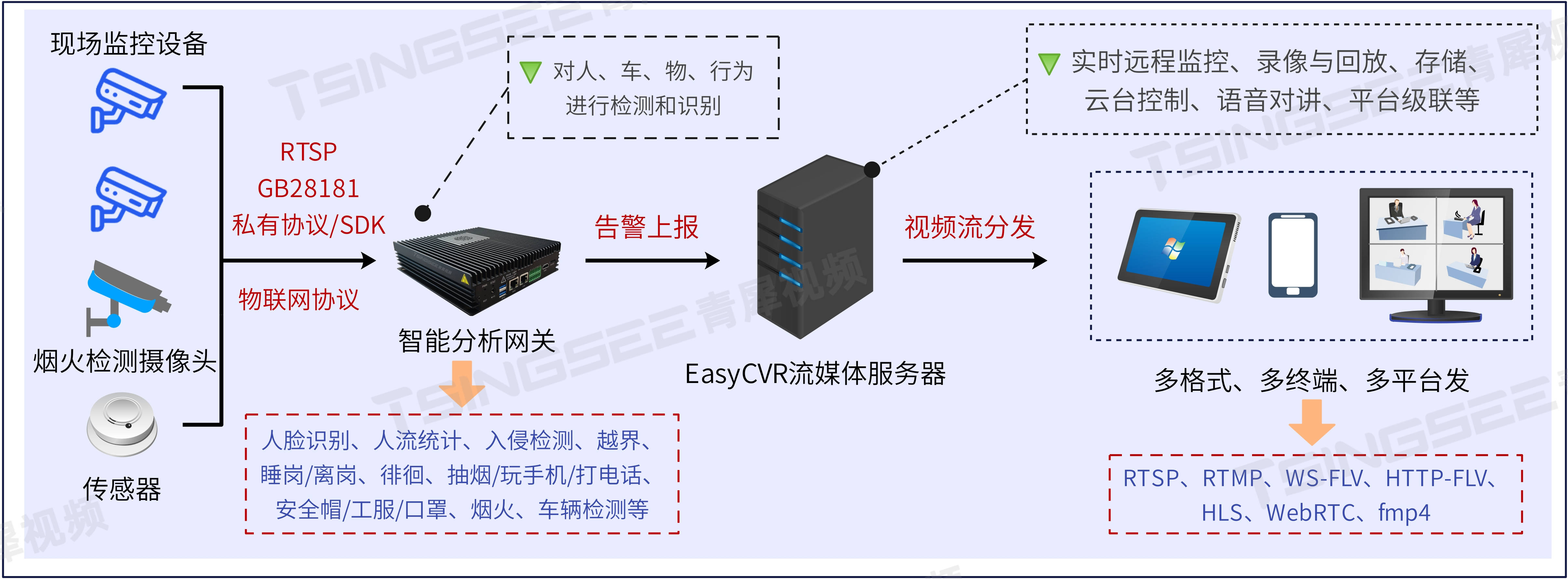
本文主要是介绍TSINGSEE青犀边缘计算AI智能分析网关V4客流统计算法的配置步骤及使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
TSINGSEE青犀AI智能分析网关V4内置了近40种AI算法模型,支持对接入的视频图像进行人、车、物、行为、烟火等实时检测分析,上报识别结果,并能进行语音告警播放。硬件支持RTSP、GB28181协议、以及厂家私有协议接入,可兼容市面上常见的厂家品牌设备,可兼容IPC、网络音柱等。同时也支持智能摄像头的接入,对于已部署有AI算法的智能摄像头,平台也能展示摄像头上传的告警信息。
其中,客流统计AI算法是指自动检测和统计设定区域内人头过线的数量,可以应用在景区、商场楼宇、车站、机场等场景中。正在使用TSINGSEE青犀AI智能分析网关V4的用户,可能会使用到【客流统计】这一算法,但有很多用户却并不清楚这一算法的配置和使用。今天我们来介绍一下:智能分析网关V4如何配置客流统计算法?
在此之前,我们需要简单了解一下客流统计算法的检测要点。
客流统计是通过在指定的经营区域安装客流统计设备,精准统计出每个入口实时客流的进出人数。所以客流统计是包含进出或者正反的辨识,需要分别统计进和出的总人数。
1)首先,添加一个用于识别的网络监控摄像头,然后给这个摄像头添加【客流统计】算法。
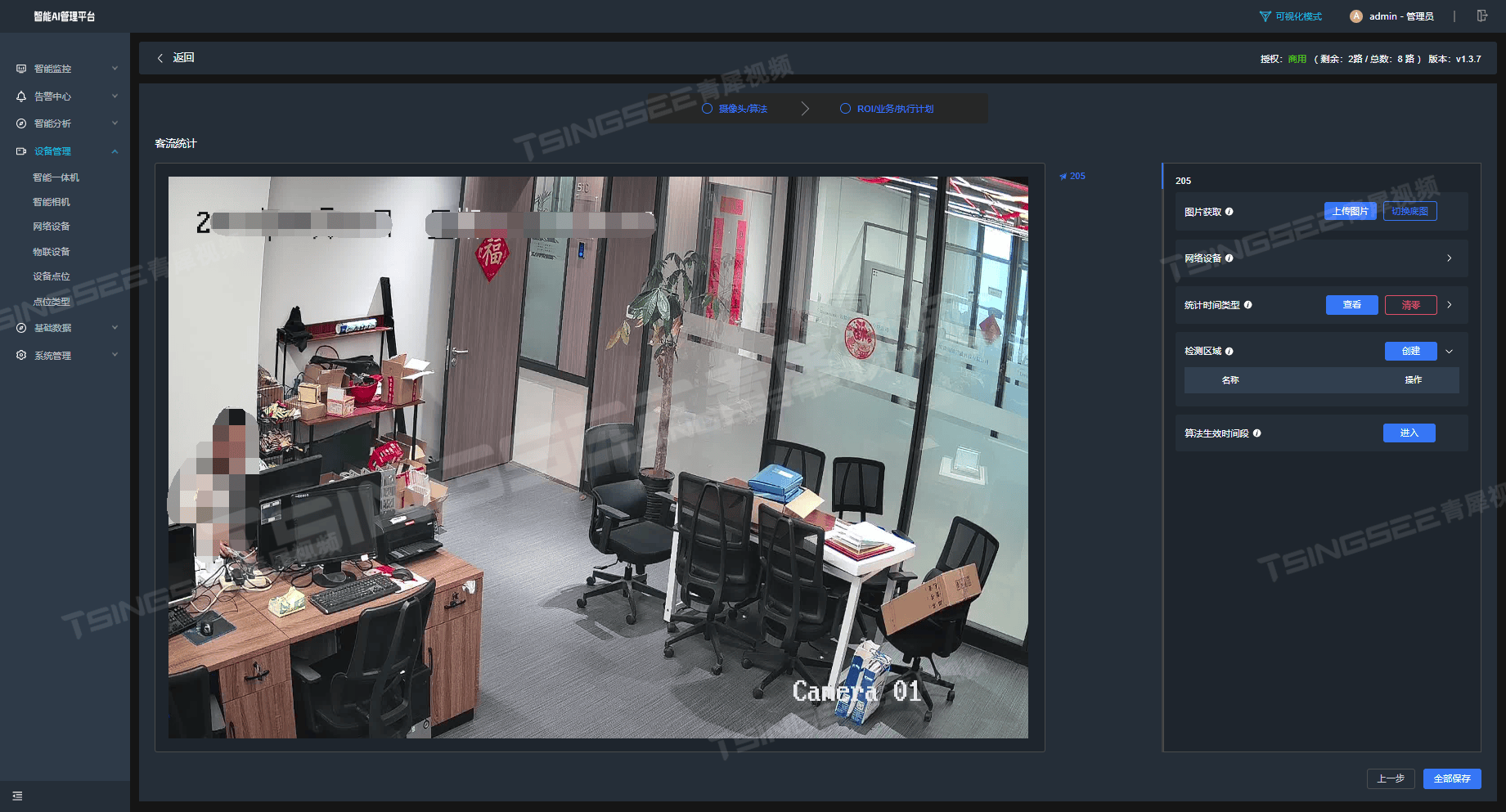
2)如上图所示,在这个界面点击【检测区域】的【创建】按钮,会在画面中添加一个类似坐标系一样的图形,它是由一个箭头加上一个线段组成的“十”字图形。
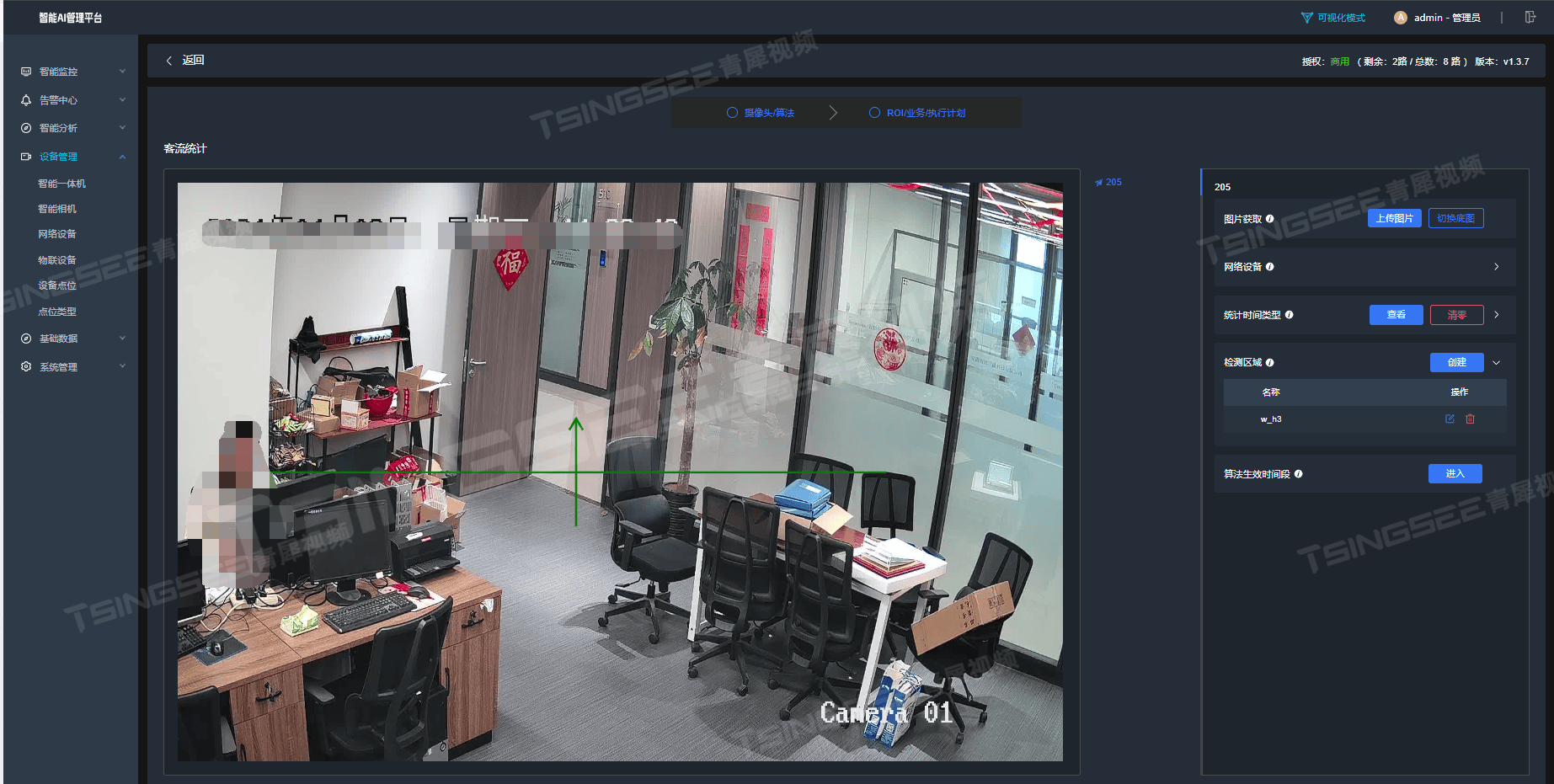
3)我们可以点击它,然后将它移到出入口的位置,线段的长度是可以调整的,且可以任意调整位置。先按照当前的环境将它绘制好,然后再讲解为什么要这样设置。

4)上图就是设置的最终位置。那么,为什么要这样设置呢?
首先【客流统计】算法的识别需要满足两个条件:第一是人员流动的方向,我们可以看到一个箭头,该箭头就是控制方向的,顺箭头为正方向,逆箭头为反方向;第二是横着的线段,这个线段表示当人员的头部一半越过了这条线,那么就触发算法,按照运行的方向累加进出的数值。
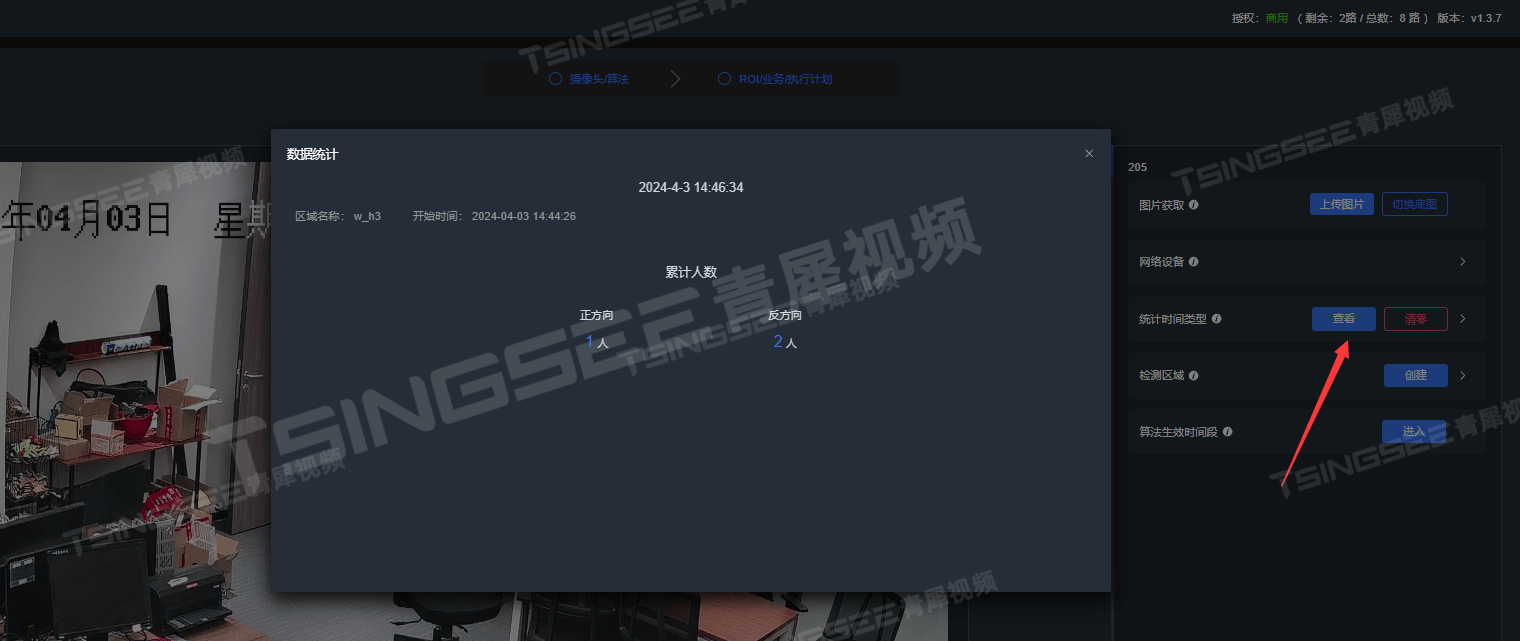
5)算法配置完成后,我们可以在【智能监控】-【实时监控】里查看累计的人员进出数量。

6)也可在配置算法的界面,点击【统计时间类型】-【查看】,查看数据统计详情,为用户提供参考数据用于决策分析。
客流量统计AI算法的应用场景包括商场、地铁站、公共交通工具、车站、机场等人流量较大的场所。通过实时监控客流量,可以进行人员调度、资源分配、安全预警等方面的管理和决策。
1)智慧景区/公园:利用客流量统计算法实时监测景区、公园等场所的人流量,保障场所安全,防止因人流量过大出现拥挤现象,同时基于客流量统计与变化数据能更好地了解游客需求和市场趋势,从而协助管理者制定针对性的管理和优化策略,提升游客的满意度和品质。
2)智慧门店/商场:基于客流量统计AI算法可以帮助商家了解顾客的流量和行为,基于对客流动态的分析,客观反映门店/商场运营特点,为商家优化店面布局和服务质量提供决策数据支持。
3)智慧工厂/工地:可用于监测工地、工厂、车间等场景出入口的人流量,协助管理人员对工地人员进出实现更加智慧高效的管理。
4)交通运输:该算法可以用于监测地铁、公交车站等公共交通场所的人流量,为交通管理部门提供数据支持,优化交通规划和运营。
这篇关于TSINGSEE青犀边缘计算AI智能分析网关V4客流统计算法的配置步骤及使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





