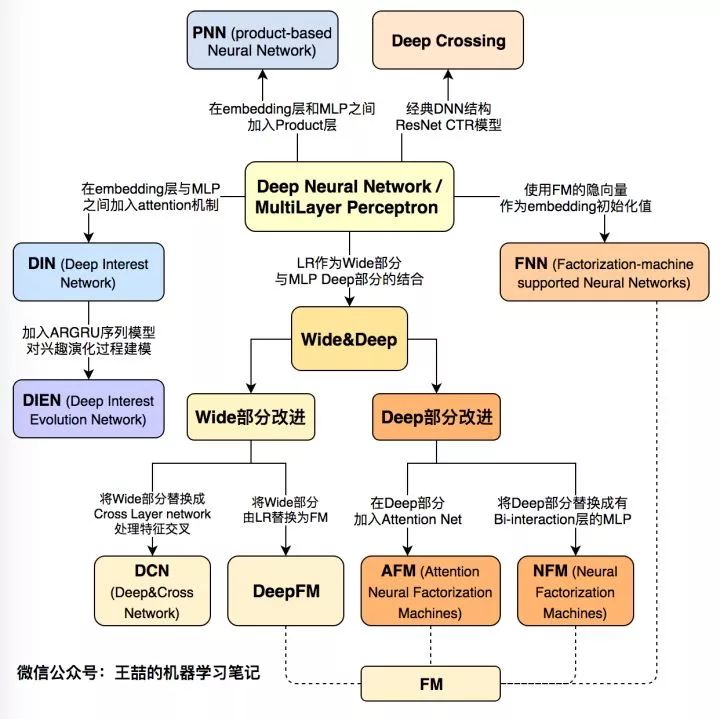
图1 深度学习CTR模型演化图谱
一、微软Deep Crossing(2016年)——深度学习CTR模型的base model
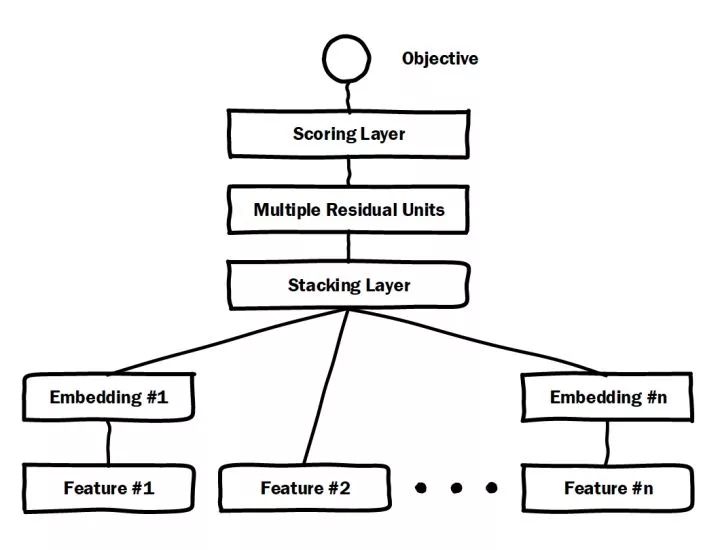
图2 微软Deep Crossing模型架构图
微软于2016年提出的Deep Crossing可以说是深度学习CTR模型的最典型和基础性的模型。如图2的模型结构图所示,它涵盖了深度CTR模型最典型的要素,即通过加入embedding层将稀疏特征转化为低维稠密特征,用stacking layer,或者叫做concat layer将分段的特征向量连接起来,再通过多层神经网络完成特征的组合、转换,最终用scoring layer完成CTR的计算。跟经典DNN有所不同的是,Deep crossing采用的multilayer perceptron是由残差网络组成的,这无疑得益于MSRA著名研究员何恺明提出的著名的152层ResNet。
论文:[Deep Crossing] Deep Crossing - Web-Scale Modeling without Manually Crafted Combinatorial Features (Microsoft 2016)
二、FNN(2016年)——用FM的隐向量完成Embedding初始化
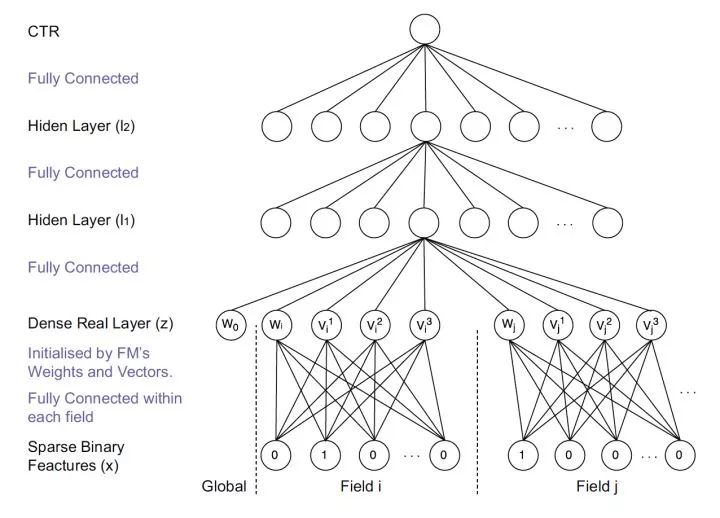
图3 FNN模型架构图
FNN相比Deep Crossing的创新在于使用FM的隐层向量作为user和item的Embedding,从而避免了完全从随机状态训练Embedding。由于id类特征大量采用one-hot的编码方式,导致其维度极大,向量极稀疏,所以Embedding层与输入层的连接极多,梯度下降的效率很低,这大大增加了模型的训练时间和Embedding的不稳定性,使用pre train的方法完成Embedding层的训练,无疑是降低深度学习模型复杂度和训练不稳定性的有效工程经验。
论文:[FNN] Deep Learning over Multi-field Categorical Data (UCL 2016)
三、PNN (2016年)——丰富特征交叉的方式
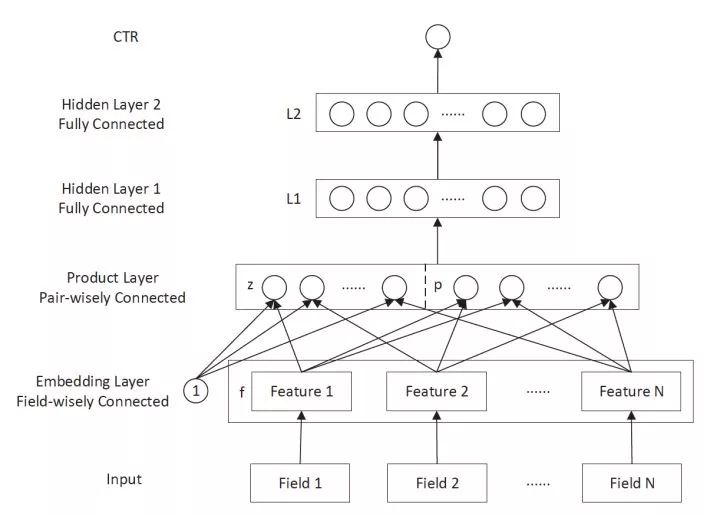
图4 PNN模型架构图
PNN的全称是Product-based Neural Network,PNN的关键在于在Embedding层和全连接层之间加入了Product layer。传统的DNN是直接通过多层全连接层完成特征的交叉和组合的,但这样的方式缺乏一定的“针对性”。首先全连接层并没有针对不同特征域之间进行交叉;其次,全连接层的操作也并不是直接针对特征交叉设计的。但在实际问题中,特征交叉的重要性不言而喻,比如年龄与性别的交叉是非常重要的分组特征,包含了大量高价值的信息,我们急需深度学习网络,有针对性的结构能够表征这些信息。因此PNN通过加入Product layer完成了针对性的特征交叉,其Product操作在不同特征域之间进行特征组合。并定义了inner product,outer product等多种product的操作捕捉不同的交叉信息,增强模型表征不同数据模式的能力 。
论文:[PNN] Product-based Neural Networks for User Response Prediction (SJTU 2016)
四、Google Wide&Deep(2016年)——记忆能力和泛化能力的综合权衡

图5 Google Wide&Deep模型架构图
Google Wide&Deep模型的主要思路正如其名,把单输入层的Wide部分和经过多层感知机的Deep部分连接起来,一起输入最终的输出层。其中Wide部分的主要作用是让模型具有记忆性(Memorization),单层的Wide部分善于处理大量稀疏的id类特征,便于让模型直接“记住”用户的大量历史信息;Deep部分的主要作用是让模型具有“泛化性”(Generalization),利用DNN表达能力强的特点,挖掘藏在特征后面的数据模式。最终利用LR输出层将Wide部分和Deep部分组合起来,形成统一的模型。Wide&Deep对之后模型的影响在于——大量深度学习模型采用了两部分甚至多部分组合的形式,利用不同网络结构挖掘不同的信息后进行组合,充分利用和结合了不同网络结构的特点。
论文:[Wide&Deep] Wide & Deep Learning for Recommender Systems (Google 2016)
五、华为 DeepFM (2017年)——用FM代替Wide部分
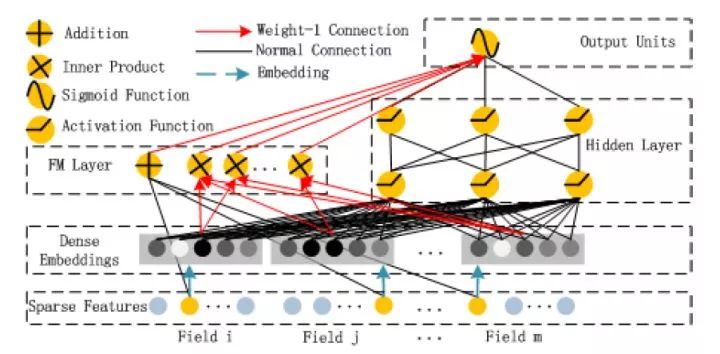
图6 华为DeepFM模型架构图
在Wide&Deep之后,诸多模型延续了双网络组合的结构,DeepFM就是其中之一。DeepFM对Wide&Deep的改进之处在于,它用FM替换掉了原来的Wide部分,加强了浅层网络部分特征组合的能力。事实上,由于FM本身就是由一阶部分和二阶部分组成的,DeepFM相当于同时组合了原Wide部分+二阶特征交叉部分+Deep部分三种结构,无疑进一步增强了模型的表达能力。
论文:[DeepFM] A Factorization-Machine based Neural Network for CTR Prediction (HIT-Huawei 2017)
六、Google Deep&Cross(2017年)——使用Cross网络代替Wide部分
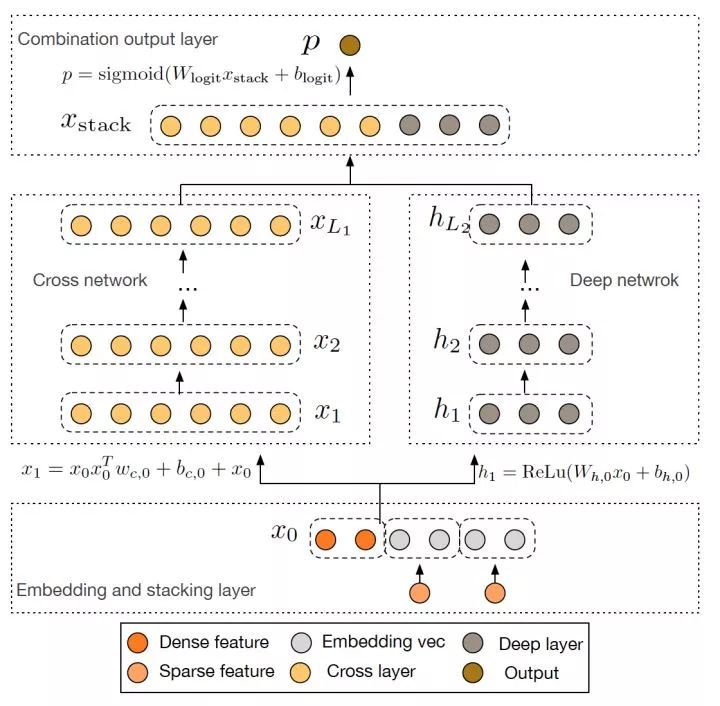
图7 Google Deep Cross Network模型架构图
Google 2017年发表的Deep&Cross Network(DCN)同样是对Wide&Deep的进一步改进,主要的思路使用Cross网络替代了原来的Wide部分。其中设计Cross网络的基本动机是为了增加特征之间的交互力度,使用多层Cross layer对输入向量进行特征交叉。单层Cross layer的基本操作是将Cross layer的输入向量xl与原始的输入向量x0进行交叉,并加入bias向量和原始xl输入向量。DCN本质上还是对Wide&Deep Wide部分表达能力不足的问题进行改进,与DeepFM的思路非常类似。
论文:[DCN] Deep & Cross Network for Ad Click Predictions (Stanford 2017)
七、NFM(2017年)——对Deep部分的改进
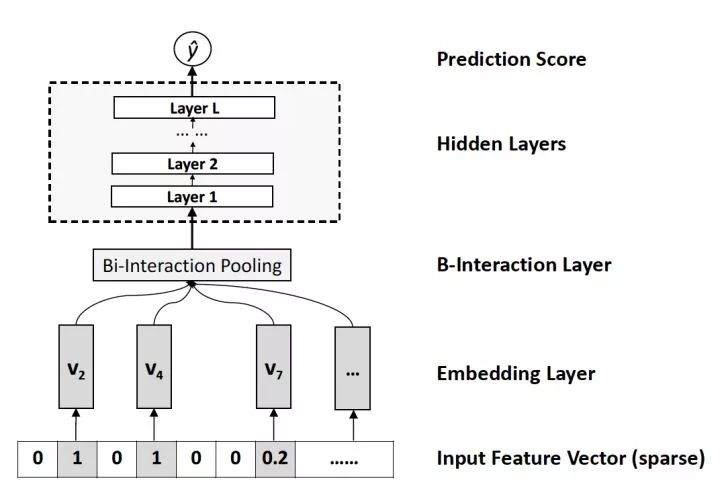
图8 NFM的深度网络部分模型架构图
相对于DeepFM和DCN对于Wide&Deep Wide部分的改进,NFM可以看作是对Deep部分的改进。NFM的全称是Neural Factorization Machines,如果我们从深度学习网络架构的角度看待FM,FM也可以看作是由单层LR与二阶特征交叉组成的Wide&Deep的架构,与经典W&D的不同之处仅在于Deep部分变成了二阶隐向量相乘的形式。再进一步,NFM从修改FM二阶部分的角度出发,用一个带Bi-interaction Pooling层的DNN替换了FM的特征交叉部分,形成了独特的Wide&Deep架构。其中Bi-interaction Pooling可以看作是不同特征Embedding的element-wise product的形式。这也是NFM相比Google Wide&Deep的创新之处。
论文:[NFM] Neural Factorization Machines for Sparse Predictive Analytics (NUS 2017)
八、AFM(2017年)——引入Attention机制的FM
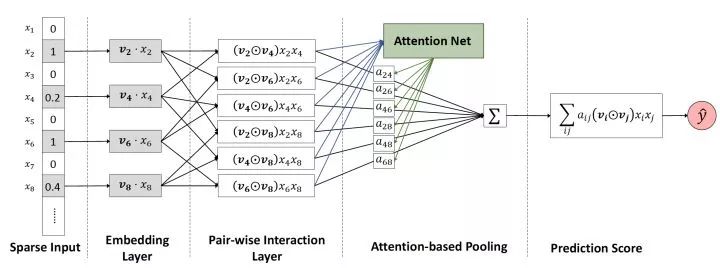
图9 AFM模型架构图
AFM的全称是Attentional Factorization Machines,通过前面的介绍我们很清楚的知道,FM其实就是经典的Wide&Deep结构,其中Wide部分是FM的一阶部分,Deep部分是FM的二阶部分,而AFM顾名思义,就是引入Attention机制的FM,具体到模型结构上,AFM其实是对FM的二阶部分的每个交叉特征赋予了权重,这个权重控制了交叉特征对最后结果的影响,也就非常类似于NLP领域的注意力机制(Attention Mechanism)。为了训练Attention权重,AFM加入了Attention Net,利用Attention Net训练好Attention权重后,再反向作用于FM二阶交叉特征之上,使FM获得根据样本特点调整特征权重的能力。
论文:[AFM] Attentional Factorization Machines - Learning the Weight of Feature Interactions via Attention Networks (ZJU 2017)
九、阿里DIN(2018年)——阿里加入Attention机制的深度学习网络

图10 阿里DIN模型与Base模型的架构图
AFM在FM中加入了Attention机制,2018年,阿里巴巴正式提出了融合了Attention机制的深度学习模型——Deep Interest Network。与AFM将Attention与FM结合不同的是,DIN将Attention机制作用于深度神经网络,在模型的Embedding layer和concatenate layer之间加入了attention unit,使模型能够根据候选商品的不同,调整不同特征的权重。
论文:[DIN] Deep Interest Network for Click-Through Rate Prediction (Alibaba 2018)
十、阿里DIEN(2018年)——DIN的“进化”
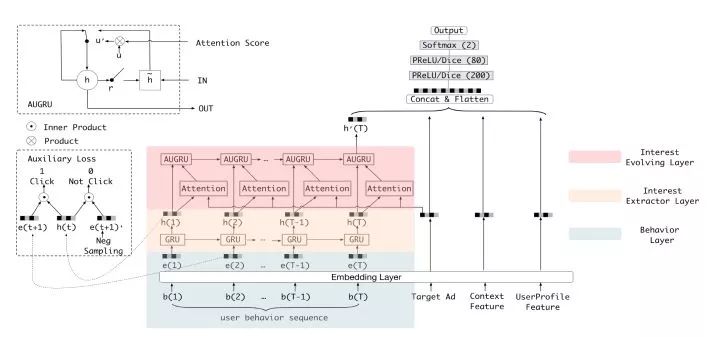
图11 阿里DIEN模型架构图
DIEN的全称为Deep Interest Evolution Network,它不仅是对DIN的进一步“进化”,更重要的是DIEN通过引入序列模型 AUGRU模拟了用户兴趣进化的过程。具体来讲模型的主要特点是在Embedding layer和Concatenate layer之间加入了生成兴趣的Interest Extractor Layer和模拟兴趣演化的Interest Evolving layer。其中Interest Extractor Layer使用了DIN的结构抽取了每一个时间片内用户的兴趣,Interest Evolving layer则利用序列模型AUGRU的结构将不同时间的用户兴趣串联起来,形成兴趣进化的链条。最终再把当前时刻的“兴趣向量”输入上层的多层全连接网络,与其他特征一起进行最终的CTR预估。
论文:[DIEN] Deep Interest Evolution Network for Click-Through Rate Prediction (Alibaba 2019)
总结—— CTR模型的深度学习时代
文章的最后,我再次强调这张深度学习CTR模型演化图,可以毫不夸张的说,这张演化图包括了近年来所有主流的深度学习CTR模型的结构特点以及它们之间的演化关系。希望能够帮助推荐、广告、搜索领域的算法工程师们建立起完整的知识体系,能够驾轻就熟的针对业务特点应用并比较不同模型的效果,从而用最适合当前数据模式的模型驱动公司业务。
结合自己的工作经验,关于深度学习模型我想再分享两点内容:
没有银弹。从来没有一个深度学习模型能够在所有数据集上都表现最优,特别是推荐、广告领域,各家的数据集,数据pattern、业务领域差异巨大,不存在能够解决一切问题的“银弹”模型。比如,阿里的DIEN对于数据质量、用户整个life cycle行为完整性的要求很高,如果在某些DSP场景下运用这个模型,预计不会收到良好的效果。再比如Google 的Deep&Cross,我们也要考虑自己的数据集需不需要如此复杂的特征交叉方式,在一些百万量级的数据集上,也许浅层神经网络的表现更好。
算法工程师永远要在理想和现实间做trade off。有一种思想要避免,就是我为了要上某个模型就要强转团队的技术栈,强买某些硬件设备。模型的更新过程一定是迭代的,一定是从简单到复杂的,一定是你证明了某个模型是work的,然后在此基础上做改进的。这也是我们要熟悉所有模型演化关系的原因。
就在我们熟悉这些已有模型的时候,深度学习CTR模型的发展从没有停下它的脚步。从阿里的多模态、多目标的深度学习模型,到YouTube基于RNN等序列模型的推荐系统,再到Airbnb使用Embedding技术构建的搜索推荐模型,深度学习的应用不仅越来越广泛,而且得到了越来越快的进化。在今后的专栏文章中,我们不仅会更深入的介绍深度学习CTR模型的知识,而且会更加关注深度学习CTR模型的应用与落地,期待与大家一同学习。
原文链接:https://mp.weixin.qq.com/s/i3_0eUUcbM4q9M09RTNspA
编辑:王菁
校对:杨学俊


这篇关于谷歌、阿里们的杀手锏:3大领域,10大深度学习CTR模型演化图谱(附论文)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






