本文主要是介绍【python机器学习】python电商数据K-Means聚类分析可视化(源码+数据集+报告)【独一无二】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化【获取源码+商业合作】
👉荣__誉👈:阿里云博客专家博主、51CTO技术博主
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。

系列文章目录
目录
- 系列文章目录
- 一、设计目的
- 1.1 论文展示
- 二、聚类分析及数据可视化
- 2.1. 数据总览
- 2.2. 买家实际支付金额分布
- 2.3. 订单状态分析
- 2.4. RFM分析
- 三、模型构建
- 3.1 模型构建
- 3.2. 特征选择
- 四、模型评估与对比
一、设计目的
客户价值分析是电商数据分析领域中一项重要的工作,其核心目标是深入了解和量化不同客户群体的行为,以识别和理解客户对企业的贡献程度。通过对每个客户的消费习惯、购买频率和交易金额等方面进行综合分析,企业可以更加精准地了解客户需求,制定更有效的市场策略和个性化推广方案。
-
深入了解客户行为: 客户价值分析可以帮助企业深入了解客户的购买行为、喜好和习惯。通过对顾客的历史交易数据进行分析,企业可以识别出购买频率高的忠诚客户、低频率的潜在客户以及不活跃的客户,为企业提供更全面的客户画像。
-
个性化服务和定制推广: 通过客户价值分析,企业能够识别出高价值客户,为这些客户提供个性化的服务和定制化的促销活动。这有助于提高客户满意度,增加客户忠诚度,进而提升客户生命周期价值。
-
提高市场营销效果: 了解客户的价值可以帮助企业更有针对性地制定市场营销策略。通过分析客户行为模式,企业可以优化广告投放、选择更具吸引力的促销方式,并更好地满足客户需求,提高市场营销的效果和ROI。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 电商聚类分析 ” 获取。👈👈👈
-
有效资源分配: 客户价值分析有助于企业更加有效地分配资源。通过识别高价值客户,企业可以重点关注这部分客户,提供更多资源和服务,以最大程度地发挥其潜在价值。同时,对于低价值客户,企业可以考虑降低资源投入,以避免浪费资源。
-
提升企业盈利能力: 通过客户价值分析,企业可以更好地了解客户对于不同产品或服务的购买偏好,从而精准定价、推出更有吸引力的产品组合,提高交易金额和利润水平。
-
预测客户未来价值: 基于历史数据的分析,企业可以建立客户生命周期价值模型,从而更好地预测客户未来的购买行为。这有助于企业提前采取措施,保持对客户的吸引力,并及时调整营销策略以最大化客户价值。
综合而言,客户价值分析为企业提供了深刻的洞察力,使其能够更灵活、更智能地运用资源,提高市场竞争力,实现长期可持续的盈利增长。通过对客户行为的理性解读,企业能够更好地把握市场动向,实现精准营销,从而更好地满足客户需求,促进企业的可持续发展。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 电商聚类分析 ” 获取。👈👈👈
1.1 论文展示
二、聚类分析及数据可视化
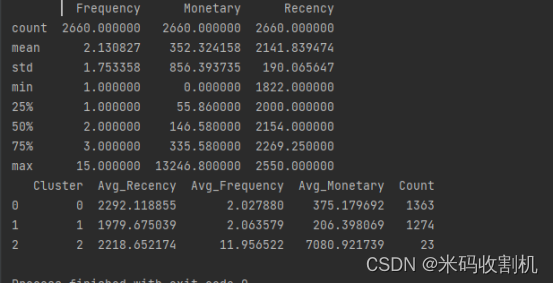
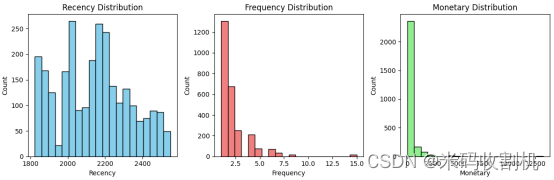
运用K-Means聚类方法对电商客户数据进行分类,基于客户价值的分析是通过对Recency(最近购买时间)、Frequency(购买频率)、Monetary(总购买金额)三个关键指标的聚类结果展开的。
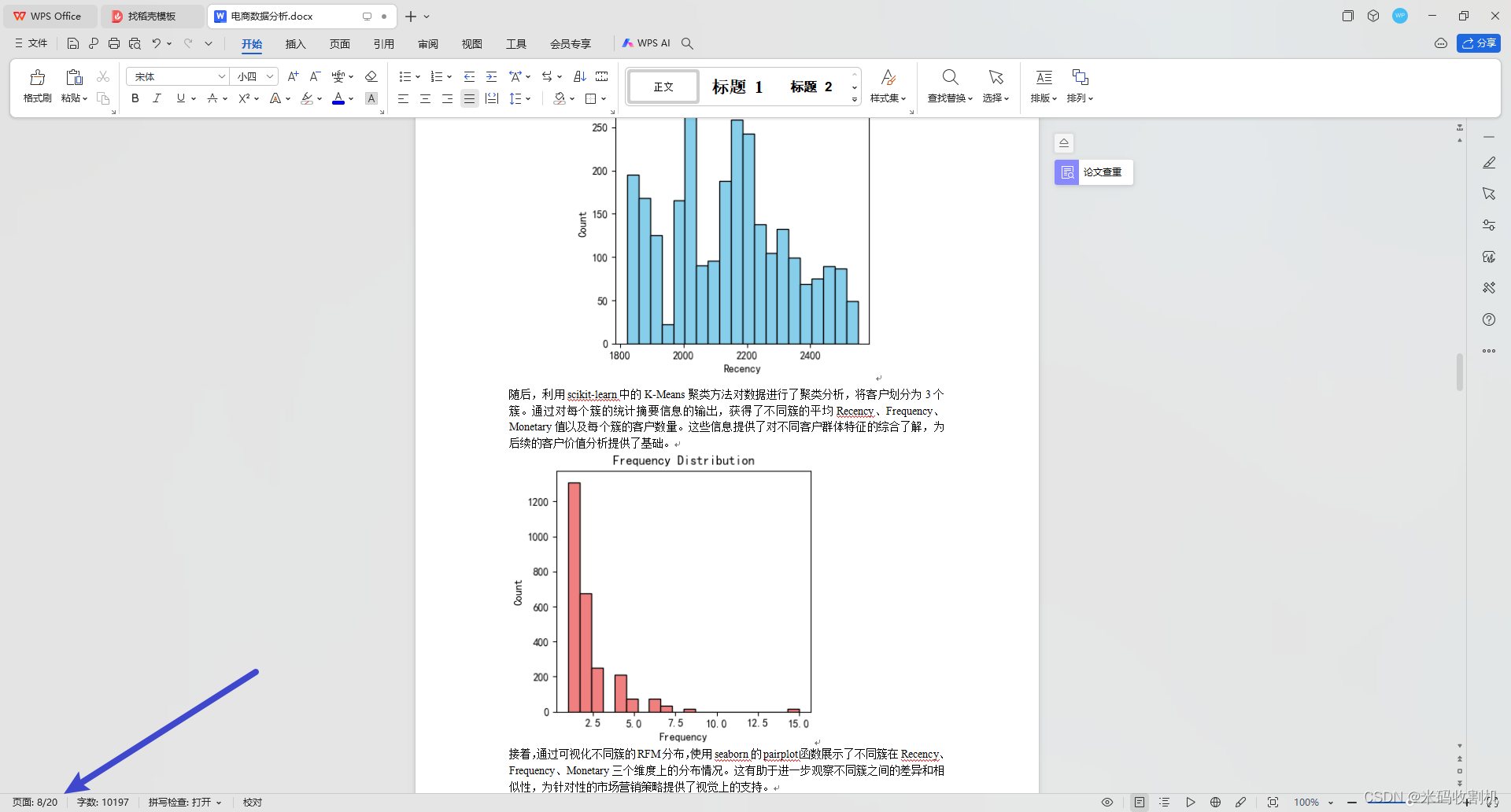
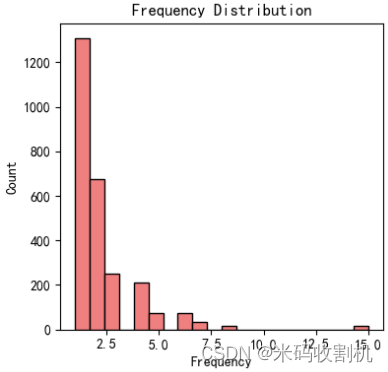
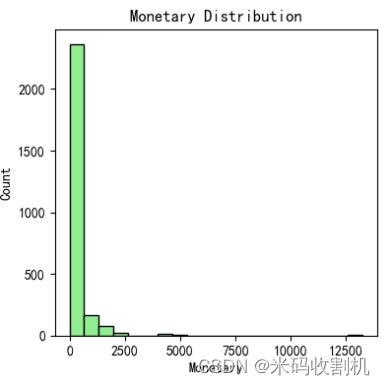
首先,通过对数据进行探索性分析(EDA),绘制了Recency、Frequency、Monetary的分布直方图,直观地展示了这些关键指标在数据集中的分布情况。这有助于了解客户行为的整体特征。
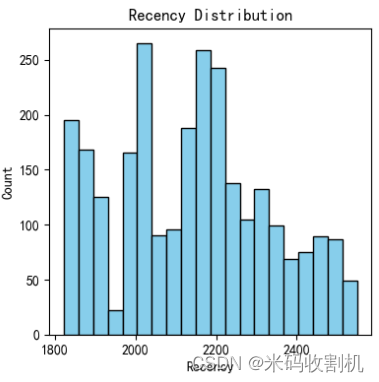
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 电商聚类分析 ” 获取。👈👈👈
随后,利用scikit-learn中的K-Means聚类方法对数据进行了聚类分析,将客户划分为3个簇。通过对每个簇的统计摘要信息的输出,获得了不同簇的平均Recency、Frequency、Monetary值以及每个簇的客户数量。这些信息提供了对不同客户群体特征的综合了解,为后续的客户价值分析提供了基础。
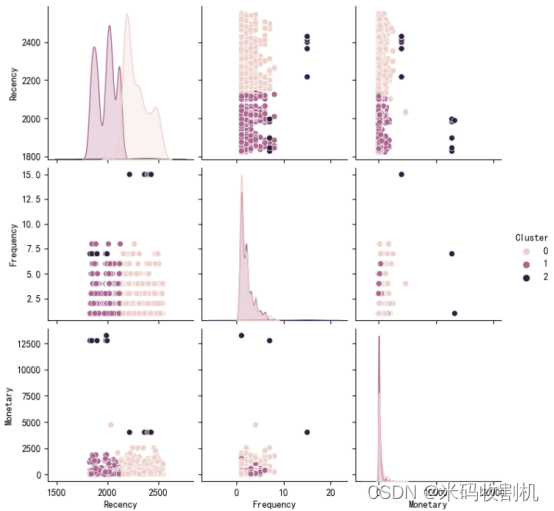
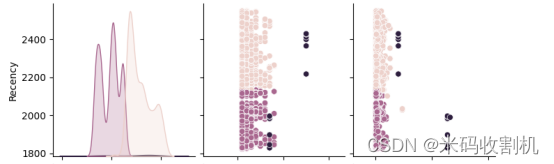
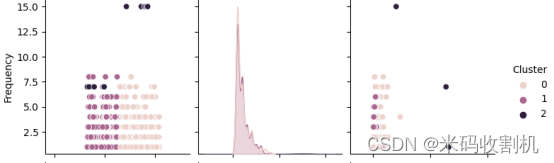
接着,通过可视化不同簇的RFM分布,使用seaborn的pairplot函数展示了不同簇在Recency、Frequency、Monetary三个维度上的分布情况。这有助于进一步观察不同簇之间的差异和相似性,为针对性的市场营销策略提供了视觉上的支持。
通过运用K-Means聚类,企业可以更好地理解和利用客户的差异,提高精准营销的效果,从而实现客户价值的最大化。这种数据驱动的客户分析方法不仅有助于洞察客户行为,还为企业制定战略决策提供了科学依据。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 电商聚类分析 ” 获取。👈👈👈
天猫电商交易数据作为电商领域的重要组成部分,蕴含着大量的信息和商业价值。通过对这一数据集的分析与可视化,我们可以深入了解消费行为、订单状态、交易趋势等关键信息,为业务决策提供有力支持。以下是对天猫电商交易数据的综合分析,结合代码片段进行详细讨论。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 电商聚类分析 ” 获取。👈👈👈
2.1. 数据总览
首先,我们通过代码截取了数据集的前20行,以快速了解数据的结构和字段。通过观察数据,我们可以发现包含有关买家、订单金额、商品数量、订单状态等多个方面的信息。
df = pd.read_excel("TB201812.xls")
df = df.head(20)
print(df)
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 电商聚类分析 ” 获取。👈👈👈
2.2. 买家实际支付金额分布
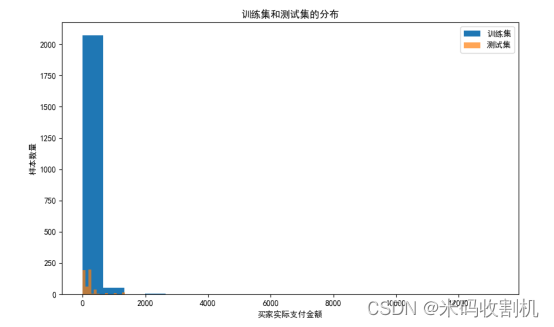
接下来,我们通过直方图可视化了训练集和测试集中“买家实际支付金额”的分布情况。这有助于我们了解订单金额的整体情况,以及训练集和测试集之间是否存在差异。
plt.figure(figsize=(10, 6))
plt.hist(train_data["买家实际支付金额"], bins=20, label="训练集")
plt.hist(test_data["买家实际支付金额"], bins=20, alpha=0.7, label="测试集")
plt.xlabel("买家实际支付金额")
plt.ylabel("样本数量")
plt.legend()
plt.title("训练集和测试集的分布")
plt.show()
通过观察直方图,我们可以看到订单金额主要集中在某个范围内,同时也发现了一些异常值。这为后续的异常值处理和业务决策提供了参考。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 电商聚类分析 ” 获取。👈👈👈
2.3. 订单状态分析
支持向量机模型的目标是预测订单状态,因此我们对订单状态进行了深入的分析。在代码中,我们通过混淆矩阵和分类报告评估了模型在测试集上的性能。
# 训练模型(在前文已经完成)
# 预测测试集结果
y_pred = svm_model.predict(X_test)# 计算混淆矩阵
confusion = confusion_matrix(y_test, y_pred)
print("混淆矩阵:")
print(confusion)# 输出模型准确率和分类报告
accuracy = accuracy_score(y_test, y_pred)
print("模型准确率:", accuracy)print("分类报告:")
print(classification_report(y_test, y_pred))
通过混淆矩阵和分类报告,我们可以详细了解模型在不同订单状态上的表现,包括准确率、召回率、F1值等指标。这有助于确定模型的优势和劣势,为进一步优化模型提供方向。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 电商聚类分析 ” 获取。👈👈👈
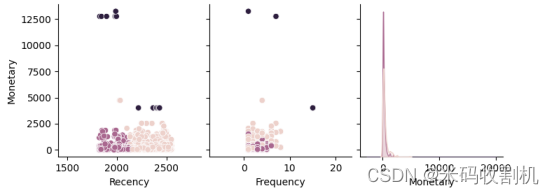
2.4. RFM分析
在电商领域,RFM(最近一次购买距今的天数、购买频率、总购买金额)分析是一种常见的用户行为分析方法。在代码中,我们对RFM数据进行了探索性分析和可视化。
# 读取数据并进行RFM分析(在前文已经完成)
# 绘制RFM分布图
sns.pairplot(data=rfm_data, hue='Cluster', vars=['Recency', 'Frequency', 'Monetary'], diag_kind='kde')
plt.show()
通过RFM分布图,我们可以清晰地看到不同聚类簇在Recency、Frequency和Monetary上的分布情况。这有助于我们理解不同用户群体的消费行为和价值,为精细化运营提供了依据。
通过时间趋势分析,我们可以发现交易活动的高峰和低谷,预测未来的销售趋势,为库存管理和营销活动的制定提供指导。
三、模型构建
3.1 模型构建
首先,我们需要准备电商订单数据,并进行必要的数据预处理。在代码中,我们使用pandas库读取Excel文件,截取了前20行以进行快速查看。然后,我们划分了训练集和测试集,以便后续模型训练和评估。
import pandas as pdfrom sklearn.model_selection import train_test_split
# 读取Excel文件
df = pd.read_excel("TB201812.xls")
df = df.head(20)
# 样本数量
total_samples = len(df)
# 划分训练集和测试集
train_size = int(total_samples * 0.8)
test_size = total_samples - train_sizetrain_data, test_data = train_test_split(df, test_size=test_size, random_state=42)
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 电商聚类分析 ” 获取。👈👈👈
3.2. 特征选择
在电商订单状态预测中,选择合适的特征对模型性能至关重要。在这里,我们选择了“买家实际支付金额”和“宝贝总数量”作为输入特征,以及“订单状态”作为输出标签。
# 选择特征和标签
target_column = "订单状态"
feature_columns = ["买家实际支付金额", "宝贝总数量"]X_train = train_data[feature_columns]
y_train = train_data[target_column]
X_test = test_data[feature_columns]
y_test = test_data[target_column]
3. 模型选择与训练
在这个案例中,我们选择了支持向量机(SVM)作为模型。SVM适用于处理分类问题,并且在处理高维度数据时表现良好。在代码中,我们使用SVC类创建了一个支持向量机分类器,选择了线性核函数,并对模型进行了训练。
pythonCopy code
from sklearn.svm import SVC
# 选择支持向量机(SVM)模型
svm_model = SVC(kernel='linear', random_state=42)
# 训练模型
svm_model.fit(X_train, y_train)
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 电商聚类分析 ” 获取。👈👈👈
四、模型评估与对比
主要进行了支持向量机(SVM)模型的评估,评估指标包括混淆矩阵、准确率和分类报告。以下是对每个部分的详细分析:
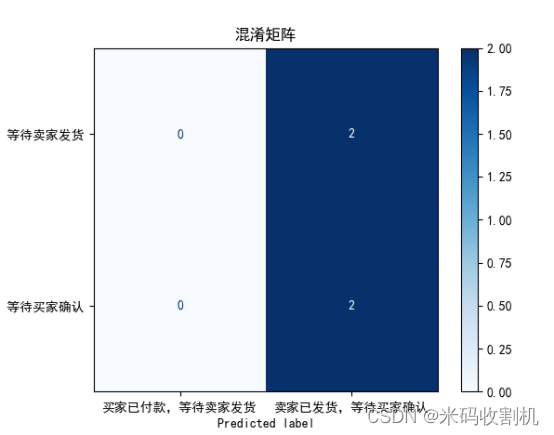
- 混淆矩阵的计算
# 计算混淆矩阵
confusion = confusion_matrix(y_test, y_pred)
print("混淆矩阵:")
print(confusion)
在这里,使用confusion_matrix函数计算了模型的混淆矩阵。混淆矩阵是一个二维矩阵,用于展示模型在不同类别上的性能。对于二分类问题,混淆矩阵包括真正例(True Positive,TP)、真负例(True Negative,TN)、假正例(False Positive,FP)和假负例(False Negative,FN)。
- 可视化混淆矩阵
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 电商聚类分析 ” 获取。👈👈👈
# 可视化混淆矩阵
plot_confusion_matrix(svm_model, X_test, y_test, cmap=plt.cm.Blues)
plt.title('混淆矩阵')
plt.show()

3. 分类报告
print("分类报告:")
print(classification_report(y_test, y_pred))
分类报告提供了更详细的模型性能指标,包括精确度(Precision)、召回率(Recall)、F1值等。classification_report函数生成了一个包含这些指标的报告,并将其打印输出。
通过以上评估步骤,可以全面了解模型在测试集上的性能。混淆矩阵提供了每个类别的详细分类情况,准确率衡量了整体的正确分类率,而分类报告则对每个类别的性能进行了更详细的分析。这些评估指标有助于判断模型的泛化能力和对不同类别的区分能力。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 电商聚类分析 ” 获取。👈👈👈
总体而言,通过RFM模型的构建和K-Means聚类分析,成功挖掘了电商数据中潜在的客户价值。这不仅有助于企业更好地理解和满足客户需求,提高客户满意度和忠诚度,同时也为企业在市场营销、资源分配和产品定价等方面提供了科学的依据。这种数据驱动的价值挖掘方法不仅可以提高企业运营效率,还能够为企业创造更为可持续的竞争优势。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 电商聚类分析 ” 获取。👈👈👈
这篇关于【python机器学习】python电商数据K-Means聚类分析可视化(源码+数据集+报告)【独一无二】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



