本文主要是介绍人工智能(pytorch)搭建模型27-基于pytorch搭建StyleGan模型,StyleGan的研究方向与应用场景,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大家好,我是微学AI,今天给大家介绍一下人工智能(pytorch)搭建模型27-基于pytorch搭建StyleGan模型,StyleGan的研究方向与应用场景。StyleGAN是一种深度学习生成模型,由 NVIDIA 在2018年提出,它是Generative Adversarial Networks (GANs) 的一种创新扩展,特别是在图像生成领域取得了显著突破。其核心在于引入了“样式空间”(Style Space)的概念,使得生成器能够控制和分离内容(Content)和样式(Style),从而实现更精细、多样化的图像生成。
在研究方向上,StyleGAN主要集中在两个方面:一是提高生成图像的质量和多样性,通过调整样式向量的控制,可以生成逼真的人脸、动物、艺术作品等高分辨率图像;二是探索生成模型的可解释性和可控性,如何在保持生成图像质量的同时,使用户能够精确地指导模型生成特定风格或特征的图像。结构上,StyleGAN由两个主要部分组成:生成器(Generator)和判别器(Discriminator)。生成器采用多层卷积网络,每一层都有一个独立的样式向量,通过逐层混合内容和样式,生成从低分辨率到高分辨率的连续图像。判别器则用于区分真实图像和生成图像,两个网络通过对抗训练相互优化。
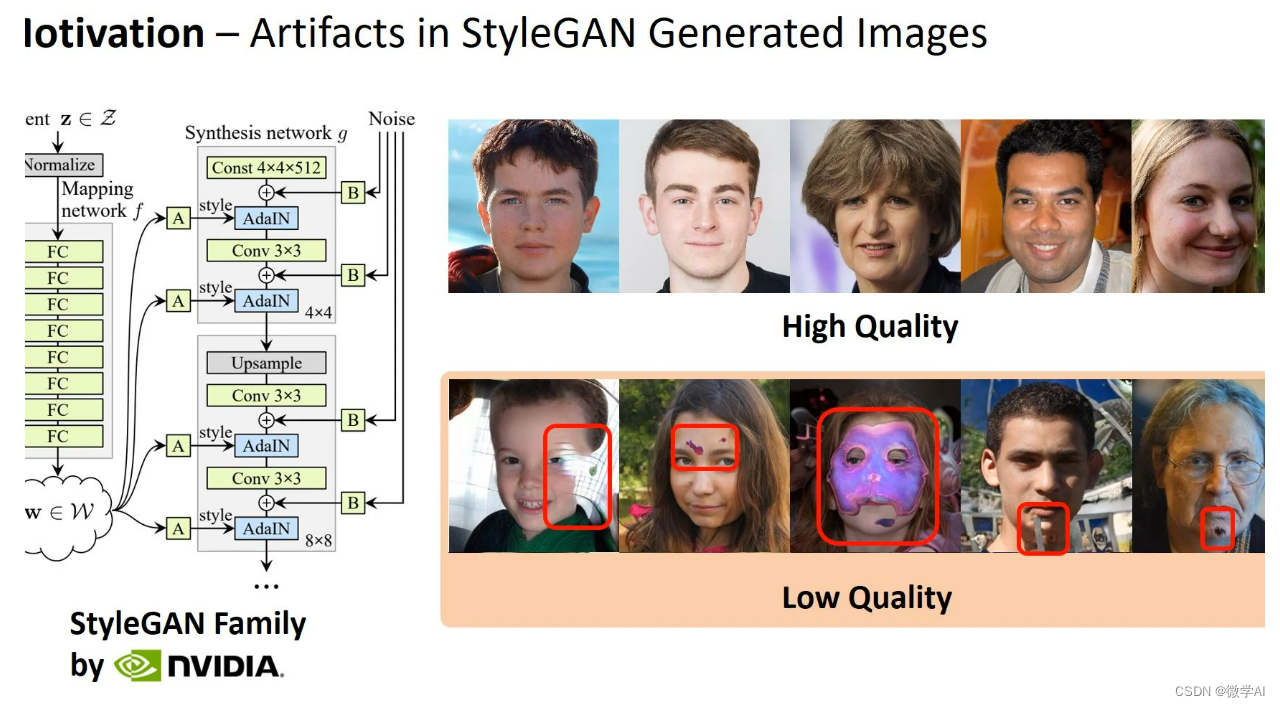
文章目录
- 一、StyleGan简介
- 1.1 StyleGan的基本概念
- 1.2 研究背景与优点
- 二、实际应用案例
- 2.1 艺术创作与设计
- 2.2 视频与电影特效
- 2.3 高科技领域
- 三、未来研究方向
- 3.1 多模态融合
- 3.2 控制与可解释性
- 3.3 泛化与适应性
- 四、StyleGan模型的数学原理
- 五、StyleGan模型的代码实现
- 六、总结
一、StyleGan简介
1.1 StyleGan的基本概念
StyleGAN是一种深度学习生成模型,特别在图像生成领域引起了广泛关注。它基于深度生成对抗网络(GAN)的框架,但创新性地采用了样式转移的概念,将图像的生成过程分解为两个主要组成部分:内容向量和样式向量。
内容向量决定生成图像的主题或基本信息,比如人物的轮廓、面部特征等,而样式向量则控制细节的纹理和风格,如皮肤的光滑度、眼睛的颜色等。这种分离使得StyleGAN能够生成高度逼真且多样化的图像,即使在微调时也能保持一致的风格。
想象你正在做蛋糕。内容向量就像蛋糕的基本配方,决定了它是巧克力、香草还是草莓口味;而样式向量则是装饰艺术,比如你选择的糖霜图案、水果点缀等。你可以随意调整风格,比如加一些精致的奶油花纹或者洒上彩色糖珠,但蛋糕的主体——口味,始终由基本配方决定。这就是StyleGAN如何通过控制内容和风格来创造出丰富多样的图像。
1.2 研究背景与优点
StyleGAN由NVIDIA的研究团队在2018年提出。它是基于对抗网络(GANs)的一种创新,特别是针对图像生成任务进行了重大改进。
研究背景与优点:
StyleGAN的诞生源于对传统GANs在生成高质量图像时遇到的挑战,如模式重复、细节缺失等问题。它引入了“样式空间”这一概念,将图像的生成过程分解为两个阶段:一是生成全局风格特征,二是调整局部细节。这种分离使得模型能够控制和精确调整图像的各个方面,如人脸的性别、年龄、表情等,从而显著提高了生成图像的质量和多样性。
想象你正在使用StyleGAN就像一个艺术家创作一幅画。首先,你可以设定画的整体风格,比如是古典油画还是现代素描,这是“全局风格”。然后,你可以精细地调整眼睛的颜色、微笑的弧度或者头发的纹理,这些都是“局部细节”。这样,无论你想要生成一张肖像、风景还是抽象艺术,都能做到既保持整体风格的一致性,又能展现丰富多样的个体特征。这就是StyleGAN的独特之处,它让机器像真正的艺术家一样,创造出令人惊叹的逼真图像。
二、实际应用案例
2.1 艺术创作与设计
在艺术创作与设计的实际应用中,数字技术发挥着日益重要的角色。例如,艺术家们可以使用3D建模软件创造出逼真的虚拟雕塑或装置,如米开朗基罗的《大卫》雕像在虚拟空间中的数字化复原。设计师则运用参数化设计,通过算法自动生成独特的建筑外观,如悉尼歌剧院的壳形结构就是通过计算得出的理想形态。
以日常生活中的家居装饰为例,设计师可能会利用软件进行室内布局优化,通过调整家具位置和颜色搭配,实现空间的最大利用和美观效果。比如,一款智能设计工具可以帮助你预览不同风格的沙发如何适应你的客厅布局,甚至根据光线变化自动调整色彩。这种数字化技术不仅提高了创作的效率,也丰富了我们的生活美学体验。
2.2 视频与电影特效
视频与电影特效在现代娱乐行业中扮演着至关重要的角色。它们就像魔术师手中的道具,能够将平凡的场景转化为奇幻的世界。例如,在《阿凡达》中,特效团队利用CGI(计算机生成图像)技术,创造出一个充满生机的潘多拉星球,那里的大眼睛纳美人和悬浮山都是视觉上的奇迹。观众仿佛置身于一个由像素构建的梦幻世界。
在生活中,我们可以这样想象:假如你在烹饪晚餐,但你希望你的炒菜变成在五星级酒店的顶级厨师手中完成,或者你的客厅突然变成了热带雨林,这些都可以通过视频特效实现。比如,通过手机应用,你可以为你的家庭照片添加上蓝天白云的背景,或者让宠物猫穿上华丽的礼服,这些都是特效赋予我们的想象力和创造力。总的来说,视频与电影特效就是那双神奇的手,让不可能变为可能,为我们的日常生活增添了无数的乐趣和惊喜。
2.3 高科技领域
在高科技领域,人工智能(AI)的应用已经深入到我们生活的方方面面。比如,自动驾驶技术是AI的一个重要分支。以特斯拉的Autopilot为例,它通过搭载的摄像头、雷达和传感器,能实时分析路况,识别行人、车辆等障碍物,甚至能在高速公路上实现自动导航和车道保持。就像你坐在家里就能远程操控家里的扫地机器人一样,驾驶者只需设定目的地,车辆就能自主行驶,大大减轻了驾驶压力。
又如医疗领域,AI正在协助医生进行疾病诊断。比如深度学习算法可以通过分析大量的医学影像资料,帮助医生更准确地识别肿瘤、病变等。想象一下,就像你的私人医生随身携带了一个超级强大的“X光眼”,能快速且无遗漏地检查你的健康状况。
再者,智能家居也是AI的实际应用,例如Amazon Echo或Google Home,它们能通过语音识别技术,理解并执行用户的指令,如调节室内温度、播放音乐等,让生活更加便捷。这就像有个贴心的小秘书,随时待命,满足你的各种需求。
高科技领域的AI应用就像一个无所不能的超级助手,它在我们看不见的地方默默工作,让我们的生活变得更加智能、高效。
三、未来研究方向
3.1 多模态融合
三、未来研究方向:多模态融合
在人工智能和机器学习领域,多模态融合是一种前沿趋势,它指的是将多种不同类型的数据源,如文本、图像、语音、视频等进行整合和交互分析,以提升系统的理解和决策能力。这种融合旨在打破单一数据模式的局限,实现更全面、深入的理解。
举例来说,比如你正在使用智能助手。如果你对它说:“今天天气怎么样,还有明天的会议提醒?”这里就涉及到多模态融合。语音识别技术捕捉你的语言信息,而环境传感器则提供实时的天气数据。系统通过融合这两者,不仅理解了你的问题,还能给出准确的回答,这就是多模态融合在实际生活中的应用。未来的研究将进一步探索如何使这些模态信息无缝对接,提高人机交互的效率和精准度。
3.2 控制与可解释性
在未来的研究方向中,控制与可解释性是一个至关重要的领域。这主要关注于如何设计和实施智能系统,使其既能执行复杂的任务,又能让用户理解其决策过程。例如,在自动驾驶汽车中,控制意味着车辆需要精确地响应驾驶员的指令或者预设的路径规划,而可解释性则意味着当遇到特殊情况,如突然的行人或障碍物时,乘客需要知道为何车辆做出了刹车或转向的决定,而不是一个黑盒操作。
科学家们正在研发新的算法和技术,比如透明度模型和因果推理,来提高机器学习系统的透明度。想象一下,就像在烘焙中,你调整了配方的每个成分,就能预测出最终的蛋糕口味。在AI中,我们也希望类似地理解每一个输入数据和决策之间的因果关系,让技术更像一个可以解释的科学实验,而非神秘的魔法。这样,我们不仅能提升系统的性能,还能增强公众对人工智能的信任。
3.3 泛化与适应性
在未来的AI研究中,泛化与适应性是一个至关重要的领域。泛化能力指的是AI系统从已学习的知识中推断并应用到未见过的新情境的能力,就像人类能理解并处理各种新的问题和挑战。适应性则强调AI系统随着环境或需求变化时自我调整和优化的能力,比如自动驾驶汽车能根据路况实时调整行驶策略。
想象一个智能家居系统。它已经学会了如何根据你的习惯调整室内温度。如果你今天回家比平时晚,系统能自动推断你可能会更晚需要舒适的温度,并提前进行调整,这就是泛化能力的体现。而如果系统检测到冬天供暖设备出现故障,它会自我诊断并调用维修服务,这是适应性的表现。这样的AI系统不仅能提供便利,还能随着环境变化持续优化,这就是未来AI研究在泛化与适应性上的发展方向。
四、StyleGan模型的数学原理
StyleGAN(Generative Adversarial Networks with Style Control)是一种深度生成模型,它在图像生成任务中取得了显著的进步。其主要创新在于引入了风格控制的概念,使得生成的图像在保持高质量的同时,可以具有更强的可控性。以下是StyleGAN的一些关键数学原理的LaTeX描述:
-
Generator Architecture:
StyleGAN的生成器(Generator, G G G)由一系列的残差块(Residual Blocks)组成,每个块内部包含一个风格转换层(Style Mixing Layer)。在这些块中,图像特征被分为两个部分:内容特征( x x x)和样式特征( w w w)。生成器的输出可以表示为:
G ( z , w ) = f θ ( z , w ) G(z, w) = f_{\theta}(z, w) G(z,w)=fθ(z,w)
其中, z z z 是随机噪声输入, w w w 是风格向量, f θ f_{\theta} fθ 是由参数矩阵 θ \theta θ定义的函数。 -
Style Mixing:
在风格混合层,内容特征和样式特征被独立处理:- 内容特征通过一个线性变换得到:
y = W c ∗ x y = W_c * x y=Wc∗x - 样式特征通过多层归一化线性变换(InstanceNorm)和非线性激活(ReLU)操作得到:
w ′ = W s ∗ InstanceNorm ( w ) + b s w' = W_s * \text{InstanceNorm}(w) + b_s w′=Ws∗InstanceNorm(w)+bs
然后将内容特征和调整后的样式特征相乘:
G ( z , w ) = ReLU ( y + w ′ ) G(z, w) = \text{ReLU}(y + w') G(z,w)=ReLU(y+w′)
这允许在生成过程中混合不同的风格。
- 内容特征通过一个线性变换得到:
-
Discriminator Architecture:
StyleGAN的判别器(Discriminator, D D D)是一个多级架构,用于判断输入是否真实。判别器的输出可以表示为:
D ( x ) = d ϕ ( x ) D(x) = d_{\phi}(x) D(x)=dϕ(x)
其中, d ϕ d_{\phi} dϕ 是由参数矩阵 ϕ \phi ϕ定义的函数。 -
Adversarial Loss:
生成器和判别器通过对抗训练进行优化。生成器的目标是最小化判别器的误分类,判别器的目标是最大化正确分类。损失函数通常为二元交叉熵损失:
L G A N ( G , D ) = E x ∼ p d a t a ( x ) [ l o g ( D ( x ) ) ] + E z ∼ p z ( z ) , w ∼ p w ( w ) [ l o g ( 1 − D ( G ( z , w ) ) ) ] \mathcal{L}_{GAN}(G, D) = E_{x \sim p_{data}(x)}[log(D(x))] + E_{z \sim p_z(z), w \sim p_w(w)}[log(1 - D(G(z, w)))] LGAN(G,D)=Ex∼pdata(x)[log(D(x))]+Ez∼pz(z),w∼pw(w)[log(1−D(G(z,w)))] -
Latent Space Exploration:
StyleGAN的潜在空间(latent space) W W W是多级的,其中 w w w表示低维空间,而 w ′ w' w′表示高维空间。通过在 W W W的不同层次上采样,可以控制生成图像的细节程度。
请注意,这只是一个简化版的描述,实际的StyleGAN模型还包括更多的细节,如权重共享、多尺度结构等。
五、StyleGan模型的代码实现
StyleGAN是一种用于生成高质量图像的深度学习模型,它在PyTorch中实现起来相对复杂,因为其结构包括多个卷积层、残差块、以及多级样式传递等。以下是一个简化的StyleGAN模型的示例代码,但请注意,这个代码只是一个基本框架,实际的StyleGAN模型会更复杂,且需要大量的训练数据和计算资源。
import torch
from torch import nnclass StyleBlock(nn.Module):def __init__(self, in_channels, out_channels, style_dim):super(StyleBlock, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)self.style_layer = nn.Linear(style_dim, out_channels * 4)self.norm = nn.LayerNorm(out_channels)self.activation = nn.LeakyReLU(0.2)def forward(self, x, style):h = self.conv(x)style = self.style_layer(style).reshape(h.shape[0], h.shape[1], 4, -1)style = style.permute(0, 2, 3, 1)h = h + h * styleh = self.norm(h)return self.activation(h)class Generator(nn.Module):def __init__(self, style_dim, resolution=128):super(Generator, self).__init__()self.style_dim = style_dimself.resolution = resolutionself.num_layers = int(log2(resolution)) - 1layers = []for i in range(self.num_layers):out_channels = min(512, 4 * 2 ** (i + 1))layers.append(StyleBlock(512 if i == 0 else out_channels, out_channels, style_dim))self.layers = nn.Sequential(*layers)self.to_rgb = nn.Sequential(nn.Conv2d(512, 3, kernel_size=3, stride=1, padding=1),nn.Tanh())def forward(self, styles):x = torch.randn(styles.shape[0], 512, 4, 4)for i, layer in enumerate(self.layers):x = layer(x, styles[:, i])if i != self.num_layers - 1:x = resize(x, 2)return self.to_rgb(x)def resize(x, scale):return nn.functional.interpolate(x, scale_factor=scale, mode='nearest')# 这里只是简单地创建一个风格向量和生成器实例,实际使用时你需要训练这个模型
style_dim = 512
styles = torch.randn(1, style_dim)
generator = Generator(style_dim)# 生成图像
image = generator(styles)
image = image.clamp(-1, 1)
StyleGAN的训练过程通常需要GPU,并且需要大量的计算资源。如果你想要运行完整的StyleGAN,你可能需要查阅更详细的教程或者GitHub上的开源实现。
六、总结
StyleGAN革新了GANs在图像生成上的表现。它通过引入样式空间,实现了内容和样式分离,生成的图像质量高且多样化。研究重点在于提升图像逼真度和可控性,让用户能精确指导模型。StyleGAN由生成器(逐层混合内容和样式)和判别器构成,通过对抗训练不断优化。这款模型不仅在学术界有重要影响,还在图像编辑、虚拟人物设计、艺术创作和数据增强等领域展现出强大实用性。
这篇关于人工智能(pytorch)搭建模型27-基于pytorch搭建StyleGan模型,StyleGan的研究方向与应用场景的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






