本文主要是介绍Qlik Sense : Crosstable在数据加载脚本中使用交叉表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是Crosstable?
交叉表是常见的表格类型,特点是在两个标题数据正交列表之间显示值矩阵。如果要将数据关联到其他数据表格,交叉表通常不是最佳数据格式。
本主题介绍了如何逆透视交叉表,即,在数据加载脚本中使用 LOAD 语句的 crosstable 前缀将部分交叉表转置为行。也就是所谓的行转列。
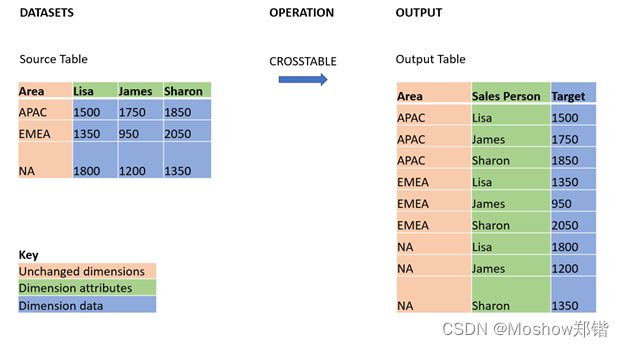
CrossTable实战 1
使用一个限定列逆透视交叉表
交叉表通常位于许多限定列之后,这些列将被直接读取。在此例中,有一个限定列 Year,以及每个月的销售数据矩阵。
| Year | Jan | Feb | Mar | Apr | May | Jun |
|---|---|---|---|---|---|---|
| 2008 | 45 | 65 | 78 | 12 | 78 | 22 |
| 2009 | 11 | 23 | 22 | 22 | 45 | 85 |
| 2010 | 65 | 56 | 22 | 79 | 12 | 56 |
| 2011 | 45 | 24 | 32 | 78 | 55 | 15 |
| 2012 | 45 | 56 | 35 | 78 | 68 | 82 |
如果此表格只是简单加载到 Qlik Sense,结果将为Year使用一个字段,每个月份各一字段。通常,这并非您希望看到的结果。您可能更希望生成三个字段:
- 在此例中,在上述表格中限定列 Year 使用绿色标记。
- 在此例中,使用黄色标记的 Jan - Jun 月份表示属性字段。可以适当地将此字段命名为 Month。
- 数据矩阵值使用蓝色标记。在此例中,它们表示销售数据,因此可以适当地将此字段命名为 Sales。
通过将 crosstable 前缀添加到 LOAD 或 SELECT 语句可实现此操作,例如:
crosstable (Month, Sales) LOAD * from ex1.xlsx;
这可以在 Qlik Sense 中创建以下表格:
| Year | Month | Sales |
|---|---|---|
| 2008 | 一月 | 45 |
| 2008 | 二月 | 65 |
| 2008 | 三月 | 78 |
| 2008 | 四月 | 12 |
| 2008 | 五月 | 78 |
| 2008 | 六月 | 22 |
| 2009 | 一月 | 11 |
| 2009 | 二月 | 23 |
| ... | ... | ... |
使用两个限定列逆透视交叉表
在此例中,左边有两个限定列,紧跟矩阵列之后。
| Salesman | Year | Jan | Feb | Mar | Apr | May | Jun |
|---|---|---|---|---|---|---|---|
| A | 2008 | 45 | 65 | 78 | 12 | 78 | 22 |
| A | 2009 | 11 | 23 | 22 | 22 | 45 | 85 |
| A | 2010 | 65 | 56 | 22 | 79 | 12 | 56 |
| A | 2011 | 45 | 24 | 32 | 78 | 55 | 15 |
| A | 2012 | 45 | 56 | 35 | 78 | 68 | 82 |
| B | 2008 | 57 | 77 | 90 | 24 | 90 | 34 |
| B | 2009 | 23 | 35 | 34 | 34 | 57 | 97 |
| B | 2010 | 77 | 68 | 34 | 91 | 24 | 68 |
| B | 2011 | 57 | 36 | 44 | 90 | 67 | 27 |
| B | 2012 | 57 | 68 | 47 | 90 | 80 | 94 |
限定列的数量可表述为 crosstable 前缀的第三个参数,如下所述:
crosstable (Month, Sales, 2) LOAD * from ex2.xlsx;
这可以在 Qlik Sense 中创建下列结果:
| Salesman | Year | Month | Sales |
|---|---|---|---|
| A | 2008 | 一月 | 45 |
| A | 2008 | 二月 | 65 |
| A | 2008 | 三月 | 78 |
| A | 2008 | 四月 | 12 |
| A | 2008 | 五月 | 78 |
| A | 2008 | 六月 | 22 |
| A | 2009 | 一月 | 11 |
| A | 2009 | 二月 | 23 |
| ... | ... | ... | ... |
了解更多Crosstable
- Crosstable
 https://help.qlik.com/zh-CN/sense/November2023/Subsystems/Hub/Content/Sense_Hub/Scripting/ScriptPrefixes/crosstable.htm
https://help.qlik.com/zh-CN/sense/November2023/Subsystems/Hub/Content/Sense_Hub/Scripting/ScriptPrefixes/crosstable.htm
Crosstable实战 2
crosstable 加载前缀用于转置“交叉表”或“透视表”结构化数据。使用电子表格源时,通常会遇到以这种方式构造的数据。crosstable 加载前缀的输出和目的是将此类结构转换为规则的面向列的表等价物,因为这种结构通常更适合 Qlik Sense 中的分析。
交叉表转换后数据结构为交叉表及其等效结构的示例
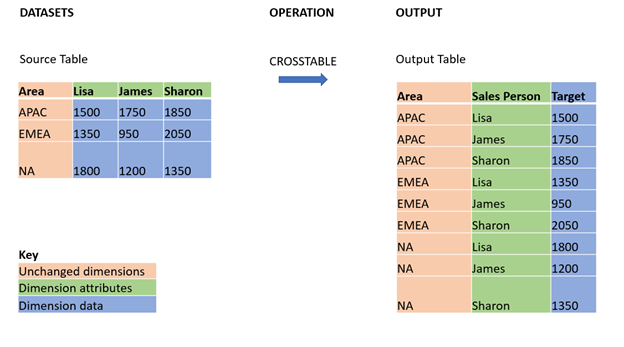
语法:
crosstable (attribute field name, data field name [ , n ] ) ( loadstatement | selectstatement )
| 参数 | 说明 |
|---|---|
| attribute field name | 描述要转置的水平方向维度的所需输出字段名称(标题行)。 |
| data field name | 所需的输出字段名称,用于描述要转置的维度的水平方向数据(标题行下方的数据值矩阵)。 |
| n | 要被转换成常规形式的表格前面的限定符字段数量或未更改的维度。默认值为 1。 |
此脚本函数与以下函数相关:
| 函数 | 交互 |
|---|---|
| Generic | 一种转换加载前缀,用于获取实体属性值结构化数据集,并将其转换为常规关系表结构,将遇到的每个属性分离为新的字段或数据列。 |
示例 1 – 转换数据透视销售数据(简单)
加载脚本和结果
概述
打开数据加载编辑器,并将下面的第一加载脚本添加到新选项卡。
第一个加载脚本包含一个数据集,crosstable 脚本前缀稍后将应用于该数据集,其中应用 crosstable 的部分已注释掉。这意味着注释语法用于在加载脚本中禁用此部分。
第二个加载脚本与第一个加载脚本相同,但应用了未注释 crosstable(通过删除注释语法启用)。脚本以这种方式显示,以突出显示该脚本函数在转换数据中的价值。
第二加载脚本(应用的函数)
tmpData:
//Crosstable (MonthText, Sales)
Load * inline [
Product, Jan 2021, Feb 2021, Mar 2021, Apr 2021, May 2021, Jun 2021
A, 100, 98, 103, 63, 108, 82
B, 284, 279, 297, 305, 294, 292
C, 50, 53, 50, 54, 49, 51];//Final:
//Load Product,
//Date(Date#(MonthText,'MMM YYYY'),'MMM YYYY') as Month,
//Sales//Resident tmpData;//Drop Table tmpData;复制代码到剪贴板有关使用内联加载的详细信息,请参见内联加载。
结果
加载数据并打开工作表。创建新表并将这些字段添加为维度:
-
Product
-
Jan 2021
-
Feb 2021
-
Mar 2021
-
Apr 2021
-
May 2021
-
Jun 2021
| 产品 | 2021 年 1 月 | 2021 年 2 月 | 2021 年 3 月 | 2021 年 4 月 | 2021 年 5 月 | 2021 年 6 月 |
|---|---|---|---|---|---|---|
| A | 100 | 98 | 103 | 63 | 108 | 82 |
| B | 284 | 279 | 297 | 305 | 294 | 292 |
| C | 50 | 53 | 50 | 54 | 49 | 51 |
该脚本允许创建一个交叉表,每个月一列,每个产品一行。按照目前的格式,该数据不容易分析。最好将所有数字放在一个字段中,将所有月份放在另一个字段中,放在一个三列表格中。下一节将解释如何对交叉表进行这种转换。
第二加载脚本(应用的函数)
通过删除 // 来取消对脚本的注释。加载的脚本应如下所示:
tmpData:
Crosstable (MonthText, Sales)
Load * inline [
Product, Jan 2021, Feb 2021, Mar 2021, Apr 2021, May 2021, Jun 2021
A, 100, 98, 103, 63, 108, 82
B, 284, 279, 297, 305, 294, 292
C, 50, 53, 50, 54, 49, 51];Final:
Load Product,
Date(Date#(MonthText,'MMM YYYY'),'MMM YYYY') as Month,
SalesResident tmpData;Drop Table tmpData;复制代码到剪贴板有关使用内联加载的详细信息,请参见内联加载。
结果
加载数据并打开工作表。创建新表并将这些字段添加为维度:
-
Product
-
Month
-
Sales
| 产品 | 月 | 销售额值 |
|---|---|---|
| A | Jan 2021 | 100 |
| A | Feb 2021 | 98 |
| A | Mar 2021 | 103 |
| A | Apr 2021 | 63 |
| A | May 2021 | 108 |
| A | Jun 2021 | 82 |
| B | Jan 2021 | 284 |
| B | Feb 2021 | 279 |
| B | Mar 2021 | 297 |
| B | Apr 2021 | 305 |
| B | May 2021 | 294 |
| B | Jun 2021 | 292 |
| C | Jan 2021 | 50 |
| C | Feb 2021 | 53 |
| C | Mar 2021 | 50 |
| C | Apr 2021 | 54 |
| C | May 2021 | 49 |
| C | Jun 2021 | 51 |
应用脚本前缀后,交叉表将转换为一个垂直表,其中一列用于 Month,另一列用于 Sales。这提高了数据的可读性。
示例 2 – 将数据透视销售目标数据转换为垂直表结构(中等)
加载脚本和图表表达式
概述
打开数据加载编辑器,并将下面的加载脚本添加到新选项卡。
加载脚本包含:
-
加载到名为目标的表中的数据集。
-
crosstable 加载前缀,将数据透视的销售人员姓名转换为其自己的字段,标记为 Sales Person。
-
关联的销售目标数据,该数据被结构化为一个名为 Target 的字段。
加载脚本
SalesTargets:
CROSSTABLE([Sales Person],Target,1)
LOAD
*
INLINE [
Area, Lisa, James, Sharon
APAC, 1500, 1750, 1850
EMEA, 1350, 950, 2050
NA, 1800, 1200, 1350
];复制代码到剪贴板结果
加载数据并打开工作表。创建新表并将这些字段添加为维度:
-
Area
-
Sales Person
添加该度量:
=Sum(Target)
| 面积图 | 销售员 | =Sum(Target) |
|---|---|---|
| APAC | James | 1750 |
| APAC | Lisa | 1500 |
| APAC | Sharon | 1850 |
| EMEA | James | 950 |
| EMEA | Lisa | 1350 |
| EMEA | Sharon | 2050 |
| NA | James | 1200 |
| NA | Lisa | 1800 |
| NA | Sharon | 1350 |
如果要将数据的显示复制为数据透视输入表,可以在工作表中创建等效的数据透视表。
执行以下操作:
- 将刚刚创建的表复制并粘贴到工作表中。
- 将透视表图表对象拖动到新创建的表副本的顶部。选择转换。
- 单击 完成编辑。
- 将 Sales Person 字段从垂直列架拖动到水平列架。
下表显示了初始表格形式的数据,如 Qlik Sense 中所示:
| 面积图 | 销售员 | =Sum(Target) |
|---|---|---|
| 总计 | - | 13800 |
| APAC | James | 1750 |
| APAC | Lisa | 1500 |
| APAC | Sharon | 1850 |
| EMEA | James | 950 |
| EMEA | Lisa | 1350 |
| EMEA | Sharon | 2050 |
| NA | James | 1200 |
| NA | Lisa | 1800 |
| NA | Sharon | 1350 |
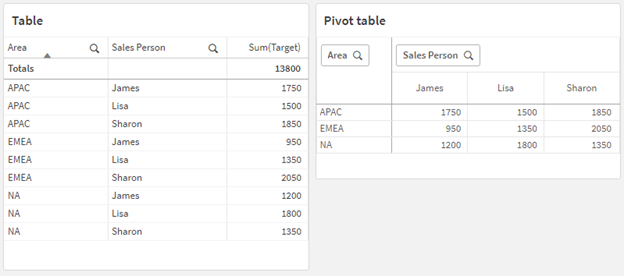
等效数据透视表类似如下,每个销售人员姓名的列包含在较大的 Sales Person 行中:
| 面积图 | James | Lisa | Sharon |
|---|---|---|---|
| APAC | 1750 | 1500 | 1850 |
| EMEA | 950 | 1350 | 2050 |
| NA | 1350 | 1350 | 1350 |
显示为表和等效数据透视表的数据示例,该透视表具有水平透视的 Sales Person
示例 3 – 将数据透视销售和目标数据转换为垂直表结构(高级)
加载脚本和图表表达式
概述
打开数据加载编辑器,并将下面的加载脚本添加到新选项卡。
加载脚本包含:
-
表示销售和目标数据的数据集,按地区和月份组织。这将加载到名为 SalesAndTargets 的表中。
-
crosstable 加载前缀。这用于将 Month Year 维度取消透视到专用字段中,以及将销售和目标金额矩阵转换到名为 Amount 的专用字段中。
-
使用文本到日期转换特性 date# 将 Month Year 字段从文本转换为适当的日期。此日期转换 Month Year 字段通过 Join 加载前缀连接回 SalesAndTarget 表中。
加载脚本
SalesAndTargets:
CROSSTABLE(MonthYearAsText,Amount,2)
LOAD*
INLINE [
Area Type Jan-22 Feb-22 Mar-22 Apr-22 May-22 Jun-22 Jul-22 Aug-22 Sep-22 Oct-22 Nov-22 Dec-22
APAC Target 425 425 425 425 425 425 425 425 425 425 425 425
APAC Actual 435 434 397 404 458 447 413 458 385 421 448 397
EMEA Target 362.5 362.5 362.5 362.5 362.5 362.5 362.5 362.5 362.5 362.5 362.5 362.5
EMEA Actual 363.5 359.5 337.5 361.5 341.5 337.5 379.5 352.5 327.5 337.5 360.5 334.5
NA Target 375 375 375 375 375 375 375 375 375 375 375 375
NA Actual 378 415 363 356 403 343 401 365 393 340 360 405
] (delimiter is '\t');tmp:
LOAD DISTINCT MonthYearAsText,date#(MonthYearAsText,'MMM-YY') AS [Month Year]
RESIDENT SalesAndTargets;JOIN (SalesAndTargets)
LOAD * RESIDENT tmp;DROP TABLE tmp;
DROP FIELD MonthYearAsText;复制代码到剪贴板结果
加载数据并打开工作表。创建新表并将这些字段添加为维度:
-
Area
-
Month Year
使用标签 Actual 创建以下度量值:
=Sum({<Type={'Actual'}>} Amount)
同时创建此度量,具有标签 Target:
=Sum({<Type={'Target'}>} Amount)
| 面积图 | 年度月份 | 实际 | 目标 |
|---|---|---|---|
| APAC | Jan-22 | 435 | 425 |
| APAC | Feb-22 | 434 | 425 |
| APAC | Mar-22 | 397 | 425 |
| APAC | Apr-22 | 404 | 425 |
| APAC | May-22 | 458 | 425 |
| APAC | Jun-22 | 447 | 425 |
| APAC | Jul-22 | 413 | 425 |
| APAC | Aug-22 | 458 | 425 |
| APAC | Sep-22 | 385 | 425 |
| APAC | Oct-22 | 421 | 425 |
| APAC | Nov-22 | 448 | 425 |
| APAC | Dec-22 | 397 | 425 |
| EMEA | Jan-22 | 363.5 | 362.5 |
| EMEA | Feb-22 | 359.5 | 362.5 |
如果要将数据的显示复制为数据透视输入表,可以在工作表中创建等效的数据透视表。
执行以下操作:
- 将刚刚创建的表复制并粘贴到工作表中。
- 将透视表图表对象拖动到新创建的表副本的顶部。选择转换。
- 单击 完成编辑。
- 将 Month Year 字段从垂直列架拖动到水平列架。
- 将 Values 项目从水平列架拖动到垂直列架。
下表显示了初始表格形式的数据,如 Qlik Sense 中所示:
| 面积图 | 年度月份 | 实际 | 目标 |
|---|---|---|---|
| 总计 | - | 13812 | 13950 |
| APAC | Jan-22 | 435 | 425 |
| APAC | Feb-22 | 434 | 425 |
| APAC | Mar-22 | 397 | 425 |
| APAC | Apr-22 | 404 | 425 |
| APAC | May-22 | 458 | 425 |
| APAC | Jun-22 | 447 | 425 |
| APAC | Jul-22 | 413 | 425 |
| APAC | Aug-22 | 458 | 425 |
| APAC | Sep-22 | 385 | 425 |
| APAC | Oct-22 | 421 | 425 |
| APAC | Nov-22 | 448 | 425 |
| APAC | Dec-22 | 397 | 425 |
| EMEA | Jan-22 | 363.5 | 362.5 |
| EMEA | Feb-22 | 359.5 | 362.5 |
等效数据透视表类似如下,每个单独年度月份的列包含在较大的 Month Year 行中:
| 面积(值) | Jan-22 | Feb-22 | Mar-22 | Apr-22 | May-22 | Jun-22 | Jul-22 | Aug-22 | Sep-22 | Oct-22 | Nov-22 | Dec-22 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| APAC - 实际 | 435 | 434 | 397 | 404 | 458 | 447 | 413 | 458 | 385 | 421 | 448 | 397 |
| APAC - 目标 | 425 | 425 | 425 | 425 | 425 | 425 | 425 | 425 | 425 | 425 | 425 | 425 |
| EMEA - 实际 | 363.5 | 359.5 | 337.5 | 361.5 | 341.5 | 337.5 | 379.5 | 352.5 | 327.5 | 337.5 | 360.5 | 334.5 |
| EMEA - 目标 | 362.5 | 362.5 | 362.5 | 362.5 | 362.5 | 362.5 | 362.5 | 362.5 | 362.5 | 362.5 | 362.5 | 362.5 |
| NA - 实际 | 378 | 415 | 363 | 356 | 403 | 343 | 401 | 365 | 393 | 340 | 360 | 405 |
| NA - 目标 | 375 | 375 | 375 | 375 | 375 | 375 | 375 | 375 | 375 | 375 | 375 | 375 |
显示为表和等效数据透视表的数据示例,该透视表具有水平透视的 Month Year

这篇关于Qlik Sense : Crosstable在数据加载脚本中使用交叉表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






