本文主要是介绍数据应用OneID:ID-Mapping Spark GraphX实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
说明
以用户实体为例,ID 类型包含 user_id 和 device_id。当然还有其他类型id。不同id可以获取到的阶段、生命周期均不相同。
device_id 生命周期通常指的是一个设备从首次被识别到不再活跃的整个时间段。
user_id是用户登录之后系统分配的唯一标识,即使不同的设备只要user_id相同就会识别为一个用户,但 user_id 只能在登录后获取到,所以会损失用户登录前的行为数据。
单体应用单独使用user_id或者device_id都不能完整地表达一个用户,多应用多类id又有差异性。如果可以将不同 ID 进行关联映射,最终通过唯一的 ID 标识用户。所以需要一个解决方案来映射。
用户渠道
- 手机、平板电脑
- 安卓手机、ios手机
- 有PC、APP和小程序
标识情况
(1)cookieid:PC站存在用户cookies中的ID,会被清理电脑时重生成。
(2)unionid:微信提供的唯一身份认证。
(3)mac:手机网卡物理地址。
(4)imei(入网许可证序号):安卓系统可取到。
(5)imsi(手机SIM卡序号):安卓系统可取到。
(6)androidid :安卓系统id。
(7)openid (app自己生成的序号) :卸载重装app就会变更。
(8)idfa(广告跟踪码):用户可重置。
(9)deviceid(app日志采集埋点开发人员自己定义一种逻辑id,可能取自 android,imei,openudid等):逻辑上的id。
还有其他不同应用设定标识用户的ID. . . . . .
设备与登录用户分析
1. device_id 作为唯一
场景
适用登录率比较低的应用。
缺点
- 不同用户登录一个设备,会识别为一个用户。
- 同一个用户使用不同设备,会识别为多个用户。
2. 一个device_id关联一个user_id
场景
同一个设备登陆前(device_id) 和登录后(user_id) 可以绑定。
缺点
- 一个未被绑定的设备登录前的用户和登录后的用户不同,这个时候会被错误地识别为同一个用户。
- 一个被绑定的设备后续被其他用户在未登录状态下使用,也会被错误地识别为之前被绑定的用户。
- 一个被绑定了的用户使用其他设备时,未登录状态下的数据不会标识为该用户数据。
3. 多个device_id关联一个user_id
场景
只要登录后的 user_id 相同,其多个设备上登录前后的数据都可以连通起来。
缺点
一个 device_id只能绑定到一个用户,当其他用户使用同一个已被绑定的设备时,其登录前数据还是会被识别成已绑定到该设备的用户。
4. 多个应用间的不同ID进行关联
场景
当存在多个应用,实现应用间 ID 映射和数据相通时。比如,通过手机号,邮箱号,微信号等等可以统一为一个 ID。
缺点
复杂性高。
5. 行业内方案
网易ID-Mapping
网易产品线:网易云音乐,邮箱,新闻,严选等等,不同的应用有不同的ID,比如:phone,email,yanxuan_id,music_id 等等
思路与方案
- 结合各种应用账号,各种设备型号之间的关系,以及设备使用规律,比如时间和频次。
- 采用规则过滤 和 数据挖掘,判断账号是否属于同一个人。
存在问题和方案
- 用户有多个设备信息:使用一定时间 和 频次才进行关联。
- 设备以后从来不用:设定设备未使用衰减函数。
6. 其他
美团采用手机号、微信、微博、美团账号的登录方式;大众点评采用的手机号、微信、QQ、微博的登录方式;其交集为手机号、微信、微博。最终,对于注册用户账户体系,美团采用了手机号作为用户的唯一标识。
图计算
图计算的核心思想:将数据表达成“点”,点和点之间可以通过某种业务含义建立“边”。然后,我们就可以从点、边上找出各种类型的数据关系。
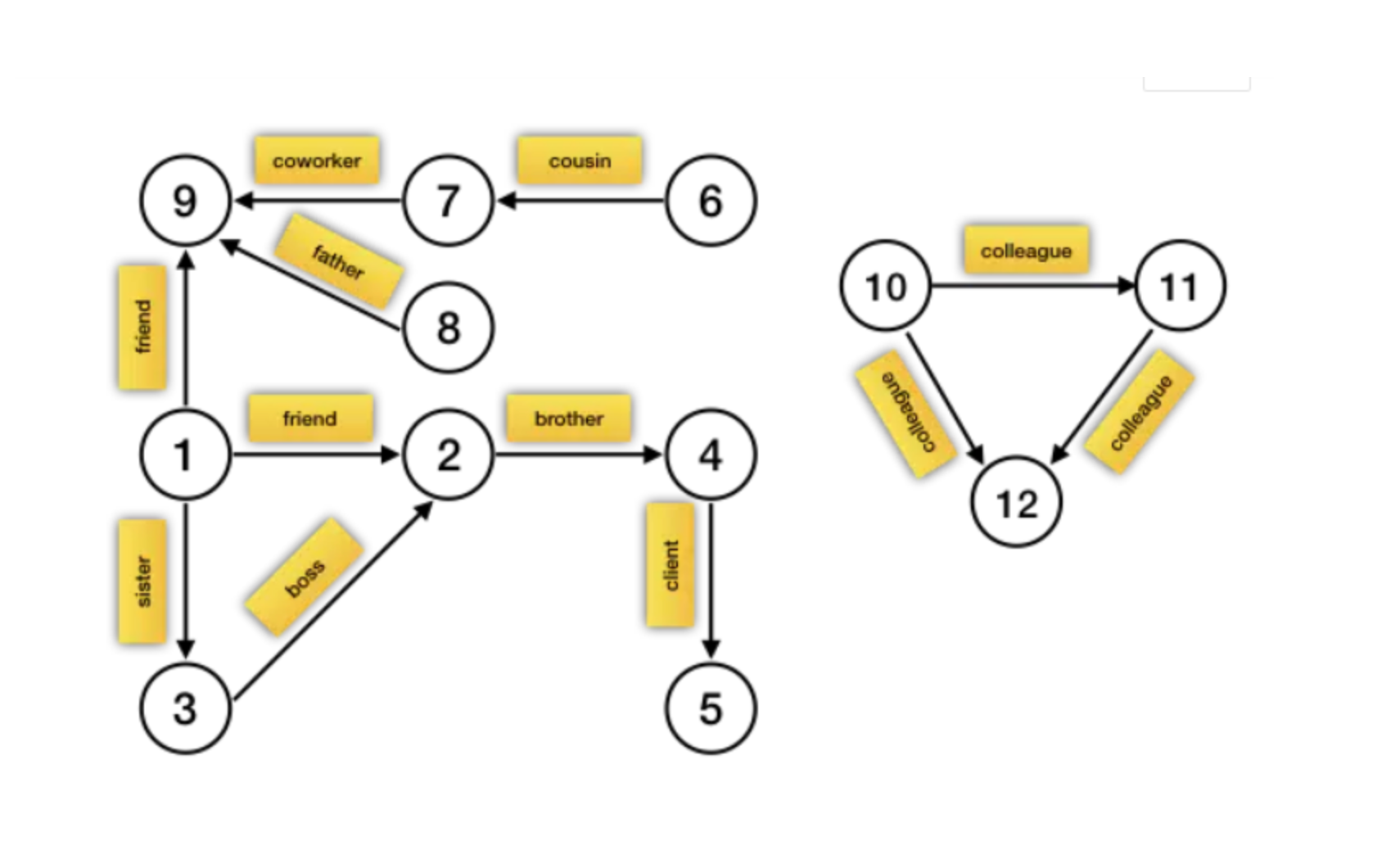
在GraphX中,图由顶点(Vertices)和边(Edges)组成:
- 顶点(Vertices):图中的点,代表实体,例如人、商品或事件。
- 边(Edges):连接两个顶点的线,代表实体之间的关系,例如朋友关系、购买行为或网络连接。
- 边的属性(Edge Attributes):边的附加信息,可以是权重、成本或其他相关数据。
- 顶点的属性(Vertex Attributes):顶点的附加信息,可以是标签、状态或其他相关数据。
首先通过一个案例先认识下图计算。
案例:朋友关系的连通性
首先,需要将这些数据转换为Vertex和Edge对象
假设有以下数据:user_id: A, friend_id: B
user_id: B, friend_id: C
user_id: C, friend_id: D
user_id: D, friend_id: E
user_id: E, friend_id: F
user_id: F, friend_id: G
user_id: G, friend_id: H
user_id: H, friend_id: I
user_id: I, friend_id: Jimport org.apache.spark._
import org.apache.spark.graphx._val conf = new SparkConf().setAppName("Graph Example").setMaster("local[*]")
val sc = new SparkContext(conf)// 将原始数据转换为Vertex和Edge对象
val vertices: RDD[(VertexId, String)] = sc.parallelize(Seq((1L, "A"), (2L, "B"), (3L, "C"), (4L, "D"), (5L, "E"),(6L, "F"), (7L, "G"), (8L, "H"), (9L, "I"), (10L, "J"))
)val edges: RDD[Edge[String]] = sc.parallelize(Seq(Edge(1L, 2L,"friend"), Edge(2L, 3L,"friend"), Edge(3L, 4L,"friend"),Edge(4L, 5L,"friend"), Edge(5L, 6L,"friend"), Edge(6L, 7L,"friend"),Edge(7L, 8L,"friend"), Edge(8L, 9L,"friend"),Edge(9L, 10L,"friend"), Edge(10L, 1L,"friend")
))// 创建图
val graph: Graph[String,String] = Graph(vertices, edges)
// triplets同时存储了边属性和对应顶点信息
graph.triplets.foreach(println)((4,D),(5,E),friend)
((5,E),(6,F),friend)
((9,I),(10,J),friend)
((10,J),(1,A),friend)
......// 连通性:可以将每个顶点都关联到连通图里的最小顶点
val value = graph.connectedComponents()
value.vertices.map(tp => (tp._2, tp._1)).groupByKey().collect().foreach(println)结果:(1,CompactBuffer(8, 1, 9, 10, 2, 3, 4, 5, 6, 7))如果修改:Edge(5L, 1L,"friend") Edge(10L, 5L,"friend")val edges: RDD[Edge[String]] = sc.parallelize(Seq(Edge(1L, 2L,"friend"), Edge(2L, 3L,"friend"), Edge(3L, 4L,"friend"),Edge(4L, 5L,"friend"), Edge(5L, 1L,"friend"), Edge(6L, 7L,"friend"),Edge(7L, 8L,"friend"), Edge(8L, 9L,"friend"),Edge(9L, 10L,"friend"), Edge(10L, 5L,"friend")
))结果:
(1,CompactBuffer(1, 2, 3, 4))
(5,CompactBuffer(8, 9, 10, 5, 6, 7))ID-Mapping 简单实现
val conf = new SparkConf().setAppName("Graph Example").setMaster("local[*]")
val sc = new SparkContext(conf)
// 假设我们有三个数据集
val userMappingData = sc.parallelize(Seq((11L,111L), // phone,device_id(22L,222L)
))val userInfoData = sc.parallelize(Seq((11L, 1111L), // phone,open_id,这里把phone当作user_id(22L, 2222L)
))val userLoginData = sc.parallelize(Seq((1111L, 11111L, 111111L), // open_id,idfa,idfy(2222L, 22222L, 222222L)
))// 为每个数据集创建顶点RDD
// val userVertices = userMappingData.flatMap(item =>{
// for (element <- item.productIterator)
// yield (element,element)
// })val phoneVertices = userMappingData.map { case (phone, _) => (phone, "phone") }
val deviceVertices = userMappingData.map { case (_, deviceId) => (deviceId, "deviceId") }val userPhoneVertices = userInfoData.map { case (phone,_) => (phone, "phone") }
val openidVertices = userInfoData.map { case (_, openId) => (openId, "openId") }val idfaVertices = userLoginData.flatMap { case (openId, idfa, _) => Seq((openId, "openid"), (idfa, "idfa")) }
val idfvVertices = userLoginData.flatMap { case (openId, _, idfv) => Seq((openId, "openid"), (idfv, "idfv")) }// 合并所有顶点RDD
val allVertices = phoneVertices.union(deviceVertices).union(userPhoneVertices).union(openidVertices).union(idfaVertices).union(idfvVertices)// 创建边RDD
val mappingEdges = userMappingData.map { case (phone, deviceId) => Edge(phone, deviceId, "maps_to") }
val infoEdges = userInfoData.map { case (phone, openid) => Edge(phone, openid, "linked_to") }
val loginEdges = userLoginData.flatMap { case (openid, idfa, idfv) =>Seq(Edge(openid, idfa, "logins_with"), Edge(openid, idfv, "logins_with"))
}// 合并所有边RDD
val allEdges = mappingEdges.union(infoEdges).union(loginEdges)val graph = Graph(allVertices, allEdges)graph.triplets.map(item=> "点 and 边:"+item).foreach(println)点 and 边:((22,phone),(222,deviceId),maps_to)
点 and 边:((11,phone),(111,deviceId),maps_to)
点 and 边:((11,phone),(1111,openId),linked_to)
点 and 边:((22,phone),(2222,openId),linked_to)
点 and 边:((1111,openId),(11111,idfa),logins_with)
点 and 边:((1111,openId),(111111,idfv),logins_with)
点 and 边:((2222,openId),(22222,idfa),logins_with)
点 and 边:((2222,openId),(222222,idfv),logins_with)val value = graph.connectedComponents()
value.vertices.map(tp => (tp._2, tp._1)).groupByKey().collect().foreach(println)(11,CompactBuffer(1111, 11, 111, 11111, 111111))
(22,CompactBuffer(2222, 22, 222, 222222, 22222))说明
真实的数据可能不会都是Long型,需要你特殊处理计算,计算出结果再转换为明文。案例中,数据连通性后,可以生成统一ID。
上面只是简单案例,在最上面分析过会出现不同的情况,更复杂的需要更复杂的逻辑处理。
除了图计算,直接SQL JOIN也即可。
这篇关于数据应用OneID:ID-Mapping Spark GraphX实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






