本文主要是介绍分表?分库?分库分表?实践详谈 ShardingSphere-JDBC,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
如果有不是很了解ShardingSphere的可以先看一下这个文章:
《ShardingSphere JDBC?Sharding JDBC?》基本小白脱坑问题
阿丹:
在很多开发场景下面,很多的技术难题都是出自于,大数据量级或者并发的场景下面的。这里就出现了我们要解决的。本文章重点讨论一下在java的spirng开发场景下,有哪些业务场景可以让我们使用下面的三个场景:
分表?分库?分库分表?
这个文章的根本就是能让大家可以自己上手使用,以及清楚分表?分库?分库分表?这三种业务场景,来帮助大家可以使用这样的技术来解决业务的难题。
在开始前先给分表?分库?分库分表?这三个业务场景先搞清楚在说。
分库分表:
分库和分表有两种形式,垂直和水平
分库的两种模式:
分库:
垂直分库:
也就是说,垂直的将各个领域分开成表。
将不同的垂直的领域来进行分库

水平分库:
将单个性质的数据库,平行拆分多个数据库,对于数据库的命名使用附带逻辑的命名来解决这个问题。
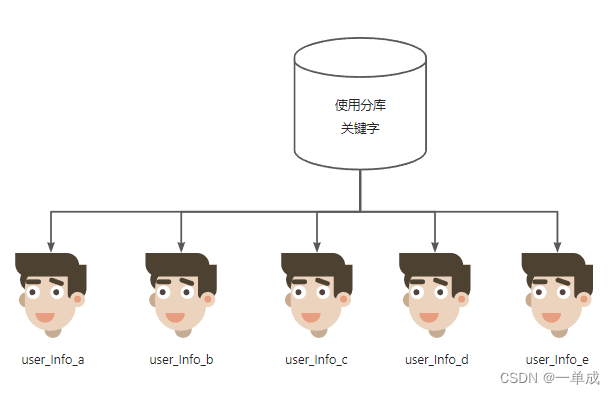
分表:
垂直分表:
也就是按照业务维度来将数据进行拆分,将不常用的信息放到一个扩展表中去。

水平分表:
水平也就是将用户做一个水平的分布,展现出来就是user_table_--name这样的方式来展现
什么时候这样做呢?
从两个方向去考虑
1、数据库连接
2、单表数据量
当数据库连接不够的时候,肯定是使用分库的方式来完成这个操作
当单表的数据影响到数据操作的时候,使用分表来完成这个操作。具体多少以上要根据单条数据量级,以及数据内核来计算。
那么什么时候来使用分库分表?
在高并发的写入或者查询的场景下面
以及在数据量非常巨大的情况下面我们就可以开始考虑分库分表来进行操作了。
那分库分表使用什么技术栈呢?
数据库分库分表框架 ShardingSphere
官方操作文档:
ShardingSphere-JDBC :: ShardingSphere
Sharding-JDBC 是一款开源的Java框架,主要用于在数据库层面解决大规模数据存储下的水平扩展问题,即数据分片(sharding)。它通过在应用程序的JDBC层进行增强,使得开发者能够在不改变原有SQL操作习惯的前提下,透明地实现对数据库的分库与分表操作。
Sharding-JDBC的主要特点包括:
-
轻量级客户端模式:无需额外部署服务器端中间件,直接作为JDBC驱动集成到应用中,无缝对接各类 ORM 框架及 JDBC 使用场景。
-
透明化分片:通过解析SQL语句以及应用自定义的分片规则,自动路由到正确的数据库和表,对于应用层来说,就像是在操作一个完整的逻辑数据库。
-
功能全面:支持多数据源、读写分离、分库分表、数据一致性保证(如分布式事务)、灵活的分片策略等,并且提供了丰富的分片算法供用户选择或自定义。
-
高性能:由于其工作原理是在客户端完成SQL解析和路由,避免了网络传输开销,理论上性能更优。
-
兼容性良好:完全兼容JDBC和大部分ORM框架,可以很容易地整合到现有的基于Java的企业级应用中。
分片键
用于将数据库(表)水平拆分的数据库字段。
分库分表中的分片键(Sharding Key)是一个关键决策,它直接影响了分库分表的性能和可扩展性。以下是一些选择分片键的关键因素:
- 访问频率:选择分片键应考虑数据的访问频率。将经常访问的数据放在同一个分片上,可以提高查询性能和降低跨分片查询的开销。
- 数据均匀性:分片键应该保证数据的均匀分布在各个分片上,避免出现热点数据集中在某个分片上的情况。
- 数据不可变:一旦选择了分片键,它应该是不可变的,不能随着业务的变化而频繁修改。
分片键(Sharding Key)是数据库分片技术中非常关键的概念。在分布式数据库系统或者数据仓库中,当单个数据库实例无法容纳全部数据,或者为了提高并发处理能力和数据访问效率时,往往会采取水平分区的方式,也就是数据分片(Sharding),将数据分布到多个物理节点上。
分片键是指在进行数据分片时,用来确定数据记录应被分配到哪个特定分片上的字段或属性。它是数据分区的依据,根据分片键的值,通过预定义的分片策略(例如哈希、范围、列表等)计算出数据应该存储在哪个分片上。换句话说,分片键的选择直接关系到数据在各个分片之间的分布均衡性、查询性能以及业务需求的满足程度。
例如,如果我们有一个订单表orders,并且按年份进行分片,那么o_orderdate字段就可以作为分片键,每年的订单数据都会被存储在一个特定的数据库分片中。在实际应用中,分片键的选择应当尽量考虑以下因素:
- 查询模式:选择那些频繁出现在查询条件中且能均匀分布数据的字段。
- 数据增长趋势:确保分片键能够适应未来数据的增长,避免热点分片。
- 分区粒度:粒度过大可能造成单个分片过大,粒度过小则可能导致分片过多,影响管理效率和查询效率。
总之,分片键是整个分片机制的核心,合适的分片键能够有效提升分布式数据库系统的可扩展性和可用性。
Sharding-JDBC引入项目
需求:
我要使用ShardingSphere JDBC完成分库,库名为XXXX_2024往后就是按照年份来,每年一个日志的库,Id为雪花算法生成,
分表的原理为XXXXX_0402像这样在表后面追加时间来完成比如今天是4月7号就是在表后面追加0407
引入依赖
ShardingSphere-JDBC配置application.yml文件文件
# application.yml
spring:shardingsphere:datasource:names: ds0 # 数据源名称,可添加更多数据源以支持读写分离ds0:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/chicklogin_record_2024?serverTimezone=UTCusername: rootpassword: passwordsharding:tables:chick_record: # 表名逻辑名称actual-data-nodes: chicklogin_record_$->{2024..2099}.chick_record_$->{0101..1231} # 分库分表策略,假设从2024年开始,每年一个库,每天一个表table-strategy:standard:sharding-column: record_date # 分表依据的字段名precise-algorithm-class-name: com.example.CustomDateTableShardingAlgorithm # 自定义分表算法类,处理日期转换为表后缀key-generator:column: id # 主键列名type: SNOWFLAKE # 使用雪花算法作为主键生成器props:worker-id: 1 # 雪花算法workerId配置,根据实际情况设定在配置文件中的定义分片规则!!注意:我们在自定义的时候需要给需要分表的一类表,在配置文件中说明如何分配
# application.yml
spring:shardingsphere:# ...其他配置...sharding:tables:chick_record: # 第一个表配置actual-data-nodes: chicklogin_record_$->{2024..2099}.chick_record_$->{0101..1231}table-strategy:standard:sharding-column: record_dateprecise-algorithm-class-name: com.example.CustomDateTableShardingAlgorithmorder_info: # 第二个表配置actual-data-nodes: chicklogin_record_$->{2024..2099}.order_info_$->{0101..1231}table-strategy:standard:sharding-column: order_dateprecise-algorithm-class-name: com.example.CustomDateTableShardingAlgorithm# ...其他配置...配置雪花算法ID生成器
如果使用的是内建的雪花算法主键生成器,通常无需额外配置。但如果需要自定义,也可以实现相关接口。这里默认使用内置的SnowflakeKeyGenerator。
在实体类中使用雪花ID注解
import org.apache.shardingsphere.infra.datanode.DataNode;
import org.springframework.data.annotation.Id;
import org.springframework.data.relational.core.mapping.Table;@Table(name = "chick_record")
public class ChickRecordEntity {@Idprivate Long id; // 由雪花算法自动生成// 其他属性和getter/setter省略
}pom依赖
<!-- Spring Boot Starter Data JPA 或 Spring Boot Starter MyBatis等基础数据库依赖 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId> <!-- 或 spring-boot-starter-mybatis 等 --></dependency><!-- ShardingSphere JDBC核心依赖 --><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>shardingsphere-jdbc-core</artifactId><!-- 检查ShardingSphere官网或Maven仓库获取最新的稳定版本号 --><version>{latest_version}</version></dependency><!-- 如果你的项目中使用了MySQL数据库驱动 --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><!-- 根据实际情况填写版本号 --><version>{mysql_driver_version}</version><!-- 若使用Spring Boot,通常可以作为provided或者runtime scope --><scope>runtime</scope></dependency>
具体的增删改查还使用MyBatis Plus或其他持久层框架集成-就OK了
这个就不在这个文章中在教大家了,大家可以自行去搜索一下。
注意!!!
Apache ShardingSphere-JDBC 提供了一种称为“透明化分片”的能力,通过其内置的优化机制,它可以尽可能地减少跨分片的SQL查询带来的性能损失。为了提高查询效率并避免多次查询不同分片表的情况发生,ShardingSphere-JDBC提供了以下几种机制:
-
分片路由优化:
- 对于简单的分片SQL,ShardingSphere-JDBC会根据分片策略智能路由至正确的数据源和表,确保一次查询仅访问必要的分片。
-
广播表:
- 广播表是指在所有分片库中完全复制的一张表,用于存储全局唯一或者不需要分片的数据。查询广播表时,ShardingSphere-JDBC会在所有数据源上执行相同的查询,并将结果合并返回。
-
笛卡尔积连接消除:
- 当SQL中有多个分片表参与JOIN查询时,默认情况下ShardingSphere-JDBC会尽量避免产生不必要的笛卡尔积,而是通过分析查询条件,找出最优的连接顺序和范围,减少分片间的数据交互。
-
多表关联查询优化:
- 对于涉及多个分片表的复杂查询,如果满足特定条件(例如join条件包含了分片键),ShardingSphere-JDBC能够进行优化,从而减少跨分片查询次数。
-
分页优化:
- 对于带有LIMIT和OFFSET的分页查询,ShardingSphere-JDBC会对分页参数进行重置,以保证在分片环境下也能获取正确的分页结果,同时降低无效数据的传输。
-
Hint机制:
- 用户可以通过SQL Hint直接指定查询的目标数据源或表,强制指定路由规则,这对于某些特殊场景下避免全表扫描或跨分片查询非常有用。
通过以上特性,ShardingSphere-JDBC能够帮助开发者在处理分片场景下的SQL查询时,有效提升查询效率并减少对多个表的重复查询。然而,值得注意的是,针对过于复杂的SQL语句和查询场景,仍需结合业务特点和数据分布进行合理的设计和优化。
这篇关于分表?分库?分库分表?实践详谈 ShardingSphere-JDBC的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



