本文主要是介绍我国数据出境制度2.0时代下的企业合规应对(下篇),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
三、企业的合规应对
(一)理清数据出境制度适用的三个层次
如前文所述,《数据跨境新规》及其配套文件不仅创建了数据出境的第四条路径,而且将某些情形直接从源头排除在“数据出境”适用范围之外。为了方便企业设计合规方案,我们根据所对应法律义务的不同将所有数据跨境传输行为归纳为如下三个层次。
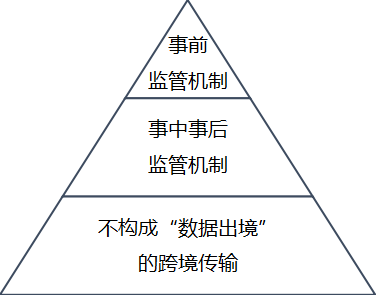
图一:数据出境制度2.0适用的三个层次
1.数据出境事前监管机制(“三条路径”)
如果企业的数据跨境传输行为符合《数据跨境新规》第七条和第八条所述范围,该企业需要履行数据出境事前监管机制下的义务,即安全评估、标准合同、认证“三条路径”。
2.数据出境事中事后监管机制(“第四条路径”)
如果企业的数据跨境传输行为符合《数据跨境新规》第五条和第六条所述范围,该企业无需履行任何前置的行政监管手续,但是仍然需要履行“三大基本法”下对数据跨境传输这一个处理行为的基本义务,如个人信息的单独同意、一般数据的技术等必要措施(参见《数据跨境新规》第十条和第十一条)。企业需要注意的是,上述基本义务还包括《个保法》第三十八条规定:“个人信息处理者应当采取必要措施,保障境外接收方处理个人信息的活动达到本法规定的个人信息保护标准”。
3.不构成“数据出境”的跨境传输
如果企业将数据传输至境外,但是未落入我国数据出境安全管理制度的监管范畴,即不属《第二版指南》第一条中规定的“数据出境行为”,则企业理论上无需履行对应数据跨境传输这一个处理行为的基本义务,例如,某企业将几十个客户的非敏感个人信息存在境外自己服务器上,无需取得这些客户的单独同意。当然,如上文所述,《数据跨境新规》第四条的“数据过境”情形是否应划归属于这个层次值得讨论。
(二)分析影响层次归类的几个重要因素
在实务中,企业在判断其数据跨境传输行为具体应被归类到如上三个层次中具体哪一个时,会面临几个重要因素的理解,我们逐一分析如下。
1.重要数据的认定
企业在判断是否适用数据出境事前监管机制时,其中重要数据的认定是重中之重。《数据跨境新规》第二条免除了数据处理者的重要数据认定义务,但是其有一个前提条件,即处理者需要履行重要数据的“识别申报”义务。例如,2024年2月7日天津市商务局、中国(天津)自由贸易试验区管委会联合发布的《中国(天津)自由贸易试验区企业数据分类分级标准规范》中便要求“企业根据本规范开展内部数据分类分级工作,形成企业数据目录,明确本企业重要数据,并向天津自贸试验区网络数据安全工作主管部门报送重要数据目录”。如果企业疏于履行该义务,导致相关数据未能被相关部门或地区获悉,进而也可能无法告知或者公布其为重要数据,以至于是否会造成其无法享受《数据跨境新规》第二条赋予的“举证责任倒置”的风险,值得企业关注。
2.豁免条件的适用
如上文所述,《数据跨境新规》第五条创建了第四条数据出境路径,即对之前三条路径的豁免。其所列的四个情形可以分为两大类:场景豁免(为合同所必需、为人力资源管理所必需、为生命财产所必需)和数量豁免(十万以下)。
(1)场景豁免中的“确需”的认定
我们建议企业在评估其出境行为是否满足场景豁免中的“确需”时,与数据出境的“必要性”评估进行一定区分,因为前者的门槛相对于后者稍高一些。场景豁免中的“确需”与《个保法》十三条“取得个人的同意”以外的合法性基础类似,仅限于“客观必需”,且与其所对应的三个具体场景(合同、人力资源管理、生命财产)构成紧密且不可或缺的一部分。而数据出境的“合法性、正当性、必要性”中“必要性”评估则是向境外提供数据的基本要求。这一点从《个保法》第三十八条表述体现:“个人信息处理者因业务等需要,确需向中华人民共和国境外提供个人信息的,应当具备下列条件之一……”可见,“必要性”评估不仅是该条款项下前三条路径(数据出境事前监管机制),而且是第四条路径(场景豁免)的适用前提条件。如果将场景豁免中的“确需”门槛下调至与数据出境的“必要性”评估一致,那么在未达到场景豁免中的“确需”门槛时,则意味着数据出境的“必要性”评估也无法满足,最终导致《个保法》第三十八条项下的四条路径都无法走通。这显然不符合《个保法》第三十八条与场景豁免制度设计的本意。这也可以从数据出境安全评估申报的实践中看出,《安评办法》要求处理者在开展数据出境风险自评估时应当评估数据出境的“合法性、正当性、必要性”,如果未取得个人的单独同意,需要处理者满足《个保法》十三条第(二)至(七)款的同意豁免条件。在安全评估申报的成功案例中,就存在通过了“必要性”审查但因未满足《个保法》十三条的同意豁免条件而通过单独同意取得合法性基础的情况。
(2)数量豁免中的“敏感个人信息”认定
数量豁免条款,即《数据跨境新规》第五条第(四)款,的关键在于“敏感个人信息”的认定,因为如果企业出境的个人信息虽然在十万人以下,但只要其中含有敏感个人信息,则无法适用数量豁免,而必需走数据出境事前监管机制。然而,虽然《个保法》和《GB/T 35273-2020《信息安全技术 个人信息安全规范》以列举方式来明确“敏感个人信息”的范围,但是在实践中,特别是不同行业和领域中,“敏感个人信息”的名称和字段纷繁复杂。鉴于《数据跨境新规》并未给予“敏感个人信息”与“重要数据”一样的“举证责任倒置”待遇,企业在分析其出境数据时不要忽视“敏感个人信息”的认定,滥用数量豁免。
理清上述几个重要因素有助于企业准确将其出境情形归类到三个不同的制度层次。但是,在数据出境制度2.0版本下,准确归类仍然面临各类条件多维度交叉适用的复杂情况,即在主体方面处理者是否构成关键信息基础设施运营者;在数据种类方面数据是否构成重要数据、个人信息、敏感个人信息;出境情形是否适用场景豁免;出境情形是否适用数量门槛等等。为了方便企业准确适用数据出境制度2.0下的四条路径,我们上述所有条件体现在一张分析流程图上(如下)。
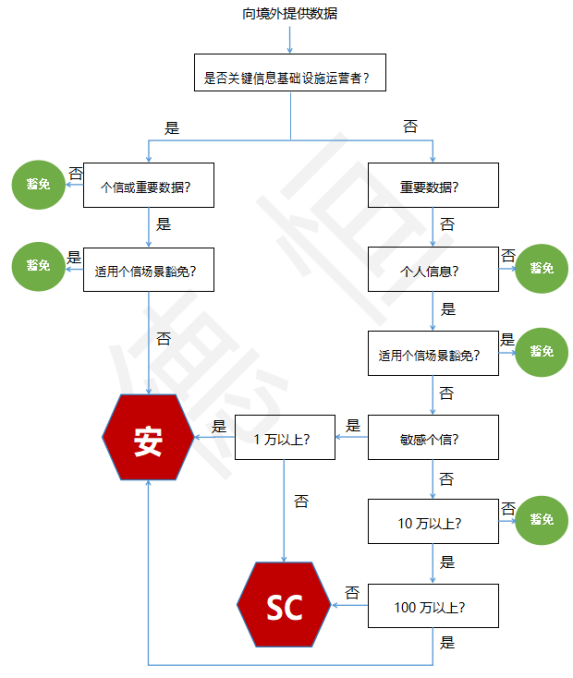
图二:数据出境四条路径分析流程图
注1:图中红色六边形图标系数据出境事前监管机制
注2:图中绿色圆形图标系系数据出境事中事后监管机制
(三)履行所对应层次的合规义务
企业将其跨境传输行为准确归类到三个不同的制度层次之后,就需要考虑并履行其所适用的合规义务。
如果企业适用数据出境事前监管机制,应尽快按照法规要求启动安全评估或标准合同/认证的相关专项工作,摒弃观望态度,因为我国数据出境制度从1.0过渡到2.0,已经完成了初步探索阶段,正式步入全面实施阶段,监管部门将会“强化事前事中事后全链条全领域监管“。
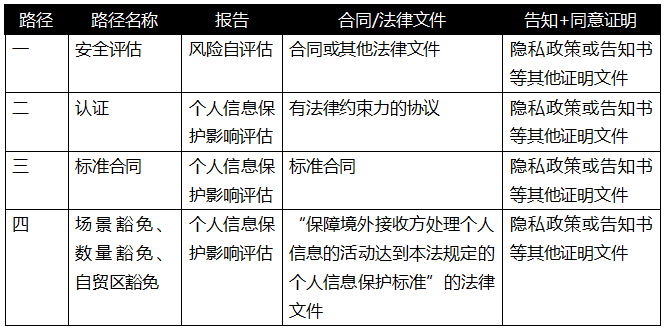
如果企业适用数据出境事中事后监管机制,应注意其虽然无需通过事前监管机制,但仍需履行一些合规义务,准备一些法律文件,如告知、单独同意、个人信息影响评估报告等。另外,我们建议企业在准备个人信息影响评估报告时应当充分论证和分析其《数据跨境新规》第五条的适用,特别是上文中几个重要因素,为今后可能面临的监管检查或合规审计做好举证准备。为了帮助企业更好地理解该机制下需要履行的合规义务,我们将数据出境四条路径主要合规文件列表如下。
表一:数据出境四条路径主要合规文件一览表
最后,如果企业的数据跨境传输行为不属于《第二版指南》第一条中规定的“数据出境行为”,则无需履行与“出境”这一处理活动相关的任何合规义务,仅需关注其他处理活动(如收集、存储、加工、删除、公开等)项下义务即可。
四、结语
数据跨境流动的法律规制一直是各个国家网络安全和数据保护的重点关注领域。其因繁杂的业务场景、变化的地缘政治、诸多的利益平衡等因素,也给各国的制度设计带来巨大挑战。我国数据出境安全管理制度建设自《网安法》出台以来一直稳步推进,经历了一个从理论研究、立法规制、实践探索、优化调整的过程,逐渐走向完善和成熟。
对于监管部门来说,在此过程中一个贯穿始终的核心问题是,如何能在有限的行政资源情况下找到发展与安全之间最佳平衡点。数据出境安全管理制度2.0版本给了我们一个阶段性答案,就是监管部门将适当减少事前监管机制的适用情形,同时增加事中事后监管机制的适用情形,进而将部分有限的行政资源从“事前”海量的申报和备案工作中解放出来,转而投入到“事中事后”全链条全领域监管工作中去,形成审批与处罚并重、发展和安全兼顾的监管态势,最终在全社会营造一个长期可持续的合规环境。
对于企业来说,虽然在数据出境制度2.0时代更多情况下无需通过事前监管机制来完成跨境传输,但是也失去了事前监管机制给企业合规工作带来的确定性。如果说现阶段“重要数据”的识别需要企业与相关部门地区相互配合、共同努力,那么事中事后监管机制的适用及其后果则将完全由企业自身来完成和承担。将来企业在数据跨境传输场景中,不仅要接受网信部门的监管,还可能要面对境内外上市、合规审计、投资并购、数据资源入表等等多个场景下的相关方(如证券监管机构、审计机构等)提出的一系列“灵魂拷问”:该行为是否构成“数据出境”?如果构成,是否适用数据出境事前监管机制?如果不适用,所依据的理由是否充分准确?如果充分准确,是否完成了事中事后监管机制的合规义务等等?这将是企业在我国数据出境安全管理制度2.0时代下需要面临和应对的新挑战。
来源:CNCERT国家工程研究中心
这篇关于我国数据出境制度2.0时代下的企业合规应对(下篇)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







