本文主要是介绍【论文阅读——SplitFed: When Federated Learning Meets Split Learning】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
级别CCFA
1.摘要
联邦学习(FL)和分割学习(SL)是两种流行的分布式机器学习方法。两者都采用了模型对数据的场景;客户端在不共享原始数据的情况下训练和测试机器学习模型。由于机器学习模型的架构在客户端和服务器之间分割,SL提供了比FL更好的模型隐私性。此外,分割模型使SL成为资源受限环境的更好选择。然而,由于在多个客户端之间基于中继进行训练,SL的速度比FL慢。
2.贡献
本文提出了一种名为分割联邦学习(SFL)的新方法,它将这两种方法融合在一起,消除了它们固有的缺点,并采用了一种精细的架构配置,结合差分隐私和PixelDP来增强数据隐私和模型鲁棒性。我们的分析和实证结果表明,(纯)SFL在多个客户端上比SL显著减少了每个全局时期的计算时间,同时提供了类似的测试精度和通信效率。此外,就像SL一样,它在客户端数量增加时的通信效率优于FL。此外,带有隐私和鲁棒性措施的SFL在扩展实验设置下进一步进行了评估
3.目标场景
FL的主要优势在于它允许跨多个客户端并行进行高效的ML模型训练。在FL中,客户端的计算需求和ML训练期间的模型隐私是两个主要问题。(对于一些商业公司的模型,肯定是不能全部下发导数据提供方进行训练的,同时对于客户端服务器配置的要求也比较高)
在SL中,通过切割模型可以使数据公司无法拥有全部模型,同时降低了对于数据公司设备的要求。但SL中的中继式训练会导致客户端资源处于空闲状态,因为一次只有一个客户端与服务器交互;这会导致在许多客户端下训练开销的显著增加。
4.方法
4.1 方法概览
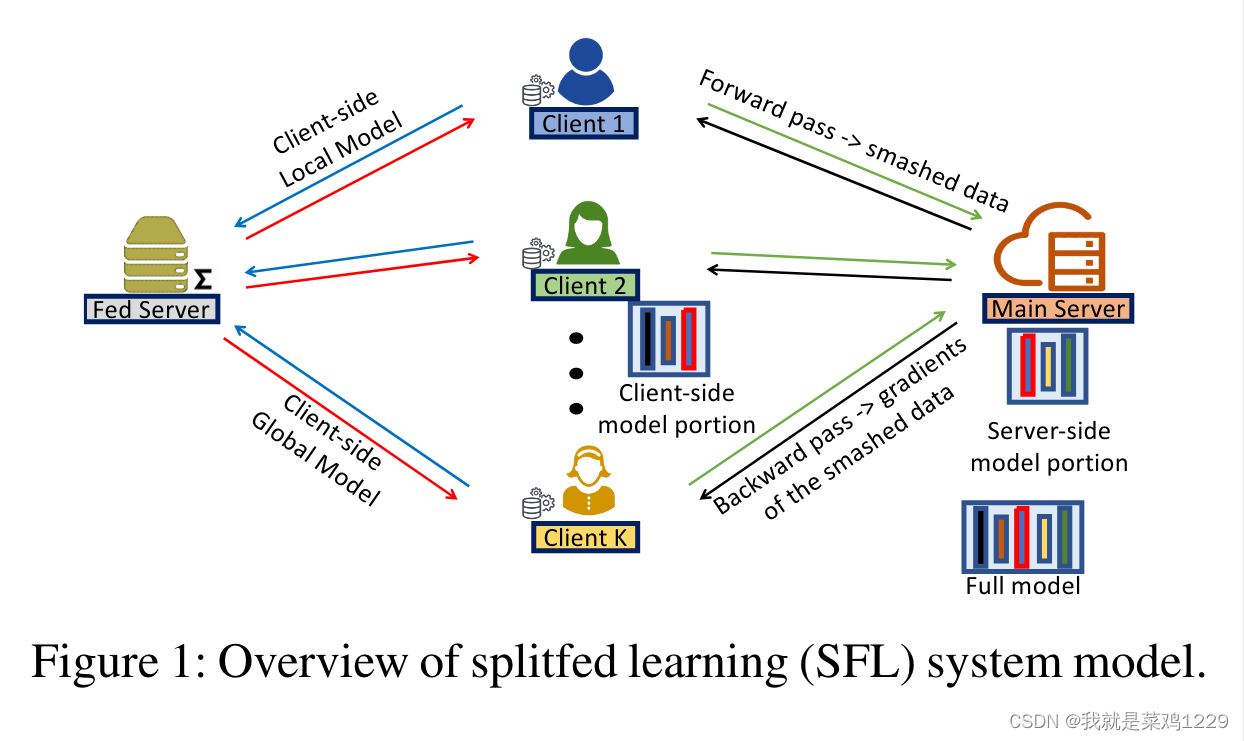
我们假设模型分为特征提取部分 M c M_c Mc和结果推理部分 M t M_t Mt
这里主要存在3个部分:
- Client
- 数据的提供方,将数据通过 M c M_c Mc得到smashed data发送给主服务器。
- 需要等待服务器进行反向传播,更新本地的 M c M_c Mc
- 并将 M c ′ M_c' Mc′上传到聚合FedServer
- 等待从FedServer上接收平均后的 M c f e d M_{c}^{fed} Mcfed
- 用接收后的 M c M_c Mc来提取数据特征
- Main Server
- 负责模型的推理和反向传播
- FedServer
- 负责 M c M_c Mc的接收、平均和下发
4.2 SFL的几种变体
- 基于服务器端聚合
- SFLV1
- MainServer模型中存在聚合特征部分
- SFLV2
- 删除MainServer模型聚合特征部分来增加模型准确性的可能性
- SFLV1
- 基于数据标签分享
- 将数据标签共享到服务器
- 基于MPC等技术
- 不共享任何数据标签到服务器
- SFL中的ML模型可以被划分为三个部分,假设是一个简单的设置。每个客户端将处理两个客户端模型部分;一个是W的前几层,另一个是W的最后几层和损失计算。W的剩余中间层将在服务器端计算。
- 将数据标签共享到服务器
6.反思
感觉这个方法真的很酷,但是工程上存在着网络等多种复杂情况。
这篇关于【论文阅读——SplitFed: When Federated Learning Meets Split Learning】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)