本文主要是介绍DPTree: Differential Indexing for Persistent Memory(VLDB 2019),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
(一)研究目的
实现崩溃一致性,减少 PM 写入,并保持优秀的读性能。
(二)研究背景
根据结构特性,现有的 PM 索引研究大致可以分为B+Tree based、Trie-based 和 hybrid(混合) 三种类型。B+Tree based 结构(例如 CDDS-Tree、wB+Tree、NVTree、FPTree、FASTFAIR)在索引更新的关键代码路径上的持久化原语的数量是次优的。Trie-based 结构(例如 WORT)在某些键分布上获得了优异的写性能,但代价是范围扫描效率不佳。对于 hybrid 结构,其思想是将多个物理索引结构组合成一个逻辑索引。例如,HiKV 将哈希表与 B+Tree 相结合,但是 HiKV 的 DRAM 消耗和恢复成本较高。
现有 PM 索引结构经常执行许多高代价的持久化原语来维护其结构属性或更新元数据。例如,在 FASTFAIR 中,对叶节点的插入平均需要保持一半的缓存线,以保持节点有序和持久。FPTree 需要在每次更新时将指纹和位图持久化到叶子节点中。但是,只有插入的键值需要一次到 PM 的往返才能保持持久性。这种对 PM 的额外写入称为结构维护开销(structural maintenance overhead,SMO)。因此需要减少 SMO。
fencing 指令会耗尽 CPU 存储缓冲区并阻塞管道,因此需要减少 fencing 指令。 如果可以批量执行索引更新,那么持久性开销可以平摊。例如,可以将一批键值条目插入 PM 中的叶节点,对元数据只进行一次更新。
(三)研究概述
基于批量更新的思想,设计了一个两级持久索引,部分灵感来自于双级索引体系结构。第一级在 DRAM 中,称为缓冲树(buffer tree),第二级在 PM 中,称为基树(base tree)。写操作首先被快速而小的缓冲树吸收,缓冲树由写优化的 PM 重做日志支持,以保证持久性。当缓冲区树达到一个阈值时,利用 PM 的字节寻址能力就地将缓冲区树合并到基树中,然后将更改刷新到PM,而只需要很少的防护开销。通过这种方式,SMO 被分摊到一批更新中。此外,对基树进行了大量读取优化,以减少两级设计引入的搜索延迟。即持续地对 DRAM 中的多个写进行批处理,然后将它们合并到一个 PM 组件中,以摊销持久化开销。
(四)关键技术
Differential Persistent Tree
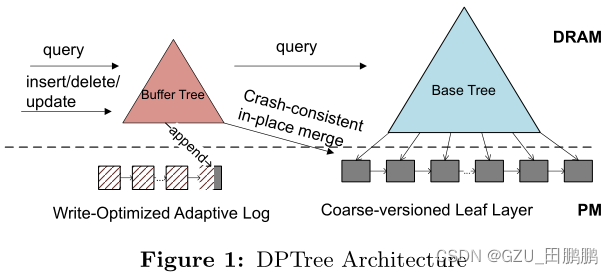
基于批量更新的思想,设计了一个两级持久索引。第一级在 DRAM 中,称为缓冲树(buffer tree),第二级在 PM 中,称为基树(base tree)。缓冲树设计了一种自适应写优化的日志记录方案,以保证持久性。基树是只读的,并采用了选择性持久性方案,内部节点在 DRAM 中,叶节点链表在 PM 中。
Buffer Tree
缓冲区树总是在恢复时重建,因此日志只存储逻辑上向上插入的键值条目,这使得基于页面的存储比传统的重做/撤消日志占用更少的存储空间。
Base Tree
在 DPTree 中,base tree 是只读的,只通过合并更新,因此在读取和合并方面对它进行了优化。为了利用 DRAM-PM 架构,在 base tree 中采用了选择性持久性方案,其中内部节点在 DRAM 中,而叶子节点在 PM 中。两个连续的叶是相对排序的,而叶本身可能无序,叶列表是粗粒度版本以保持持久性。(叶间有序,叶内无序)
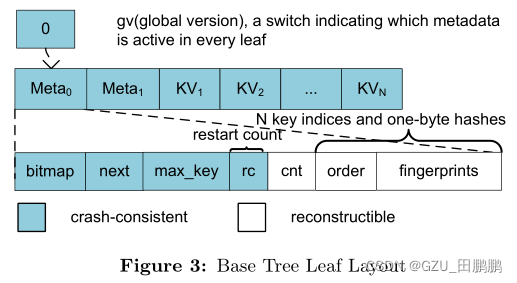
CDDS B-Tree 提出在每次写操作时对键值项进行版本化,以实现崩溃一致性,但这种细粒度的版本控制会带来巨大的开销。受版本控制技术的启发,本文观察到 base tree 合并前和合并后图像提供了一个自然的版本控制边界。于此提出了粗粒度版本控制技术。每个叶节点中维护两组元数据和一个键值槽池,如图3所示。每个元数据由一个位图、一个 next 指针、节点中的最大键、节点中键值的数量、一个 order 数组和 fingerprints 数组组成。位图跟踪键值槽的分配状态。order 数组存储有序的键值槽的索引(类似于 wB+Tree)以加速范围扫描。键值池是由哈希组织的,冲突是使用线性探测解决。指纹数组保存存储在键值池对应位置的键的一个字节哈希值,它的作用是过滤掉不必要的 PM 读。
Crash Consistent Merging
因为基树是在 PM 中,所以合并需要保持崩溃一致性。直接将 buffer tree 和 base tree 合并成一棵新的 base tree 会导致高写放大(high write amplification)。本文通过利用 PM 的字节可寻址性,将 buffer tree 原地合并到 base tree 来减少写操作。为了在合并期间保持崩溃一致性,利用了粗粒度版本控制技术,并遵循一个简单的原则:永远不要修改由全局版本号 gv 表示的当前版本的数据。
并发 DPTree
DPTree 的并发方案可以分为三个部分:并发持久缓冲树(CPBT)、并行合并和树组件之间的同步。
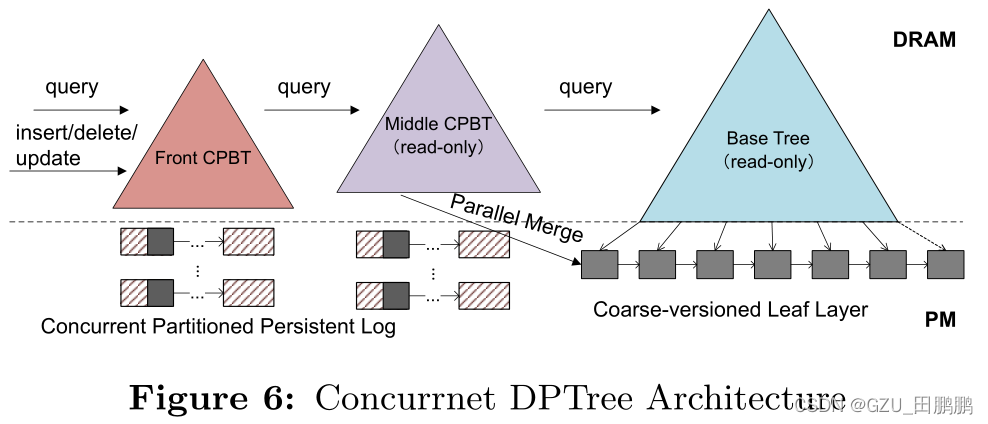
图 6 显示了并发 DPTree 的体系结构。并发写由 Front CPBT 处理。Front CPBT 满时,变成只读,命名为 Middle CPBT。一个新的 CPBT 被创建为 Front CPBT,以服务于新的写操作。然后在后台将 base tree 与 Middle CPBT 并行合并。读取顺序为 Front CPBT,Middle CPBT(如果有的话),最后是 base tree。当在这三个组件中的任何一个中找到匹配的键时,读取就结束了。
(五)实验

(六)总结
本文提出了一种新的 DPTree 索引结构,设计用于 DRAM-PM 混合系统。DPTree 采用了一些新技术,比如刷新优化的持久日志记录、粗粒度版本控制、基于散列的节点设计,以及为 PM 量身定制的与崩溃一致的原地合并算法。因此,DPTree 大大减少了缓存行大小的键值对有效负载的刷新开销。乐观锁耦合B+树、粗版本和就地合并的组合使 DPTree 在多核环境中具有并发性和可伸缩性。
这篇关于DPTree: Differential Indexing for Persistent Memory(VLDB 2019)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!
![BUUCTF靶场[web][极客大挑战 2019]Http、[HCTF 2018]admin](https://i-blog.csdnimg.cn/direct/ed45c0efd0ac40c68b2c1bc7b6d90ebc.png)


![最简单的使用JDBC[连接数据库] mysql 2019年3月18日](https://i-blog.csdnimg.cn/blog_migrate/d10b0c37d5115bce2197b87d8034b833.png)


![(php伪随机数生成)[GWCTF 2019]枯燥的抽奖](https://i-blog.csdnimg.cn/direct/4cedb561c99944399713d7d7d7a37c7c.png)