本文主要是介绍Jackson @JsonUnwrapped注解扁平化 序列化反序列化数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考资料
- Jackson 2.x 系列【7】注解大全篇三
- @JsonUnwrapped 以扁平的数据结构序列化/反序列化属性
- Jackson扁平化处理对象
目录
- 一. 前期准备
- 1.1 前端
- 1.2 实体类
- 1.3 Controller层
- 二. 扁平化序列反序列化数据
- 2.1 序列化数据
- 2.2 反序列化数据
- 三. 前缀后缀处理属性同名
- 四. Map数据的处理
一. 前期准备
1.1 前端
$(function() {bindEvent();
});function bindEvent() {$("#btn").click(() => {// 准备提交到后端的数据const jsonData = {id: "112",name: "前端来的name",houseId: "前端来的houseId",address: "前端来的address",blogId: "前端来的blogId",blogName: "前端来的blogName"};$.ajax({url: `/test34/get_data`,type: 'POST',data: JSON.stringify(jsonData),contentType: 'application/json;charset=utf-8',success: function (data, status, xhr) {console.log(data);}});});
}
1.2 实体类
import com.fasterxml.jackson.annotation.*;
import lombok.Data;@Data
public class Test34Entity {private String id;private String name;@JsonUnwrappedprivate House house;@JsonUnwrappedprivate BlogTag blogTag;
}
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;@Data
@AllArgsConstructor
@NoArgsConstructor
public class House {private String houseId;private String address;
}
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;@Data
@AllArgsConstructor
@NoArgsConstructor
public class BlogTag {private String blogId;private String blogName;
}
1.3 Controller层
mport org.springframework.http.ResponseEntity;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.servlet.ModelAndView;import java.io.IOException;@Controller
@RequestMapping("/test34")
public class Test34Controller {@GetMapping("/init")public ModelAndView init() {ModelAndView modelAndView = new ModelAndView();modelAndView.setViewName("test34");return modelAndView;}@PostMapping("/get_data")public ResponseEntity<Test34Entity> getData(@RequestBody Test34Entity data) throws IOException {System.out.println(data);Test34Entity entity = new Test34Entity();// 设置基本类型的属性值entity.setId("1355930");entity.setName("贾飞天");// 设置自定义类型(bean)的属性值entity.setHouse(new House("house_id_1", "地球"));entity.setBlogTag(new BlogTag("tag_id_1", "tag_name_1"));return ResponseEntity.ok(entity);}
}
二. 扁平化序列反序列化数据
⏹@JsonUnwrapped注解只能处理Bean类型的数据,List<Bean>和Map<键,Bean>等数据类型是无法处理的。
2.1 序列化数据
- 给需要扁平化处理的Bean添加
@JsonUnwrapped注解 - 需要扁平化处理的Bean还需要有
构造函数,必须有构造函数,否则后台接收数据时会报错。 - 这样前台扁平化提交数据的时候,后台可以用一个类组合多个类的方式接收数据
⏹使用@JsonUnwrapped注解之前
- 前台需要提交如下的数据结构,前台的数据结构层次需要根据后台的Bean结构层次调整
const jsonData = {id: "112",name: "前端来的name",house: {houseId: "前端来的houseId",address: "前端来的address"},blogTag: {blogId: "前端来的blogId",blogName: "前端来的blogName" }
};
- 后台使用的数据结构
@Data
public class Test34Entity {private String id;private String name;private House house;private BlogTag blogTag;
}
⏹使用@JsonUnwrapped注解之后,前台无需根据后台的Bean结构来组装数据,直接扁平化提交即可,对于一些不使用Vue,React框架等前台框架的项目有用,能写起来更简单。
- 前台数据结构
const jsonData = {id: "112",name: "前端来的name",houseId: "前端来的houseId",address: "前端来的address",blogId: "前端来的blogId",blogName: "前端来的blogName"
};
- 后台数据结构
@Data
public class Test34Entity {private String id;private String name;@JsonUnwrappedprivate House house;@JsonUnwrappedprivate BlogTag blogTag;
}
⏹实质上是Jackson 通过@JsonUnwrapped注解将House和BlogTag属性拍扁放到Test34Entity实体类中。右下图可以看到,数据自动完成了封装。

2.2 反序列化数据
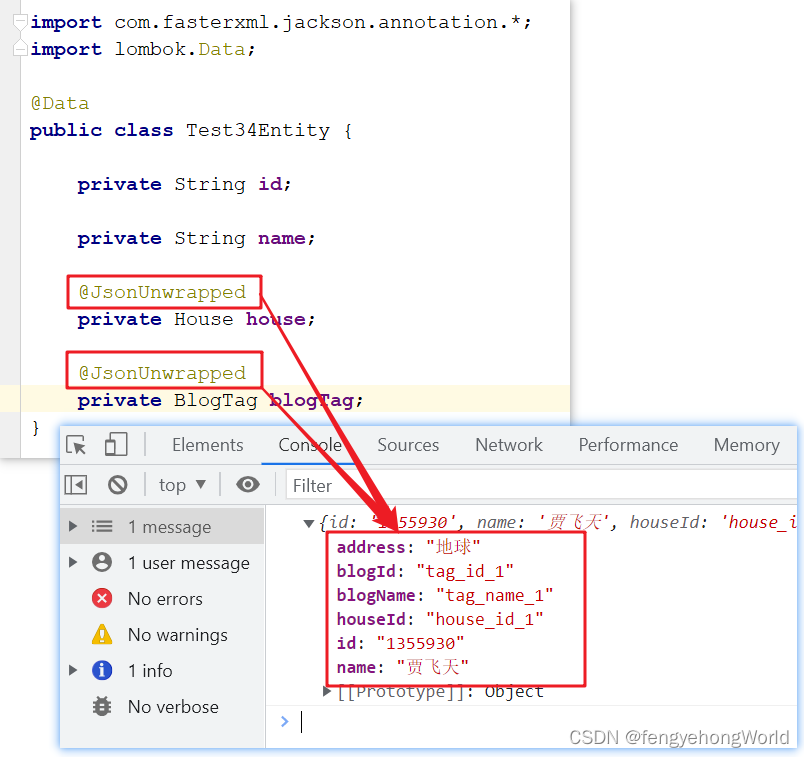
⏹不使用@JsonUnwrapped注解,前台的json数据结构和后台的Bean相同。
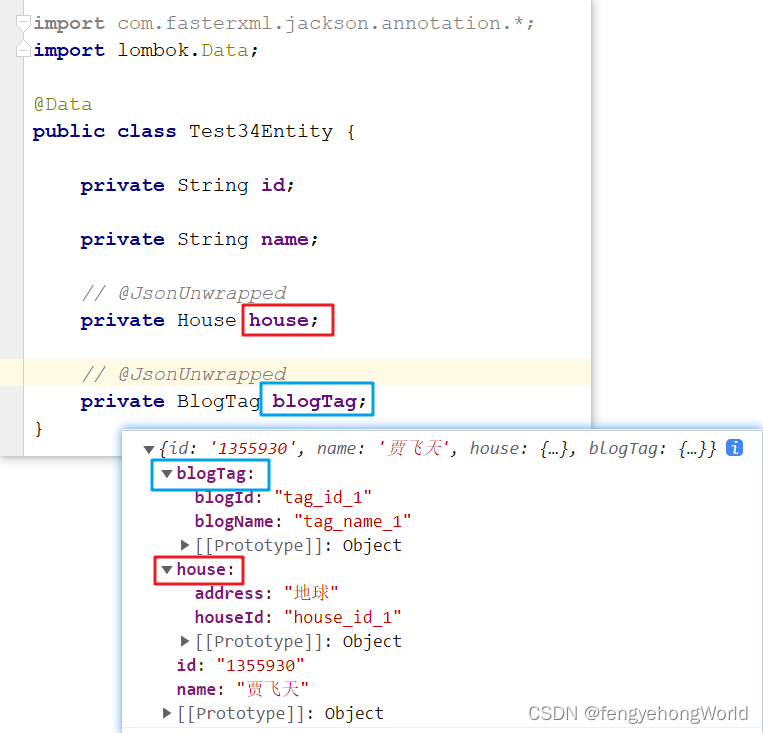
⏹使用@JsonUnwrapped注解,后台的嵌套的Bean属性被展平后返回给前台。
三. 前缀后缀处理属性同名
😅如下图所示,由于Test34Entity类和组合类的属性名相同,从而导致属性丢失。
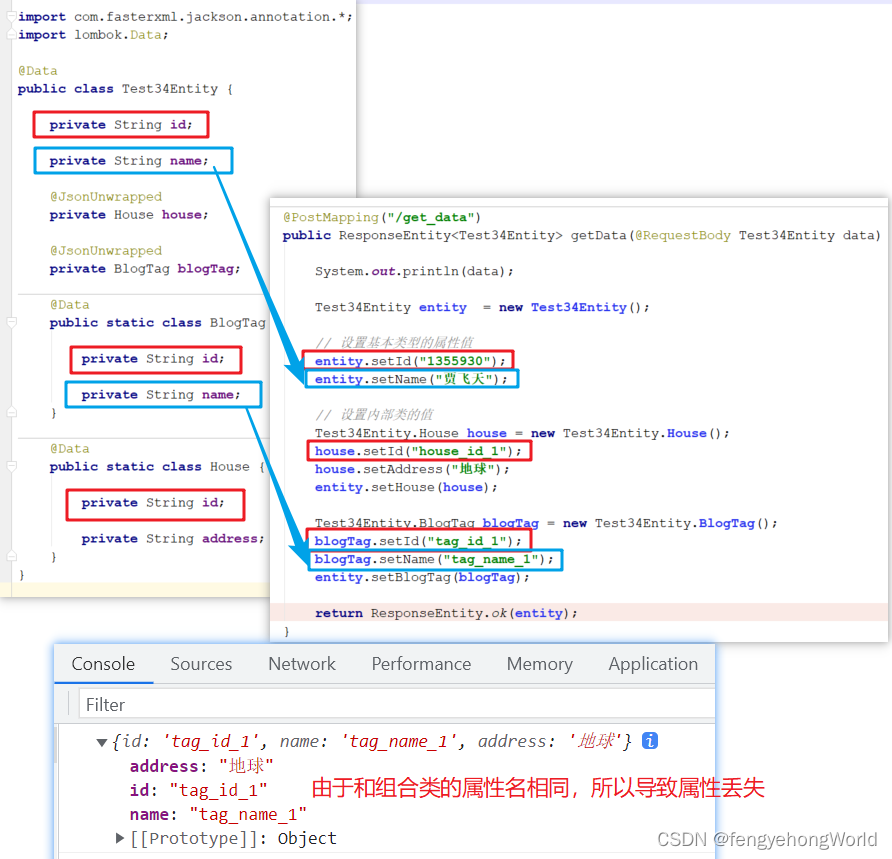
⏹可以在@JsonUnwrapped注解上指定前缀或后缀来避免属性重名问题
import com.fasterxml.jackson.annotation.*;
import lombok.Data;@Data
public class Test34Entity {private String id;private String name;@JsonUnwrapped(prefix = "house_", suffix = "_suffix")private House house;@JsonUnwrapped(prefix = "blog_", suffix = "_suffix")private BlogTag blogTag;@Datapublic static class BlogTag {private String id;private String name;}@Datapublic static class House {private String id;private String address;}
}
⏹反映到前端的截图如下所示

四. Map数据的处理
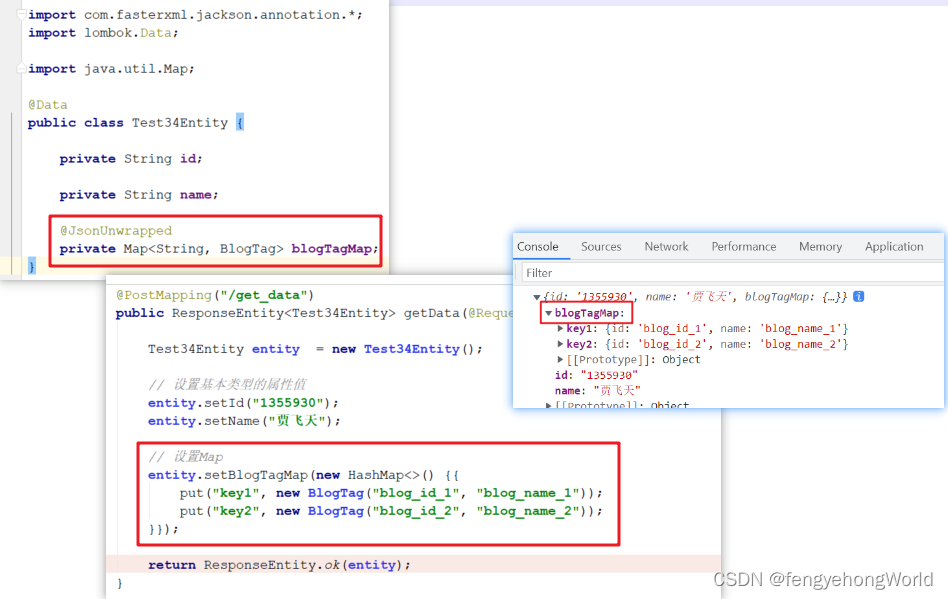
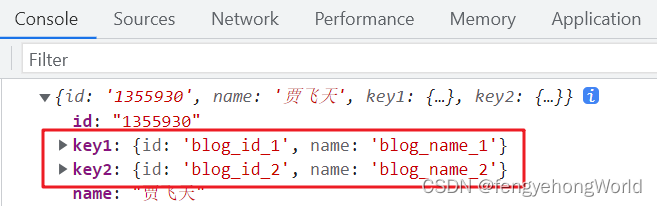
😅@JsonUnwrapped注解原生不支持Map,由下图所示,前台得到的json中,blogTagMap属性依然存在。
⏹将Test34Entity 实体类,进行如下修改
- 使用
@JsonAnySetter,@JsonAnyGetter注解 - addBlogTagMap,getBlogTagMap,setBlogTagMap方法名中的blogTagMap部分和属性名blogTagMap保持一致。
import com.fasterxml.jackson.annotation.*;
import lombok.Data;import java.util.Map;@Data
public class Test34Entity {private String id;private String name;private Map<String, BlogTag> blogTagMap;@JsonAnySetterpublic void addBlogTagMap(String key, BlogTag value) {blogTagMap.put(key, value);}@JsonAnyGetterpublic Map<String, BlogTag> getBlogTagMap() {return blogTagMap;}public void setBlogTagMap(Map<String, BlogTag> blogTagMap) {this.blogTagMap = blogTagMap;}
}
⏹然后在前台查看效果,可以看到外侧的blogTagMap属性名不见了。
这篇关于Jackson @JsonUnwrapped注解扁平化 序列化反序列化数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






