本文主要是介绍c语言中统计一组整形数据出现的次数,不同的整形数按顺序依次输出,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
#include<stdio.h>
int main()
{
int c;
printf(“请输入数据个数:”);
scanf("%d",&c);
int A[c],B[10],time[10],k=0,i,j;//A为存输入数据数组,B为存储不同数数组,time存次数;***
for(int e=0;e<c;e++)
scanf("%d",&A[e]);//手动输入一组数据*
for(i=0;i<c;i++)
{
for(j=0;j<k;j++)
if(A[i]== B[j])//相等时次数增加1
{
time[j]++;
break;
}
if(j==k)//角标相同表明没有形同的,存入B数组,数组长度+1,判断是否相等的数据增加一个
{
B[k]=A[i];
time[k]=1;
k++;
}
}
for(i=0;i<k;i++)//循环输出数据和次数
printf("%d:出现%d次\n",B[i],time[i]);
return 0;
}
附上运行截图
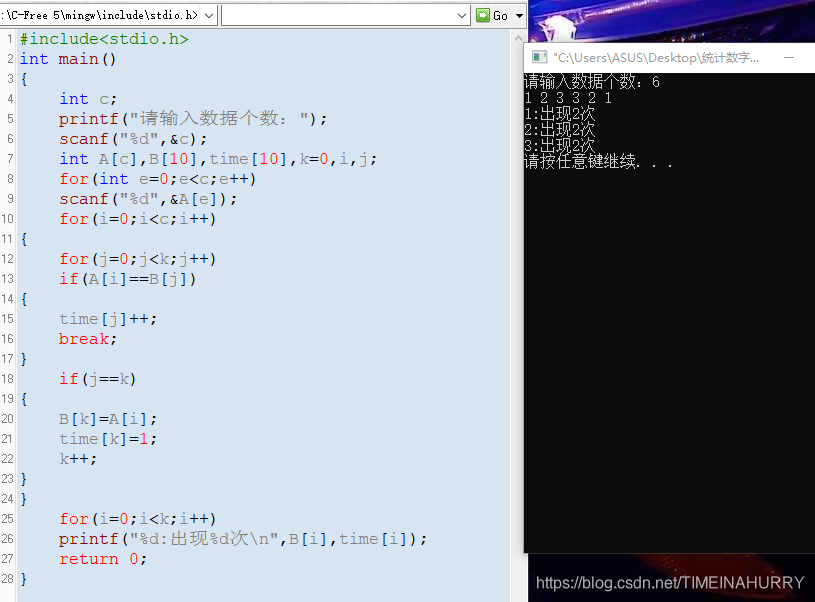
这篇关于c语言中统计一组整形数据出现的次数,不同的整形数按顺序依次输出的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




