本文主要是介绍你了解过副本机制么?ISR是什么?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
💡副本机制
简单来说就进行数据的拷贝,比如由kafka中间件来说,我们一开始可能考虑不周到,所以将数据进行单节点存储。

单节点同步
一开始非常的开心,部署简单,使用简单,还满足了高峰期大流量对数据库的压力,小苏同学沾沾自喜,随之时间延长,系统出现了硬件故障,由于硬盘坏了,从而导致kafka服务不可用了,高峰期数据库一度处于宕机边缘。

怎么办呢?小苏同学一度陷入混乱中,那么我们应该怎么避免这种场景出现呢?
💡副本机制的作用
这时候, 为了避免这种问题,保证系统的高可用,当然是加多一个副本啦,并且kafka本来就支持多副本从而保证高可用的,这时候小苏同学就学聪明了,直接加多一个kafka机器作为备份用。
让主从节点进行数据同步,当出现了故障 直接进行数据迁移,将流量直接直接请求follower节点就好。
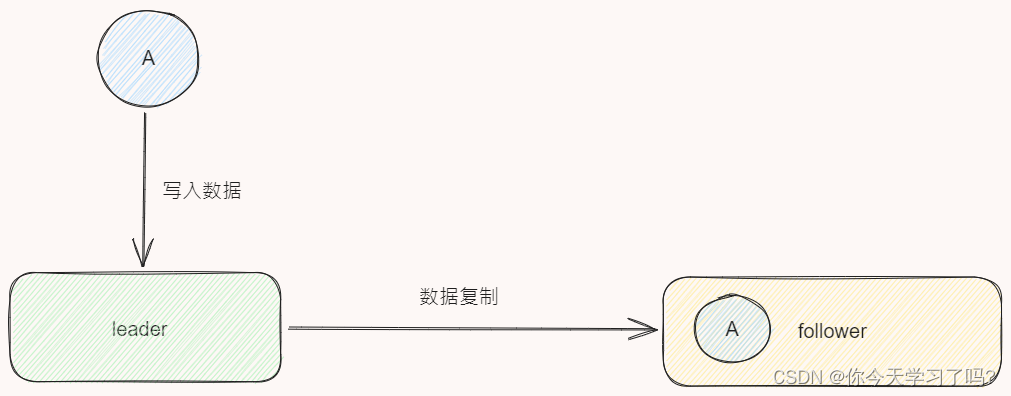
简单同步机制 (1)
就这样 小苏同学又开始沾沾自喜了, 但是好景不长, 这一次的宕机居然在高峰期, 在下单系统中, 好几个用户进行投诉,我钱都付了, 为什么看不到订单?
小苏同学一脸懵,不对啊, 我已经做了主从切换呀, 怎么会有这个问题呢???
我们来还原一下这种场景

高峰期主从同步弊端
由上图场景, 4比订单A B C D 进行正常业务写入, 这时候已经有三笔订单已经完成了复制,此时突然leader 突然宕机 但是此时D订单还没有进行同步呢,
这时候订单D就相当于丢了,这就是典型的主从复制出现的弊端,在高峰期会宕机会出现信息丢失的情况。 那么kafk中间件是怎么避免这种问题的呢?
💡ISR机制登场
ISR起始是副本同步的简称,是In-Sync Replicas(同步副本)的缩写。这里最重要的是in sync 意思在可控范围内的同步,还是上述的流程,我们来分析一下他的弊端吧
由图显而易见的是leader 并不知道follower的复制情况,所以follower落后了 leader也不知道,及时leader重新启动了,也没法告诉follower 缺失了 哪条记录,所以这时候我们需要进行优化一下
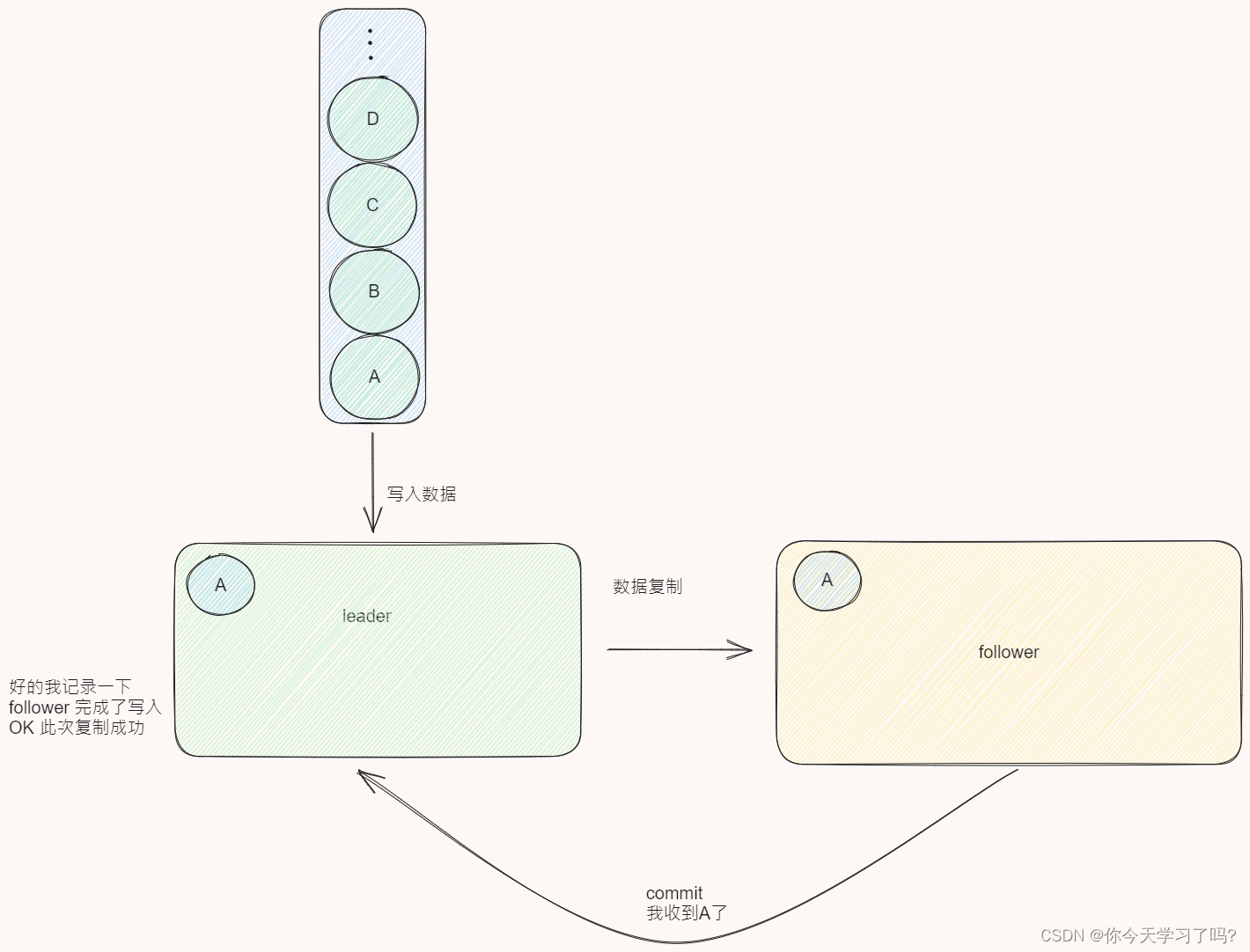
引入commit通知
这样我们就知道follower同步到哪里了,但这时候之前的leader已经成为follower ,我们该如何去告诉现任leader丢了这个数据呢?

pastedImage_4_9_2024__16_27_15_879
让我们来一步步剖析其中的奥秘吧。
由上图 这就出现了leader follower数据不一致的场景了。我们来看看LSR机制是怎么做的吧。
💡高水位 HW 下个写入标志LEO
HW:高水位 ,你可以理解成大多数人都统一,我举个简单的例子吧
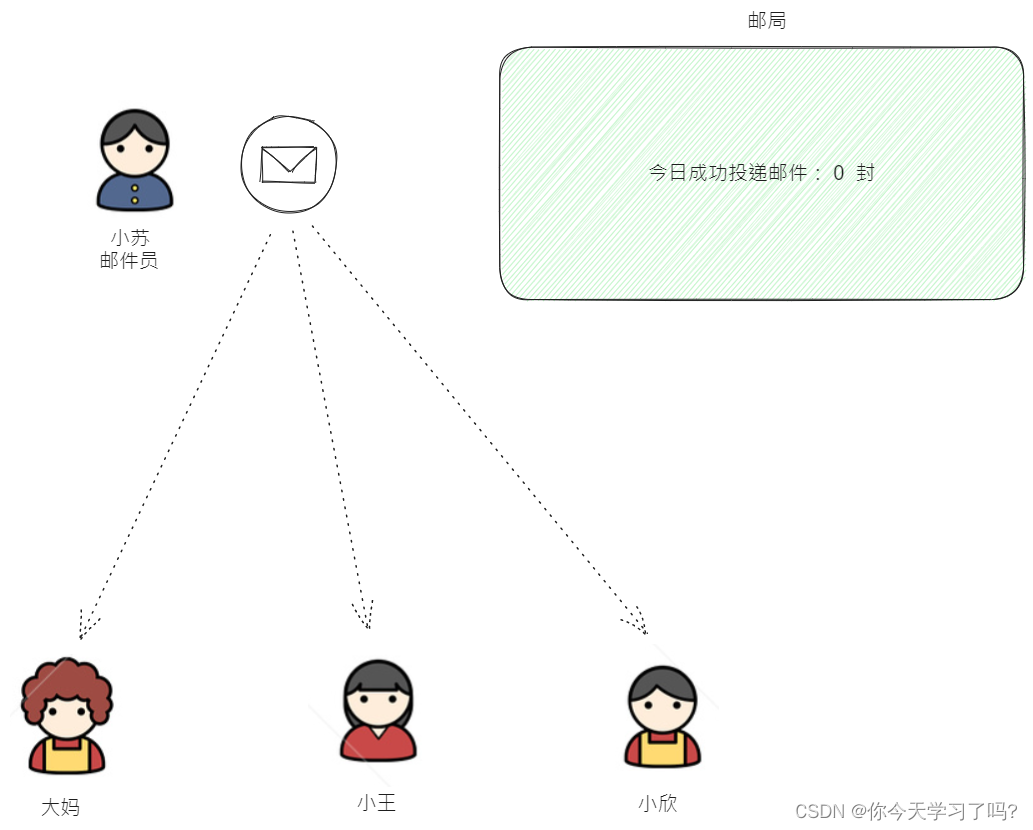
HW故事初始化说明
假设有一个小镇,名叫消息镇(Town of Messages)。这个小镇有一个邮局,用于处理来自周围地区的信件。邮局有一个非常特别的规定:只有当邮递员将信件送到每户人家后,才会认为这些信件被成功投递。
现在,让我们来看看消息镇的邮局是如何运作的:
邮局的大门上挂着一块牌子,上面写着“邮局高水位线:已经成功投递的信件数”。当邮局开始运作时,高水位线是0,因为还没有投递过任何信件。如上图所示。
假设现在快递员小苏准备将邮件进行派送,当邮件派送给大妈完成后,邮局的高水位线被更新为1,表示有一封信件已经成功投递了。
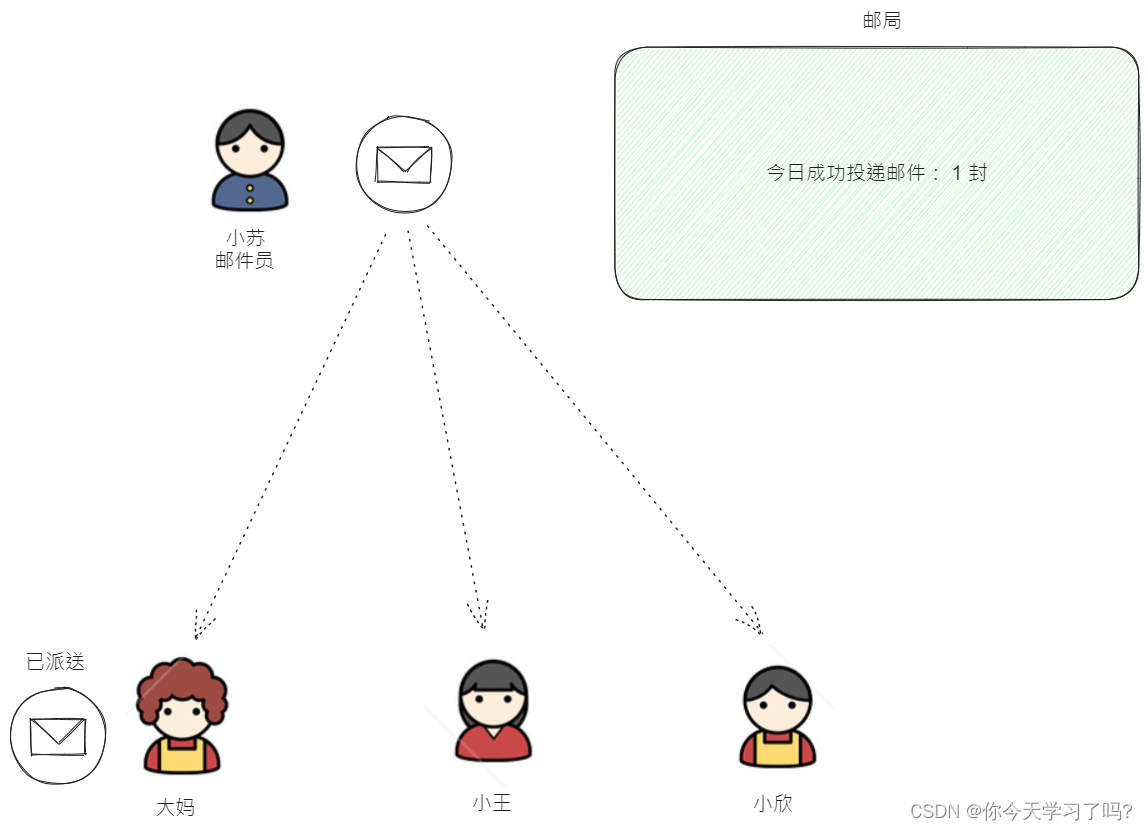
HW故事说明成功派件
所以HW就很简单了 ,这就相当于信息传递的一个响应 证明某某人已经接收到邮件了,这样邮局才能确认用户已经收到邮件了。
那么LEO是什么呢?
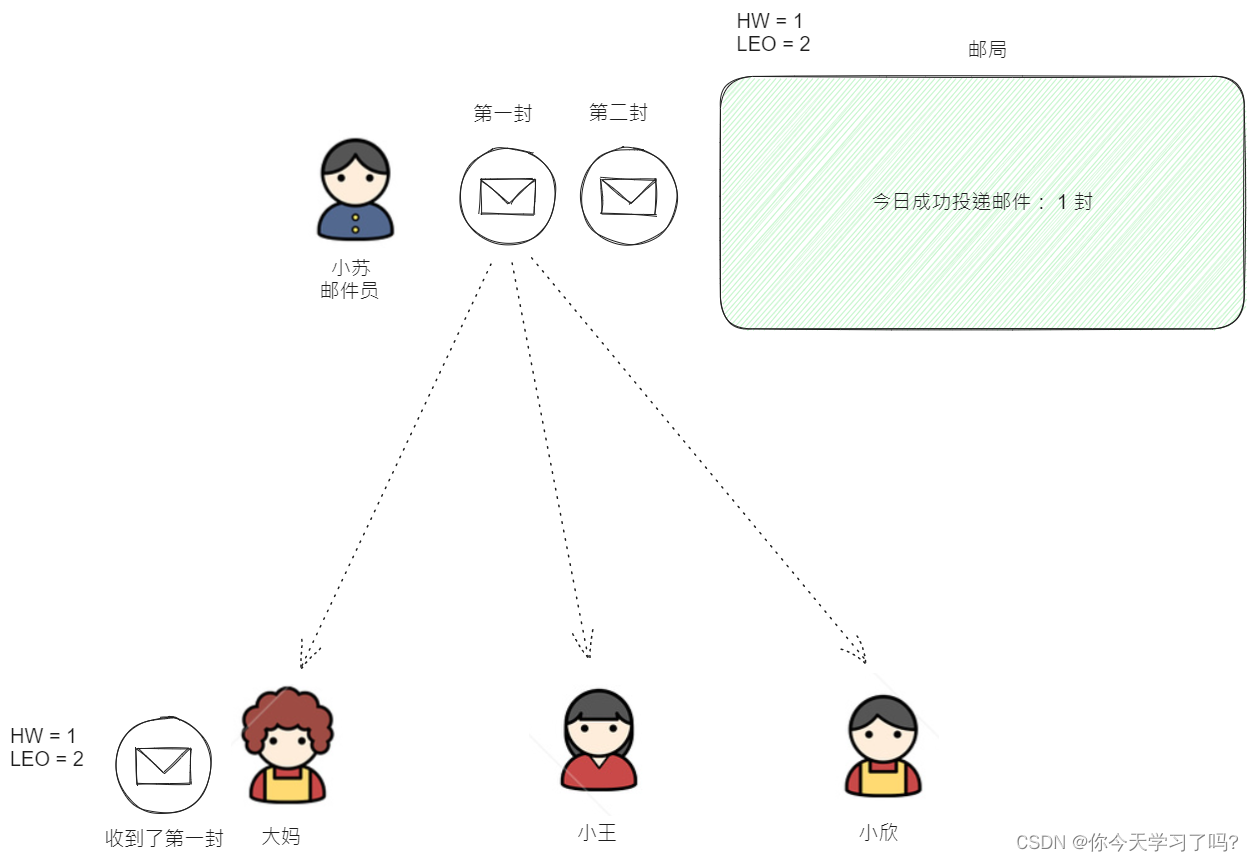
LEO故事说明 (1)
假设每个人都有两封邮件需要签收,此时呢 大妈只收到一份邮件,那么这个时候邮局的高水位HW = 1 ,那么准备要把第二封邮件进行发送给大妈了, 需要进行标识下一封发送那个邮件
此时这就是LEO了,LEO就代表了下一个要发送的邮件。所以上述的流程中呢 邮局的HW = 1 LEO = 2 大家就明白了吧.
有了HW 和 LEO 就可以知道你收到了那个信息, 你下一个需要接受什么信息,通过这两个标识就可以简单的进行同步数据,并且互相确认。
🗣️后面HW 和 LEO 是如何运转的呢? 为什么有了这种机制还会导致数据丢失的是说明场景?
那么请留意后期的推文,或者关注我集中更新哦~
这篇关于你了解过副本机制么?ISR是什么?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





