本文主要是介绍Lotus开发性能优化 (II),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.主要因素
一般而言,以下因素对应用程序的性能影响最大:
- 视图的数量及其复杂性。删除不使用的视图或合并相似的视图。对于包含相同文档但使用不同排序的视图,使用一个可重新排序的列合并它们。删除不需要的列,并简化选择和视图列公式。检查是否存在您不能访问的“服务器私有”视图或其他视图。
- 在视图选择公式或列选择公式中使用 _cnnew1@Today 和 @Now。尽量避免这种情况。参见 IBM Support Web 站点技术文档 Time/Date views in Notes: What are the options?;并阅读本文下面的视图小节。
- 文档数量。文档越多打开的速度就越慢。可以考虑压缩旧文档或将主文档合并为单一文档。例如,如果您的主文档是一个“订单”,那么将订单上的每个“排列项”放到独立的文档中就是一个糟糕的做法。Lotus Notes 不是关系数据库,而是面向文档的数据库。
- 储存在文档中的摘要字段的数量。不属于富文本的字段称为“摘要”字段(尽管这个称呼过于简单化)。文档包含的摘要字段越多,将其编入到视图索引中所需的时间就越长(如果存在几百个字段,那么所需的时间将增加 30%)。只要字段存在,即使不在视图中使用它们,也会造成一样的结果。有时使用更少的文档却需要更多的字段,反之亦然;必须仔细考虑才能为提升性能做出正确的选择。
- 表单的复杂性。尝试将表单的数量限制为与实际需要的字段相等。表单越长,打开、刷新和保存它们所需的时间就会大大延长(并且视图索引器需要处理的字段也会增多)。
- 修改文档。对文档进行不必要的修改会增加索引器的负担,从而降低了视图索引的速度,并且还会影响复制和全文本索引的速度。
- 删除文档的数量。当删除一个文档时,就会留下一个称为“删除存根”的标记。复制程序需要根据这个标记决定是否从其他副本中删除相同的文档,或将“缺失”的文档复制到该副本。删除存根最终会过期(默认为 90 至 120 天),因此只要数据库保持正常的删除文档数量,就不会造成问题。
然而,我们见过一些应用程序包含的删除存根要比文档多好几倍。如果使用代理程序在夜间执行文档删除,然后从其他外部数据源创建新的文档,那么通常会出现这种情况。不要使用这种方法。您可以使用更高级的算法比较文档和源数据,从而确定应该更新或删除哪些文档。参见 Lotus Sandbox download 了解更多信息。
- Reader 字段。如果有必要使用 Reader 字段,那么必须使用它 —— 没有其他方法能够提供它所提供的安全性。但要注意它对视图的性能造成的影响,尤其是用户仅访问大量文档中的一小部分文档时。这份白皮书的视图小节讲述了一些减小该字段的影响的技巧,另外 developerWorks 文章 Lotus Notes/Domino 7 application performance: Part 2: Optimizing database views 也讨论了类似的主题。
- 用户数量。如果服务器上存在大量用户,那么将会影响应用程序和服务器的性能。当应用程序的性能已经处于临界状态时,添加新的用户会导致性能恶化。改良设计会有所帮助,但您还需要在其他服务器上创建副本(尤其是集群服务器),或鼓励用户创建更 快的本地副本。
2.数据库级别的性能因素
参考 Domino Designer 帮助文档“Properties that improve database performance”的数据库选项列表,您可以利用它调试性能。在很多情况下,这些选项通过削弱性能来获得其他功能;因此,对于特定应用程序不需要的功能,可以禁用它。
对性能有巨大影响的选项包括:
- Don't maintain unread marks。
- Don't maintain the "Accessed (In this file)" document property。如果“不进行维护”,您就不知道最后一次读取文档的时间。对长时间不读取的文档进行归档时,这个信息非常有帮助。
- Disable specialized response hierarchy information。如果禁用该项选,就不能使用 NotesDocument.Responses 属性,也不能使用 @AllDescendants 或 @AllResponses,它们偶尔用于视图选择公式和复制公式。
- Disable transaction logging。这个选项对性能的影响取决于管理员如何在服务器上设置它,以及用户的数量。如果用户很多,使用事务日志能得到更佳的性能。尝试启用和禁用该选项造成的影响。事务日志用于恢复。
- Optimize Document Table Map。如果应用程序包含的各种类型的文档大致相等,并且大多数视图仅显示一个类型(例如,SELECT Form = “xyz” & ...),这个选项就非常有用。如果视图选择公式都采用这种方式,并且先对表单进行检查,那么视图索引就会变快,因为这能立即排除不使用该表单的文档。
使用 NSFDB2(在 DB2® 数据库中存储 Domino 数据)并不能提升性能,事实上,使用传统的 NSF 文件还会更快一些。NSFDB2 的目标是添加功能,而不是提升性能。
全文本索引可能会占据大量的磁盘空间,但这通常是物有所值的。您可以利用全文本索引在代理中执行更快速的搜索,如果没有这个索引,用户必须使用更慢的搜索方法,这将导致长时间占用服务器,从而造成性能下降。
注意:在 8.0 版本的 Notes 中,一个新数据库属性使您可以关闭非全文本索引数据库的“全文本”搜索。一般而言,即使您拥有全文本索引,该选项也是很有用的;它确保索引被意外删除之后,用户会看到一条消息,而不仅是觉得性能无缘无故突然下降。
对于数据库,除了属性对话框之外,您还可以设置的另一个地方是 ACL 对话框。限制用户创建视图和文件夹能够减少服务器的负载(见图 1)。
图 1. ACL 对话框
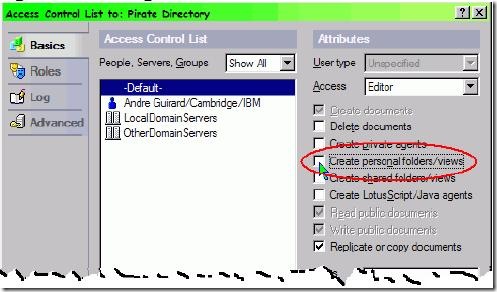
如果您取消选择“Create personal folders/views”,用户仍然能够创建私有视图,但创建的视图必须储存在本地的桌面文件中,而不是存储在服务器上。因此不会对应用程序的性能造成太大的影响。
桌面私有视图肯定会对性能造成影响,因为索引它们时用户必须从服务器实时提取数据。因此过多地使用桌面私有视图还会使服务器陷入困境。所以要避免为启用“Private on first use”选项的用户自动创建个人视图。(下面会对此进行详细阐述)。
3.公式性能
大部分 @ 函数都是相当快的,但有一小部分比较慢。因此要谨慎地使用它们:
- @Contains 的开销还不是十分大,通常用于测试列表是否包含某个值,这是一种低效的方法。例如,如果 Cities 包含值“East Lansing”,则表达式 @Contains(Cities; “Lansing”) 返回 True。如果这正是您需要的,当然很好;但如果您查找的是包含“Lansing”值的条目,那么应该使用 =、*= 或 @IsMember。这些函数更加快,因为如果第一个字符不匹配,它们就不再扫描整个字符串。
- @For 和 @While 通常可以被更高效的 @Transform 代替,或被其他对整个列表进行一次性操作的函数代替。
- @Unique 必须将列表中的每个值与其他值进行比较,因此执行时间与列表中的项数的平方成正比。对于其中的各个值都具有惟一性的列表,这个函数的表现会更好。后面还将对此进行讨论。
- @NameLookup 类似于 @DbLookup,但它仅用于目录信息。
- @DbLookup 和 @DbColumn。过度使用和错误使用这些函数是造成表单延迟的主要原因。下面将对此进行详细讨论。
我们通常不必要地使用了宏语言中的循环函数。尽管没有在这个 Domino
Designer 帮助文档中阐述宏函数,但几乎所有接受字符串参数的宏函数都可以对列表进行操作。例如,@Left(x; “,”),其中 x 是一个列表,它返回一个所有元素都被“左置”的列表。
注意:在以前,@UserRoles 和 @UserNamesList 函数都会造成严重的性能问题,但从 Lotus Notes 6.0 开始,这些函数的结果都将被缓存。
@DbLookup 和 @DbColumn
影响 @DbLookup 和 @DbColumn 的性能的 3 个主要因素是:
- 是否使用缓存
- 正在查找的视图是否高效
- 是否不必要地使用它们
使用缓存
许多开发人员过度地使用“NoCache”选项,尤其是在关键字公式中。这种现象很容易观察到,因为在开发和首次测试期间需要经常编辑关键字,因此NoCache(不使用缓存)是“正确的选择”。
然后,在应用程序投入使用之后,就不会经常编辑关键词。在出现新值时,迟一些再提供给用户可以得到更好的性能,这种代价是可以接受的。务必在必要时才使用“NoCache”选项。
有 3 个缓存选项:
- “Cache”(默认)仅对在应用程序会话期间对视图的首次查询起作用,它会记住该查找结果供以后使用,直到您退出应用程序。
- “NoCache”绕过缓存直接指向视图。如果存在同一查找的缓存值,将不更新缓存。
- “ReCache”是一个容易忽略的选项,它通常直接指向视图,但它也使用查找值更新缓存。通过使用 ReCache,您可以在特定时间更新缓存,比如在保存查找所引用的文档时。在其他时候也可以使用缓存值,因为您知道对于用户输入的信息而言,这个值至少是最新的。
为查找选择正确的视图
有时对 @Db 函数最高效的视图并不是最好的。例如,@U nique(@DbColumn(“”:“NoCache”; “”:“”; “InvoicesByCompany”; 1)) 存在几个问题:
- 它在这里不应该使用 NoCache。您并不是每天都添加一个公司,即使添加,也可以在 Invoice 表单的 Postsave 中使用“ReCache”选项,让新添加的名字立即可用。
- 当前的数据库是用表达式 “”:“” 指定的。相反,应该使用 “”,因为 “”:“” 不仅带有更多容易混淆的标点,而且它的计算速度也要慢一些。
- 不要查找带有重复值的列表,然后再使用 @Unique 删除重复内容。相反,您应该查找其值具有惟一性的视图列,因为它们来自一个已分类的列。
最后一点特别重要,因为使用 100 个测试数据文档时能够很好工作的列查找,在实际使用中性能就会急剧下降,因此此时应用程序面对的是数千个文档。尤其是在服务器上使用该应用程序时,需要通过网络将视图列的完整内容发送给用户工作站,这是需要时间的。从视图读取已经存在的惟一值要快得多。
注意:在获取惟一值列表时,似乎可以使用“Generate unique keys in index”选项代替已分类的列,但实际上它存在一些缺点,因此不适合该用途。
查找需要花很长时间索引的视图也是不明智的,尤其是在选择公式或列公式中使用@Today 或 @Now 的视图。如果您仅需查找特定日期的文档,那么可以对仅包含这些文档的视图使用 @DbColumn,对包含所有按日期排序的文档的视图使用 @DbLookup,并提供日期作为查找键。
避免重复查找
不必要地使用 @Db 函数的方式有好几种。这里给出一些常见的方式:
在公式中重复
@If(@IsError(@DbLookup(“”: “NoCache”; “”; “SomeView”; CustID; 3); “” @DbLooku p(“”: “NoCache”; “”; “SomeView”; CustI D; 3))
这个公式不仅使用了不需要的 NoCache,并且进行了两次查找(实际上一次查找就可以了)。下面是两个修改后的公式:
_tmp := @DbLookup(“”; “”; “SomeView”; CustID; 3); @If(@IsError(_tmp); “”; _tmp)
或
@DbLookup(“”; “”; “SomeView”; CustID; 3; [FailSilent])
在读模式中使用不必要的关键字查找
当打开文档进行查看时,对于某些类型的关键字字段,Notes 客户端不需要知道选择列表。但复选框和单选按钮字段除外,在其中甚至以读模式显示所有选项,并且所有使用关键字的内容都是同义词(“Display text|value”),因为文档仅储存“value”,而表单必须显示“Display text”。
但是在其他情况中,需要编写该关键字公式来延迟查找,直到您实际需要选择列表为止:
_t := @If(@IsDocBeingEdited; @DbColumn(""; ""; "Customers"; 1); @Return(@Unavailable));
@If(@IsError(_t); ""; _t)
通过在文档的读模式下返回 @Unavailable,公式会再次通知表单,让它询问随后是否需要选择列表。这将在用户切换到编辑模式并且指针点击该字段时发生。
因此,在用户仅查看文档时,您不仅要避免进行查找,并且要分散编辑文档时的延迟;8 个半秒延迟肯定没有一个 4 秒延迟那么烦人。如果用户的指针没有指向该字段,那么他们根本不需要进行查找。
在只需一个查找的位置使用多个查找
假设您将一个客户 ID 储存在“invoice”文档中,并想通过这个 ID 查找和显示客户的名称、地址和购买联系人姓名。这样,表单上就有几个 Computed for Display 字段,每个字段包含一个使用 @DbLookup(“”; “”; “CompanyByID”; CustID; x) 的公式,其中 x 是列号或字段名。
使用一个列来包含您需要的所有值会更高效,您可以从中找出每个字段值。因此这个列公式应该为:
CustName : StreetAddress : (City + “ ” + State + “ ” + Zip) : PurchasingContact
在您的表单上,添加一个隐藏的 Computed for Display 字段,名为 CustDetails,如下所示:
@DbLookup(“”; “”; “CompanyByID”; CustID; 4)
(假设合并的列为列 4)。然后,您就可以在需要显示名称的地方使用公式:
CustDetails[1] 等等。
在刷新时重复查找
假设您在组建表单时需要在计算字段中查找客户的经理的名字,如下所示:
@DbLookup(“”; “VOLE 1”: “EmpData. nsf”; “EmpByName”; @Name([CN]; @Username); “Manager”)
每次刷新表单时,都重新计算已计算的字段。许多表单需要经常刷新(因为您启用根据关键字字段的变化刷新字段的选项),因此这会严重影响速度。将字段设置为“Computed when Composed”会更好。
如果不需要将字段储存在文档中(记住,不要储存不需要存储的字段!),然后对它使用Computed for Display,但这个例子中,需要按照以下步骤避免在刷新时重复查找:
@If(@IsDocBeingLoaded; @DbLookup(“”; “VOLE 1”: “EmpData. nsf”; “EmpByName”; @Name([CN]; @Username); “Manager”); @ThisValue)
使用 @DbColumn 分配序列号
这是一个经常犯的错误。当设计人员必须为每个文档创建一个惟一的 ID 时,他们通常向最新的现有文档的编号加“1”。因此他们的公式如下所示:
tmp := @DbColumn(“”:“NoCache”; “”; “RequestsByNumber”; 1); nextNumber := @If(tmp = “”; 1; @ToNumber(@Subset(tmp; -1)) + 1); @Right(“000000” + @Text(nextNumber); 7)
这是一个非常糟糕的主意。随着文档数量的增长,@DbColumn 的执行时间会越来越长。此外,当应用程序有多个用户时,它不能保证 ID 是惟一的,尤其是存在多个副本时。
如果在文档保存之后再给它分配序列号,那么序列号在此之前是不可用的,这很不方便。不过,如果在创建文档时就给它分配序列号,这将留有充足的时间让其他人使用相同的序列号创建并保存文档。
您可能需要重新考虑自己的需求。有时应用程序实际上仅需要惟一的非数字标识符,而我们却总是要求使用序列号。仔细查看 @Unique 函数,它生成一个很短但基本上是惟一的值(通过一些额外的工作就可以保证惟一性,例如为每位用户添加一个惟一的“前缀”,通常是他们的名称的首字母)。
如果您决定真的需要使用序列号,那么请阅读 developerWorks 文章 Generating sequential numbers in replicated applications,它为使用序列号提供一种合理、高效的方法。一篇更多地讨论这个主题的 developerWorks 文章即将发布。
4.表单设计
在这个小节中,我们将解决一下值得关注的问题。
能使用 Computed for Display 字段就不要使用 Computed 字段
因为存储字段一般都会使应用程序变慢,所以如果能够在需要时轻松地计算这些值,就应该避免存储值。这里有一个折中;当文档以读模式打开时,不会计算 Computed 字段,因此如果它是一个很慢的公式,则最好储存值,这样能够改善读模式的性能(另一方面,这还意味着它会过期)。
但一定不要使用 Computed 字段重新显示另一个字段的值 —— 这样会存储相同信息的两个副本。
大量使用字段
在一个表单中使用大量字段的最常见原因是,一个表有多个行和列的信息,并且每个单元格有一个字段,超出了支持的行数。这是一种棘手的情况,因为到目前为止使用表单是最简单的办法。
不过,还有其他办法可以管理表的值。最常见的办法是将表放到一个富文本字段中,然后让用户根据需要进行填充(在富文本字段的默认公式中使用 @GetProfileField 从配置文件文档读取一个“starter”表)。这样做的缺点是用户在填写表格时不能获得帮助,要是存在私有字段的话,就可以提供关键字列表、转换和验证。不过,有时这也是一种可接受的办法。
现在已经发布一些工具和技术,可以在对话框中每次仅编辑表的一行,然后在表中显示结果。例如,Lotus Sandbox 中的 Domino Design Library Examples 包含一组设计元素,可用于在表中编辑和显示数据,而不要求每个单元格必须有一个字段。在名为“Table Editor”的数据库文档中,将详细描述这个系统。需要付诸一定的努力才能实现它,但它对性能非常有帮助。
有时,我们在大部分文档中可以看到包含许多空字段的表单。例如,大约 5% 的文档需要一个包含 50 个字段的“Regulatory Approval”部分。而其余 95% 的文档则存储了这些空字段,这不仅浪费空间,而且还造成糟糕的性能
对于这种情况,使用两个不同的表单可能更好 —— 一个包含必需字段的主表单,和一个分开的“Regulatory Approval”表单,它可能是对原始文档的响应,或者仅在需要时创建。在这里,可以通过使用额外的文档来避免使用更多的字段。
不要忘记多值字段。除了通过 5 个字段让用户输入 5 个不同的值之外,还可以使用一个可以输入多个值的字段。对条目的数量没有任何限制(除非您选择必须使用一个),并且生成的值在视图和公式中更容易 使用。
注意:如果应用程序已经因为字段过多而变慢,仅编辑设计元素是于事无补的;您必须编写代理程序遍历现有文档,并从中删除多余的条目。已经出现一些业务合作产品可以简化这个过程。不过,如果您的更改是一个重大的重组,比如将一些字段移动到特定的响应文档中,那么代理程序的编写是相当复杂的。设计时从长远考虑,争取第一次就把事情做好,这能节省很多时间。
图像过多
有些表单无节制地使用图像,对背景使用大型位图以及使用许多其他图像修饰。大图像需要更长的加载时间、占用设计元素的缓存,并且查看表单时需要更长的图像呈现时间。创建表单时稍加注意就可以得到比较专业的外观,并且不会对性能造成太大的影响。下面是一些技巧:
- 不要将图像复制粘贴到表单上;相反,要么使用图像资源设计元素,要么导入图像。如果您计划在多个表单中使用同一个图像,那么可以使用图像资源,因为它允许客户端将图像与表单设计分离,然后再缓存它。即使您不打算 在多个表单中使用同一个图像,将图像作为资源也是一个不错的主意,因为以后其他人可能需要使用该图像创建另一个表单。
- 将图像放到表单上之后,不要随意缩小它的尺寸。使用图像编辑器(比如,GIMP)将原始图像缩小为您所需的尺寸 —— 即使您需要的是同一图像的多个大小不同的图像资源,也必须这么做。
如果图像的格式为 JPEG,那么可以尝试不同的压缩设置,看看能不能减小它的体积。JPEG 压缩是“有损耗”的,因此压缩后图像可能会失真,但如果您在不影响视觉效果的情况下最大限度地压缩图像,可以加快表单的加载速度。您可以购买图像工具,它们能帮助您找到一个平衡点。
- 对图像使用正确的文件格式。如果图像使用有限的调色板(就像大部分徽标),GIF 格式的图像文件可能是最小的。如果使用全色照片或绘画,JPEG 可能是更好的选择。不要使用 BMP 格式的文件,因为它们的压缩比很小。
- 呈现表单元格和图像单元格的背景需要一定的时间。隐藏单元格边框的表单比显示边框的表单的呈现速度快,尤其是使用 3-D 效果的边框。与嵌套在其他表内部的表相比,使用合并单元格的表的呈现速度更快。
存储表单
不要使用存储表单。
自动刷新字段
一般不要使用表单选项“Automatically refresh fields”。这个选项会在编辑表单时频繁刷新它,重新计算已计算字段和输入转换公式,从而造成延迟。使用字段级别的选项“Refresh on keyword change”或字段事件 Onchange 或 Onblur 会更好,它们只在需要时进行刷新。
过多的共享设计元素
表单可以从其他设计元素获取信息,比如图像资源、共享字段、共享操作、子表单、摘要、样式表和脚本库。打开一个文档可能会从除表单之外的许多其他设计元素读取信息,读取过程是需要时间的。共享设计元素的优点是使应用程序的维护更加容易,而它的不足之处是访问多个元素需要更长的加载时间。
Lotus Notes 缓存设计信息,因此不需要每次都从原始设计元素读取设计信息;然而,首次加载可能是个问题。缓存意味着使用共享设计元素可以提升性能,如果需要在许多不同的表单中使用相同的子表单或图像的话。
共享操作不会损害性能,因为仅有一个设计元素包含共享操作,所以多添加几个共享操作与使用一个共享操作所需的开销是一样的。共享视图列也不会影响性能。
由于共享设计元素有利于维护,所以除非采取各种措施仍然不能得到可以接受的性能,否则不推荐取消设计元素共享。
5.视图
由于以下原因,低效和不必要的视图会造成延迟:
- 打开视图时需要时间更新索引。
- 当在 @Db 函数中使用视图时,需要时间获取信息。
- 服务器上的更新任务会定期检查每个视图,看看是否需要使用最近修改的文档更新它们。因此视图越多(或越复杂),就越长时间地占用服务器,导致所有应用程序变慢。
视图打开缓慢的另一个常见原因是数据库中存在大量文档。当您打开视图时,Lotus Notes 将检查在最后一次视图索引更新之后是否修改了某些文档。您拥有的文档越多,检查所需的时间就越长,即使最终结果是“没有最近修改的文档”。
视图中的 @Now 或 @Today
已经有许多文章介绍在不使用 @Today 或 @Now 时如何提供基于日期/时间的视图。其中的一个例子就是 IBM Support Web 站点技术文档 Time/Date views in Notes: What are the options?,它提供一些创建基于日期/时间的视图的方法。
现在我们对其他几个方面进行讨论。首先,经常建议使用的@TextToTime(“Today”) 是不完整的。现在它仅适用于第一天。您必须修改它,让它能够正确地工作。
为什么?一般情况下,当您打开一个视图时,Lotus Notes 就会查看“视图索引” —— 视图中存储的文档和行值的列表 —— 并仅检查自索引最后一次更新之后创建或修改的文档,以决定是否将它们添加到视图,或删除它们,或重新计算它们的列值。如果自从最后一次使用视图之后没有修改任何文档,这个过程就会很快。
不过,如果您使用 @Today,旧的视图索引就没有用了。例如,假设选择公式为:
SELECT Status = “Processing” & DueDate <= @Today
可以将文档添加到该视图,即使这些文档并没有改变,因为自从上一次使用视图之后,@Today 的值就改变了。因此您每次使用这个视图时,Lotus Notes 都会丢弃旧的视图索引,并查看数据库中的每个文档,以决定这些文档是否属于该视图,或重新计算列值。
如果您使用 @TextToTime(“Today”) 而不是 @Today,那么您就可以“胜过”视图索引器。祝贺您!Lotus Notes 将重用旧的视图索引,并仅检查被更改的文档。这会得到更快的速度,但不幸的是得出的结果是错误的,因为当 @Today 改变时,我们必须重新检查所有文档。 不必要的视图
假设您有一个列,如果“请求”文档在3个小时之后仍然打开的话,它将显示一个红色的感叹号(使用 @Now 测试它)。这种情况会发生变化,即使在5秒钟之前还在使用该视图。然而使用 @Today 时,降低视图索引的更新频率可能更好。
您可以使用视图属性对话框中的视图索引选项实现这个目的。在 Advanced options 选项卡上,您可以将视图更新指定为“Auto, at most every x hours”,其中 x 是您指定的值。这样做的优点是大大加快了视图的打开,但同时也存在缺点,那就是视图不会立即显示文档更改,即便文档已更改。用户必须手动刷新视图才能看到最新的数据。
另一个流行的代替办法就是创建一个在夜间运行的调度代理程序,它通过更新视图选择公式(使用 NotesView.SelectionFormula 方法)来包含当天的选择公式。例如,代理程序可能包含以下语句:
view.SelectionFormula = {SELECT Status=“Processing” & DueDate=[} & Today & {]}
不过,它也有一些缺点:
- 在所有副本显示正确的文档之前,必须在所有地方复制视图设计更改。
- 服务器管理员可能不信任更改产品应用程序的设计的代理程序。
- 第二天早上打开视图的第一位用户仍然需要等待索引视图。您可以将视图索引选项设置为“Automatic”,或让代理程序刷新视图,这样就能够避免这个问题。
- 如果数据库从模板获取设计,您的视图将被模板覆盖。为了避免这个问题,您可以让代理程序在夜间设计刷新之后再运行,或将更改应用到模板。
另一个办法就是在用户界面上做出让步。例如,您可以对视图使用 “open requests by due date ”而不是“open requests that are overdue”,以在视图的顶部对延迟的请求进行排序。它们很容易实现,实现之后视图的打开会快得多。
在一些情况下,适合使用文件夹根据日期条件显示一组文档。在夜间运行的代理程序可以使用满足该日期需求的文档填充这个文件夹,并且文件夹上的访问设置可以阻止用户手动更改其内容。如果在白天编辑文档时需要更改文件夹的内容,这就不是一个好选择(虽然比较繁琐,但您还可以使用定制代码进行管理)。
许多应用程序很慢,因为它们包含太多视图,删除一部分视图将有所帮助。性能影响一般出现在服务器上,而不是特定的应用程序。
注意:数据库的设计器不一定要访问每个视图。用户的“Server private”视图和其他带有读者列表的视图是不可见的,但它们仍然会影响性能。服务器管理员可以在“Full access administration”模式下查看这些视图。
默认的视图刷新设置(Auto after first use, Discard index after 45 days)意味着超过 45 天后不使用的视图索引将被丢弃,并且服务器不会再刷新它们。在这点上,它们对服务器性能的影响是很小的。然而,在摘要中使用视图可能会导致用户在搜索所需视图时意外地使用它们。
因此,通过仅包含必要的视图(用于完成用户的特定任务,其命名方式便于用户辨认),您不但可以改善性能,而且还提供更好的用户体验。
通常需要为某个目的创建一次性使用的视图,并且没有程序记录谁需要它们,谁使用它们,以及何时能够安全地删除它们。它们常常是“Server private”视图,仅对它们的创建者是可见的,但它们仍然会影响性能。限制创建此类视图能够保持更好的性能(如果您想看看有哪些私有视图,服务器管理员可以使用“Full access administration”模式列出它们)。
我们推荐对视图使用 Comment 字段,用于描述视图的任务、使用者和超过该日期就可以删除视图的“过期”日期(如果知道的话)。这样,如果您对是否有必要使用视图存在疑问,您至少知道应该问谁。如果您想删除一个视图,看看是否有人反对,可以将其复制粘贴到另一个未包含有文档的数据库,这样您就可以在需要时找到它。
通常,应用程序包含的视图仅是排列方式不同而已。这些视图应该使用可重新排序的列合并到一个视图中。尽管添加重新排序列的成本很高,但这要比拥有第二个视图的成本低。
如果您在 Lotus Notes 8.0 中使用新的列选项“Defer index creation until first use”,那么就更应该这样做了。这个选项延迟为重新排序创建索引,直到用户请求它。这会给首位请求用户造成很长的延迟,但如果没有人请求的话,大家都能享受到更好的性能。
私有视图
当您查找不需要的视图时,要记住,开发人员不一定能够查看应用程序中的所有视图。如果用户在服务器上存储了私有视图,或者共享视图的访问列表没包含您的名字,那么您就不能在设计器中查看这些视图 —— 但它们仍然会影响性能。使用“Full access administration”模式的服务器管理员可以绕过访问控制获得所有视图的列表(并删除任意视图)。
不必要的重新排序
因为服务器必须通过额外工作才能在请求时执行交替视图排序,所以除非有必要,否则不要启用重新排序。升序和降序计数是两种不同的重新排序,因此除非实际需要,否则不要同时启用它们。在 Lotus Notes 8.0 中,如果您不确定是否使用了重新排序,那么可以启用该列上的“Defer index creation until first use”选项。
注意,您还可以选择通过单击列的头部,将用户导航到已由该列完成排序的不同视图,这样您就可以为重新排序提供便利,并且省去额外的工作(如果另一个视图已经存在)。
不必要的列
我们倾向于为每个字段创建一个列,但应该避免这样做。仅在视图中包含用户实际需要查看的信息即可;这样屏幕就不会那么拥挤,并且应用程序的速度会更快,占用的存储空间会更少。
过于复杂的公式
如果视图列公式或选择公式使用了循环函数(@For、@While和@Transform),或除注释之外超过 200 个字符,那么就需要简化它。如果不能简化它,那么考虑将公式移动到表单的计算字段,让视图仅引用字段名。对于在多个视图中使用的公式,这尤其有用。
即使您不使用计算字段,对于较长的公式,稍微思考一下就能简化它。考虑使用 @Select 或 @Replace 代替较长的 @If 语句,并检查逻辑,看看是否能够通过不同的顺序简化测试。
要注意对列表的所有成员执行操作的运算符和 @Functions。没有必要为字符串列表上的许多简单操作编写循环;例如,要获取每个元素的前三个字符,可以使用 @Left(listfieldname; 3) 来实现。
我们还有一些“组合操作符”,比如 *=,可用于比较来自两个列表的组合元素,并且也能帮助您编写更加紧凑的公式。
如果您使用其他语言编写程序,您可能对逻辑运算符比较熟悉,它们仅对能够决定连接值的表达式进行计算。例如,您可能希望得到这样的表达式:
Form = “Report” & ( Sections = “Financials” | Total > 10000)
首先检查 Form 是不是 Report,当这个条件为真时,才测试表达式的其余部分。在宏语言(和 LotusScript)中,逻辑运算符不是这样工作的。表达式的两部分都要计算。所以,如果计算第二部分的开销比较大,您可以选择如下所示的“懒惰逻辑”公式:
@If(Form = “Report”; Sections = “Financials” | Total > 10000; @False)
@If 函数的执行时间比 & 运算符长,但如果能够通过它避免执行一些不必要的大开销函数,您就领先一步了。
过度使用多个分类
分类是非常有用的。它们允许在同一视图的多个标题下列出某个文档。但不要过度使用它,因为在一个视图任务中两次列出某个文档所需的时间几乎翻了一倍。如果每个文档分别列出在 50 个类别中,再乘以文档数就得出总行数,那么服务器需要存储和计算多少个行?这会给服务器带来很大的压力。
即使您不使用多个 分类,经过分类的视图仍然比使用简单排序的视图慢。所需的时间取决于行数,而不是文档数,并且每个文档和类别标题都是一个行。
过度使用索引
视图属性对话框包含一组控制视图索引的选项。这些选项很少用到,但选择正确的索引选项能够大大提升性能。
例如,假设数据库包含特定的关键字文档,您需要频繁查找它们以填充表单上的关键字列表。关键字文档是很少更改的,但应用程序中的其他文档则需要经常更改。
在讨论 @DbLookup 时我们已经知道对这种查找使用缓存是最好的,但第一次必须直接访问视图,因为还不存在缓存值。当您执行这个过程时,Lotus Notes 发现在最后一次使用视图之后文档被更改了,然后将花时间查找被更改的文档,并发现它们并不在视图中。
对于在关键词值 @DbLookup 中使用的视图,不需要在每次使用时都进行重新索引。对于这种视图,使用索引选项“Auto, at most every x hours”比较合适(见图 2)。
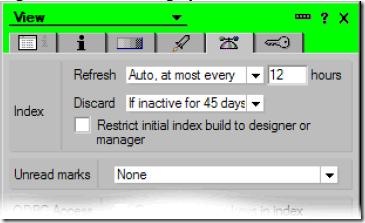
如果没有人使用这些视图,服务器仍然会更新它们,但时间间隔要长些。偶尔可能会有不幸运的用户刷新索引。但这会导致平均查找时间更短,并且同一个用户在复杂表单的每个查找中都碰到刷新的机会不大,因此使用该选项后表单的打开速度会更快。
如果仅在每个季度的季度审核时才使用视图,那么将索引保留 45 天没有任何意义。将其设置为在 2 天之后丢弃,这样能够减轻服务器的工作。
在其他情况下,选择适当的索引选项能够改善性能。想办法确定您的视图应该使用什么设置是值得的。
注意:可以通过程序在当前的副本中刷新索引,比如使用 NotesView.Refresh 方法。假设一个索引在正常情况下很少更新,但当您保存某个向视图提供数据的表单时,则必须更新视图,以在查找中使用新的数据。在表单的 Postsave 代码中,对视图使用 Refresh 方法。同时,您可以使用带有 ReCache 的 @Db 函数,将特定查找的缓存更新到视图。
Reader 字段
当您需要 Reader 字段时,没有什么东西可以代替它,但它可能会大大损害视图性能。当您打开包含带有 Reader 字段的文档时,Lotus Notes 会对行进行扫描,查找您可以访问的行。当行的数量填满屏幕时,将停止查找。如果您仅能访问一个文档,它必须查看视图中的每个行进行确认,这可能需要花很长时间。
对此,您可以:
- 使用比较短的 Reader 字段值。在单一角色中检查成员关系要比根据一个长长的访问名称列表比较它们快(使用角色还便于维护)。
- 避免在这种应用程序中使用视图。如果用户仅能访问一两个文档,您可以提供其他访问方式,例如,向他们发送包含有这些文档链接的电子邮件。
- 使用嵌入式单类别视图,这种视图仅显示包含“它们的”文档的类别。
- 使用设置为显示空类别(即未包含文档的类别)的分类视图。当然,这样做使得用户查找文档更加困难,除非您为用户提供导航,因此您应该将该功能和 @SetViewInfo 结合使用,以仅显示用户所需的类别。
注意:使用分类视图存在安全问题;即您在文档中向用户显示了一个字段(类别),他们本来是不可以访问该字段的。要确保使用这种办法是可行的!
- 鼓励用户使用本地副本。因为本地副本仅包含用户能够访问的文档,因此不需要花功夫隔离他们不能访问的文档。
不要单独使用 Reader 字段作为导航帮助;例如,这是一种帮助用户方便地查找所需文档的方法,因为它们是用户能够在视图中看到的所有文档。如果文档中的信息不是隐私的,还有其他更好的方法可以帮助用户找到所需的文档,如前一小节和下一小节所述。
Private on first use
在共享视图的选择或列公式中使用 @UserName 和 @UserRoles 时,不能得到满意的结果。这是开发人员创建仅显示“My Documents”的“Private on first use”视图的常见原因。这些视图可能存储在服务器上(将从总体上影响应用程序的性能),或者存储在用户的本地“桌面”文件中。
桌面视图不会直接影响服务器的性能,但当打开其中一个视图时,将像其他视图一样进行重新索引,以显示最近的更改。这意味着用户工作站必须向服务器请求自从最后一次使用之后修改的所有文档。这个过程可能造成用户等待,如果许多用户执行该操作,服务器还可能会因为大量发送数据请求而陷入困境。
注意,视图索引仅使用摘要 数据,因此大型的富文本字段和文件附件在这里不构成问题。
除了性能问题之外,私有视图还面临维护方面的问题,因为开发人员没有简单的方法更新用户私有副本的设计。在这种情况下,共享列也不起作用,因为要在视图中更新共享列,执行更新的人员必须能够访问该视图。
通常可以使用 Notes 视图的“single category”功能避免“Private on first use”。例如,如果您正在显示“My Documents”,您可以使用根据所有者分类的视图,然后要么使用“single category”公式将该视图嵌入到表单或页面中,要么在视图中的 Postopen 事件中使用 @SetViewInfo,仅对当前用户进行显示。因为只有一个共享视图,所以总体索引开销降至最低,并且私有用户不必像在桌面私有视图中那样等待,因为索引几乎总是最新的。
6.代码
当您开始编写 LotusScript 或 JavaTM 代码时,您可能就开始逐步损害性能。在这里,我们讨论一些常见的问题。
GetNthDocument
使用 NotesDocumentCollection.GetNthDocument 遍历集合是非常慢的;应该改用GetFirstDocument 和 GetNextDocument。对于某些类型的集合使用 GetNthDocument 也一样高效,但不使用它事情更好办。
表单或视图包含的操作代码过多
如果表单、视图或文件夹有许多操作,您就需要在设计元素中为每个操作编写代码(使用共享操作也是如此),这样就存储了许多代码,每次使用设计元素时都必须将它们加载到内存中。
在大部分时间,仅用到许多操作中的其中一两个,因此您需要等待加载所有操作。如果操作出现在多个地方,您就在设计缓存中多次缓存了相同的代码,从而占用应该用于其他用途的内存。
可以考虑将一些操作移动到代理程序中。这样,当有人请求运行操作时,仅在内存中加载一个代码副本。可以用宏语言编写操作按钮,以使用 @Command([RunAgent]) 调用代理程序,这能大大减少随设计元素一起加载的代码。
如果您允许用户创建私有视图或文件夹时,这尤为重要,因为他们的文件夹将多次复制操作代码,这不仅占用空间,而且还不能进行更新,除非用户手动删除私有视图。
脚本库过多
加载多个脚本库所需的时间并不是线性增长的。即加载 10 个脚本库所需的时间比加载 5 个脚本库所需的时间的 2 倍还要多,脚本库使用了其他库时尤其如此。
这在未来可能会得到改变,尽管如此,也存在一个平衡点;访问两个设计元素比访问一个包含相同数量代码的设计元素所需的时间长。将经常一起使用的脚本库合并起来能够节省加载时间,尽管有时会加入不需要在特定代理程序中调用的代码。
ComputeWithForm
NotesDocument 的 ComputeWithForm 方法是在文档中更新计算字段但不复制代码的便捷方法。不幸的是,这比“手动”计算和分配新字段值更慢。如果您的代理程序很慢并且使用了 ComputeWithForm,向 ComputeWithForm 添加几行用于为特定字段赋值的代码就能够大大加快程序的速度。
自动更新视图
默认情况下,使用 NotesView 对象时,它将为视图实现常规的索引刷新属性。例如,假设您更新一组“Vegetable”文档,作为这个过程的一部分,您必须在同一数据库下的“Pests”视图中查找破坏该植物的害虫。但是当您保存了一个 Vegetable 文档时,另一个文档又被更改了。
当您处理下一个文档,并查找“Pests”视图时,Lotus Notes 就知道视图索引已经过期,然后刷新它。您所做的更改不会影响 Pests 视图,但在检查已更改的文档之前,Lotus Notes 并不知道这点。
对于这个例子,使用 NotesView 的 AutoUpdate 属性告诉 Lotus Notes 不必更新视图索引是个不错的主意,除非您使用 Refresh 方法显式地请求它。这能够大大提升速度。
即使您所做的更改影响到 NotesView 的内容,也可以使用这种方法,只要您的更改对自己正在做的事情没有影响即可。例如,您知道更新将从视图删除文档,但这没有关系,因为您已开始处理下一个文档。
不能使用基于高效集合的方法
NotesDocumentCollection 类有一些以“All”结尾的方法,它们能够处理集合中的所有文档。您应该了解这些方法,因为它们比遍历集合和操作每个文档快得多。(除非您需要对每个文档执行多个操作;否则遍历会更快,每个文档仅需保存一次)。
重复开销大的操作
内置类中的某些方法和属性非常慢。如果不需要,就避免使用这些函数,这能让代码的运行更快。例如,假设您处理一个文档集合,必须使用每个文档的一个字段作为查找值,以从其他视图获取信息:
Dim view As NotesView Set docCur = coll.GetFirstDocument Do Until docCur Is Nothing Set view = db.GetView(“CustomersByID”) 'oops! Don't do this in the loop! Set docCust = view.GetDocumentByKey(docCur. CustI D(0), True) ... Set docCur = coll.GetNextDocu ment(docCur) Loop
在这段样例代码中,如果 coll 包含 1000 个文档,我们将调用开销很大的 GetView 方法
1000 次。如果调换 Do Until 和 Set view 代码行的位置,代码的运行就会快得多,因为
GetView 仅被调用一次。
使用代理程序探查器查找这类东西是个不错的方法。developerWorks Lotus 文章 Troubleshooting application performance: Part 1: Troubleshooting techniques and code tips 和 Troubleshooting application performance: Part 2: New tools in Lotus Notes/Domino 7 将对此进行描述。
保存未更改的文档
还记得吗,影响性能的因素之一就是修改文档的频率。当您编写处理文档的代理程序时,应该避免不必要地保存文档更改。在为每个项赋值时,检查它是否已经拥有该值。如果最终没有修改任何东西,就不要调用 Save 方法。通常,您可以使用搜索方法从文档集合中过滤出不需要处理的文档。
如果您总是检查各个项以确定是否更改它们,代理程序的运行可能慢些。但也可能不变慢,因为保存文档比在内存中比较信息需要更多时间。如果总是执行检查,应用程序的其他部分会更高效,比如复制、视图索引和全文本索引。
避免不必要的保存也可以减少复制冲突。复制使用项 修改时间;它并不将整个文档发送给其他副本,而是仅发送修改的项。所以,即使最终需要保存文档,如果只修改需要新值的项,那么就能减少复制时间。使用本地副本的用户将受益匪浅。
搜索文档的方法
大部分代理程序必须做的一件事情是查找一组需要处理的文档。有很多查找文档的方法,但不同的方法适用于不同的情况。
developerWorks Lotus 文章 Lotus Notes/Domino 7 application performance: Part 1: Database properties and document collections 讨论搜索和处理文档集的不同方法。下面概括地介绍一下:
- 如果视图包含您需要的文档,并且以有用的方式进行排序,那么从视图读取文档就会更快,例如使用 GetAllDocumentsByKey 方法。
- 对于包含大量文档的数据库,FTSearch 方法比 NotesDatabase.Search 方法要快,前提是数据库必须是全文本索引的。注意,您也可以通过在代理程序的 Document Selection 事件中输入全文本搜索来执行它。
在这两种情况中,利用服务器事先完成的索引工作可以节省时间。与必须检查每个文档的 NotesDatabase.Search 相比,FTSearch 节省了一些运行时工作。
全文本搜索的文档过滤级别不如 NotesDatabase.Search 细,但它节省了大量时间,您完全可以利用一部分时间遍历结果并忽略不适用的部分。在 Notes Client 帮助(不是 Designer 帮助)中的文章“Refining a search query using operators”介绍了完整的全文本查询语法。您将发现它的用途比您想象的要多。
注意:取决于自己的需求,有时您可以结合公式搜索的威力和全文本搜索的性能,在使用基于公式选择条件的视图中进行全文本搜索。
从缓存中删除不使用的文档
在早期的 Lotus Notes 版本中,使用完 NotesDocument 对象之后,可以使用 Delete语句从内存中删除它们。然后,从 6.0 版本开始,再也不需要这样做了。(如果您已经知道是怎么回事,就不要再使用它。如果不知道,也不用担心)。
出于其他非性能方面的原因,您可能还在使用 Delete,例如,您认为其他进程修改了文档,因为您最终打开它,并确保自己看到的是最新数据。
更高效的循环和赋值等
有一些文章比较了“for”循环和“while”循环、全局变量和堆栈变量等的性能。然而,除非您的应用程序属于计算密集型的,否则难以利用这些比较获得性能改善。
大部分脚本花在打开文档和视图的时间远比处理变量值多。避免不必要的数组引用可以节省百万分之一秒;然而,打开不必要的视图可能要花费数秒钟。如果想通过节省时间来提高性能,那么应该先考虑占用时间多的项。
了解不同 LotusScript 表达式和语句的性能特点可能非常有用,但养成良好的代码编写习惯更有用;回过头来修改不妥当的地方常常是得不偿失的。
关于这个方面的有价值技巧是:
- 不要使用 GetNthDocument(如前所述)
- 显式地声明变量,避免使用默认的变量类型。这样做不仅能够提供更好的性能,并且有助于在编译期间查找错误。对于自动将 Option Declare 语句插入到您的 LotusScript 代码中的编程面板属性,应该使用这个选项。
7.使用 LC LSX
如果将 LC LSX 与外部关系数据库或数据文件整合起来,它通常比内置的 ODBC 类快。
IBM Redbooks Implementing IBM Lotus Enterprise Integrator 6 包含了大量信息,讨论如何使用这个 API 进行编程,以及如何最大限度地提升性能。
8.测试
这份白皮书在开始时已经提到,很多优秀的小程序在数据和用户的数量比较少时表现非常出色,但当用户和数据非常多时,它们就陷入困境了。使用大量文档测试设计是明智的。测试 50 人同时使用应用程序时有什么反应(您可能很难找到 50 位朋友抽时间参与测试,但可以使用能够模拟该场景的自动化测试工具)。
此外,编写包含少量样例数据的代理程序也不是很难,然后通过为选择字段分配随机值增加数据的数量,使文档多达数千个。如果您使用代理选项创建新文档的话(在代理程序编辑屏幕的右下角),这些工作还可以通过公式代理程序完成。
警告:如果您测试已投入生产的应用程序,务必在非生产服务器的数据库拷贝(不是 副本)上进行测试,并且最好使用不用于复制生产服务器的服务器。这样,就不用担心破坏生产服务器上的数据,或阻碍使用该服务器的人员的工作。
![]()
9.使用配置文件文档
配置文件文档是高效地储存和获取不经常改变的信息的好办法。因为文档在首次使用时就被完整地缓存起来,所以使用它保存定制关键字列表是非常高效的。这不会影响视图索引,也不用担心控制缓存。它们的复制和普通文档是一样的(但使用复制选择公式的用户不会意外地破坏应用程序,这比普通的关键字文档要好)。它们既有趣又简单,您可以尝试使用!
这篇关于Lotus开发性能优化 (II)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







