本文主要是介绍ICML 2021论文接收大排行!谷歌霸榜,国内北大第一、清华第二,华人学者表现亮眼.........,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

来源:AI科技评论本文约2000字,建议阅读5分钟本文介绍了ICML2021的论文接受情况。

在一个月之前,ICML 2021的论文接收结果已经公布,今年一共有5513篇有效投稿,其中1184篇论文被接收,接收率为21.5% 。另外在这1184篇被接收论文中,有166篇长presentations和1018篇短presentations。
具体可查看这篇文章:
ICML刚刚放榜!接收率仅21%为近五年最低,感谢审稿人不「杀」之恩
而就在近日,ICML 2021的论文接收列表也终于放了出来:

链接:
https://icml.cc/Conferences/2021/AcceptedPapersInitial
在论文接收列表出来之后,还是辣个男人,Criteo AI Lab机器学习研究科学家Sergey Ivanov,他又一次火速爬取了ICLM 2021 被接收录用的论文,并按照国家、机构、大学等作为划分统计出了多个论文接收的排行榜。

机构、国家和大学排名
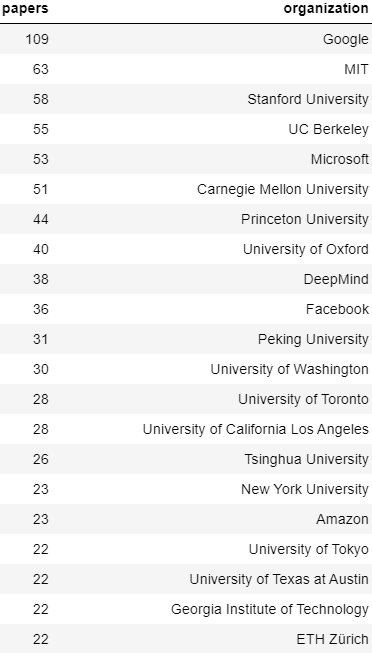
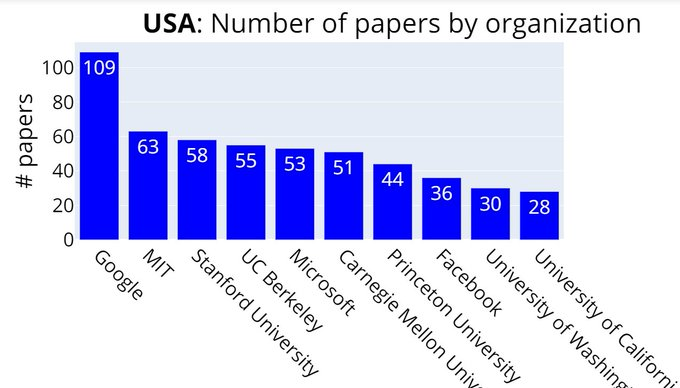
首先按照机构来划分,排在第一位的毫无疑问仍然是谷歌——以109篇论文霸榜。
2-9位依次是:MIT、斯坦福大学、伯克利大学、微软、CMU、普林斯顿大学、牛津大学、DeepMind、Facebook。
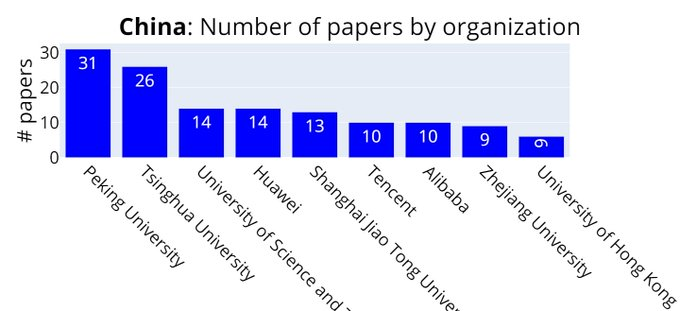
紧接着就是北京大学以31篇排在第11位 ,清华大学以26篇排在第15位。
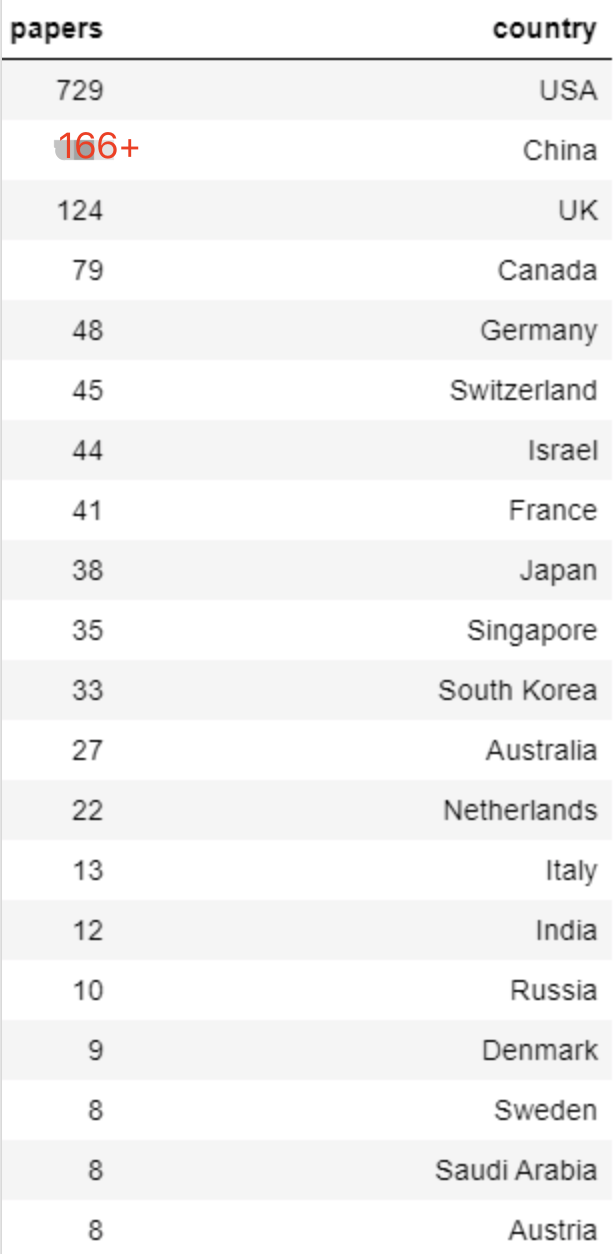
之后按照国家来划分,前两位毫无疑问是美国和中国,分别是729篇和166+篇,英国(124篇)、加拿大(79篇)、德国(48篇)则排在后面几位。
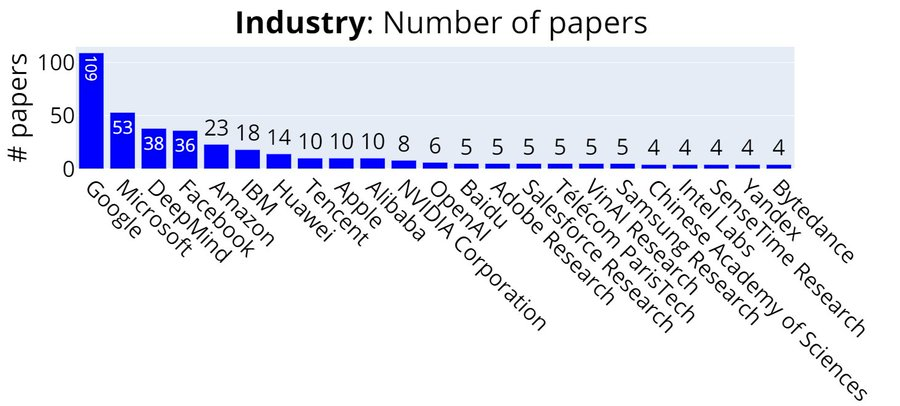
只计算产业界的大公司的论文数量来排名:
Google、Microsoft、DeepMind、FB、Amazon、IBM、华为、腾讯 、Apple、 阿里巴巴。
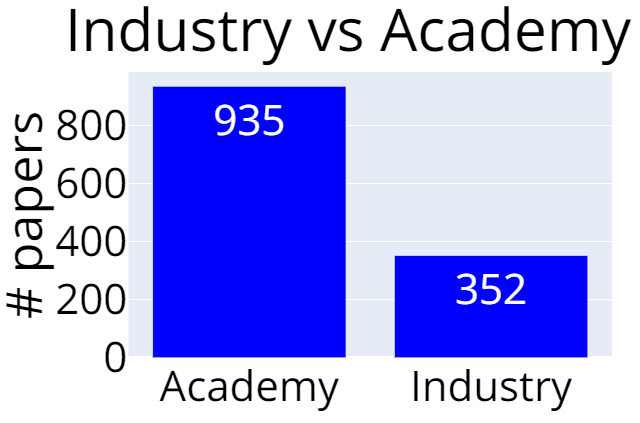
大学 vs 产业
学术界的论文有935篇,产业界的有352篇,意味着大多数论文至少与一所大学有联系。
只计算每个国家的大学来排名:美国、中国、英国......
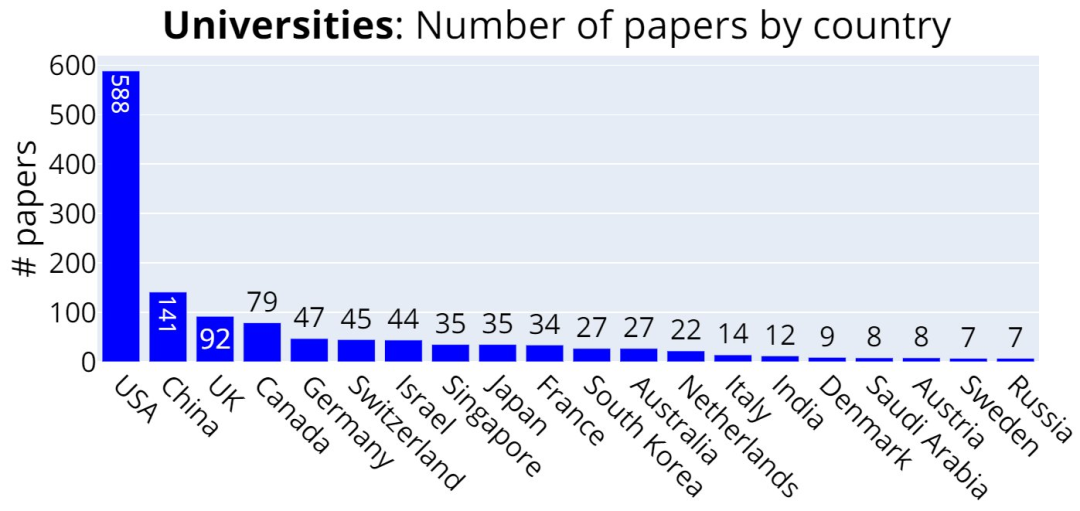
按照各个国家(前4)来分别划分排名:
美国:谷歌、MIT、斯坦福、UC伯克利、微软......
中国:北京大学(31篇)、清华大学(26篇)、中科大(14篇)、华为(14篇)上海交大(13篇)、腾讯(10篇)、阿里巴巴(10篇)、浙江大学(9篇)、香港大学(6篇)。
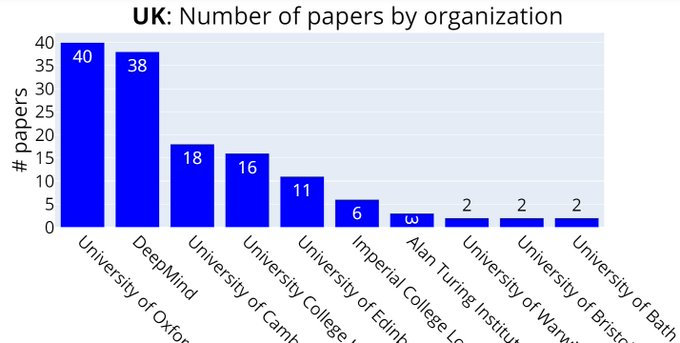
英国:牛津大学、DeepMind、剑桥大学......
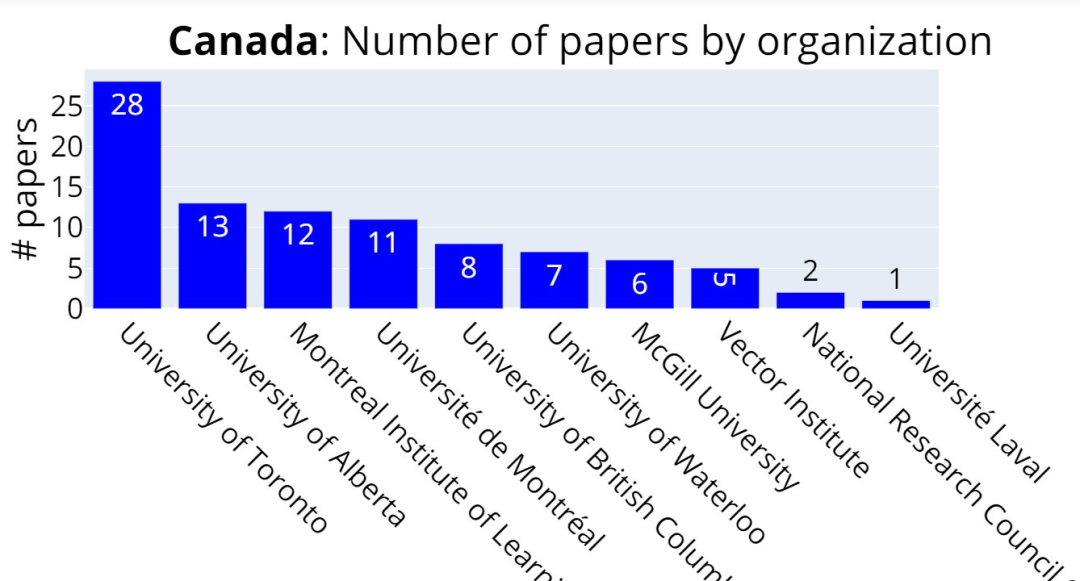
加拿大:多伦多大学、阿尔伯塔大学、蒙特利尔学习算法研究所 (MILA)......
按照作者来排名,华人学者表现亮眼
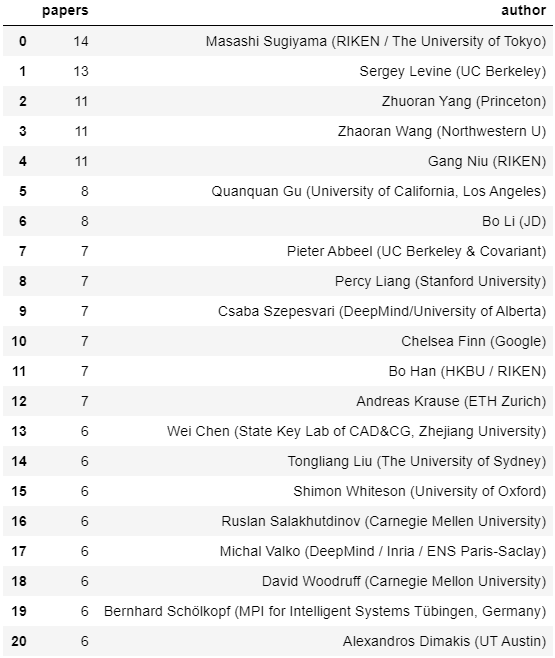
Masashi Sugiyama 14篇
日本人工智能和机器学习领域新一代的代表性人物——日本理化学研究所先进智能研究中心主任Masashi Sugiyama教授以14篇论文排在第一位,而他去年也以11篇论文同样排在第一位。

图源 CCAI 2017
Sergey Levine 13篇
强化学习领域新星、伯克利大神Sergey Levine 以13篇论文排在第二位,而他去年在ICML 2020也有5篇论文入选。另外他称得上是顶会论文收割机:NeurIPS两年共发了24篇论文。

至于他的论文到底为何发这么多,到底有没有灌水,AI科技评论在一篇文章中有所讨论:伯克利大神发布深度学习新课程!他是强化学习大牛、顶会论文收割机:NeurIPS两年24篇。
另外Sergey Levine的博士后导师、强化学习大牛Pieter Abbeel也有7篇论文排在前列,Pieter Abbeel 是吴恩达的高徒。

杨卓然 11篇

杨卓然目前是普林斯顿大学运筹学和金融工程博士生,他于2015在清华大学获得数学学士学位。
他的研究兴趣在于机器学习、统计和优化、强化学习的应用。他的主要研究目标是为强化学习和随机游戏中出现的大规模决策问题设计有效的学习算法,同时具有统计和计算保证。
个人主页:
https://www.princeton.edu/~zy6/
汪昭然 11篇
汪昭然现任美国西北大学工业工程与管理科学系和计算机科学系助理教授。本科毕业于清华大学电子工程系,随后前往普林斯顿大学运筹与金融工程系攻读博士学位。

牛罡 11篇

牛罡博士是日本理化研究所人工智能研究员,他本科毕业于南京大学。
顾全全 8篇

现为加州大学洛杉矶分校计算机科学助理教授,2003年-2007年本科就读于清华大学自动化专业,2013年取得清华大学控制科学与工程硕士学位,2014年获得伊利诺伊大学香槟分校计算机科学博士学位。
个人主页:
http://web.cs.ucla.edu/~qgu/
韩波 7篇

韩波博士于2020年1月作为计算机科学的助理教授加入香港浸会大学(Hong Kong Baptist University, HKBU),建立可信赖机器学习研究组(Trustworthy Machine Learning Group),主要从事可信赖机器学习算法及其应用。
个人主页:
https://bhanml.github.io
刘同亮 7篇

刘同亮博士于2017年作为助理教授加入悉尼大学。现任悉尼大学可信赖机器学习实验室主任。
个人主页:
https://tongliang-liu.github.io/
另外说一句,韩波博士和刘同亮博士目前都有博士生招生需求,可参见:
香港、澳洲三所高校 AI 博士生招生!还有研究助理和实习生等你加入......
Percy Liang 7篇

Percy Liang 是斯坦福大学计算机科学和统计学助理教授、Google Assistant 中核心语言理解技术的创造者,Percy Liang 所带领的团队建立了SQuAD——斯坦福问答数据集,被认为是阅读理解领域最好的数据集。
它孵化出了如今最前沿的模型,这些模型在回答问题的准确性上已经达到了人类的水平。
陈为 6篇
陈为是浙江大学计算机学院。

2021年的趋势——抱团取暖
抱团取暖也即是说2021年每篇论文有了更多的合作者和组织机构。
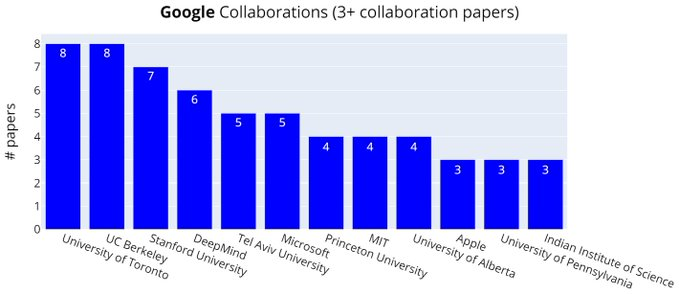
谷歌的共同论文合作者:多伦多大学(盲猜是因为Hinton老爷子)、UC伯克利大学排在前列。
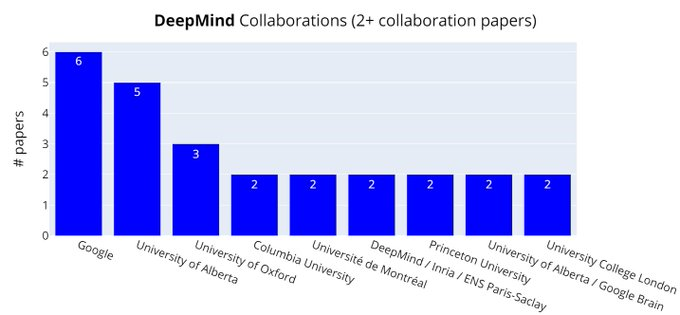
DeepMind的共同论文合作者:谷歌、阿尔伯塔大学排在前列。
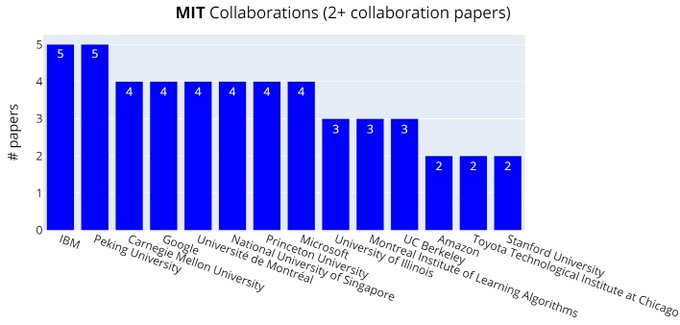
MIT的论文共同合作者:IBM、北京大学排在前列。
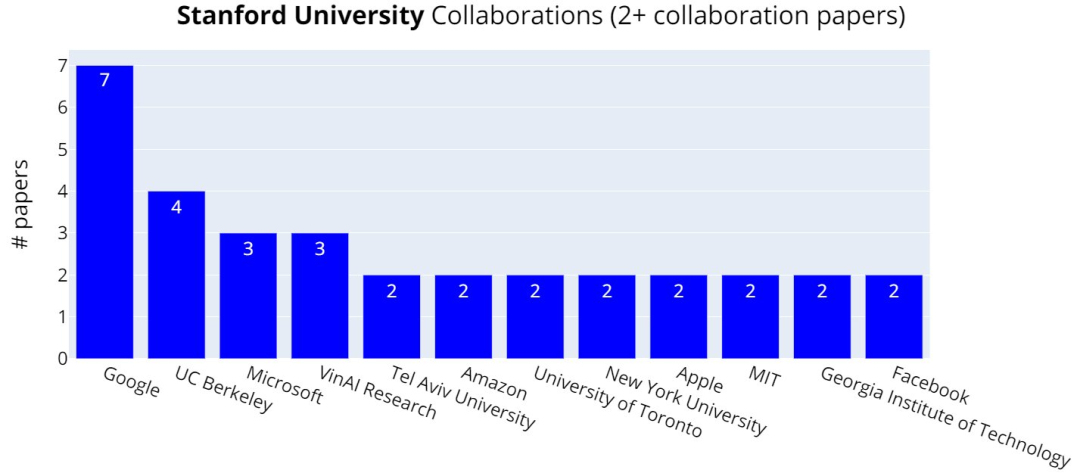
斯坦福大学的论文共同合作者:谷歌、UC伯克利排在前列。
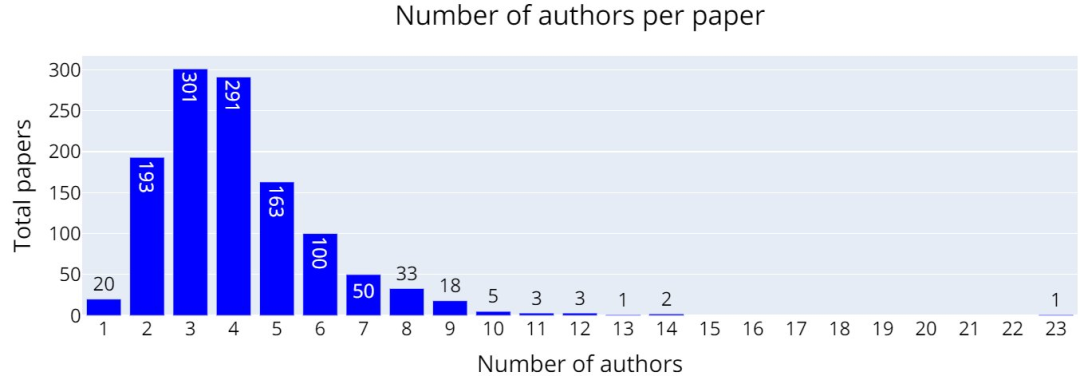
下图是每篇论文中出现的作者数量,可以看出3篇和4篇的最多,分别达到了301篇、291篇(去年则是259篇)。
另外今年有多达266篇论文中出现了3个不同组织机构的合作,去年则是195篇。
且今年有多达106篇论文有出现了4个不同组织机构的合作,去年则是64篇。
参考链接:
https://twitter.com/SergeyI49013776/status/1400377048435200001
编辑:王菁
校对:汪雨晴

这篇关于ICML 2021论文接收大排行!谷歌霸榜,国内北大第一、清华第二,华人学者表现亮眼.........的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




