本文主要是介绍前端mock数据——使用mockjs进行mock数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前端mock数据——使用mockjs进行mock数据
- 一、安装
- 二、mockjs的具体使用
一、安装
- 首选需要有nodejs环境
- 安装mockjs:
npm install mockjs

若出现像上图这样的错,则只需
npm install mockjs --legacy-peer-deps即可
- src下新建mock文件夹:

mock
├─ api.ts // mock数据接口,前端最终调用的接口
├─ data.ts // 定义数据和规则
├─ pmockAxios.ts // 模拟数据库mock 重新封装Axios,因为baseURL不同了
├─ request.ts // 根据数据模板生成模拟数据,生成接口给前端调用
二、mockjs的具体使用
最终获取到的数据: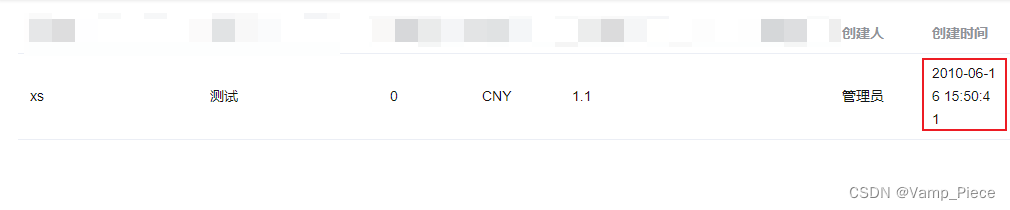
// mockAxios.ts
// 模拟数据库mock 重新封装Axios,因为baseURL不同了,在项目中会存在后端的接口调用路径,所以再使用mock数据时需重新封装axios// 对axios进行配置(二次封装)
import axios from 'axios'const mockRequestor = axios.create({// 配置对象baseURL: '/mock',timeout: 5000
})// 请求拦截器
mockRequestor.interceptors.request.use((config) => {return config
})// 响应拦截器
mockRequestor.interceptors.response.use((res) => {return res.data
}, (err) => {return new Error(err)
})export default mockRequestor
// data.ts 这里是mock的响应模板
// 定义数据和规则
import Mock from 'mockjs';这篇关于前端mock数据——使用mockjs进行mock数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




