本文主要是介绍【产量预测】基于matlab BP和GRNN神经网络预测粮食产量【含Matlab源码 1247期】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
⛄一、BP神经网络简介
1 BP神经网络概述
BP(Back Propagation)神经网络是1986年由Rumelhart和McCelland为首的科研小组提出,参见他们发表在Nature上的论文 Learning representations by back-propagating errors 。
BP神经网络是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。BP网络能学习和存贮大量的 输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用最速下降法,通过反向传播来不断 调整网络的权值和阈值,使网络的误差平方和最小。
2 BP算法的基本思想
上一次我们说到,多层感知器在如何获取隐层的权值的问题上遇到了瓶颈。既然我们无法直接得到隐层的权值,能否先通过输出层得到输出结果和期望输出的误差来间接调整隐层的权值呢?BP算法就是采用这样的思想设计出来的算法,它的基本思想是,学习过程由信号的正向传播与误差的反向传播两个过程组成。
正向传播时,输入样本从输入层传入,经各隐层逐层处理后,传向输出层。若输出层的实际输出与期望的输出(教师信号)不符,则转入误差的反向传播阶段。
反向传播时,将输出以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差信号即作为修正各单元权值的依据。这两个过程的具体流程会在后文介绍。
BP算法的信号流向图如下图所示
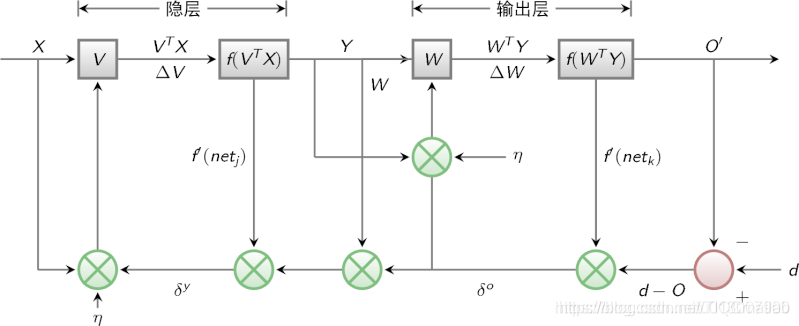
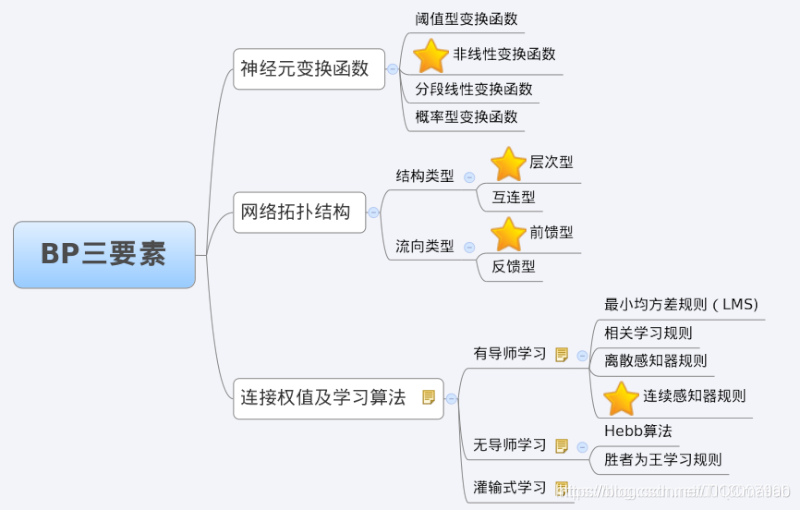
3 BP网络特性分析——BP三要素
我们分析一个ANN时,通常都是从它的三要素入手,即
1)网络拓扑结构;
2)传递函数;
3)学习算法。
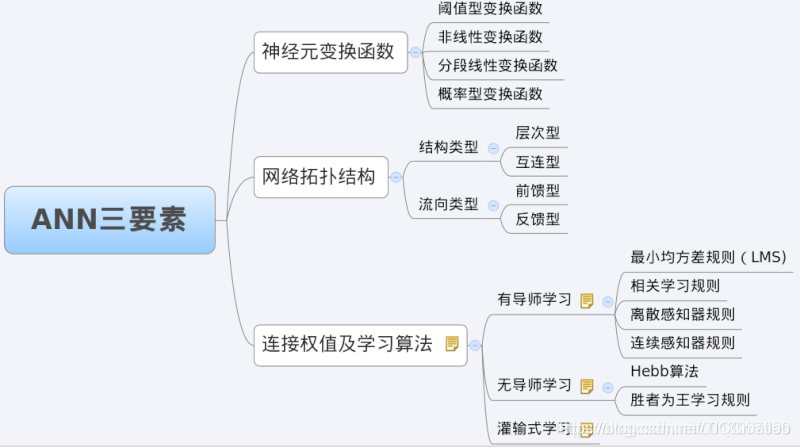
每一个要素的特性加起来就决定了这个ANN的功能特性。所以,我们也从这三要素入手对BP网络的研究。
3.1 BP网络的拓扑结构
上一次已经说了,BP网络实际上就是多层感知器,因此它的拓扑结构和多层感知器的拓扑结构相同。由于单隐层(三层)感知器已经能够解决简单的非线性问题,因此应用最为普遍。三层感知器的拓扑结构如下图所示。
一个最简单的三层BP:
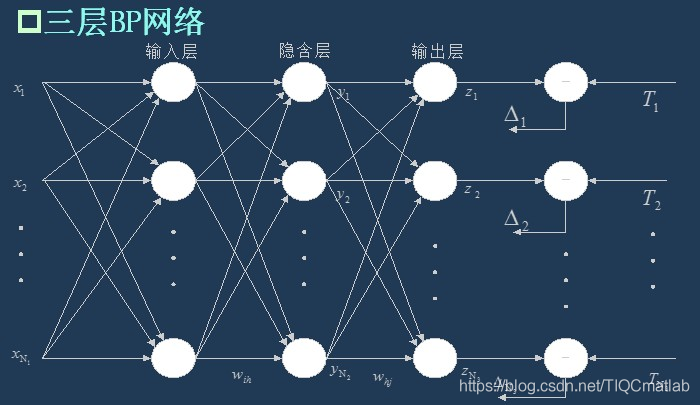
3.2 BP网络的传递函数
BP网络采用的传递函数是非线性变换函数——Sigmoid函数(又称S函数)。其特点是函数本身及其导数都是连续的,因而在处理上十分方便。为什么要选择这个函数,等下在介绍BP网络的学习算法的时候会进行进一步的介绍。
单极性S型函数曲线如下图所示。
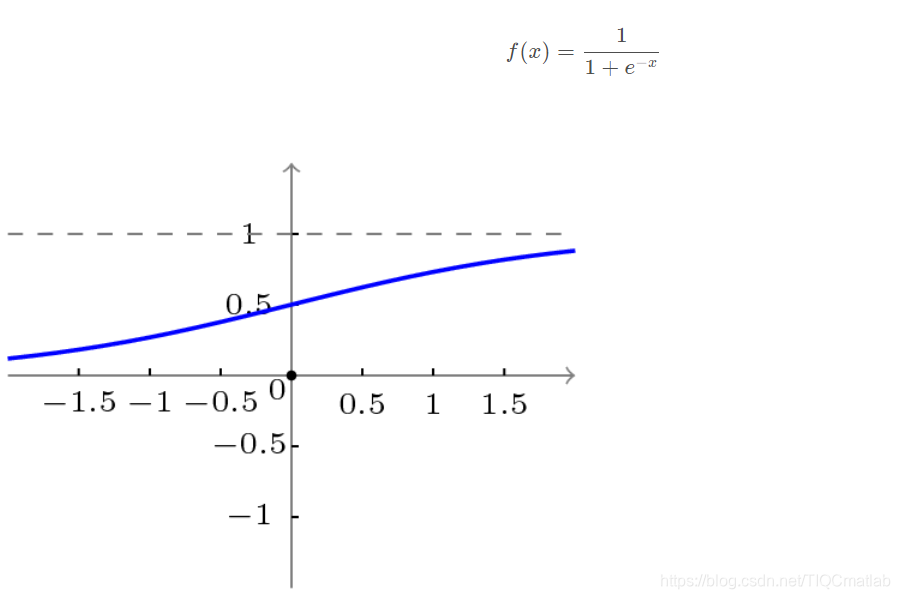
双极性S型函数曲线如下图所示。
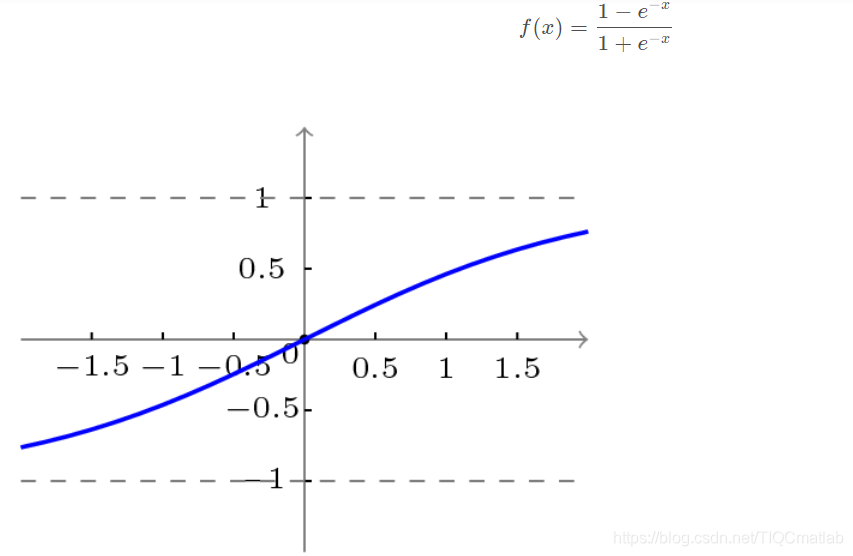
3.3 BP网络的学习算法
BP网络的学习算法就是BP算法,又叫 δ 算法(在ANN的学习过程中我们会发现不少具有多个名称的术语), 以三层感知器为例,当网络输出与期望输出不等时,存在输出误差 E ,定义如下



下面我们会介绍BP网络的学习训练的具体过程。
4 BP网络的训练分解
训练一个BP神经网络,实际上就是调整网络的权重和偏置这两个参数,BP神经网络的训练过程分两部分:
前向传输,逐层波浪式的传递输出值;
逆向反馈,反向逐层调整权重和偏置;
我们先来看前向传输。
前向传输(Feed-Forward前向反馈)
在训练网络之前,我们需要随机初始化权重和偏置,对每一个权重取[ − 1 , 1 ] [-1,1][−1,1]的一个随机实数,每一个偏置取[ 0 , 1 ] [0,1][0,1]的一个随机实数,之后就开始进行前向传输。
神经网络的训练是由多趟迭代完成的,每一趟迭代都使用训练集的所有记录,而每一次训练网络只使用一条记录,抽象的描述如下:
while 终止条件未满足:for record:dataset:trainModel(record)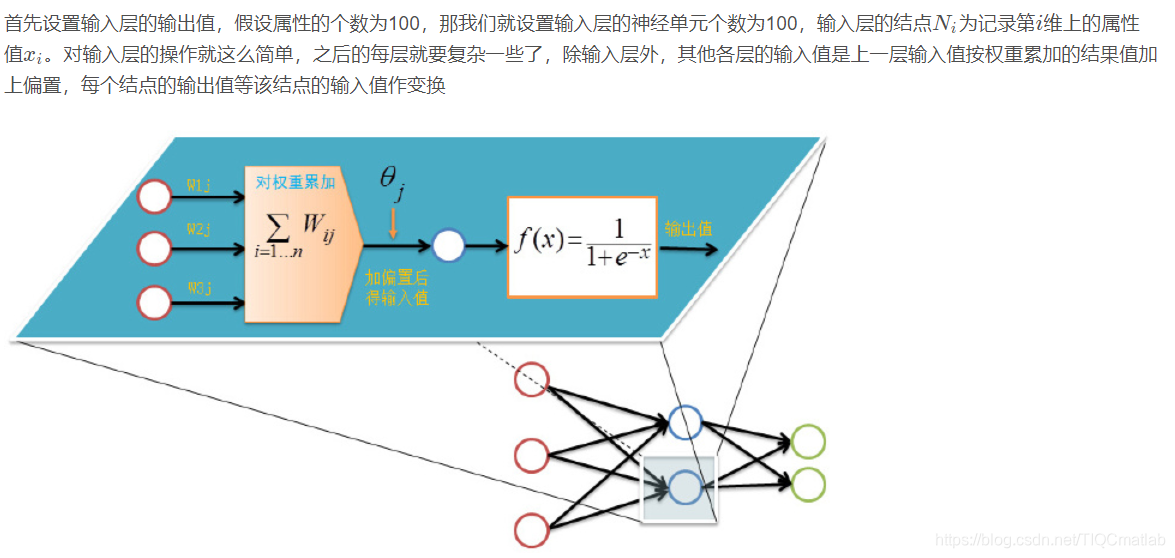

4.1 逆向反馈(Backpropagation)


4.2 训练终止条件
每一轮训练都使用数据集的所有记录,但什么时候停止,停止条件有下面两种:
设置最大迭代次数,比如使用数据集迭代100次后停止训练
计算训练集在网络上的预测准确率,达到一定门限值后停止训练
5 BP网络运行的具体流程
5.1 网络结构
输入层有n nn个神经元,隐含层有p pp个神经元,输出层有q qq个神经元。
5.2 变量定义


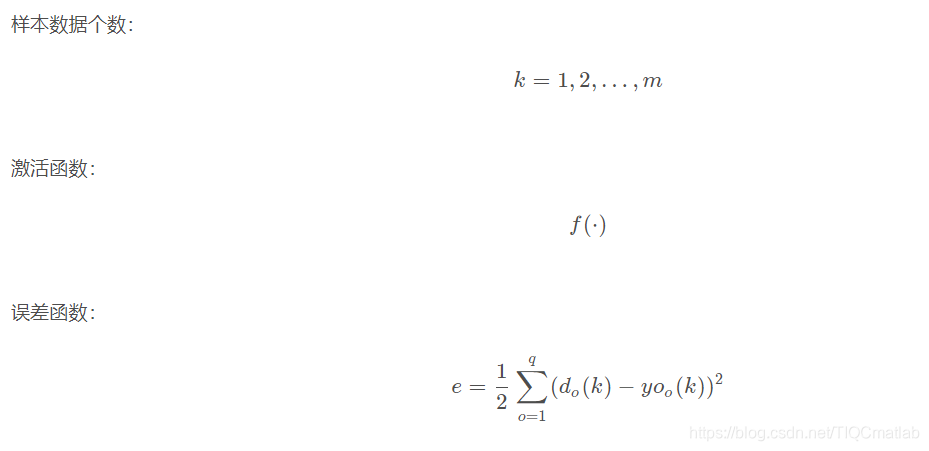


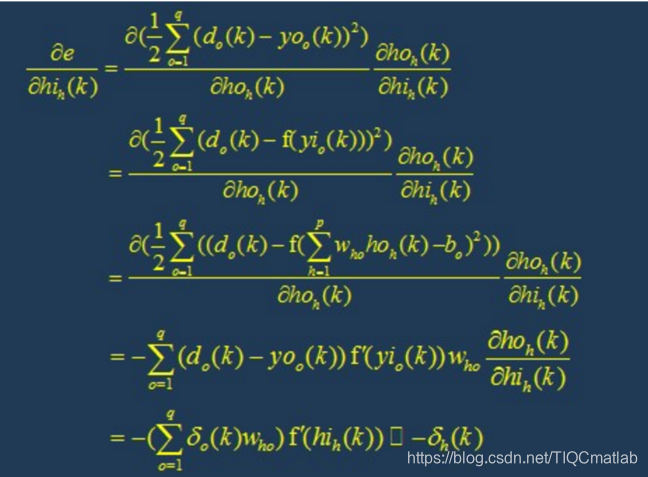


第九步:判断模型合理性
判断网络误差是否满足要求。
当误差达到预设精度或者学习次数大于设计的最大次数,则结束算法。
否则,选取下一个学习样本以及对应的输出期望,返回第三部,进入下一轮学习。
6 BP网络的设计
在进行BP网络的设计是,一般应从网络的层数、每层中的神经元个数和激活函数、初始值以及学习速率等几个方面来进行考虑,下面是一些选取的原则。
6.1 网络的层数
理论已经证明,具有偏差和至少一个S型隐层加上一个线性输出层的网络,能够逼近任何有理函数,增加层数可以进一步降低误差,提高精度,但同时也是网络 复杂化。另外不能用仅具有非线性激活函数的单层网络来解决问题,因为能用单层网络解决的问题,用自适应线性网络也一定能解决,而且自适应线性网络的 运算速度更快,而对于只能用非线性函数解决的问题,单层精度又不够高,也只有增加层数才能达到期望的结果。
6.2 隐层神经元的个数
网络训练精度的提高,可以通过采用一个隐含层,而增加其神经元个数的方法来获得,这在结构实现上要比增加网络层数简单得多。一般而言,我们用精度和 训练网络的时间来恒量一个神经网络设计的好坏:
(1)神经元数太少时,网络不能很好的学习,训练迭代的次数也比较多,训练精度也不高。
(2)神经元数太多时,网络的功能越强大,精确度也更高,训练迭代的次数也大,可能会出现过拟合(over fitting)现象。
由此,我们得到神经网络隐层神经元个数的选取原则是:在能够解决问题的前提下,再加上一两个神经元,以加快误差下降速度即可。
6.3 初始权值的选取
一般初始权值是取值在(−1,1)之间的随机数。另外威得罗等人在分析了两层网络是如何对一个函数进行训练后,提出选择初始权值量级为s√r的策略, 其中r为输入个数,s为第一层神经元个数。
6.4 学习速率
学习速率一般选取为0.01−0.8,大的学习速率可能导致系统的不稳定,但小的学习速率导致收敛太慢,需要较长的训练时间。对于较复杂的网络, 在误差曲面的不同位置可能需要不同的学习速率,为了减少寻找学习速率的训练次数及时间,比较合适的方法是采用变化的自适应学习速率,使网络在 不同的阶段设置不同大小的学习速率。
6.5 期望误差的选取
在设计网络的过程中,期望误差值也应当通过对比训练后确定一个合适的值,这个合适的值是相对于所需要的隐层节点数来确定的。一般情况下,可以同时对两个不同 的期望误差值的网络进行训练,最后通过综合因素来确定其中一个网络。
7 BP网络的局限性
BP网络具有以下的几个问题:
(1)需要较长的训练时间:这主要是由于学习速率太小所造成的,可采用变化的或自适应的学习速率来加以改进。
(2)完全不能训练:这主要表现在网络的麻痹上,通常为了避免这种情况的产生,一是选取较小的初始权值,而是采用较小的学习速率。
(3)局部最小值:这里采用的梯度下降法可能收敛到局部最小值,采用多层网络或较多的神经元,有可能得到更好的结果。
8 BP网络的改进
P算法改进的主要目标是加快训练速度,避免陷入局部极小值等,常见的改进方法有带动量因子算法、自适应学习速率、变化的学习速率以及作用函数后缩法等。 动量因子法的基本思想是在反向传播的基础上,在每一个权值的变化上加上一项正比于前次权值变化的值,并根据反向传播法来产生新的权值变化。而自适应学习 速率的方法则是针对一些特定的问题的。改变学习速率的方法的原则是,若连续几次迭代中,若目标函数对某个权倒数的符号相同,则这个权的学习速率增加, 反之若符号相反则减小它的学习速率。而作用函数后缩法则是将作用函数进行平移,即加上一个常数。
⛄二、广义回归神经网络(GRNN)
广义回归神经网络是径向基神经网络的一种,GRNN具有很强的非线性映射能力和学习速度,比RBF具有更强的优势,网络最后普收敛于样本量集聚较多的优化回归,样本数据少时,预测效果很好,还可以处理不稳定数据。虽然GRNN看起来没有径向基精准,但实际在分类和拟合上,特别是数据精准度比较差的时候有着很大的优势。
1 GRNN网络结构
GRNN是RBF的一种改进,结构相似。区别就在于多了一层求和层,而去掉了隐含层与输出层的权值连接(对高斯权值的最小二乘叠加)。


文字解析:
1.输入层为向量,维度为m,样本个数为n,线性函数为传输函数。
2.隐藏层与输入层全连接,层内无连接,隐藏层神经元个数与样本个数相等,也就是n,传输函数为径向基函数。
3.加和层中有两个节点,第一个节点为每个隐含层节点的输出和,第二个节点为预期的结果与每个隐含层节点的加权和。
4.输出层输出是第二个节点除以第一个节点。
⛄三、部分源代码
%%基于BP神经网络的粮食产量预测
clc
clear all
close all
format short
%% 载入数据
p=xlsread(‘粮食产量的8个影响因素.xls’);
t=xlsread(‘粮食总量和谷物、非谷物共3个量.xlsx’);
t1=1995:1:2009;
t2=1995:1:2014;
%训练数据
P_train=p(1:15,:)‘;%训练输入数据
T_train=t(1:15,:)’;%训练输出数据
%测试数据
P_test=p(1:20,:)‘;%测试输入数据
T_test=t(1:20,:)’;%测试输出数据
%数据归一化
%输入数据归一化
[Pn_train,inputps] = mapminmax(P_train,0,1);%原始训练数据归一化到0到1之间
Pn_test = mapminmax(‘apply’,P_test,inputps);%测试输入数据归一化到0到1之间
% 输出数据归一化
[Tn_train,outputps] = mapminmax(T_train,0,1);%原始输出数据归一化到0到1之间
Tn_test = mapminmax(‘apply’,T_test,outputps);%测试输出数据归一化到0到1之间
%建立网络
net=newff(minmax(Pn_train),[8,3],{‘logsig’,‘purelin’},‘trainlm’);
net=train(net,Pn_train,Tn_train);
%训练输入的预测结果
Tn_output= sim(net,Pn_train);
%仿真结果反归一化
T_output = mapminmax(‘reverse’,Tn_output,outputps);%反归一化的结果
%
figure
plot(t1,T_train(1,:),‘r-o’,‘linewidth’,2)
hold on
plot(t1,T_output(1,:),‘b-diamond’,‘linewidth’,2)
xlabel(‘训练样本’)
ylabel(‘粮食总量(万吨)’)
legend(‘实际值’,‘BP预测值’)
figure
plot(t1,T_train(2,:),‘r-o’,‘linewidth’,2)
hold on
plot(t1,T_output(2,:),‘b-diamond’,‘linewidth’,2)
xlabel(‘训练样本’)
ylabel(‘谷物产量(万吨)’)
legend(‘实际值’,‘BP预测值’)
figure
plot(t1,T_train(3,:),‘r-o’,‘linewidth’,2)
hold on
plot(t1,T_output(3,:),‘b-diamond’,‘linewidth’,2)
xlabel(‘训练样本’)
ylabel(‘非谷物产量(万吨)’)
legend(‘实际值’,‘BP预测值’)
%%BP仿真
Tn_sim = sim(net,Pn_test);%测试数据的仿真结果
%仿真结果反归一化
T_sim = mapminmax(‘reverse’,Tn_sim,outputps);%仿真结果反归一化
figure
plot(t2,T_test(1,:),‘r-o’,‘linewidth’,2)
hold on
plot(t2,T_sim(1,:),‘b-diamond’,‘linewidth’,2)
xlabel(‘测试样本’)
ylabel(‘粮食总量(万吨)’)
legend(‘实际值’,‘BP预测值’)
box off
figure
plot(t2,T_test(2,:),‘r-o’,‘linewidth’,2)
hold on
plot(t2,T_sim(2,:),‘b-diamond’,‘linewidth’,2)
xlabel(‘测试样本’)
ylabel(‘谷物产量(万吨)’)
legend(‘实际值’,‘BP预测值’)
box off
figure
plot(t2,T_test(3,:),‘r-o’,‘linewidth’,2)
hold on
plot(t2,T_sim(3,:),‘b-diamond’,‘linewidth’,2)
xlabel(‘测试样本’)
ylabel(‘非谷物产量(万吨)’)
legend(‘实际值’,‘BP预测值’)
box off
figure
plot(t1,t_train(1,:),‘r-o’,‘linewidth’,2)
hold on
plot(t1,train_out(1,:),‘b-diamond’,‘linewidth’,2)
xlabel(‘训练样本’)
ylabel(‘粮食总量(万吨)’)
legend(‘实际值’,‘GRNN预测值’)
figure
plot(t1,t_train(2,:),‘r-o’,‘linewidth’,2)
hold on
plot(t1,train_out(2,:),‘b-diamond’,‘linewidth’,2)
xlabel(‘训练样本’)
ylabel(‘谷物产量(万吨)’)
legend(‘实际值’,‘GRNN预测值’)
figure
plot(t1,t_train(3,:),‘r-o’,‘linewidth’,2)
hold on
plot(t1,train_out(3,:),‘b-diamond’,‘linewidth’,2)
xlabel(‘训练样本’)
ylabel(‘非谷物产量(万吨)’)
legend(‘实际值’,‘GRNN预测值’)
%测试数据仿真
test_out=sim(net,pn_test);
test_out=postmnmx(test_out,mint,maxt);
figure
plot(t2,t_test(1,:),‘r-o’,‘linewidth’,2)
hold on
plot(t2,test_out(1,:),‘b-diamond’,‘linewidth’,2)
xlabel(‘测试样本’)
ylabel(‘粮食总量(万吨)’)
legend(‘实际值’,‘GRNN预测值’)
box off
figure
plot(t2,t_test(2,:),‘r-o’,‘linewidth’,2)
hold on
plot(t2,test_out(2,:),‘b-diamond’,‘linewidth’,2)
xlabel(‘测试样本’)
ylabel(‘谷物产量(万吨)’)
legend(‘实际值’,‘GRNN预测值’)
box off
figure
plot(t2,t_test(3,:),‘r-o’,‘linewidth’,2)
hold on
plot(t2,test_out(3,:),‘b-diamond’,‘linewidth’,2)
xlabel(‘测试样本’)
ylabel(‘非谷物产量(万吨)’)
legend(‘实际值’,‘GRNN预测值’)
box off
⛄四、运行结果









⛄五、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1] 包子阳,余继周,杨杉.智能优化算法及其MATLAB实例(第2版)[M].电子工业出版社,2016.
[2]张岩,吴水根.MATLAB优化算法源代码[M].清华大学出版社,2017.
[3]周品.MATLAB 神经网络设计与应用[M].清华大学出版社,2013.
[4]陈明.MATLAB神经网络原理与实例精解[M].清华大学出版社,2013.
[5]方清城.MATLAB R2016a神经网络设计与应用28个案例分析[M].清华大学出版社,2018.
3 备注
简介此部分摘自互联网,仅供参考,若侵权,联系删除
这篇关于【产量预测】基于matlab BP和GRNN神经网络预测粮食产量【含Matlab源码 1247期】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









