本文主要是介绍ShardingSphere再回首,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
概念:
连接:通过协议 方言及库存储的适配,连接数据和应用,关注多模数据苦之间的合作
增量:抓取库入口流量题提供重定向, 流量变形(加密脱敏)/鉴权/治理(熔断限流)/分析等
可插拔:微内核
DDL:create table/index | alter table |drop table |truncate table|drop index/table 表结构
DML:insert update delete 表数据的操作
DQL:select
DCL:grant分权限 revoke废除权限
分表分库
数据分片:按某维度将存放在单一数据库中的数据分散地存放至多个数据库或表
垂直分片
专库专用,按业务
水平分片
通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中
流程
Standard 内核流程:SQL 解析 => SQL 路由 => SQL 改写 => SQL 执行 => 结果归并,用于处理标准分片场景下的 SQL 执行
Federation 执行引擎流程:SQL 解析 => 逻辑优化 => 物理优化 => 优化执行 => Standard 内核流程,在优化执行阶段依赖Standard内核流程,对优化后的逻辑 SQL 进行路由、改写、执行和归并
sql解析:词法/语法解析,词法解析器SQ拆分不可再拆的词 Token,词法解析器 理解 sql,解析上下文(表/选择项/排序项/分组项/聚合函数/分页信息/查询条件/占位符标记)
sql路由:分片/广播,解析上下文匹配分片策略,生成路由路径
sql改写:在真实数据可以执行的语句,正确性/优化改写
sql执行:多线程执行器异步执行
结果归并:结果由统一的JDBC接口输出,流式归并/内存归并/装饰者模式追加归并
流式归并:以结果集游标下移进行结果归并,省内存 减少垃圾回收
查询优化:Federation提供,优化关联/子查询,跨库分布式查,关系代数优化查询计划,最优计划查询出结果
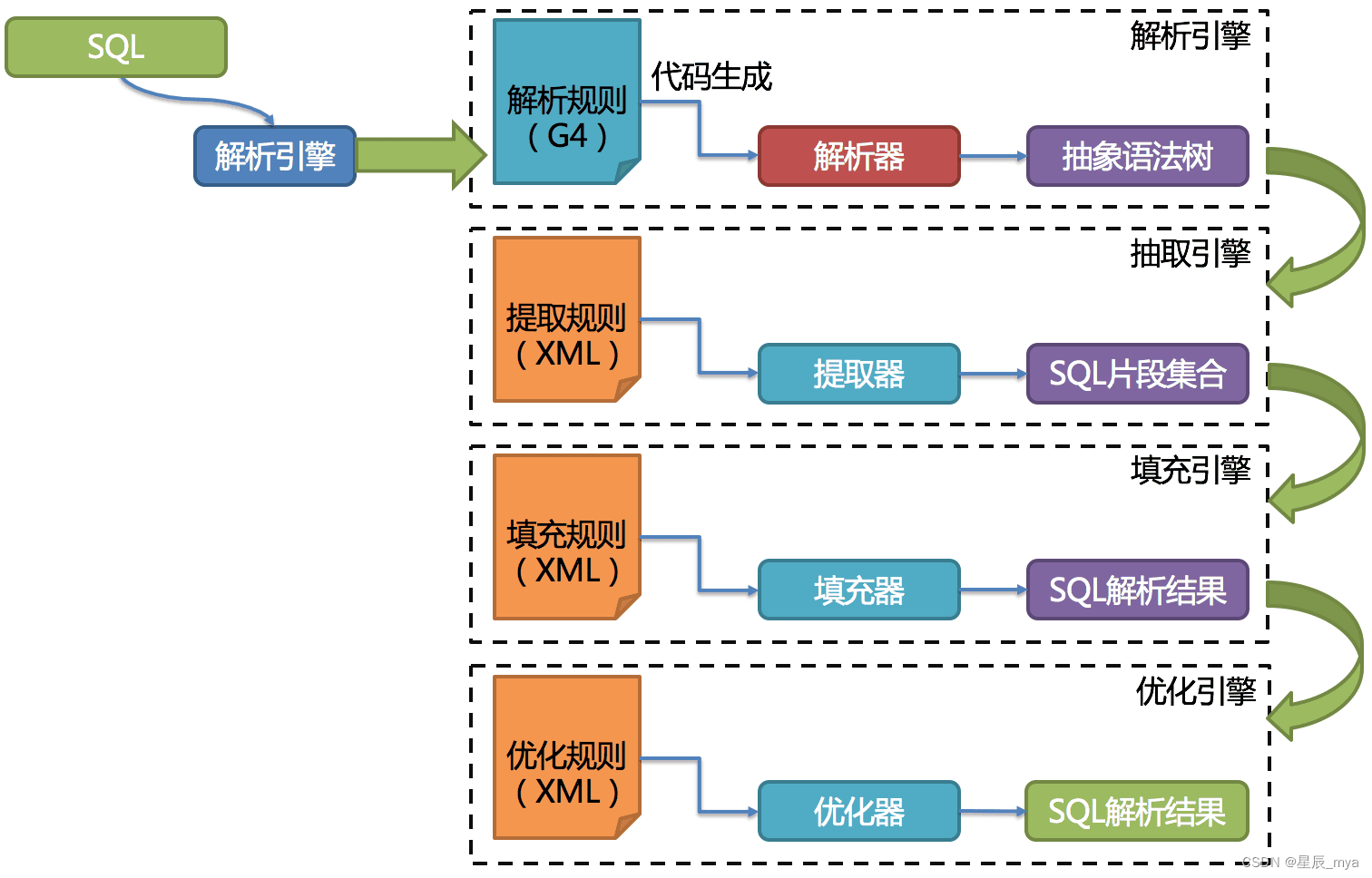
解析引擎
抽象语法树
sql解析阶段的token,再据不同数据库方言提供的字典,将其归类为关键字 表达式 字面量 操作符,语法解析器将sql转换为抽象语法树
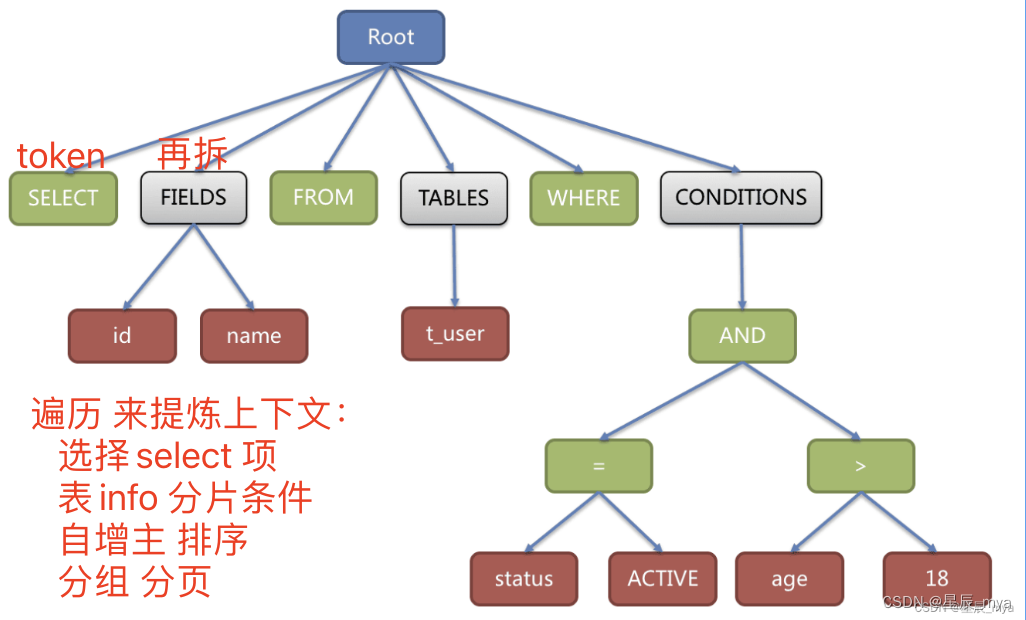
解析过程不可逆,token按原本顺序依次解析,性能高
sql解析引擎
3.0 ANTLR作为SQL解析的引擎(兼容sql),据DDL -> TCL -> DAL –> DCL -> DML –>DQL依次替换原有的解析引擎,慢 需要搭配PreparedStatement预编译
路由引擎
上下文匹配数据库/表的分片策略,生成路由
携带分片键sql,分片键不同划分单片路由(=)多片路由(in)范围路由(between)
不携带 分片键 的广播路由
分片策略
内置:尾数取模 哈希 范围 标签 时间
用户配置:需求定制复合分片策略
分片路由
直接路由:分库不分表 hint指定路由到库,避免sql解析 结果归并;可子查询 自定义函数等任意sql
标准路由:推荐,不含关联查 仅绑定表间关联的sql,=单表 between/in不定 sql拆分数目与单表一致
笛卡尔积路由:复杂 非绑定表间关联查询需拆解为笛卡尔积组合执行 t0t0 t0t1 t1t0 t1t1
广播路由
- 全库表:库中逻辑表相关的all操作,DQL DML DDL,all库all表匹配逻辑表和真实表名 执行
- 全库:对库操作,set/TCL事务控制语句,据逻辑名字遍历符合名字匹配的真实库
- 全实例:DCL 每个库只执行一次
- 单播:获取真实的表信息 任意库的任意真实表即可
- 阻断:屏蔽sql对数据库的操作
改写引擎
逻辑SQL改写在真实数据库中可正确执行的SQL:正确性改写 优化改写

流式归并优化:group by 的sql增加order by和分组项相同的排序项/顺序
执行引擎
执行引擎的目标是自动化的平衡资源控制与执行效率
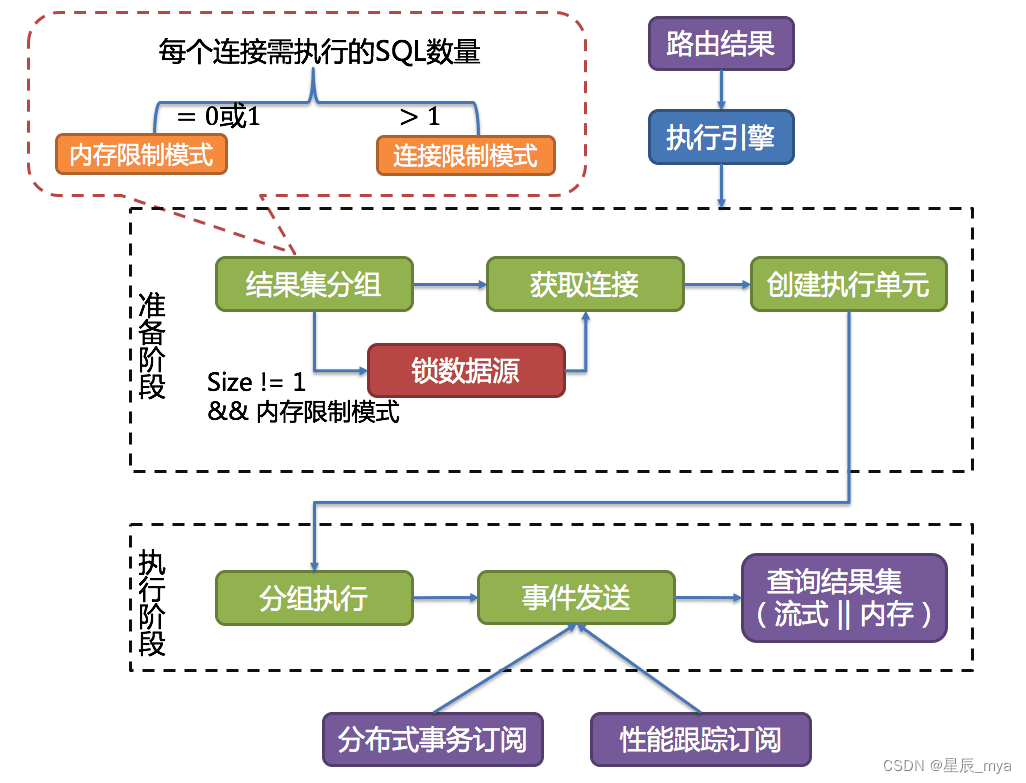
连接模式
每个分片查询维持一个独立的数据库连接:利用多线程提供执行效率/并行处理io消耗/避免过早将结果放到内存/持有查询结果集游标位置的引用
无法保证每个分片持有独立数据库连接,在复用该库连接获取下一张分表查询结果集之前,当前查询结果集全数加载至内存,流式退化为内存归并
抉择:对库连接资源控制保护 更优归并模式对中间件内存资源节省
内存限制模式
不限制一次操作所耗费的数据库连接数量,多线程并发处理,执行效率最大化
且在sql满足条件情况下,优先选择流式归并,防止内存溢出 避免频繁垃圾回收
OLAP:提供吞吐量,联机分析处理 复杂计算和统计 数据分析预测
连接限制模式
控制连接数量,唯一连接串行执行处理,分片散落不同数据库 多线程处理不同库的操作 一个库一个连接,防止对一次请求对数据库连接占用过多所带来的问题,内存归并
OLTP(联机事务) 实时性 事务处理数据操作
带分片键 路由到单一分片 保证库资源被更多应用使用到
自动化执行引擎
由执行引擎根场景自动选择最优的执行方案
连接模式的选择粒度细化至每一次SQL的操作
据路由结果,实时演算和权衡,自主选择:资源 效率最优
仅配置maxConnectionSizePerQuery一次查询时每个数据库所允许使用的最大连接数
准备阶段
结果集分组 执行单元执行两步
- sql路由结果按数据源的名称分组
- 获得在数据库实例在maxConnectionSizePerQuery范围,一连接需执行的SQL路由结果组,计算出本次请求的最优连接模式

避免死锁:同步获取连接,创建执行单元 原子性一次性获取本次sql需要all库连接
- 避免锁定一次性只需要1个库连接的操作,不需锁定,OLTP分片键路由唯一节点 读写分离
- 内存限制模式才资源限定,连接限制all结果集在内存后释放连接资源 不会死锁
执行阶段
分组执行
准备执行阶段生成的执行单元下发到底层并发执行引擎,执行过程中关键步骤发送事件 执行引擎仅关注事件发布 订阅感兴趣的并处理
归并结果
内存归并结果集或流式归并结果集,将其传递至结果归并引擎
归并引擎
结果归并:从各个数据节点获取的多数据结果集,组合成结果集并正确的返回给请求客户端
返回结果集方式归并,减少内存消耗
流式归并:每一次从结果集中获取到的数据,能通过逐条获取的方式返回正确的单条数据,与数据库原生的返回结果集的方式契合
遍历、排序以及流式分组都属于流式归并的一种
内存归并:需将结果集的all数据都遍历并存储在内存,通过统一的分组、排序及聚合等计算,再将其封装成逐条访问的数据结果集返回
装饰者归并:对all结果集归并进行统一的功能增强,分页归并和聚合归并这2种类型
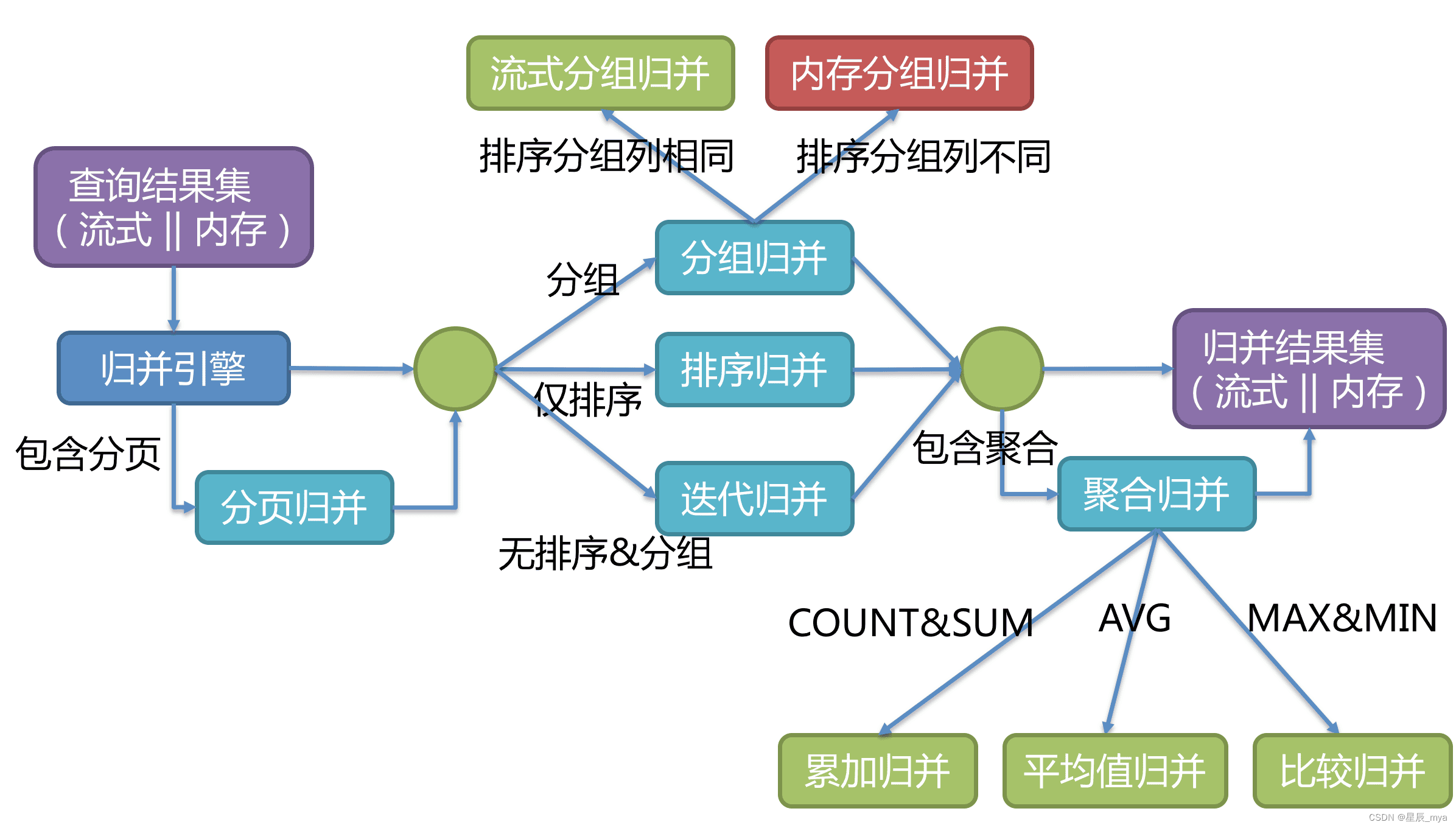
遍历:将多个数据结果集合并为一个单向链表
遍历完当前结果集,链表元素后移一位,继续遍历下一个数据结果集
排序:ORDER BY每个数据结果集自身是有序的,将结果集当前游标指向的数据值进行排序
将每个结果集的当前数据值进行比较(通过实现Java的Comparable接口),将其放入优先级队列, 获取下一条数据时,只需将队列顶端结果集的游标下移,并据新游标重新进入优先级排序队列找到自己的位置即可
???
分组:流式分组归并/内存分组归并
聚合:之前介绍的归并类的之上追加的归并能力,比较min max、累加sum count和求平均值avg
分页:通过结果集的next方法跳过无需取出的数据,不会将其存入内存
数据脱敏
完整、安全、透明化、低改造成本的数据加密整合解决方案
- 解析用户输入的SQL进行,依据用户提供的加密规则改写SQL,实现对原数据加密,将原文数据(可选)及密文数据同时存储到底层数据库
- 查询数据,从数据库中取出密文数据,并对其解密,将解密后的原始数据返回给用户。
- 自动化 & 透明化数据加密过程,无需关注数据加密的细节,像使用普通数据那样使用加密数据
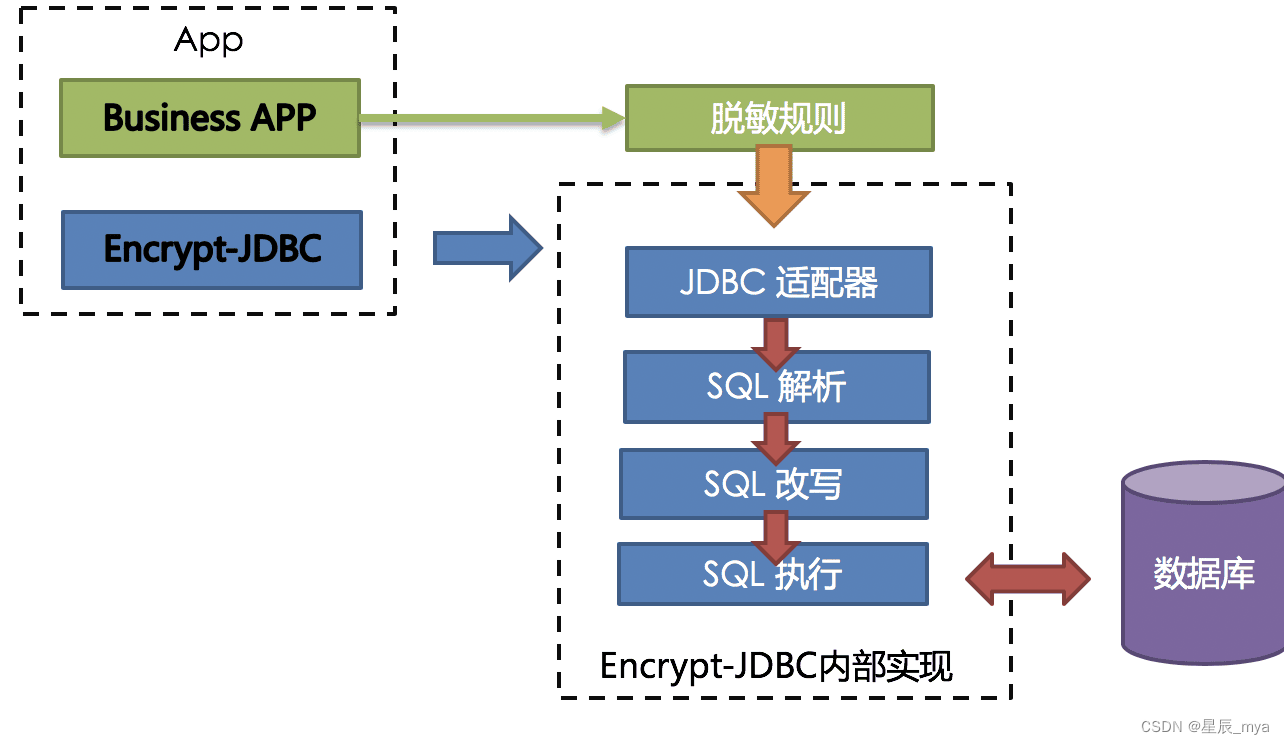
加密模块拦截 SQL ,语法解析器进行解析、理解 SQL 行为,依传入的加密规则,找出需加密的字段和所使用的加解密算法对目标字段进行加解密处理后,与底层数据库交互
在用户查询时,将密文从数据库中取出进行解密后返回给终端用户。 屏蔽对数据的加密解密处理过程
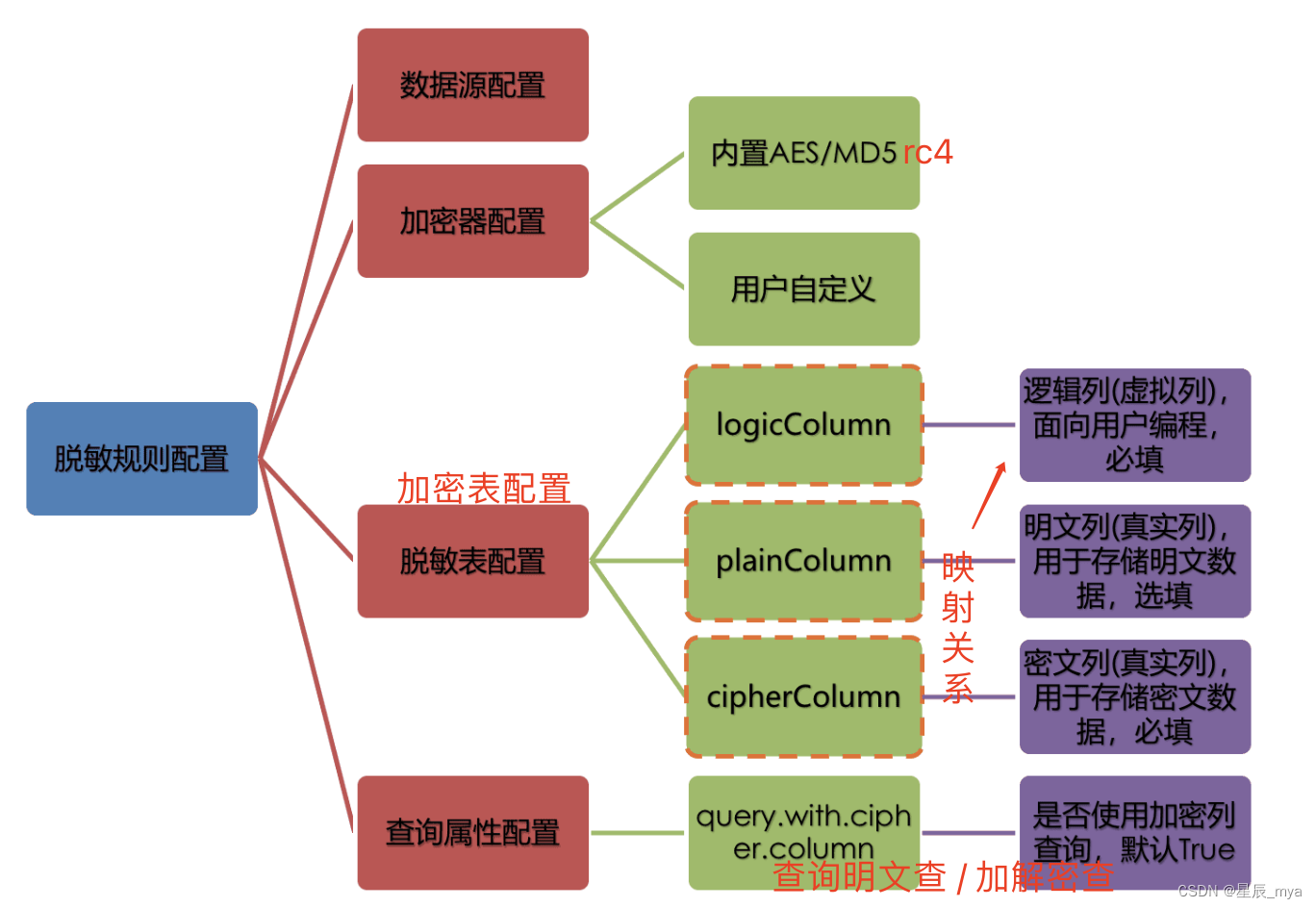
加密规则
加密处理过程
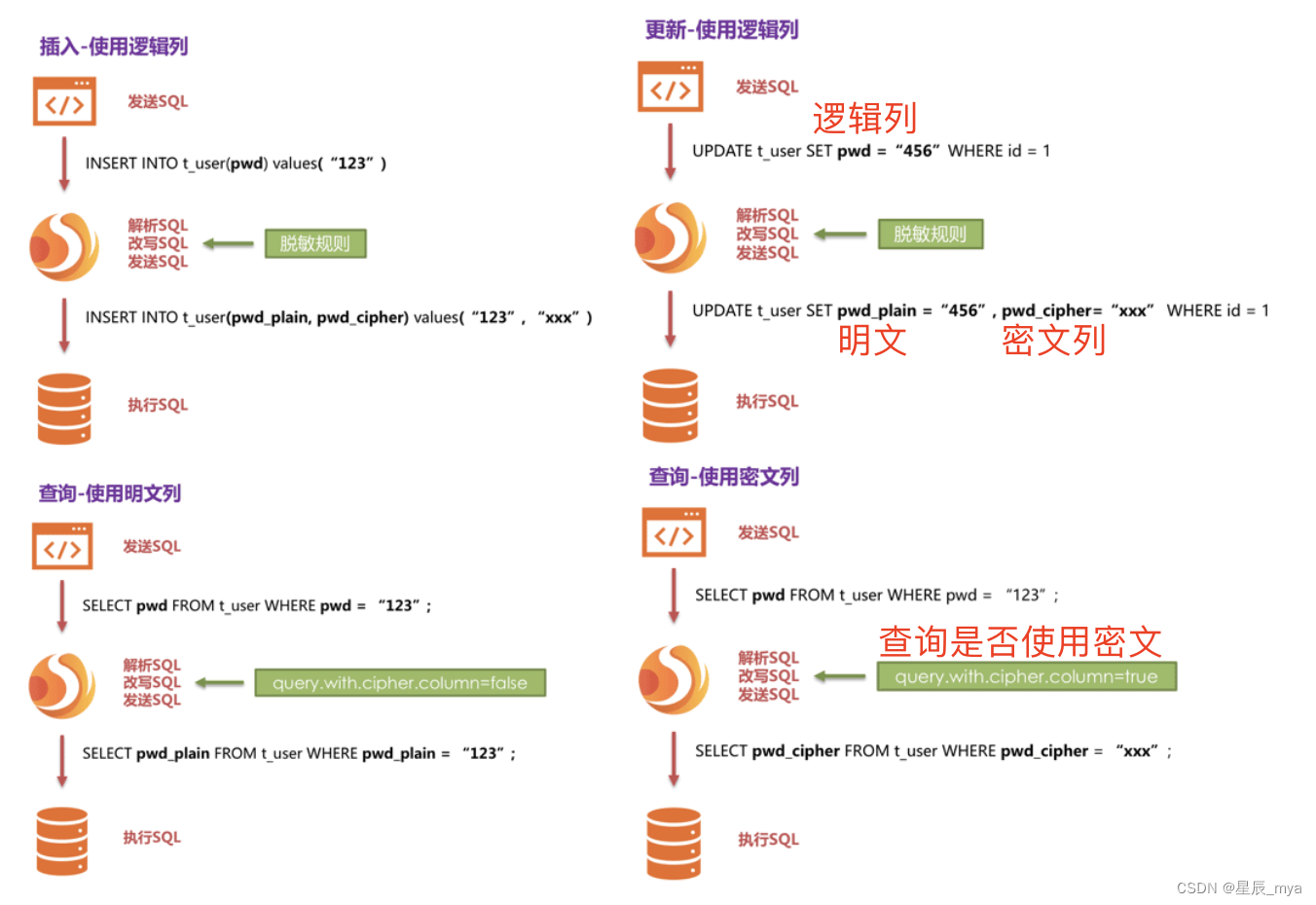
解决方案
新业务直接配置
老业务
新的数据 走配置 新增字段 自动赋值
旧数据 自行加密清洗
将明文删除,建立映射关系 底层使用密文处理
加密算法
EncryptAlgorithm
encrypt decrypt
insert/delete/update ,按配置 sql解析/改写/路由 encrypt加密 存储到库
查询decrypt从库取出加密 逆向解密,原始数据返回
md5 不可逆,aes可选,rc4可逆
QueryAssistedEncryptAlgorithm
相同的数据,库中也应该是不一样的
encrypt()阶段,设置某个变动种子,如时间戳。
针对原始数据+变动种子组合的内容进行加密,加密数据是不一样的
decrypt()可依据之前规定的加密算法,利用种子数据进行解密
辅助查询列queryAssistedEncrypt
另一种方式加密原始数据,针对原始数据相同的数据,产生的加密数据是一致的
事务
xa
X/OPEN组织定义的DTP模型抽象的 AP(应用程序), TM(事务管理器)和 RM(资源管理器)
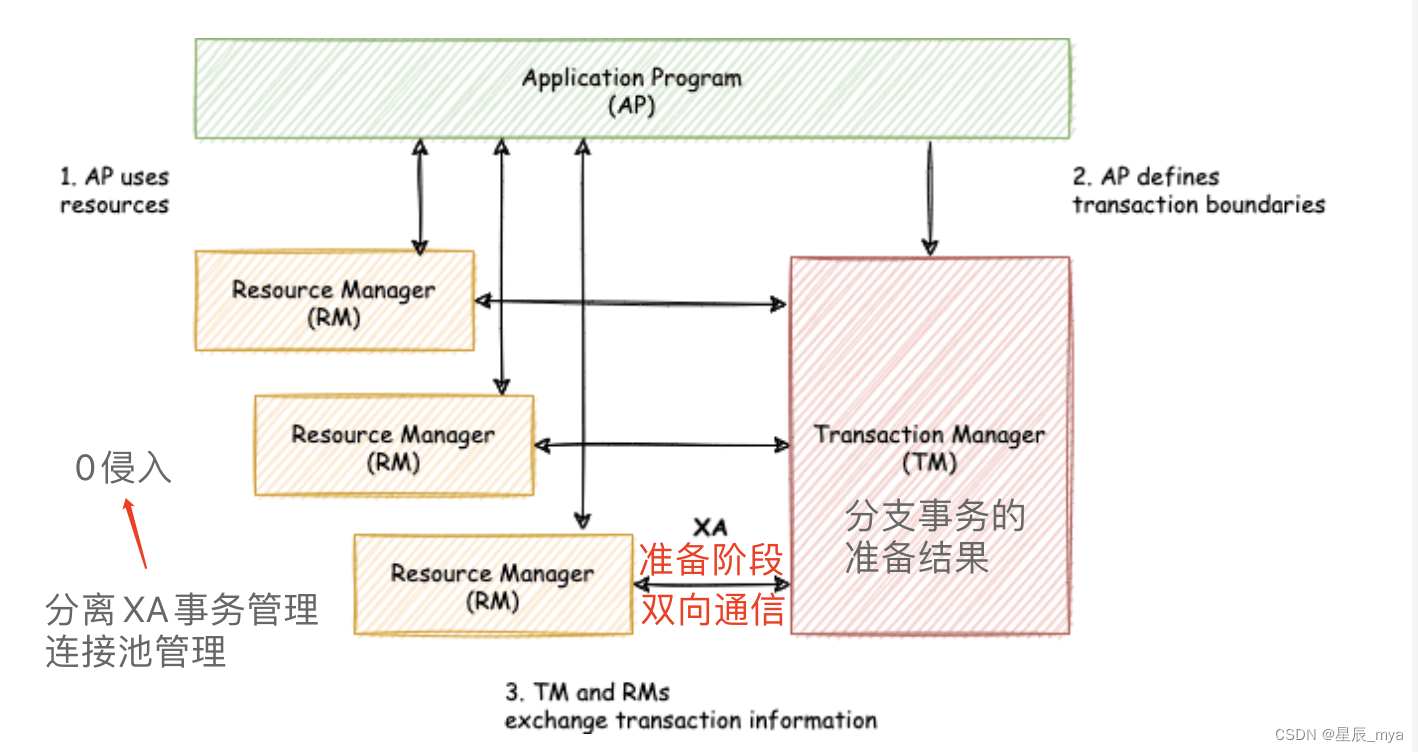
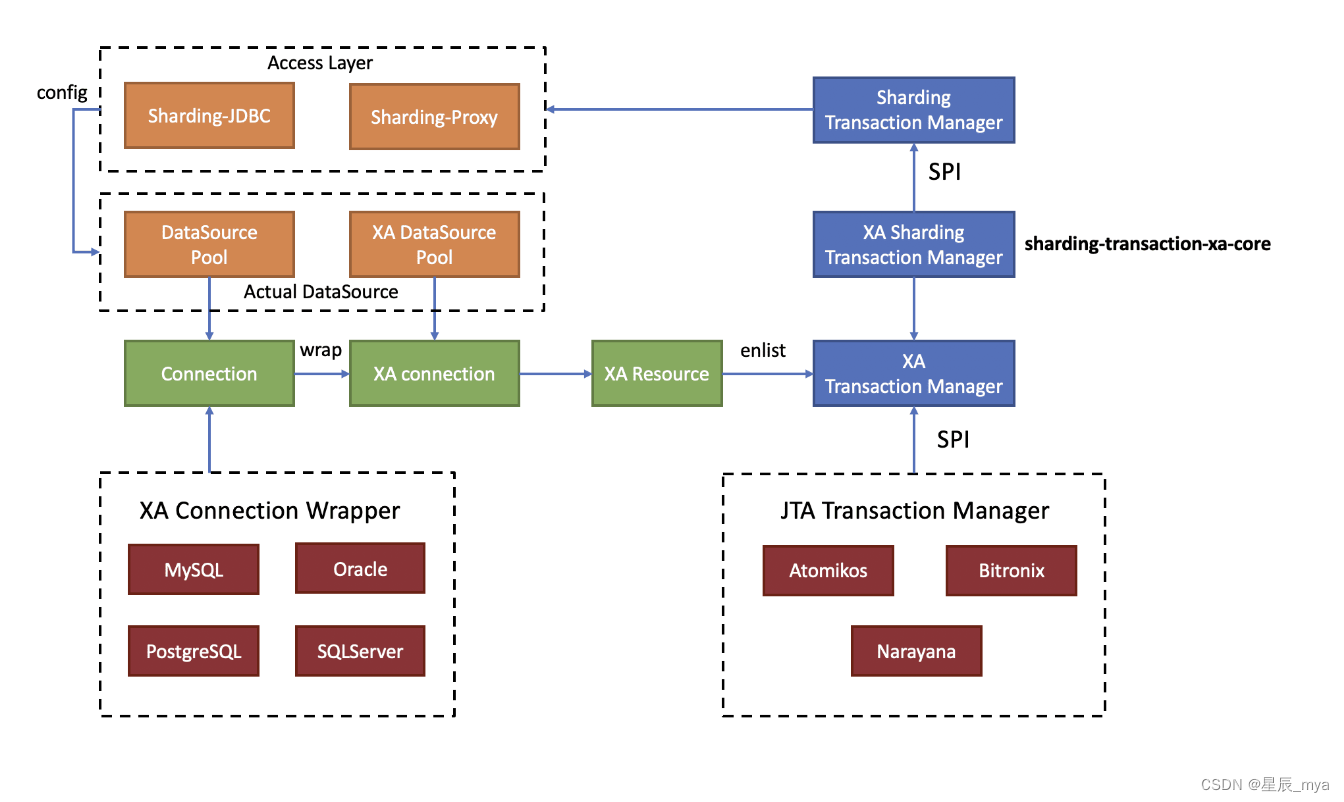
set autoCommit=0 ,XAShardingSphereTransactionManager 为调用具体的 XA 事务管理器开启 XA 全局事务,以 XID 的形式进行标记
XAResource注册XA事务中,事务管理器 XAResource.start,库收到XAResource.end前,all的sql操作标记为xa事务
XAShardingSphereTransactionManager收到接入端提交命令,委托xa事务管理器提交,收集到all注册xaResource, 发送XAResource.end 指令,依次发送prepare,手机xaResource投票,all均正确 commit最终提交,否rollback回滚
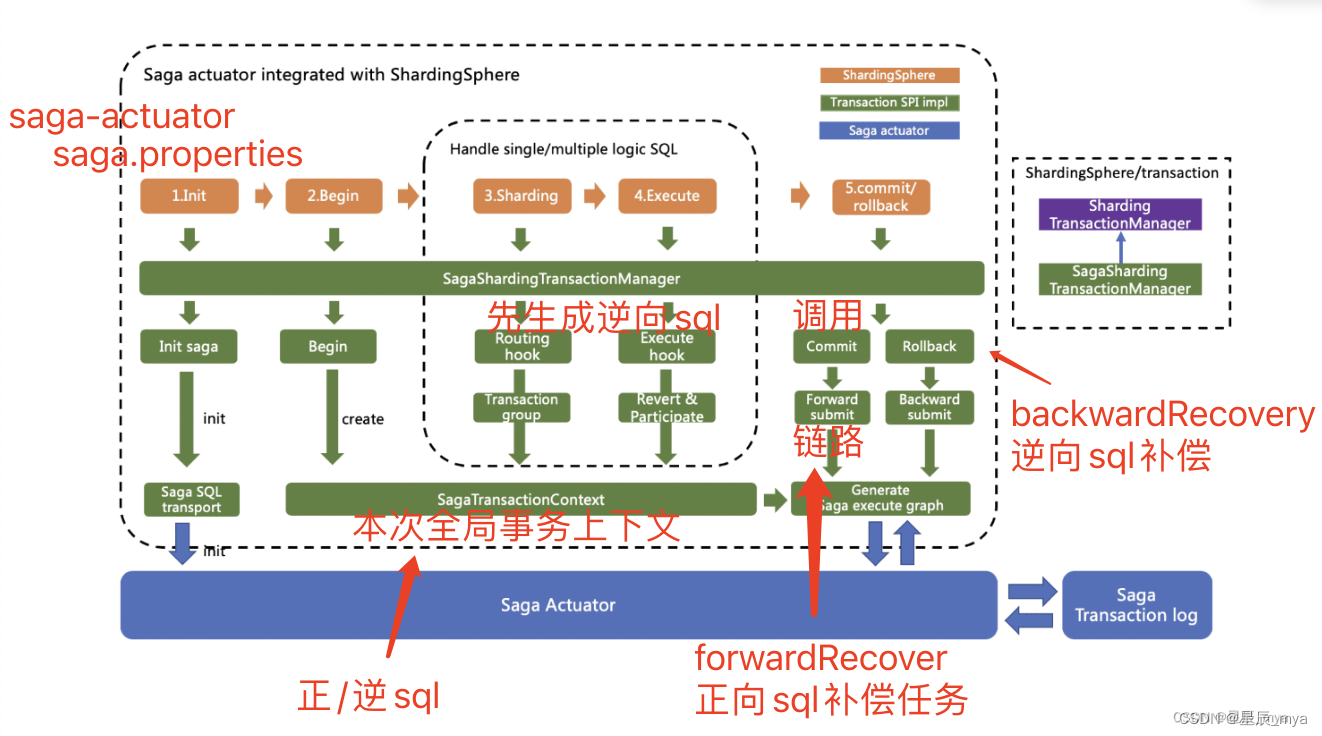
Saga
一个Saga事务是一个有多个短时事务组成的长时的事务
分布式事务场景下,一个Saga分布式事务看做是一个由多个本地事务组成的事务,每个本地事务都有一个与之对应的补偿事务
在Saga事务的执行过程中,如某一步执行出现异常,Saga事务会被终止,同时会调用对应的补偿事务完成相关的恢复操作
自动反向补偿
Saga事务管理器根程序执行结果生成一张有向无环图,在需要执行回滚操作时,据该图依次按照相反的顺序调用反向补偿操作
Saga事务管理器只用于控制何时重试,何时补偿,补偿的具体操作需开发者提供
ShardingSphere采用反向SQL技术,将对数据库进行更新操作的SQL自动生成反向SQL,并交由saga-actuator执行,无需关注如何实现补偿,柔性事务管理器的应用范畴定位回了数据库层面
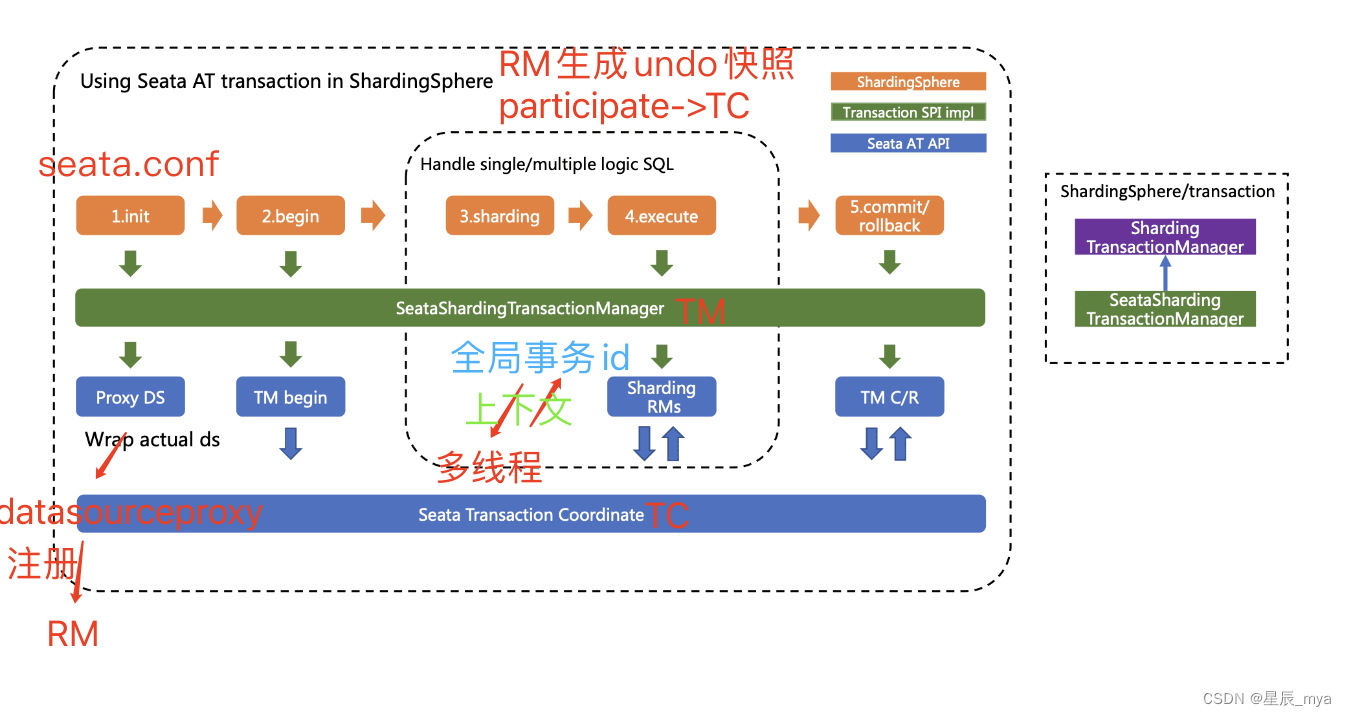
Seata
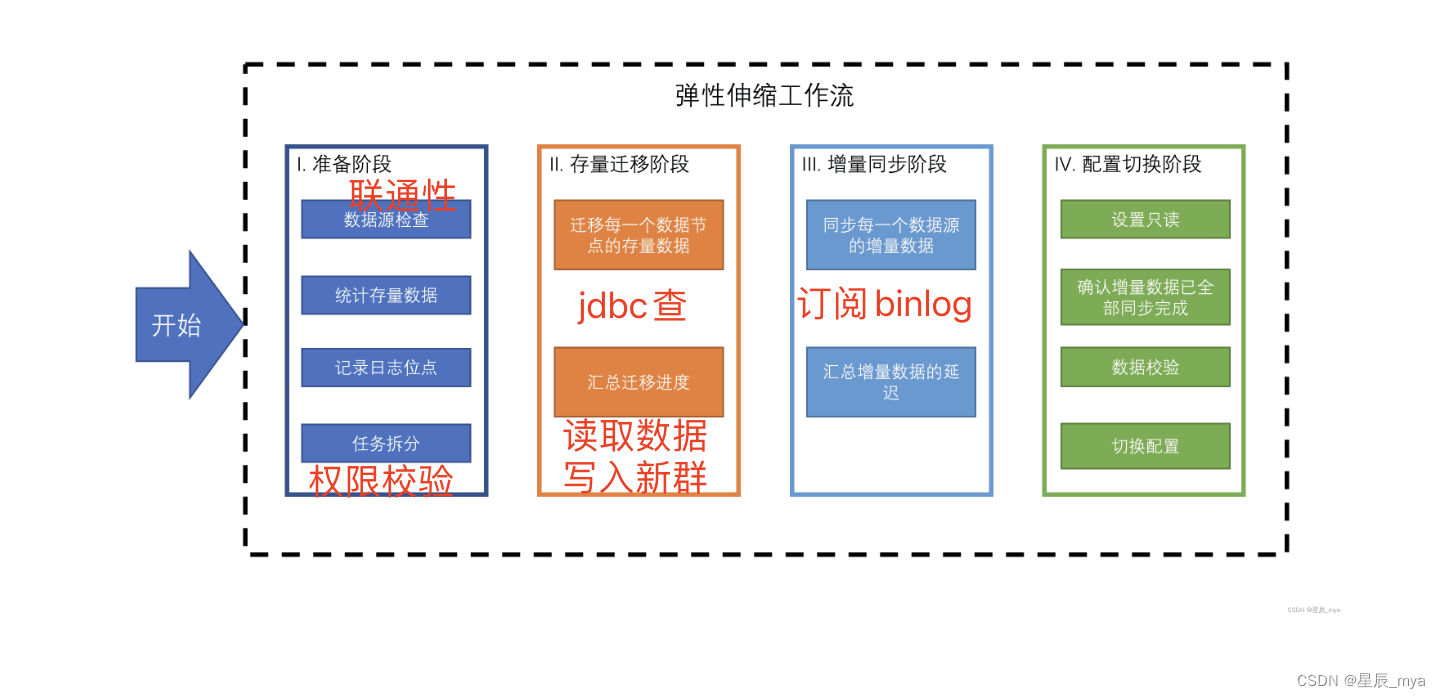
弹性伸缩
对现有的分片集群进行弹性扩容或缩容,4.1.0
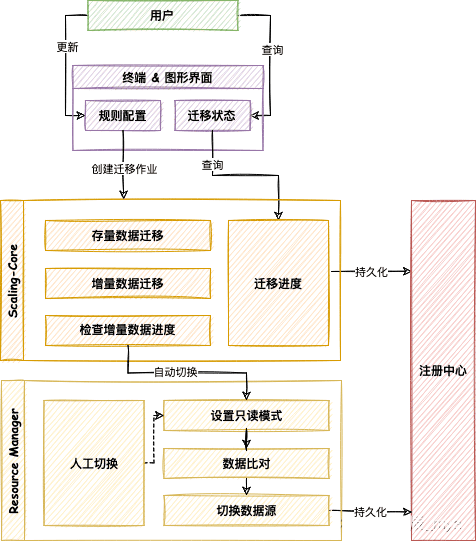
临时建两个库集群,伸缩完切换
解析旧分片规则,提取配置中的数据源、数据节点等,之后创建伸缩作业工作流
压测
解析 SQL,对传入的 SQL 进行影子判定,根配置文件设置的影子规则,路由到生产库或者影子库
以 INSERT 语句为例,对 SQL 进行解析,据配置文件规则,构造一条路由链
在当前版本的功能中(很老的版本), 影子功能处于路由链中的最后一个执行单元:如果有其他需要路由的规则存在,如分片,据分片规则路由到某一个数据库,执行影子路由判定流程,判定执行SQL满足影子规则的配置,数据路由到对应的影子库,生产数据维持不变
DML:先判断执行SQL表与配置的影子表是否有交集,有:判交集影子表关联的影子算法,任一成功 sql路由到影子库,无交集 判定失败 路由到生产库
DDL:注解影子算法,初始化/修改影子库使用,执行的sql有注解 配置hint判定 成功路由影子库 否路由生产库
这篇关于ShardingSphere再回首的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!