本文主要是介绍Leetcode算法训练日记 | day23,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、修剪二叉搜索树
1.题目
Leetcode:第 669 题
给你二叉搜索树的根节点 root ,同时给定最小边界low 和最大边界 high。通过修剪二叉搜索树,使得所有节点的值在[low, high]中。修剪树 不应该 改变保留在树中的元素的相对结构 (即,如果没有被移除,原有的父代子代关系都应当保留)。 可以证明,存在 唯一的答案 。
所以结果应当返回修剪好的二叉搜索树的新的根节点。注意,根节点可能会根据给定的边界发生改变。
示例 1:
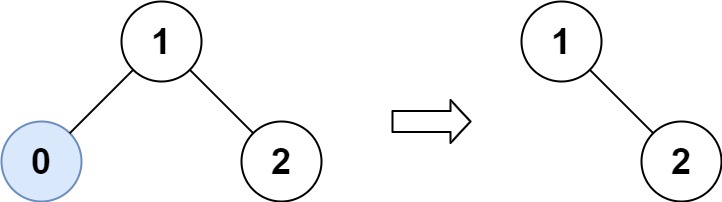
输入:root = [1,0,2], low = 1, high = 2 输出:[1,null,2]
示例 2:

输入:root = [3,0,4,null,2,null,null,1], low = 1, high = 3 输出:[3,2,null,1]
2.解题思路
利用二叉搜索树的性质来修剪树:任何节点的左子树中的所有节点的值都小于该节点的值,
任何节点的右子树中的所有节点的值都大于该节点的值。首先检查当前节点的值是否在 [low, high] 范围内。如果不在,根据当前节点的值与 low 和 high 的比较结果,递归地修剪掉不需要的子树。然后,递归地修剪当前节点的左右子树。最终,返回当前节点,因为它的值在保留范围内。
3.实现代码
#include <iostream>
#include <vector>
using namespace std;// 定义一个结构体TreeNode,用于表示二叉树的节点。
struct TreeNode {int val; // 存储节点的值。TreeNode* left; // 指向该节点左子树的指针。TreeNode* right; // 指向该节点右子树的指针。// TreeNode的构造函数,用于创建一个TreeNode实例。// 参数x是节点的值,left和right默认为NULL,表示没有左右子节点。TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};// 一、修剪二叉搜索树(递归法)
class Solution {
public:// 定义一个名为trimBST的公共成员函数,接受三个参数:二叉搜索树的根节点root,修剪的下限low和上限high。TreeNode* trimBST(TreeNode* root, int low, int high) {if (root == NULL) return NULL; // 如果根节点为空,递归结束,返回空指针。// 如果当前节点的值小于下限low,说明所有小于low的值都应该被修剪掉,递归修剪右子树。if (root->val < low) {return trimBST(root->right, low, high);}// 如果当前节点的值大于上限high,说明所有大于high的值都应该被修剪掉,递归修剪左子树。if (root->val > high) {return trimBST(root->left, low, high);}root->left = trimBST(root->left, low, high);// 递归修剪左子树,只保留在low和high之间的值。root->right = trimBST(root->right, low, high);// 递归修剪右子树,只保留在low和high之间的值。return root; // 返回当前节点,因为它的值在low和high之间,应该被保留。}
};// 二、修剪二叉搜索树(迭代法)
class Solution {
public:// 定义一个名为trimBST的公共成员函数,接受两个参数:二叉搜索树的根节点root,以及修剪的区间边界L和R。TreeNode* trimBST(TreeNode* root, int L, int R) {if (!root) return nullptr; // 如果根节点为空,直接返回空指针。// 处理头结点,让root移动到[L, R] 范围内。// 注意这里的处理方式是,如果当前节点的值小于L,就向右遍历;如果大于R,就向左遍历。while (root != nullptr && (root->val < L || root->val > R)) {if (root->val < L) root = root->right; // 如果当前节点的值小于L,向右子树移动。else root = root->left; // 如果当前节点的值大于R,向左子树移动。}TreeNode* cur = root; // 定义一个指针cur,用于遍历树。// 处理左孩子元素小于L的情况。// 这里通过不断向右遍历cur的左子树,直到找到一个值不小于L的节点或者没有左孩子为止。while (cur != nullptr) {while (cur->left && cur->left->val < L) {cur->left = cur->left->right; // 如果左孩子的值小于L,将左孩子指向其右孩子。}cur = cur->left; // 移动到当前节点的左孩子。}// 重新定义cur为root,因为我们需要处理右孩子大于R的情况。cur = root;// 处理右孩子大于R的情况。// 类似于处理左孩子,这里通过不断向左遍历cur的右子树,直到找到一个值不大于R的节点或者没有右孩子为止。while (cur != nullptr) {while (cur->right && cur->right->val > R) {cur->right = cur->right->left; // 如果右孩子的值大于R,将右孩子指向其左孩子。}cur = cur->right; // 移动到当前节点的右孩子。}return root; // 返回调整后的根节点。}
};
二、将有序数组转换为二叉搜索树
1.题目
Leetcode:第 108 题
给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵平衡二叉搜索树。
示例 1:

输入:nums = [-10,-3,0,5,9] 输出:[0,-3,9,-10,null,5] 解释:[0,-10,5,null,-3,null,9] 也将被视为正确答案:

示例 2:

输入:nums = [1,3] 输出:[3,1] 解释:[1,null,3] 和 [3,1] 都是高度平衡二叉搜索树。
2.解题思路
使用广度优先搜索来遍历有序数组,并根据数组中的元素构建对应的二叉搜索树。对于每个节点,
它都会计算出其左右子节点的区间,并创建子节点。然后,将子节点和对应的区间下标加入到队列中,以便后续处理。通过这种方式,可以确保每个节点都是按照有序数组的顺序被创建和连接的,从而构建出一个平衡的二叉搜索树。
3.实现代码
#include <iostream>
#include <vector>
#include <queue>
using namespace std;// 定义一个结构体TreeNode,用于表示二叉树的节点。
struct TreeNode {int val; // 存储节点的值。TreeNode* left; // 指向该节点左子树的指针。TreeNode* right; // 指向该节点右子树的指针。// TreeNode的构造函数,用于创建一个TreeNode实例。// 参数x是节点的值,left和right默认为NULL,表示没有左右子节点。TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};//一、将有序数组转换为二叉搜索树(递归法)
class Solution {
public:// 定义一个名为traversal的成员函数,用于递归地将有序数组nums的一部分转换为二叉搜索树的子树。// 参数nums是输入的有序整数向量,left和right分别是当前子树在nums中的左右边界。TreeNode* traversal(vector<int>& nums, int left, int right) {if (left > right) return NULL; // 如果左边界大于右边界,说明当前子树为空,递归结束,返回空指针。int mid = left + ((right - left) / 2);// 计算当前子树的中间索引。TreeNode* root = new TreeNode(nums[mid]);// 创建一个新的TreeNode实例,其值为中间索引处的值。root->left = traversal(nums, left, mid - 1);// 递归地构建左子树,将当前子树的左边界和中间索引减一作为左子树的边界。root->right = traversal(nums, mid + 1, right);// 递归地构建右子树,将当前子树的中间索引加一和右边界作为右子树的边界。return root; // 返回新创建的TreeNode实例作为当前子树的根节点。}// 定义一个名为sortedArrayToBST的成员函数,用于将有序数组nums转换为二叉搜索树。TreeNode* sortedArrayToBST(vector<int>& nums) {// 调用traversal函数,传入有序数组nums和数组的边界,初始化二叉搜索树。TreeNode* root = traversal(nums, 0, nums.size() - 1);return root;// 返回构建好的二叉搜索树的根节点。}
};//二、将有序数组转换为二叉搜索树(迭代法)
class Solution {
public:// 定义一个名为sortedArrayToBST的成员函数,用于将有序数组nums转换为二叉搜索树。TreeNode* sortedArrayToBST(vector<int>& nums) {if (nums.size() == 0) return nullptr; // 如果输入数组为空,直接返回空指针。TreeNode* root = new TreeNode(0); // 创建一个新的TreeNode实例作为根节点,初始值为0。queue<TreeNode*> nodeQue; // 定义一个队列用于存放待遍历的节点。queue<int> leftQue; // 定义一个队列用于存放左区间的下标。queue<int> rightQue;// 定义一个队列用于存放右区间的下标。nodeQue.push(root);// 将根节点入队。leftQue.push(0); // 将左区间下标初始位置0入队。rightQue.push(nums.size() - 1); // 将右区间下标初始位置(数组最后一个元素的索引)入队。// 广度优先搜索遍历数组和构建二叉搜索树。while (!nodeQue.empty()) {TreeNode* curNode = nodeQue.front();// 取出队列中的第一个节点。nodeQue.pop();int left = leftQue.front(); // 取出对应的左区间下标。leftQue.pop();int right = rightQue.front(); // 取出对应的右区间下标。rightQue.pop();int mid = left + ((right - left) / 2); // 计算当前节点的中间位置。curNode->val = nums[mid];// 将中间位置的元素赋值给当前节点。// 如果存在左子区间,则创建左子节点,并将其入队。if (left <= mid - 1) {curNode->left = new TreeNode(0);nodeQue.push(curNode->left);// 将左子区间的下标入队。leftQue.push(left);rightQue.push(mid - 1);}// 如果存在右子区间,则创建右子节点,并将其入队。if (right >= mid + 1) {curNode->right = new TreeNode(0);nodeQue.push(curNode->right);// 将右子区间的下标入队。leftQue.push(mid + 1);rightQue.push(right);}}return root;// 返回构建好的二叉搜索树的根节点。}
};
三、把二叉搜索树转换为累加树
1.题目
Leetcode:第 538 题
给出二叉 搜索 树的根节点,该树的节点值各不相同,请你将其转换为累加树(Greater Sum Tree),使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。
提醒一下,二叉搜索树满足下列约束条件:
- 节点的左子树仅包含键 小于 节点键的节点。
- 节点的右子树仅包含键 大于 节点键的节点。
- 左右子树也必须是二叉搜索树。
示例 1:
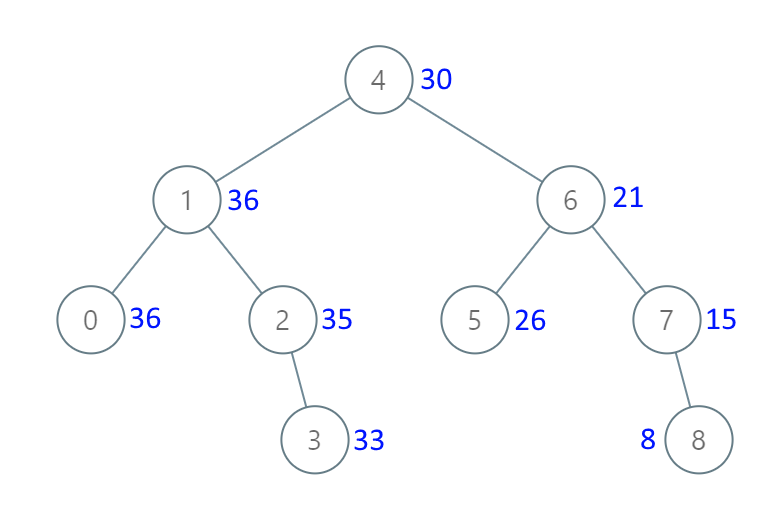
输入:[4,1,6,0,2,5,7,null,null,null,3,null,null,null,8] 输出:[30,36,21,36,35,26,15,null,null,null,33,null,null,null,8]
示例 2:
输入:root = [0,null,1] 输出:[1,null,1]
示例 3:
输入:root = [1,0,2] 输出:[3,3,2]
示例 4:
输入:root = [3,2,4,1] 输出:[7,9,4,10]
2.解题思路
利用二叉搜索树的性质(左子树的所有节点值小于根节点值,右子树的所有节点值大于根节点值)
来将一个标准的二叉搜索树转换为一个累加树(每个节点的值是其所有左子孙节点值的累加加上其父节点的值)。通过进行二叉树的遍历,保证了节点的访问顺序为右-根-左。在访问每个节点时,都会将节点的值加上累加器 pre 的值,然后更新 pre 为当前节点的新值,以便在访问左子树时进行累加。
3.实现代码
#include <iostream>
#include <vector>
#include <stack>
using namespace std;// 定义一个结构体TreeNode,用于表示二叉树的节点。
struct TreeNode {int val; // 存储节点的值。TreeNode* left; // 指向该节点左子树的指针。TreeNode* right; // 指向该节点右子树的指针。// TreeNode的构造函数,用于创建一个TreeNode实例。// 参数x是节点的值,left和right默认为NULL,表示没有左右子节点。TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};//一、把二叉搜索树转换为累加树(递归法)
class Solution {
public: int pre = 0;// 定义一个名为pre的成员变量,用于在遍历过程中累加节点的值。// 定义一个名为traversal的成员函数,用于递归地访问二叉搜索树的节点。void traversal(TreeNode* cur) {if (cur == NULL) return; // 如果当前节点为空,递归结束,直接返回。traversal(cur->right); // 首先递归访问当前节点的右子树。cur->val += pre; // 将当前节点的值加上累加器pre的值。pre = cur->val; // 更新累加器pre的值为当前节点的新值。traversal(cur->left); // 然后递归访问当前节点的左子树。}// 定义一个名为convertBST的成员函数,用于将二叉搜索树转换为累加树。TreeNode* convertBST(TreeNode* root) {pre = 0; // 重置累加器pre的值为0。traversal(root); // 递归访问根节点,开始转换过程。return root; // 返回转换后的二叉搜索树的根节点。}
};//二、把二叉搜索树转换为累加树(迭代法法)
class Solution {
public:int pre = 0;// 定义一个名为pre的成员变量,用于在遍历过程中累加节点的值。// 定义一个名为traversal的成员函数,用于递归地访问二叉搜索树的节点。void traversal(TreeNode* root) {stack<TreeNode*> st;// 定义一个栈st,用于存放二叉树的节点指针。TreeNode* cur = root; // 定义一个当前节点指针cur,初始指向根节点。// 当当前节点不为空,或者栈st不为空时,继续遍历。while (cur != NULL || !st.empty()) {// 如果当前节点不为空,将当前节点压入栈st,并将cur更新为当前节点的右子节点。if (cur != NULL) {st.push(cur);cur = cur->right;}// 如果当前节点为空,从栈st中弹出一个节点作为当前节点。else {// 弹出栈顶节点,并更新cur为该节点。cur = st.top();st.pop();cur->val += pre;// 将当前节点的值加上累加器pre的值。pre = cur->val;// 更新累加器pre的值为当前节点的新值。cur = cur->left;// 将cur更新为当前节点的左子节点,准备下一次循环。}}}// 定义一个名为convertBST的公共成员函数,用于将二叉搜索树转换为累加树。TreeNode* convertBST(TreeNode* root) {// 重置累加器pre的值为0。pre = 0;// 调用traversal函数,传入根节点,开始转换过程。traversal(root);// 返回转换后的二叉搜索树的根节点。return root;}
};
ps:以上皆是本人在探索算法旅途中的浅薄见解,诚挚地希望得到各位的宝贵意见与悉心指导,若有不足或谬误之处,还请多多指教。
这篇关于Leetcode算法训练日记 | day23的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









