graphx专题

Spark GraphX在淘宝的实践
原文链接:http://rec-sys.net/forum.php?mod=viewthread&tid=398 由于Spark GraphX性能良好,又有丰富的功能和运算符,能在海量数据上自如运行复杂的图算法,淘宝尝试将它作为分布式图计算平台,进行各种算法尝试和生产应用。本文结合GraphX的原理和特点,分享其在淘宝的应用实践。 早在0.5版本,Spark就带了一个小型的B

GraphX具体功能的代码使用实例-Scala实现
GraphX 为整个图计算流程提供了强大的支持,先前已经有若干篇文章先后介绍了GraphX的强大功能,在GraphX官方编程指南中,提供了部分简单易懂的示例代码,其为GraphX的使用提供了一个初步的认识,作为需要用GraphX来编码实现需求的读者来说是十分宝贵的资源。 本文利用一个初始示例代码,结合部分官方文档中的说明,对GraphX的部分功能方法进行了实践,在全部亲自运行通过后,对大部分代

GraphX编程指南-官方文档-整理
GraphX 是新的(alpha)的图形和图像并行计算的Spark API。从整理上看,GraphX 通过引入 弹性分布式属性图(Resilient Distributed Property Graph)继承了Spark RDD:一个将有效信息放在顶点和边的有向多重图。为了支持图形计算,GraphX 公开了一组基本的运算(例如,subgraph,joinVertices和mapReduceTri

Spark图计算及GraphX简单入门
GraphX介绍 GraphX应用背景 Spark GraphX是一个分布式图处理框架,它是基于Spark平台提供对图计算和图挖掘简洁易用的而丰富的接口,极大的方便了对分布式图处理的需求。 众所周知·,社交网络中人与人之间有很多关系链,例如Twitter、Facebook、微博和微信等,这些都是大数据产生的地方都需要图计算,现在的图处理基本都是分布式的图处理,而并非单机处理。Spark Gra

spark graphx 可视化:不同属性结点指定不同颜色
普通图: 节点指定颜色的图: 方法: 自定义节点的属性如: 属性文件stylesheets,内容如下,ip节点颜色是红色 edge { shape: cubic-curve; fill-color: #dd1c77; z-index: 0; text-background-mode: rounded-box; text-background-color:

spark graphx 图结构 画图/可视化
所需的包: maven包:<!--<!– https://mvnrepository.com/artifact/org.graphstream/gs-core –>--><dependency><groupId>org.graphstream</groupId><artifactId>gs-core</artifactId><version>1.2</ver
毕设第二周(GraphX环境搭建 GraphX API 以及对Pregel的熟悉)
GraphX环境搭建与API的熟悉 我自己在本机上搭建了GraphX的环境,并测试了几个Demo。这方面的内容,GraphX的官方网站上有详细的介绍,列举几个我个人认为比较基础和重要的关于Graph的Operators: class Graph[VD, ED] {//这个是把图存成Table所需要的数据,上一个周报里面提到了val vertices: VertexRDD[VD]val ed
###spark版### Spark Graphx 进行团伙的识别(community detection)
最近在使用Spark Graphx,拿Graphx做了点实验。对大规模图常见的分析方法有连通图挖掘,团伙挖掘等。在金融科技领域,尤其风控领域,会有各种重要的关联网络,并且这种网络图十分庞大。 所以,Spark Graphx这种分布式计算框架十分适合这种场景。下面以设备间关联网络(节点数亿级别)为例,采用Graphx做一个设备团伙挖掘demo。团伙识别的算法采用的是Graphx自带的LabelP
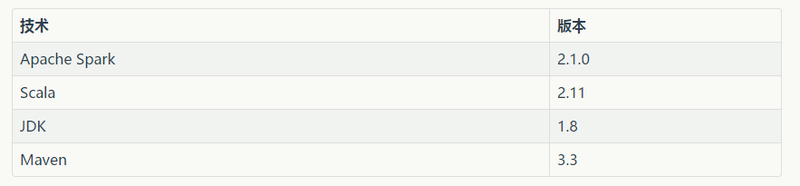
###好好好######Spark GraphX处理图数据
大数据呈现出不同的形态和大小。它可以是批处理数据,也可以是实时数据流;对前者需要离线处理,需要较多的时间来处理大量的数据行,产生结果和有洞察力的见解,而对后者需要实时处理并几乎同时生成对数据的见解。 我们已经了解了如何将 Apache Spark 应用于处理批数据(Spark Core)以及处理实时数据(Spark Streaming)。 有时候,所需处理的数据是很自然地联系在一起的。譬如,在
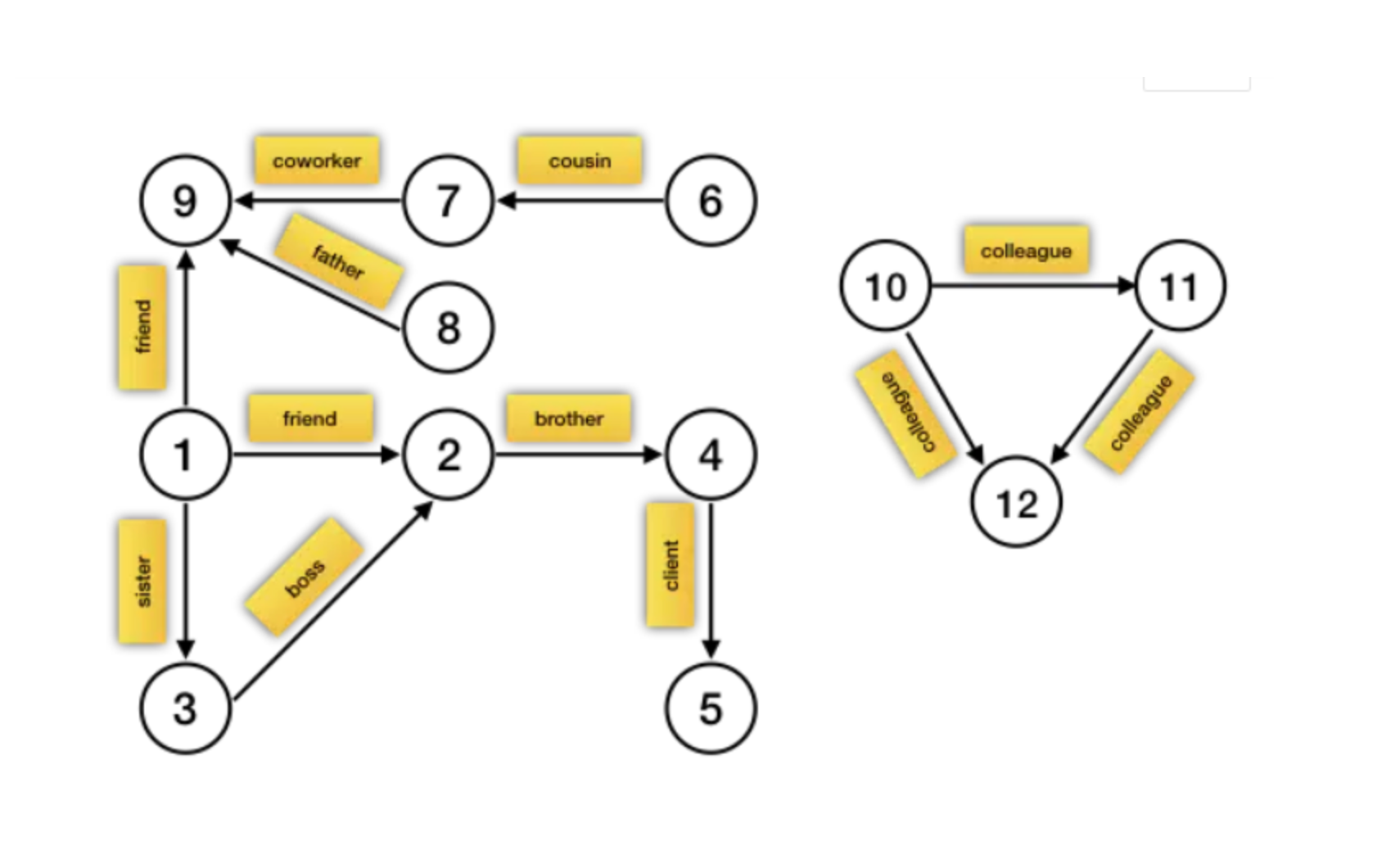
数据应用OneID:ID-Mapping Spark GraphX实现
前言 说明 以用户实体为例,ID 类型包含 user_id 和 device_id。当然还有其他类型id。不同id可以获取到的阶段、生命周期均不相同。 device_id 生命周期通常指的是一个设备从首次被识别到不再活跃的整个时间段。 user_id是用户登录之后系统分配的唯一标识,即使不同的设备只要user_id相同就会识别为一个用户,但 user_id 只能在登录后获取到,所以

Spark GraphX 图操作
Spark GraphX 图操作 在GraphX中,核心操作都是被优化过的,组合核心操作的定义在GraphOps中。 由于Scala隐式转换,定义在GraphOps的操作可以在Graph的成员中获取。例如:我们计算图中每个顶点的入度.(该方法是定义在GraphOps) val graph: Graph[(String, String), String]// Use the implicit

GraphScope、Gemini与GraphX的性能对比
目前图计算系统主要分为两大流派,general purpose和graph-specific。General purpose系统底层基于RDD等通用数据抽象,基于通用大数据平台(如Spark)将图计算操作转换为retational operator等通用操作,而graph-specific系统将数据直接表示成图结构,并为用户提供访问、操作点、边的图结构等接口。为了比较general purpose

Spark GraphX实现Bron–Kerbosch算法-极大团问题
首先,说明两个概念:团、极大团。 团(clique)是一个无向图(undirected graph )的子图,该子图中任意两个顶点之间均存在一条边。又叫做完全子图。极大团(maximal clique)是一个团,该团不能被更大的团所包含,换句话说,再也不存在一个点与该团中的任意顶点之间存在一条边。 研究极大团的问题对社区发现等场景有较高的理论价值和现实意义。求一个无向图中的极大团问题是
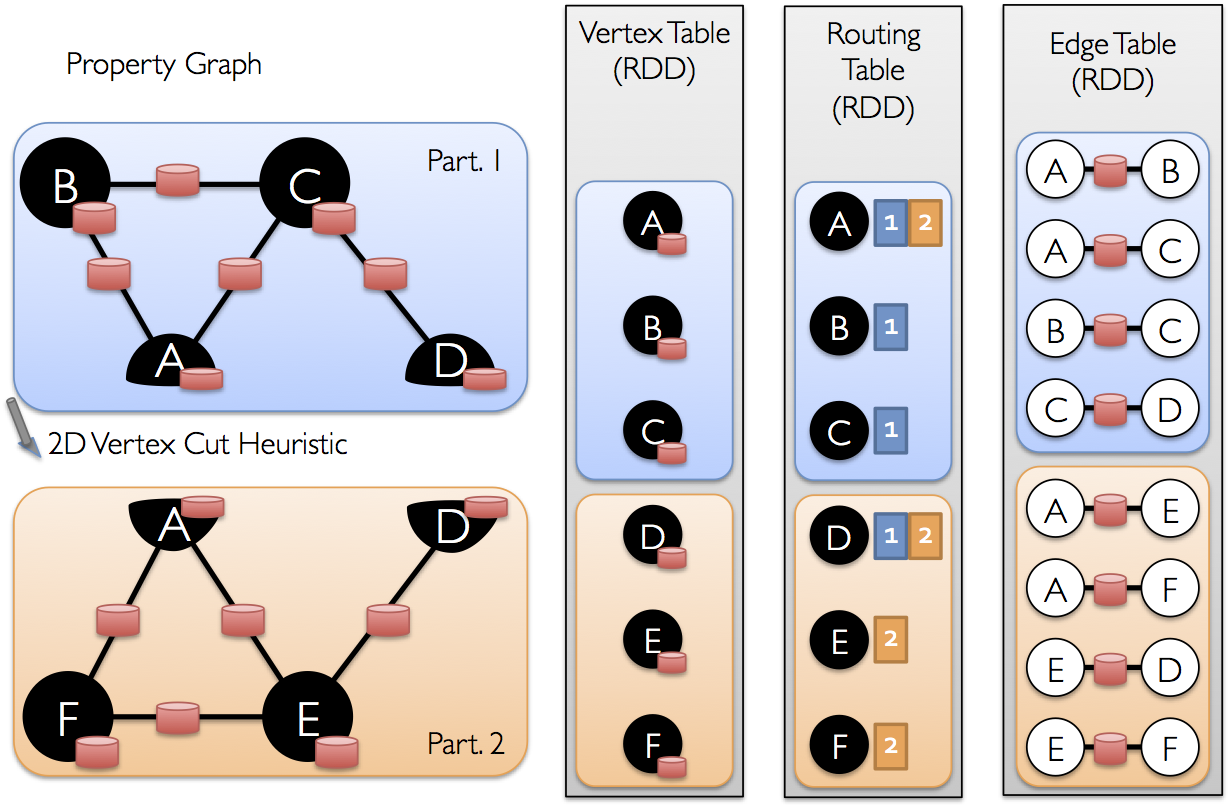
Spark GraphX Programming Guide 编程指南
6、 Spark GraphX Programming Guide 6.1 概述 GraphX是spark的一个新组件用于图和并行图计算。在一个高水平,GraphX通过引进一个新的图抽象扩展了spark RDD:带有顶点和边属性的有向多重图。为了支持图计算,GraphX 提供了很多基本的操作(像 subgraph, joinVertices, and aggregateMessages)和p
ID Mapping技术解析:从Redis到Spark GraphX的演进与应用
目录 一、ID Mapping的背景 二、ID Mapping的重要性 三、ID Mapping的方案 3.1 基于Redis的ID Mapping(效率不行)

Running Apache Spark GraphX algorithms on Library of Congress subject heading SKOS
Running Apache Spark GraphX algorithms on Library of Congress subject heading SKOS 这是Bob DuCharme的一篇客串文章。 原文出现在://www.snee.com/bobdc.blog/2015/04/running-spark-graphx-algorithm.html 译者微博:@从流域

Spark图计算GraphX介绍及实例
目录 一、GraphX介绍 二、GraphX实现分析 三、GraphX实例 四、参考资料 一、GraphX介绍 1.1 GraphX应用背景 Spark GraphX是一个分布式图处理框架,它是基于Spark平台提供对图计算和图挖掘简洁易用的而丰富的接口,极大的方便了对分布式图处理的需求。 众所周知·,社交网络中人与人之间有很多关系链,例如Twi

Spar(k)ql:SPARQL evaluation method on spark GraphX
abstract: 由于灵活和简易,RDF变的越来越受欢迎的框架。查询大量的RDF数据也是面临的巨大的挑战。in this paper ,我们研究如何评估分布式系统中的sparql查询。我们提出了一中利用graphx图形分析工具对sparql查询评估的新方法。通过此工具,我们成功利用RDF语句的类图结构。 introduction: P:查询大量的数据集变成严峻的挑战。s
spark graphx 实现二跳邻居统计——使用pregel
本文参考自: 原文地址 本文是对二跳邻居统计的实战,因为用到了pregel,需要对pregel模型有一些大致的了解,例如各个参数的意义,各个函数的作用,以及大致的流程。最核心的应该就是消息发送函数这个部分,注释中有对两轮迭代的过程有解释。 def main(args: Array[String]): Unit = {case class Person(id: String, tel: Stri