本文主要是介绍爬虫入狱笔记——xx政府网站公开政策数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近在学习爬虫,做个笔记吧

今天爬xx政府网站-政策法规栏目的数据
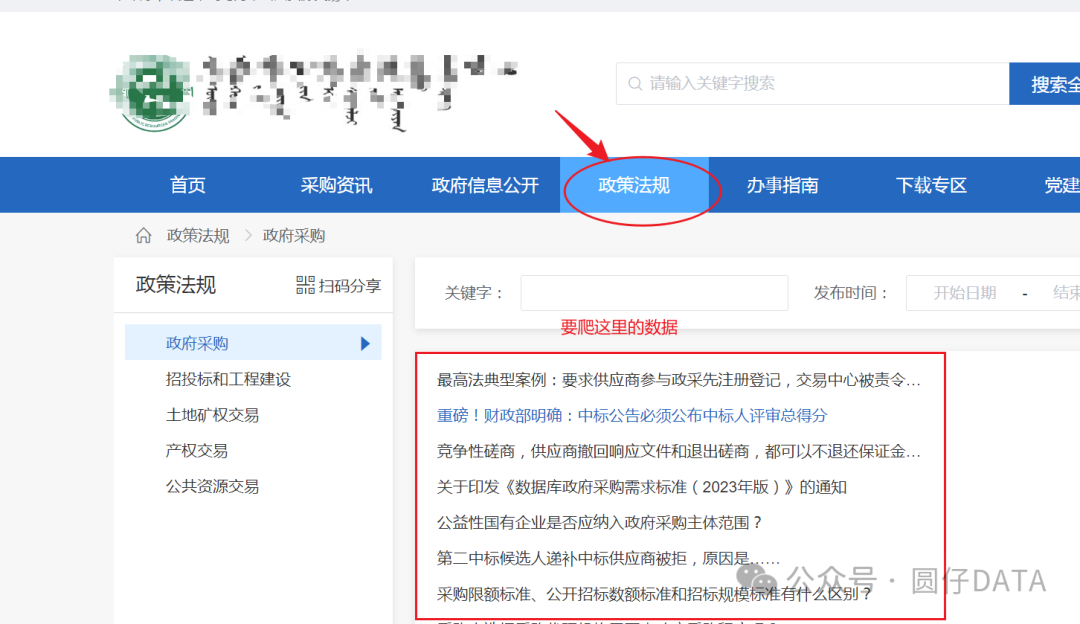
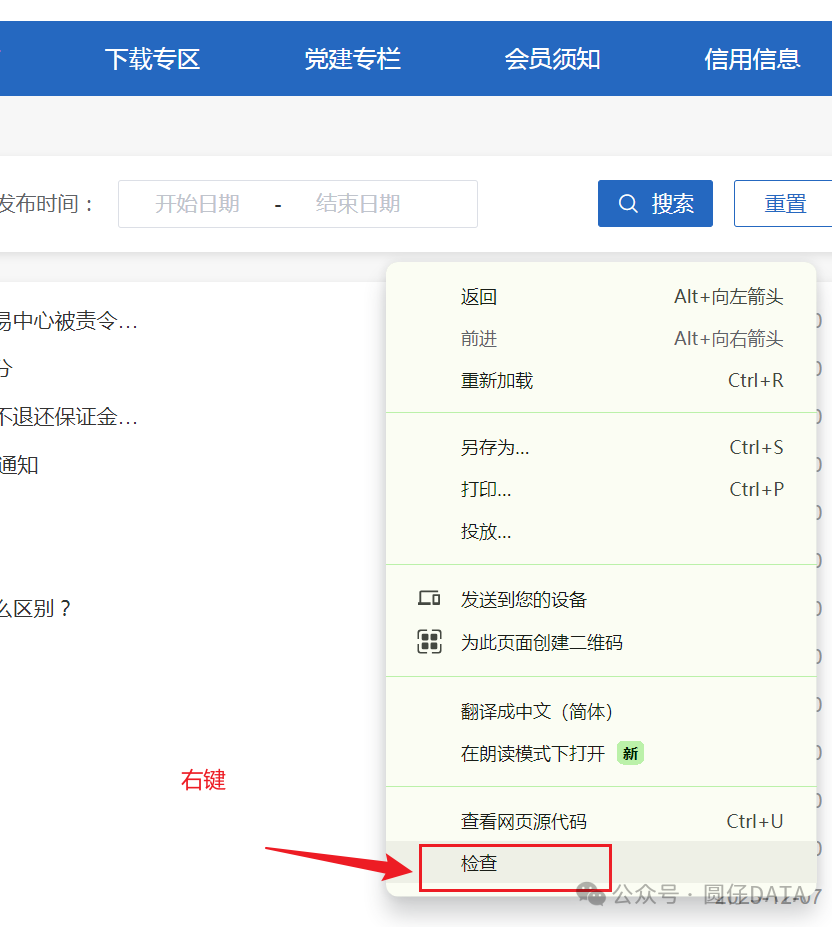
咱们首先需要找到数据从哪里来,鼠标右键->检查(或者快捷键一般为F12)检查元素,搜索关键词
eg.【违法案例】
回车,
如果没有的话,可以尝试刷新页面后重新回车搜索关键词
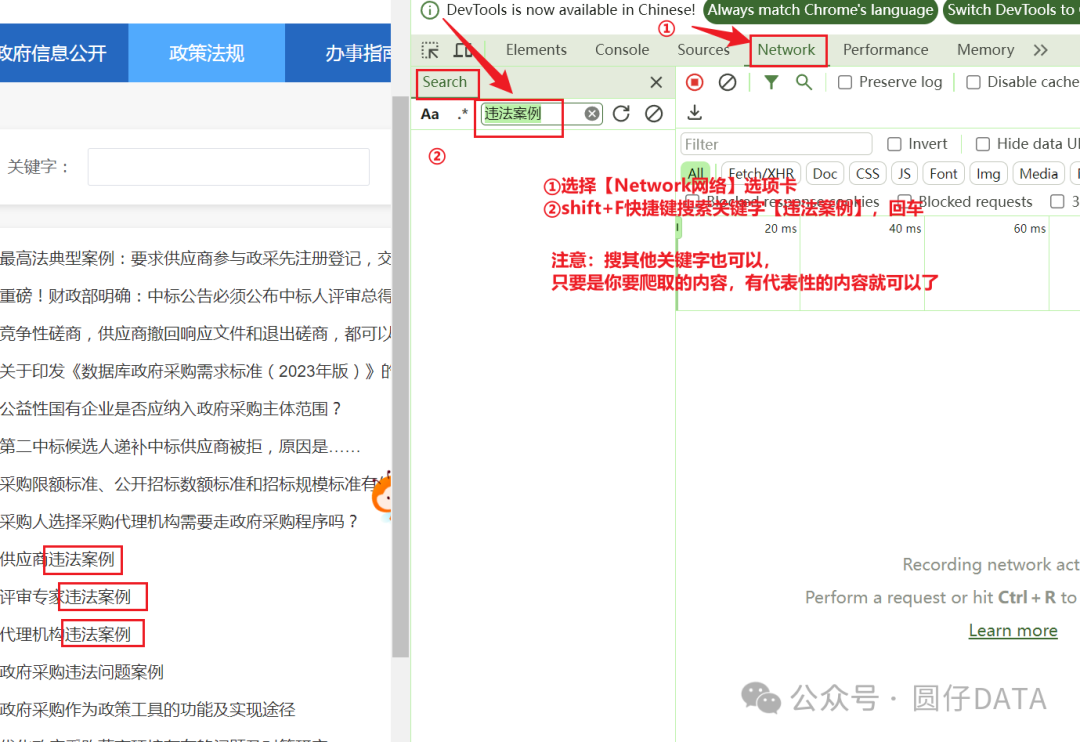
选中其中一个出现的搜索结果,
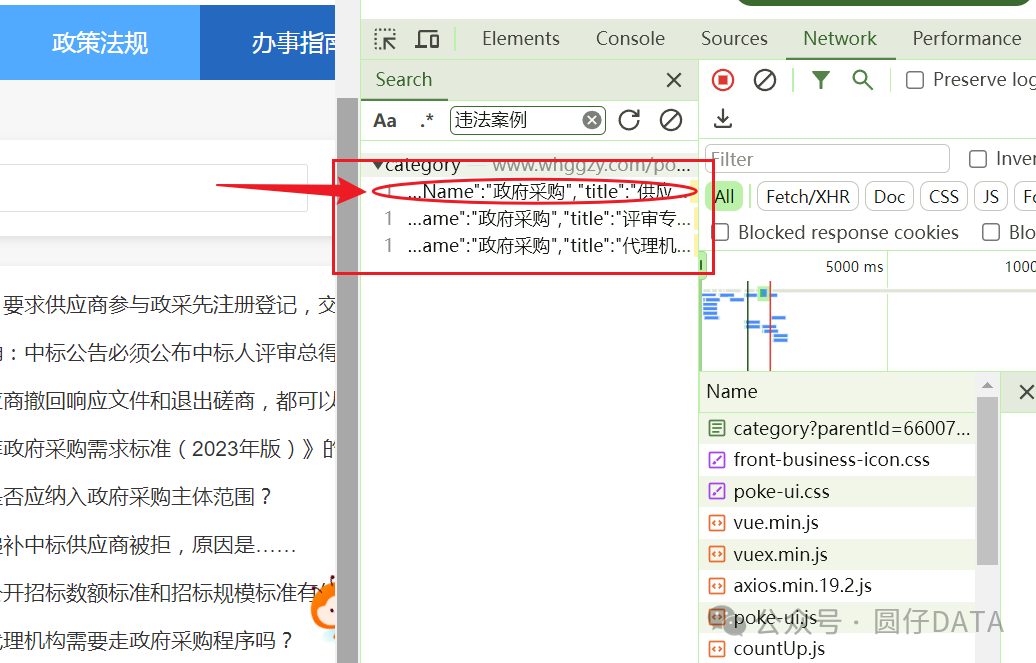
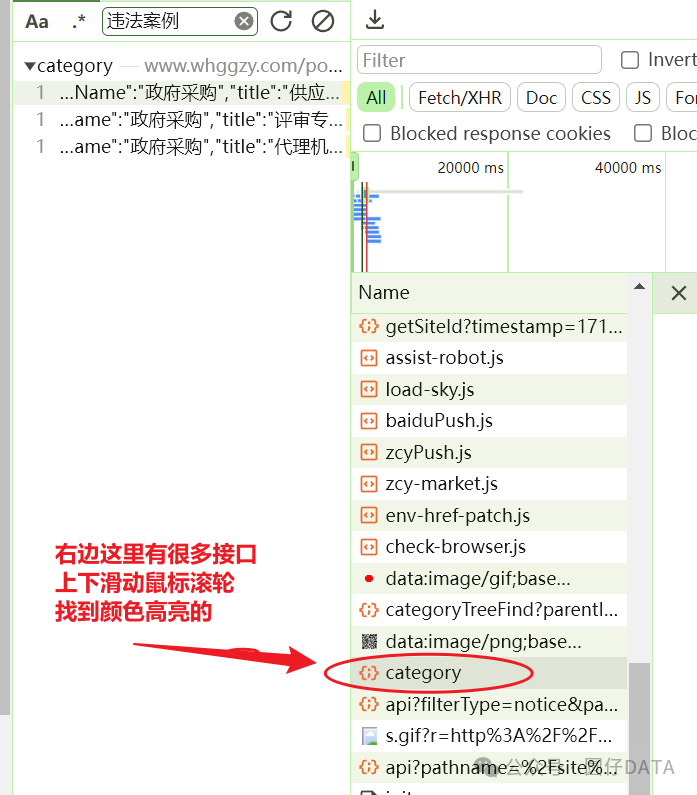
找到接口后,咱们看下是不是想要爬取的数据
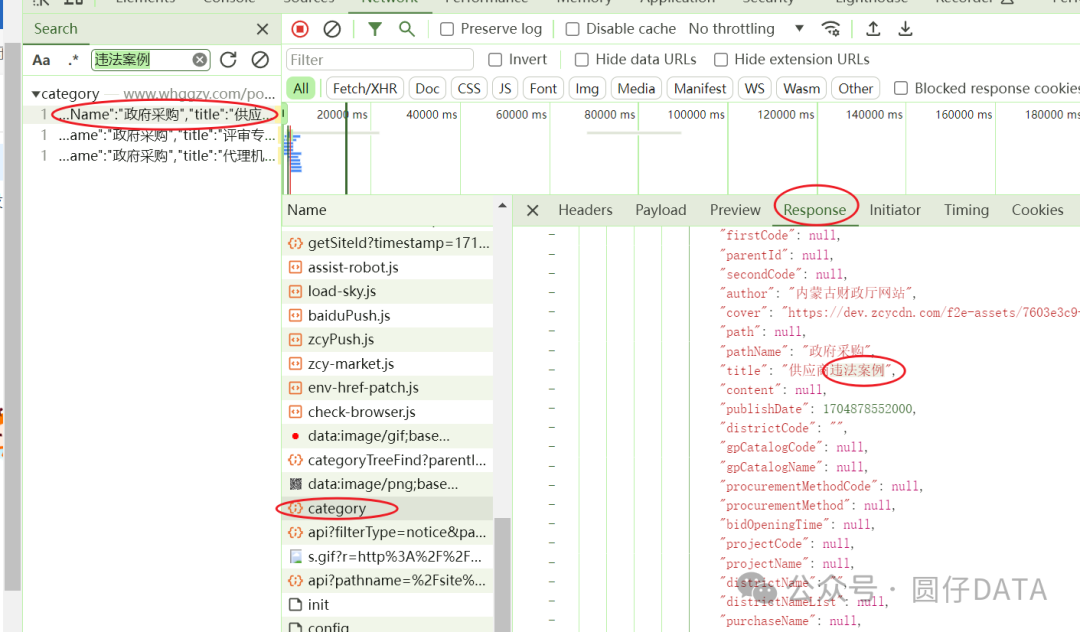
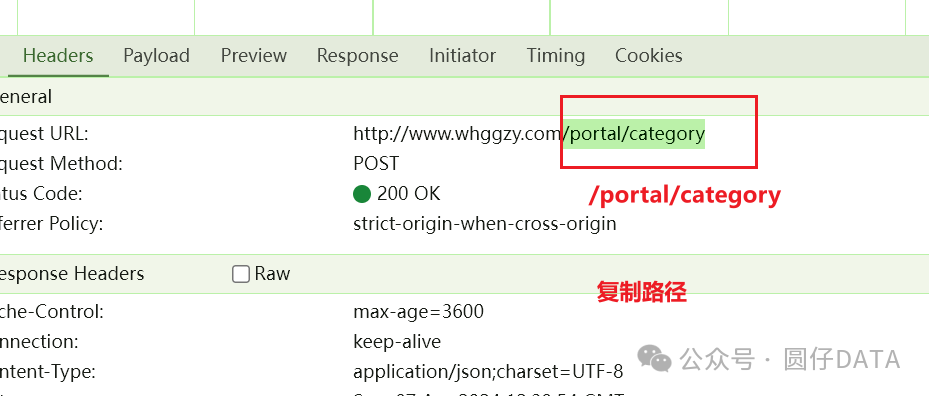
找到接口了,就是它 http://www.whggzy.com/portal/category 请求方法是POST
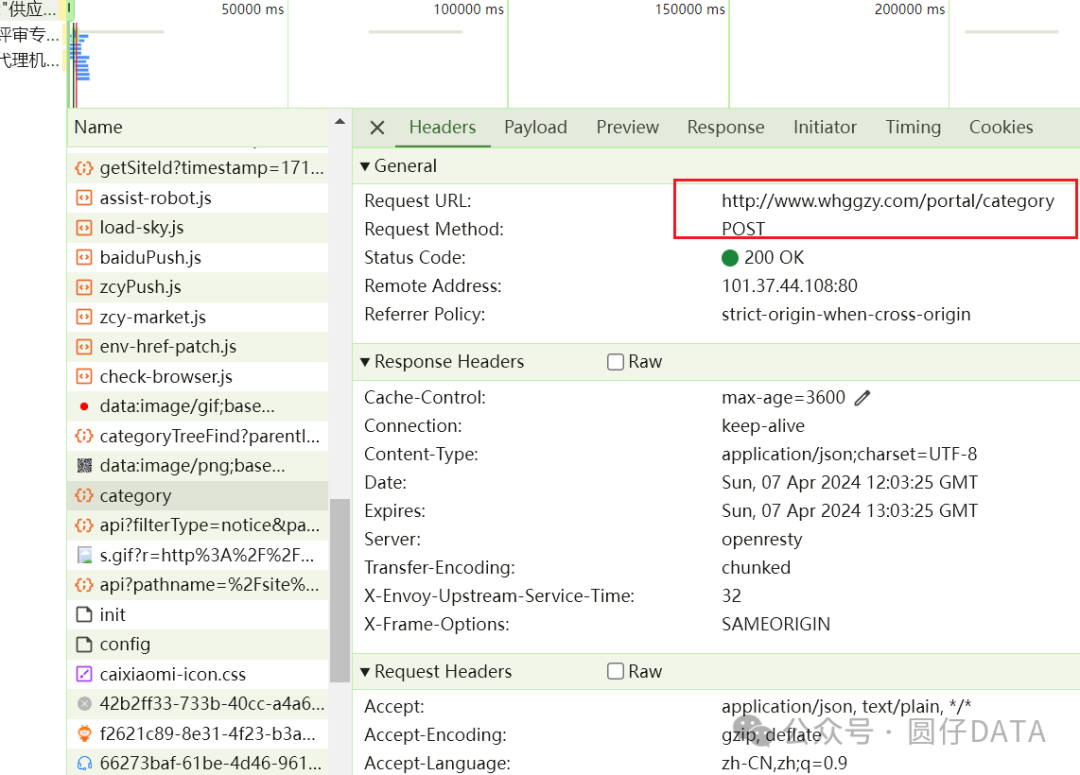
接下来,咱们看下它的请求头Headers跟请求参数Data吧
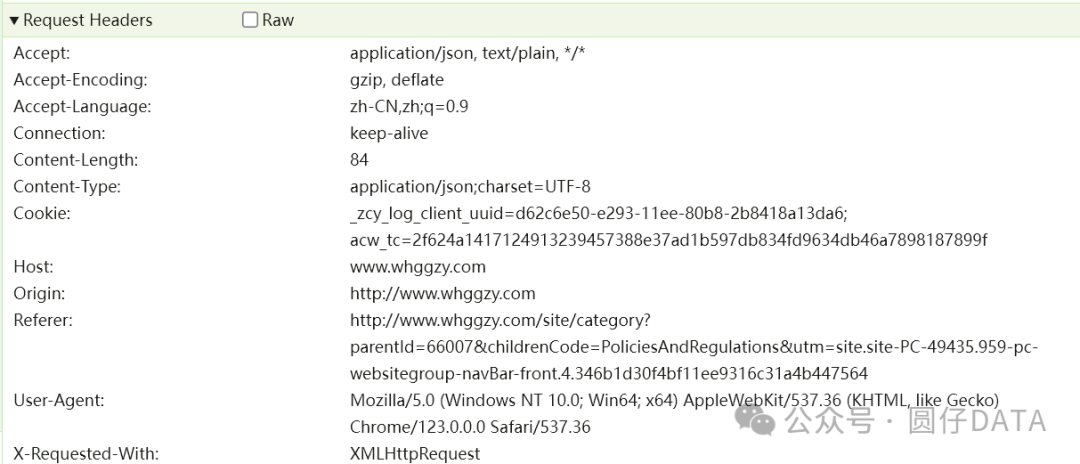
1. Headers
2. POST请求方法的Data:
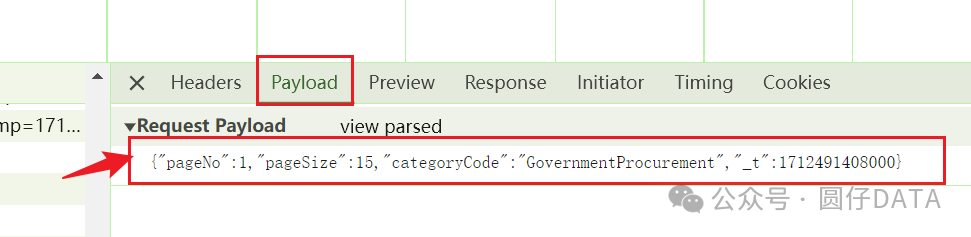
咱们到现在,直接按照这个Headers和Data构造,发送HTTP请求肯定没问题,但咱们要写爬虫代码,
第一步:看看Headers和Data里面哪些参数是必要的
第二步:有必要参数是加密的么【或者说,不能复制粘贴过来直接用的】
首先尝试下最基础的Referer和User-Agent够用不够用
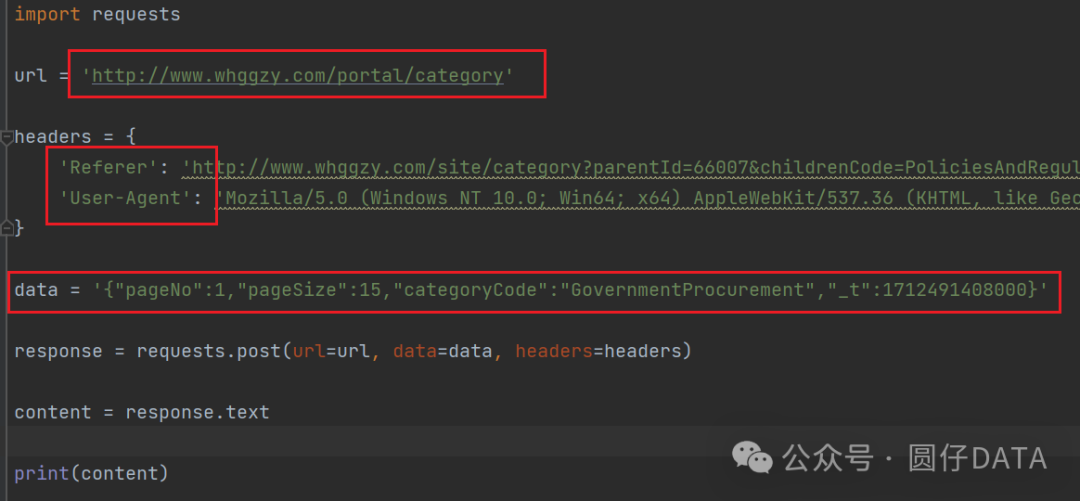
运行爬虫程序结果如下:
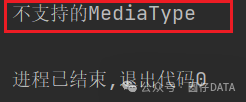
咱们对照着Headers参数看看,可能是缺了Content-Type
加上后再次运行
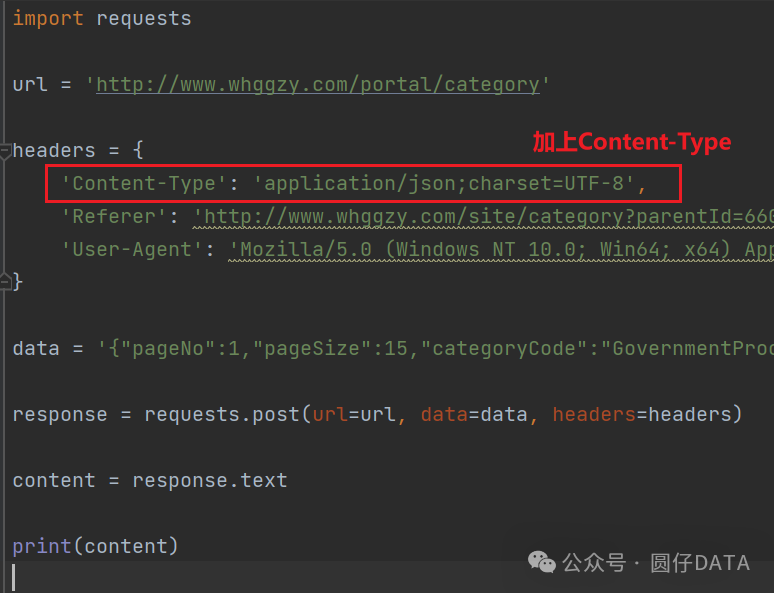
O了,成功获取数据,这边我把他保存到文件里了,方便截屏给各位读者朋友看
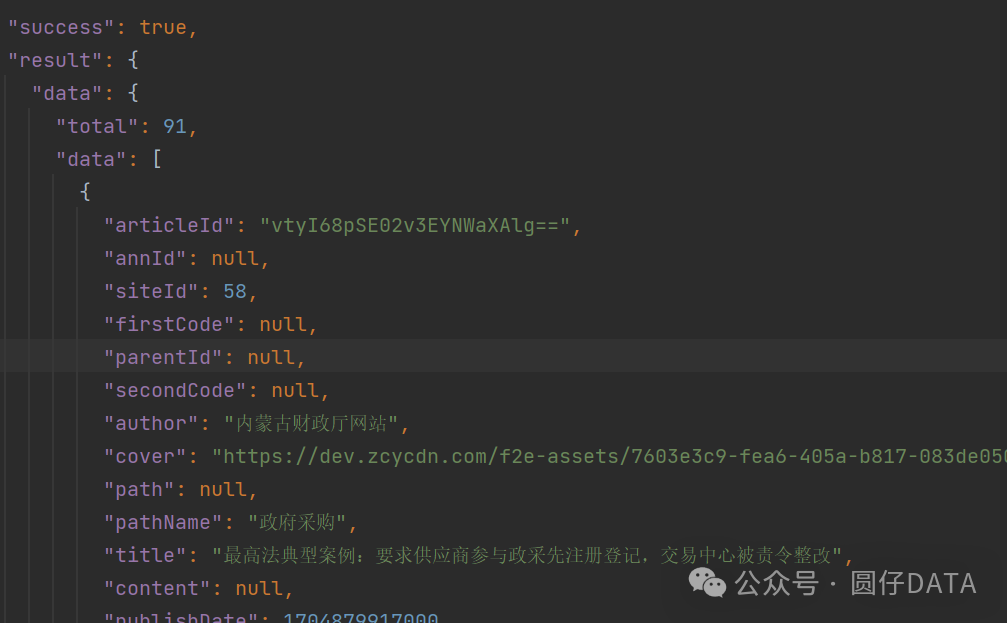
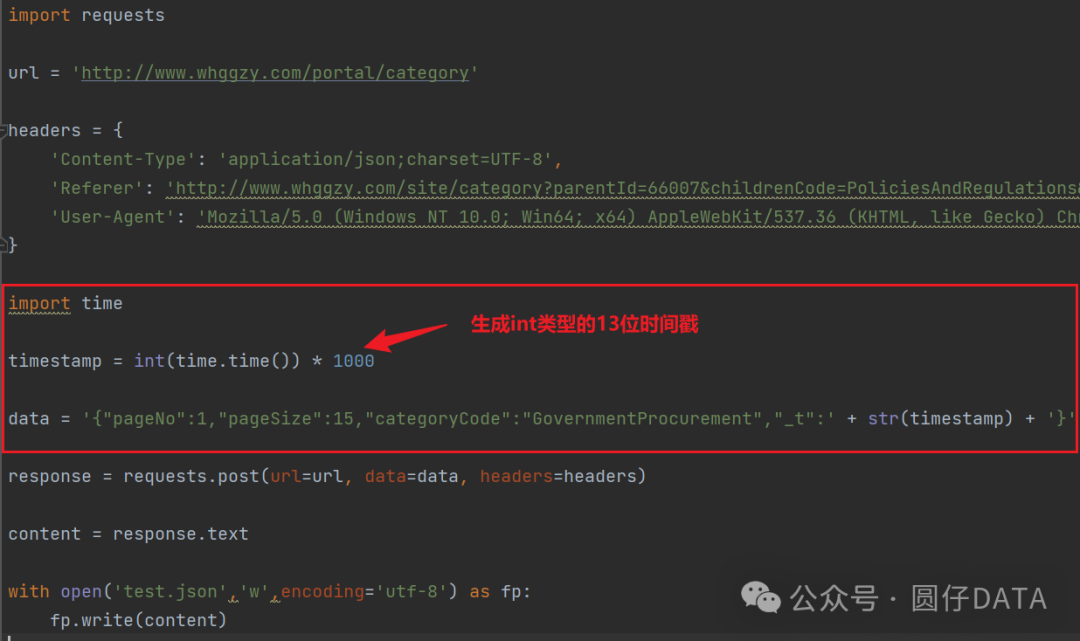
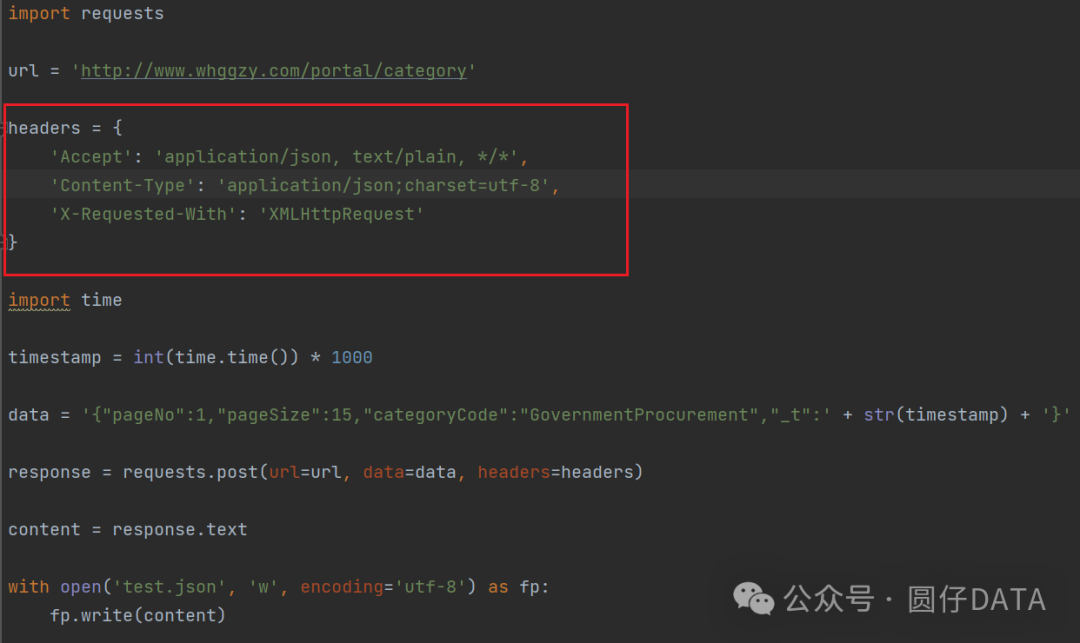
Headers和Data中,没啥加密的,就一个时间戳_t会变,咱们再修改下代码,生成时间戳吧
注意:这里的时间戳要注意位数,原本的时间戳是13位的,咱们这里也得和它一样
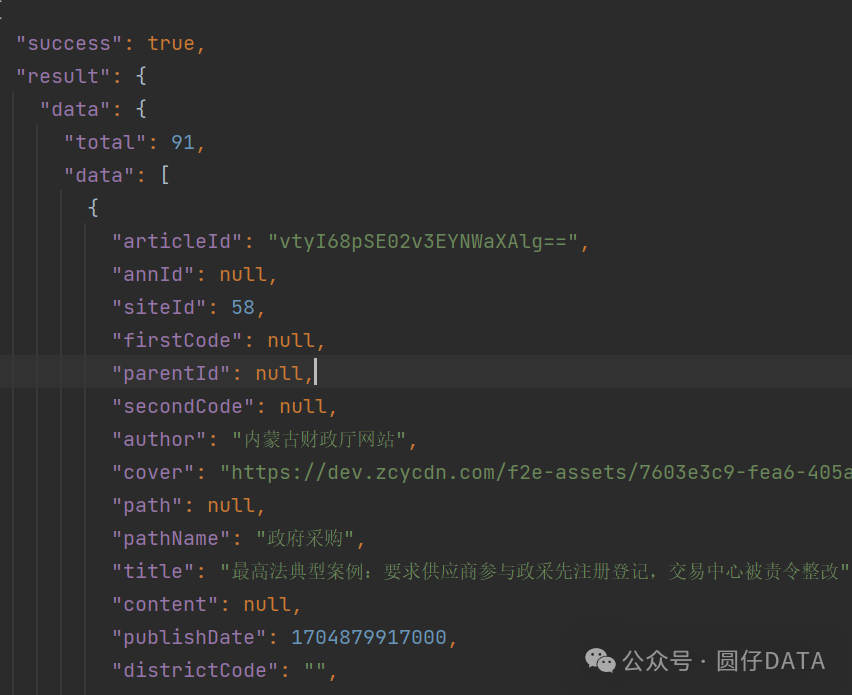
运行后没得问题,能拿到数据
视频教程里,在确定Headers里必要的参数时,是采取的调试JS代码的方式,我这边是直接通过程序返回的结果判断了少Content-Type
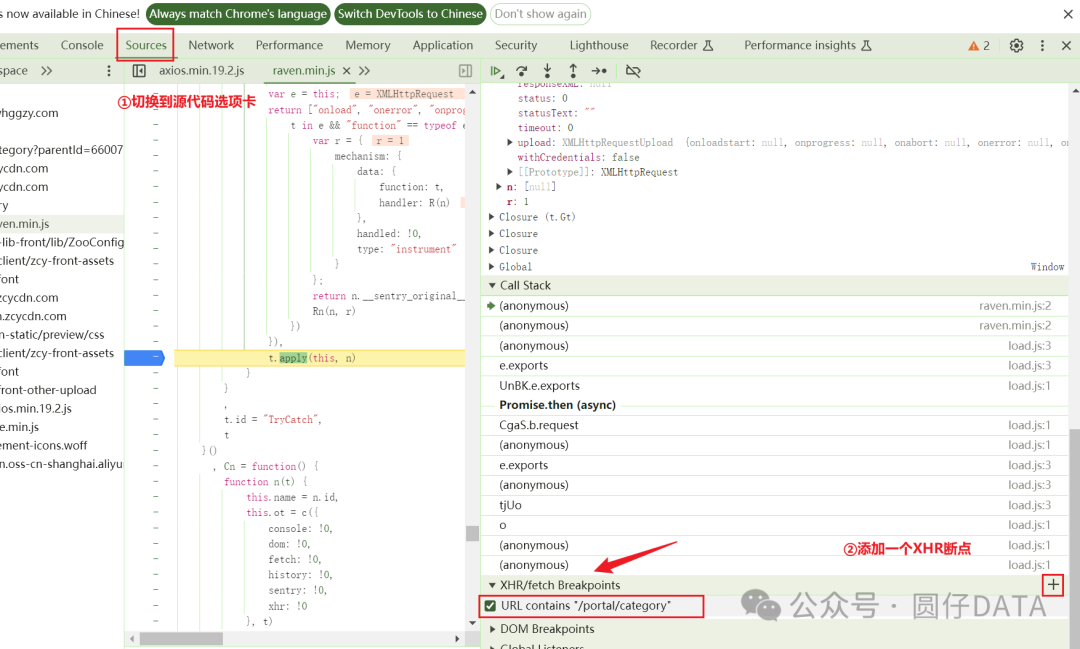
这里,我也调试下JS代码,练练手。请各位看官看看吧。
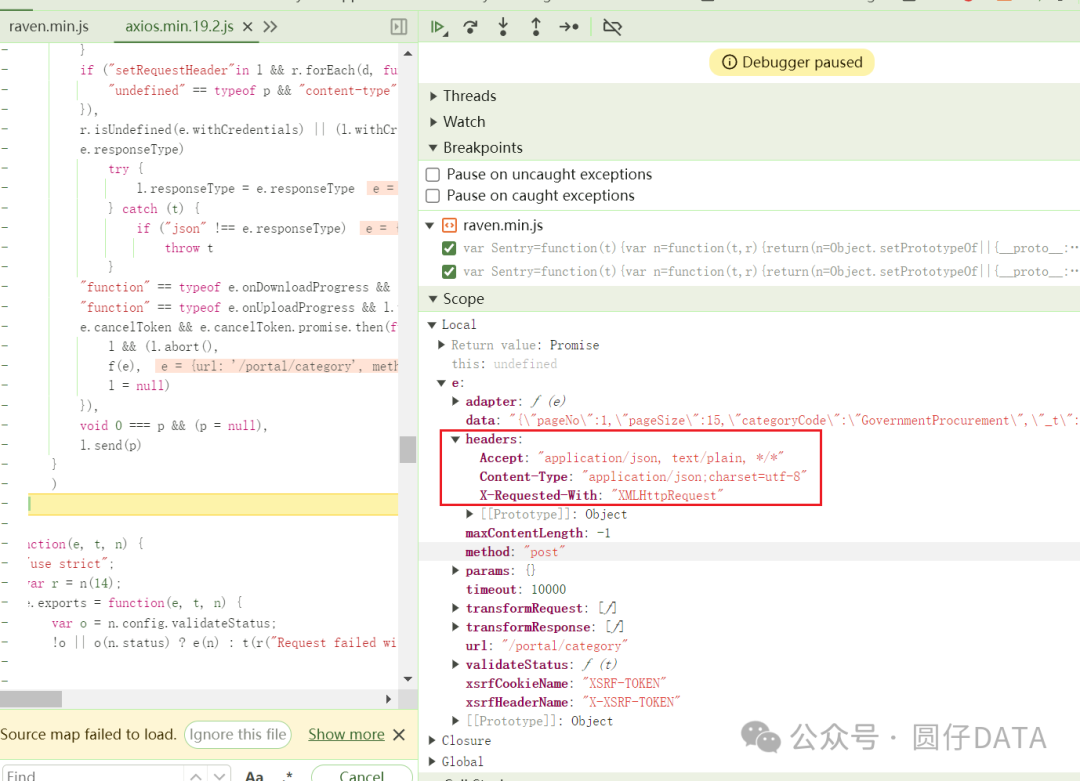
咱们按照JS调试中获得的headers参数,修改下爬虫代码试试看
-
搜索路径 /portal/category
-
添加XHR断点,刷新页面,单步调试,直到出现headers
也可以成功获得数据
这篇关于爬虫入狱笔记——xx政府网站公开政策数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





