本文主要是介绍基础的unicorn模拟简介与库函数调用方案与代码实例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
运行环境:python
基本的导入:from unicorn import *
简介
1. unicorn对象的初始化:
UC = Uc(unicorn_const.UC_ARCH_X86,unicorn_const.UC_MODE_16)
Uc接收的二值分别指定将模拟的架构和程序位数。后续操作的寄存器(如rax、eax、ax之分别)请严格匹配程序位数。
2. 内存映射
# 基地址
BASE_ADDR = 0x0
# 内存
MEM_SIZE = 16 * 1024
UC.mem_map(BASE_ADDR, MEM_SIZE)
mem_map将为UC标记、分配一段“有效”的空间,超出这个空间的地址操作将可能报Invalid memory operation (UC_ERR_READ_UNMAPPED)错误。
3. 段初始化/内存写
BASE_ADDR = 0x0
MEM_SIZE = 16 * 1024
MEM = b'0' * MEM_SIZE
UC.mem_map(BASE_ADDR, MEM_SIZE)
UC.mem_write(BASE_ADDR, MEM)
这一段是内存分配的继续。unicorn并不会在map后对空间初始化。因此这里对其、对整段分配的内存空间用0覆写,避免可能存在的问题。
段分配前需要获取目标段的物理偏移和虚拟地址,请用PE软件如DIE查看。
代码:
RDATA_OFFSET = 0x6000
RDATA_LEN = 0x800
FILE = open(f".\\test.bin", "rb")
FILE.seek(RDATA_OFFSET)
RDATA = FILE.read(RDATA_LEN)
UC.mem_write(BASE_ADDR + RDATA_OFFSET, RDATA)
4. 堆栈分配
我一般是在代码段后追加一小段,或是将内存空间的末尾作为栈区。这里要注意,分配的堆栈空间可以相对自由,但要分配好sp寄存器的值。
STACK = b'0' * 1024STACK_POINT = BASE_ADDR + CODE_LEN + 1024UC.reg_write(unicorn.x86_const.UC_X86_REG_SP, STACK_POINT)UC.mem_write(STACK_POINT, STACK)
同样,这里堆栈区进行了一次初始化。
5. 寄存器分配
STACK_POINT = BASE_ADDR + CODE_LEN + 1024
UC.reg_read(unicorn.x86_const.UC_X86_REG_IP)
UC.reg_write(unicorn.x86_const.UC_X86_REG_SP, STACK_POINT)
在引入了unicorn包后,调用寄存器常量可以用unicorn.x86_const.的方式,也可以直接:mips_const.UC_MIPS_REG_15
需要注意的是:
python包可能默认不包含riscv常量,需要自己引入
# Unicorn Python bindings, by Nguyen Anh Quynnh <aquynh@gmail.com>from . import arm_const, arm64_const, mips_const, sparc_const, m68k_const, x86_constfrom .unicorn_const import *from .unicorn import Uc, uc_version, uc_arch_supported, version_bind, debug, UcError, __version__
6. hook与trace
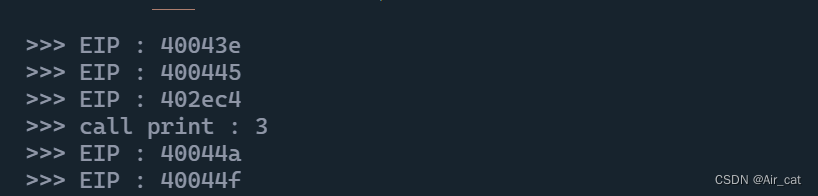
def trace(mu: Uc, address, size, data):md = cs.Cs(cs.CS_ARCH_X86, cs.CS_MODE_16)EIP = mu.reg_read(unicorn.x86_const.UC_X86_REG_EIP)CODE = [i for i in md.disasm(mu.mem_read(address, size), size)][0]print(">>> EIP : %x" % (EIP), CODE.mnemonic, CODE.op_str)
这是一个基本的unicorn trace回调函数模板。注意这里,这个是“trace”的回调函数模板。unicorn对于hook不同的情况,需要定制不同参数的回调函数。如:
UC.hook_add(UC_HOOK_CODE, trace) # hook每一步指令,单步traceUC.hook_add(UC_HOOK_MEM_FETCH_UNMAPPED, printf)def trace(mu: Uc, address, size, data):EIP = mu.reg_read(unicorn.x86_const.UC_X86_REG_EIP)CODE = [i for i in md.disasm(mu.mem_read(address, size), size)][0]print(">>> EIP : %x" % (EIP), CODE.mnemonic, CODE.op_str)def printf(mu: Uc, access, address, size, value, user_data):ESP = mu.reg_read(unicorn.x86_const.UC_X86_REG_ESP)# 这里的值是立即数VALUE = bytes(mu.mem_read(ESP + 8, 4))VALUE = int.from_bytes(VALUE, 'little')# 格式是指针,地址归属rdata段FORMAT = mu.mem_read(int.from_bytes(bytes(mu.mem_read(ESP + 4, 4)), 'little'), 4)# 检查是哪种格式if bytes(FORMAT)[0:2] == b'%d':print(">>> call print : %x" % (VALUE))# 从printf的调用处重新执行OLD_IP = mu.mem_read(ESP, 4) # 获得返回地址OLD_IP = int.from_bytes(bytes(OLD_IP), 'little')mu.emu_stop()try:mu.emu_start(OLD_IP, 2 * 1024 * 1024)except UcError as e:print("ERROR: %s" % e)
7. 启动
START = ADDRESS + 0x41Etry:UC.emu_start(START, 2 * 1024 * 1024)except UcError as e:print("ERROR ", e)
emu_start的第二个参数可以认为是执行的截止地址,可以匹配最终执行地址,也可以直接写到内存结束等error。
unicorn执行外部库函数
不建议用unicorn模拟调用外部函数的程序。
但如果实在要执行的话,这里有几个思路:
①使用pywin调用库函数,代替原函数。
②使用ctypes调用库函数,代替原函数。
③hook指定地址|trace时做检查。
④hook地址异常。
实例:
#include<stdio.h>int main(){int a,b;a = 1;b = 2;a += b;printf("%d",a);}
from unicorn import *def test():# 一些常量定义,感觉可以挪到全局ADDRESS = 0x400000CODE_LEN = 0x3200RDATA_LEN = 0x800RDATA_OFFSET = 0x6000MEM_SIZE = 4 * 1024 * 1024MEM = b'0' * MEM_SIZE# 读取目标程序FILE = open(f".\\test_1.exe", "rb")# 设置代码段UC = Uc(unicorn_const.UC_ARCH_X86, unicorn_const.UC_MODE_32)UC.mem_map(ADDRESS, MEM_SIZE)FILE.seek(0x400)CODE = FILE.read(CODE_LEN)UC.mem_write(ADDRESS, MEM) # 对MEM空间进行初始化,空间管理严格的话这里其实也不用初始化UC.mem_write(ADDRESS, CODE) # 写代码段# 设置RDATA段FILE.seek(0x3800)RDATA = FILE.read(RDATA_LEN)UC.mem_write(ADDRESS + RDATA_OFFSET, RDATA)# 设置栈区STACK = b'0' * 1024STACK_POINT = ADDRESS + CODE_LEN + 1024UC.reg_write(unicorn.x86_const.UC_X86_REG_ESP, STACK_POINT)UC.mem_write(STACK_POINT, STACK)# 设置hookUC.hook_add(UC_HOOK_CODE, trace)UC.hook_add(UC_HOOK_MEM_FETCH_UNMAPPED, printf)# 模拟执行START = ADDRESS + 0x41Etry:UC.emu_start(START, 2 * 1024 * 1024)except UcError as e:print("ERROR ", e)def trace(mu: Uc, address, size, data):EIP = mu.reg_read(unicorn.x86_const.UC_X86_REG_EIP)print(">>> EIP : %x" % (EIP))def printf(mu: Uc, access, address, size, value, user_data):ESP = mu.reg_read(unicorn.x86_const.UC_X86_REG_ESP)# 这里的值是立即数VALUE = bytes(mu.mem_read(ESP + 8, 4))VALUE = int.from_bytes(VALUE, 'little')# 格式是指针,地址归属rdata段FORMAT = mu.mem_read(int.from_bytes(bytes(mu.mem_read(ESP + 4, 4)), 'little'), 4)# 检查是哪种格式if bytes(FORMAT)[0:2] == b'%d':print(">>> call print : %x" % (VALUE))# 从printf的调用处重新执行OLD_IP = mu.mem_read(ESP, 4) # 获得返回地址OLD_IP = int.from_bytes(bytes(OLD_IP), 'little')mu.emu_stop()try:mu.emu_start(OLD_IP, 2 * 1024 * 1024)except UcError as e:print("ERROR: %s" % e)if __name__ == "__main__":test()# 执行的代码:'''.text:0040141E C7 44 24 1C 01 00 00 00 mov dword ptr [esp+1Ch], 1.text:00401426 C7 44 24 18 02 00 00 00 mov dword ptr [esp+18h], 2.text:0040142E 8B 44 24 18 mov eax, [esp+18h].text:00401432 01 44 24 1C add [esp+1Ch], eax.text:00401436 8B 44 24 1C mov eax, [esp+1Ch].text:0040143A 89 44 24 04 mov [esp+4], eax.text:0040143E C7 04 24 44 60 40 00 mov dword ptr [esp], offset Format ; "%d".text:00401445 E8 7A 2A 00 00 call _printf.text:00401445.text:0040144A B8 00 00 00 00 mov eax, 0.text:0040144F C9 leave.text:00401450 C3 retn'''
这篇关于基础的unicorn模拟简介与库函数调用方案与代码实例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




