本文主要是介绍语音特征的反应——语谱图,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
语谱图的横坐标为时间,纵坐标为对应时间点的频率。坐标中的每个点用不同颜色表示,颜色越亮表示频率越大,颜色越淡表示频率越小。可以说语谱图是一个在二维平面展示三维信息的图,既能够表示频率信息,又能够表示时间信息。
创建和绘制语谱图的过程是首先对音频分帧,然后对每一帧进行傅里叶变换得到对应的频率特征,最后根据帧的先后顺序形成一张语谱图。我们可以通过 matplotlib.pyplot模块中的specgram函数绘制音频的语谱图,函数形式如下:语法:matplotlib.pyplot.specgram(x, NFFT=None, Fs=None, Fc=None,detrend=None, window=None, , noverlap=None, cmap=None, xextent=None, pad_to=None, sides=None, scale_by_freq=None, mode=None, scale=None, vmin=None, vmax=None, *, data=None,**kwargs)
X--为输入信号的向量,默认情况下,没有后续参数,x将被平分成8段分别进行傅里叶变换处理,如果x不能被平分成8段,则会做截断处理。
NFFT--傅里叶变换中每个片段的数据点数(窗长度),默认为256。 Fs--采样频率,默认为2。
window--窗函数,长度必须等于NFFT(帧长),默认为汉宁窗。
noverlap--窗之间的重叠长度。默认值是128。
xextent--None or(xmin,xmax)图像x轴范围。
Sides--{'default',onesided', 'twosided'}单边频谱或双边谱。
scale_by_freg--bool,密度值是否按密度频率缩放,MATLAB默认为真。
mode--{'default', 'psd', 'magnitude', 'angle', 'phase'}默认为 PSD 谱。
scale--{'default',1inear','dB')频谱纵坐标单位,默认为dB。返回值:
spectrum--二维阵列,频谱矩阵。
Freqs--一维数组,频谱图中每行对应的频率。 t--一维数组,频谱图中每列对应的时间。
int--图像。
代码如下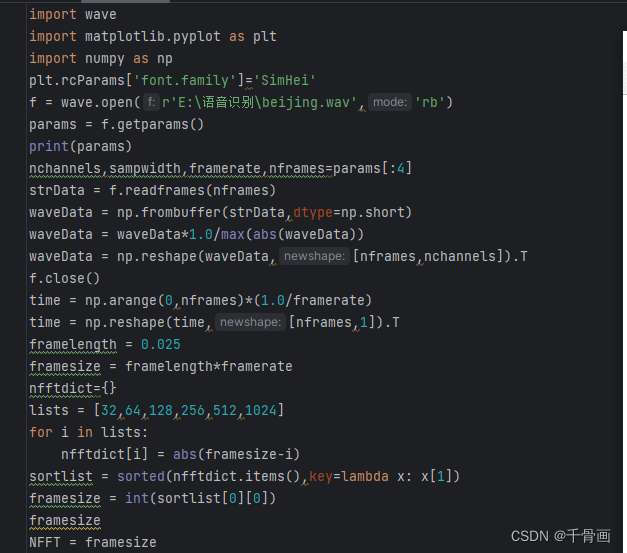
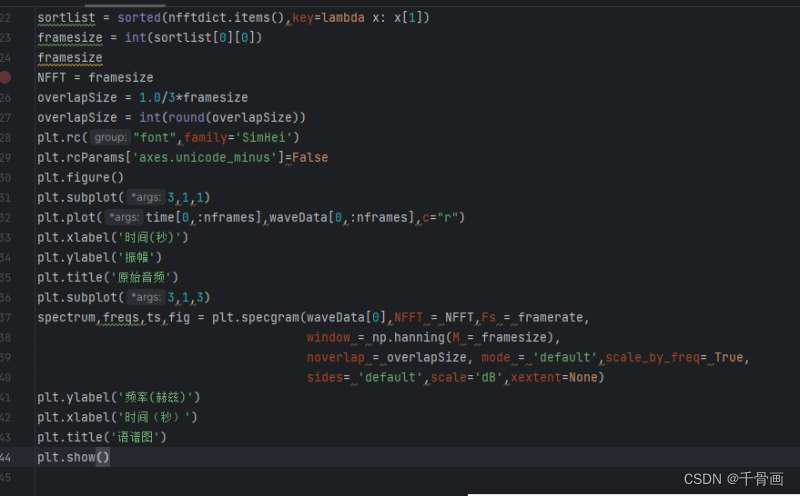
运行的结果如图: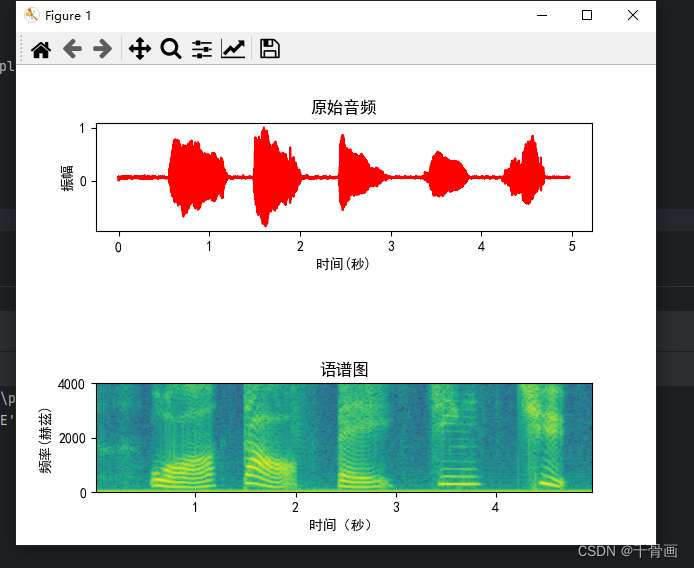
这篇关于语音特征的反应——语谱图的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







