本文主要是介绍【Ambari】Ansible自动化部署大数据集群,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

目录
一.版本说明和介绍信息
1.1 大数据组件版本
1.2 Apache Components
1.3 Databases支持版本
二.安装包上传和说明
三.服务器基础环境配置
3.1global配置修改
3.2主机名映射配置
3.3免密用户名密码配置
3.4 ansible安装
四. 安装Ambari-server
4.1 安装ambari-server
4.2 检查REPO源
五、HDP 安装
Get Started
Select Version
Install Options
Confirm Hosts
Choose Services
Assign Masters
Assign Slaves and Clients
Customize Services
CREDENTIALS
DATABASES
DIRECTORIES
ACCOUNTS
ALL CONFIGURATIONS
Review
六、开启Kerberos
6.1 kerberos服务检查
6.2 Ambari启动kerberos
Get Started
Configure Kerberos
Install and Test Kerberos Client
Configure Identities
Confirm Configuration
Stop Services
Kerberize Cluster
Start and Test Services
七、开启服务高可用
7.1 HBaseMaster高可用开启
7.2 ResourceManager高可用开启
7.3 NameNode高可用开启
八、ranger权限开启
8.1 ranger登录
8.2 HDFS权限控制
8.3 HBase权限控制
8.4 Hive权限控制
8.5 Yarn权限控制
九、ansible自动化安装脚本
一.版本说明和介绍信息
1.1 大数据组件版本
| 组件 | 版本 |
| os | CentOS7.2-7.9 |
| ambari | 2.7.4 |
| HDP | 3.3.1.0 |
| HDP-GPL | 3.3.1.0 |
| HDP-UTILS | 1.1.0.22 |
| JDK | jdk-8u162-linux-x64.tar.gz |
| MySQL | 5.7 |
1.2 Apache Components
| 组件名称 | Apache版本 |
| Apache Ambari | 2.7.4 |
| Apache Zookeeper | 3.4.6 |
| Apache Hadoop | 3.1.1 |
| Apache Hive | 3.1.0 |
| Apache HBase | 2.0.2 |
| Apache Ranger | 1.2.0.3.1 |
| Apache Spark 2 | 2.3.0 |
| Apache TEZ | 0.9.1 |
1.3 Databases支持版本
| Name | Version |
| PostgreSQL | 10.7 10.5 10.2 9.6 |
| MySQL | 5.7 |
| MariaDB | 10.2 |
| 人大金仓 | V8 |
二.安装包上传和说明
使用工具将安装包上传到Linux服务器(安装ansible),上传到/opt 目录,如下命令进入/opt目录并解压安装包,包名日期可能有所变动,解压完成需要等待5分钟左右。如下操作使用root用户完成。脚本在博客资源中可以下载,文章后面会有部分说明。
tar -zxvf windp-deploy-2.7.4_20240329.tar.gz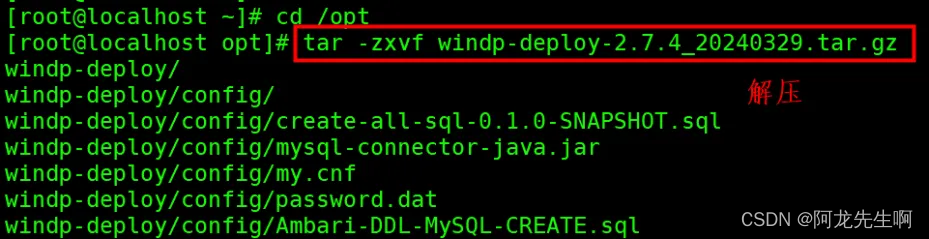
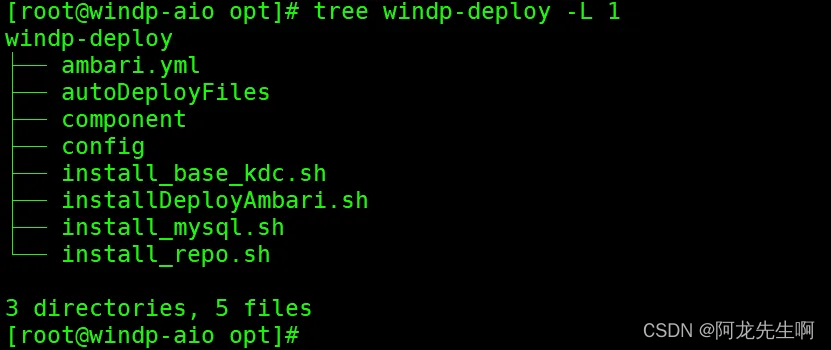
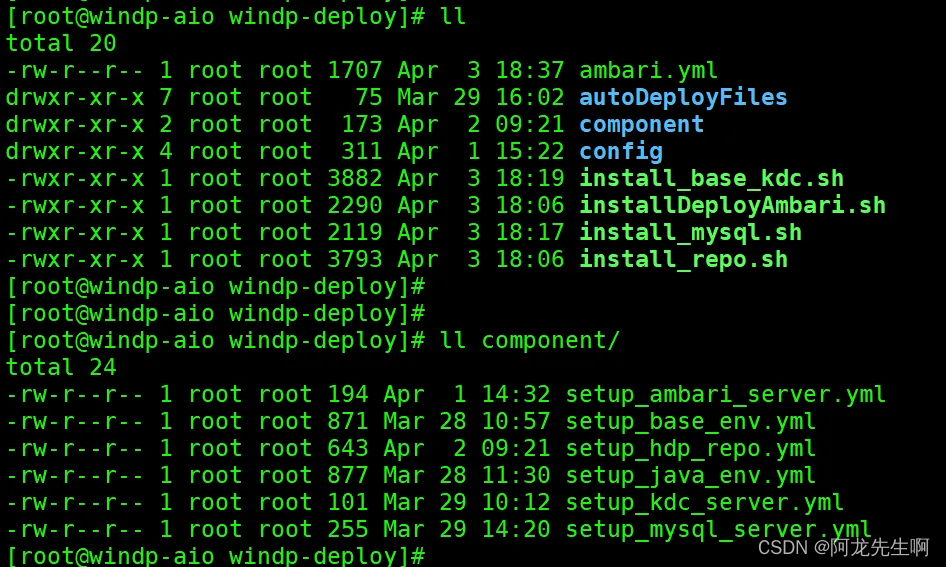
安装包解压后目录结构:
cd /opt/windp-deploy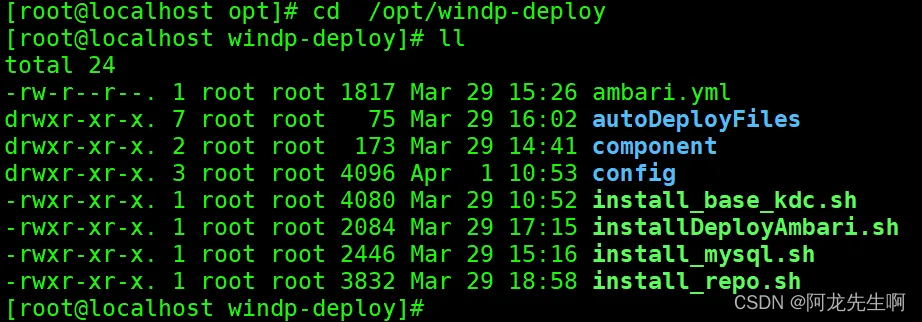
windp-deploy-dxxxxxxxx.tar.gz 包内容说明
| 脚本和目录 | 说明 |
| ambari.yml | ansible play-book 入口 |
| component | 配置文件和安装包 |
| install_base_kdc.sh | 配置KDC |
| install_mysql.sh | MySQL安装 |
| install_repo.sh | HDP源配置和Ambari安装 |
| config | 配置文件目录 |
| installDeployAmbari.sh | 安装启动脚本 |
三.服务器基础环境配置
3.1global配置修改
/opt为安装目录,默认无需修改。修改完成后复制如下命令在Linux服务器命令行执行后回车:
cat > /opt/windp-deploy/config/global.sh << EOF
#######################
#部署相关全局参数定义
#######################
# mysql配置
myurl=localhost
myuser=root
mypwd=Winner001
myport=3306
# HDP包解压目录
install_path=/hadoop
# mysql 安装目录
mysql_install_path=/usr/localEOF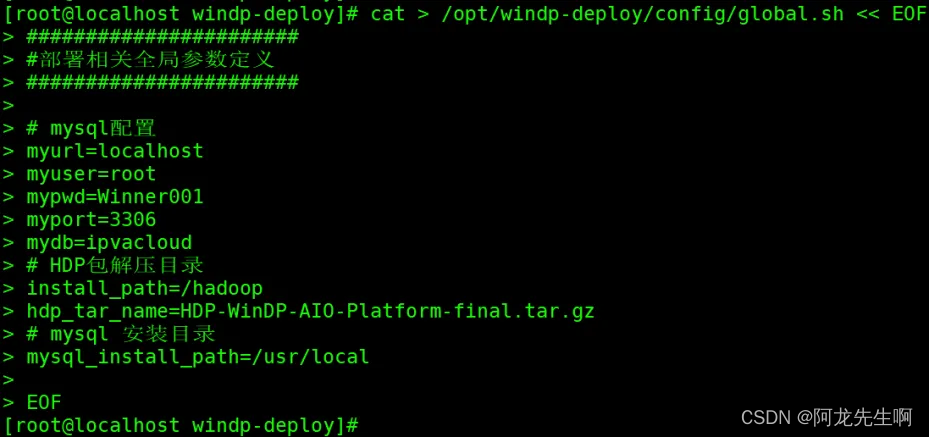
执行如下命令,检查文件是否保存成功。
cat /opt/windp-deploy/config/global.sh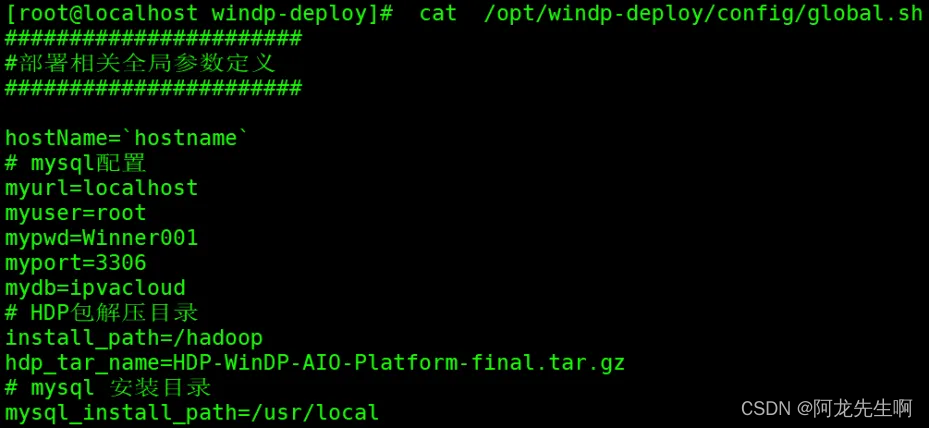
3.2主机名映射配置
如下为主机hosts映射本地临时文件,修改好后执行如下命令(修改部分已标红),
cat > /opt/windp-deploy/autoDeployFiles/scripts/temphosts.txt << EOF
192.168.2.142 hdp-node1
192.168.2.143 hdp-node2
EOF
执行如下命令,查看hosts是否配置成功。
cat /opt/windp-deploy/autoDeployFiles/scripts/temphosts.txt 
3.3免密用户名密码配置
如下为主机名和密码临时文件,修改好后执行如下命令(修改部分已标红),
cat > /opt/windp-deploy/autoDeployFiles/scripts/hostlist.txt << EOF
hdp-node1 winner@001
hdp-node2 winner@001
EOF执行如下命令,查看是否配置成功。
cat /opt/windp-deploy/autoDeployFiles/scripts/hostlist.txt
3.4 ansible安装
执行如下命令,查看ansible是否安装,如若显示版本信息则已安装,则跳过此步骤。如若没有显示版本信息,则执行下面的安装命令。
ansible --version
如果没有安装执行如下命令:
yum install epel-release -y
yum install ansible -y再执行查看ansible版本信息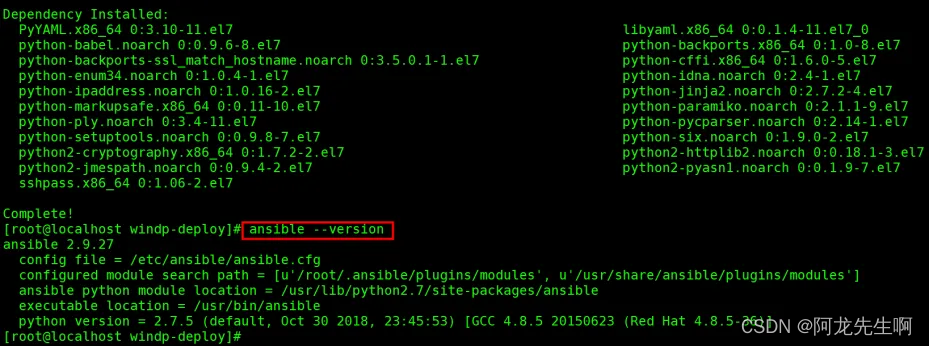
也可以选择离线安装,执行如下命令:
cd /opt/windp-deploy/config/ansible-rpm
yum install *.rpm -y四. 安装Ambari-server
4.1 安装ambari-server
执行如下命令,等待Ambari-Server 配置启动完成,需要等待20分钟左右。
cd /opt/windp-deploy/
sh installDeployAmbari.sh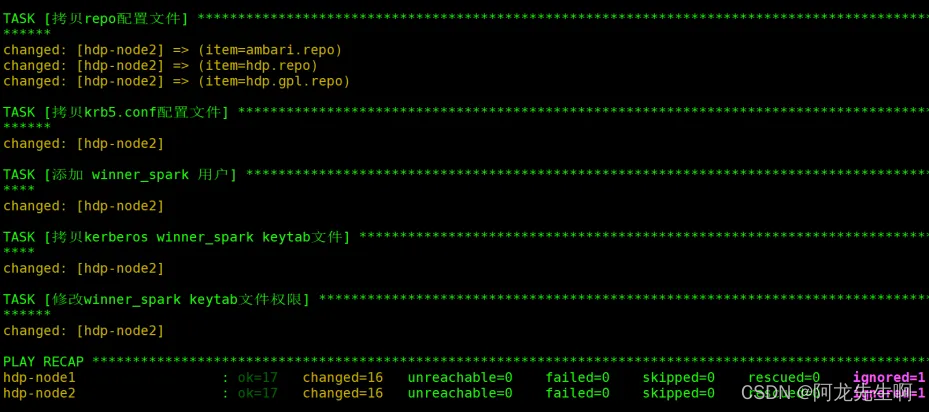
执行如下命令,查看mysql是否启动成功,显示如图“running”则表示启动成功。
/etc/init.d/mysqld status
执行如下命令,查看Ambari-Server是否启动成功,显示如图“running”则表示启动成功。
ambari-server status
如果Ambari-Server没有启动成功,执行如下命令尝试重启。
ambari-server restart4.2 检查REPO源
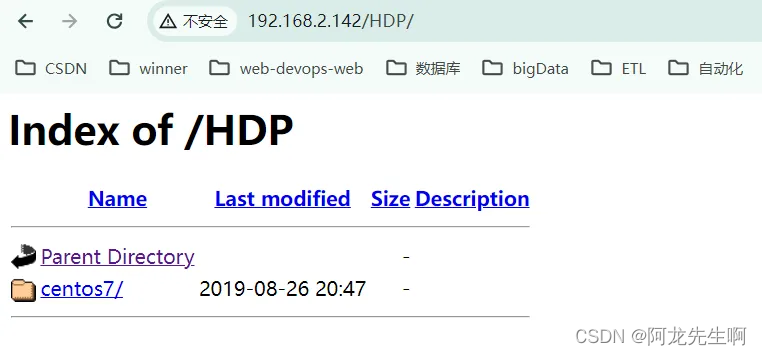
配置的REPO源可以在浏览器中查看。需要将示例IP地址换成部署WinDP Linux本机的IP。如下是示例IP地址:
http://192.168.2.142/ambari/
http://192.168.2.142/HDP/
http://192.168.2.142/HDP-UTILS/
http://192.168.2.142/HDP-GPL/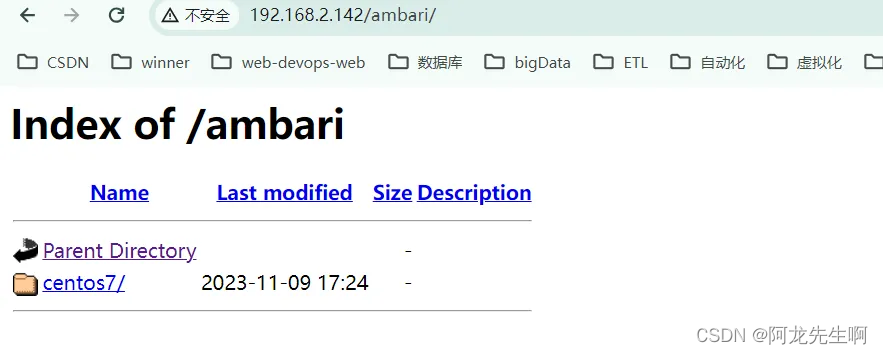
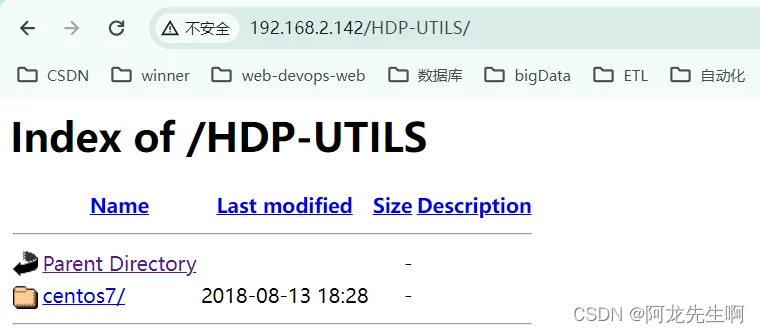
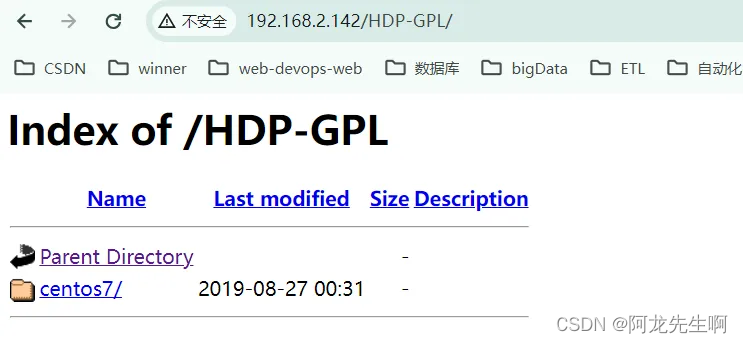 注意:如果某个地址从浏览器访问失败则说明配置的基础环境有问题,需要检查基础环境的配置。
注意:如果某个地址从浏览器访问失败则说明配置的基础环境有问题,需要检查基础环境的配置。
五、HDP 安装
登录Ambari-Server, 地址为IP:8080,示例地址:http://192.168.2.161:8080/,账号密码默认:admin。
第一次登录进去的默认界面如下图所示,点击红框按钮。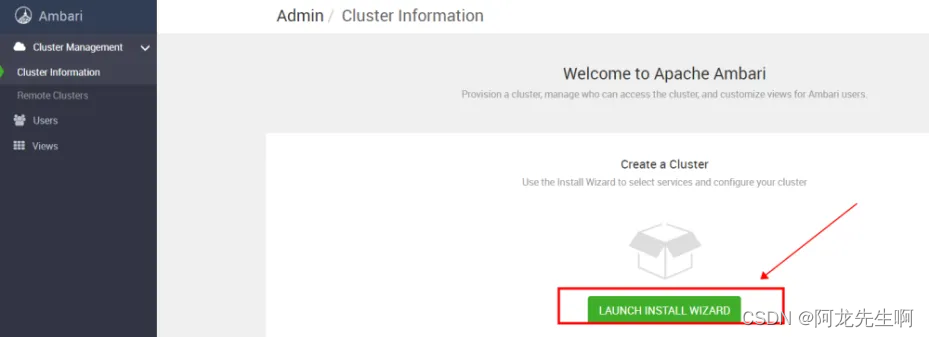
Get Started
输入集群名称 “winner”,点击NEXT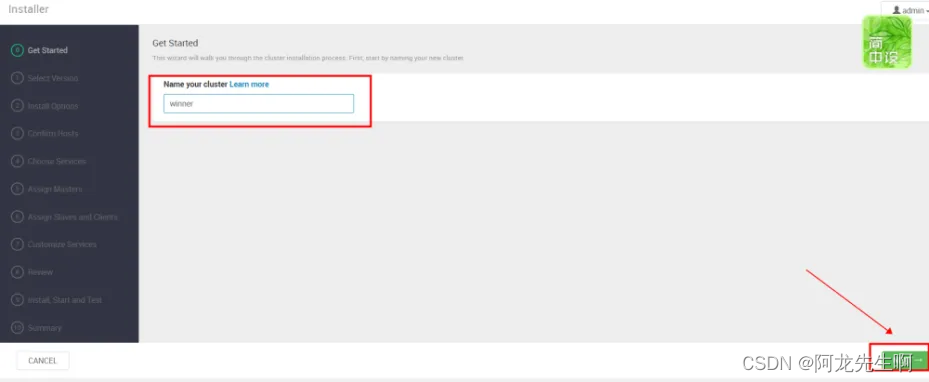
Select Version
选择HDP的版本,这里使用的是3.1版本,repo选择“Use Local Repository”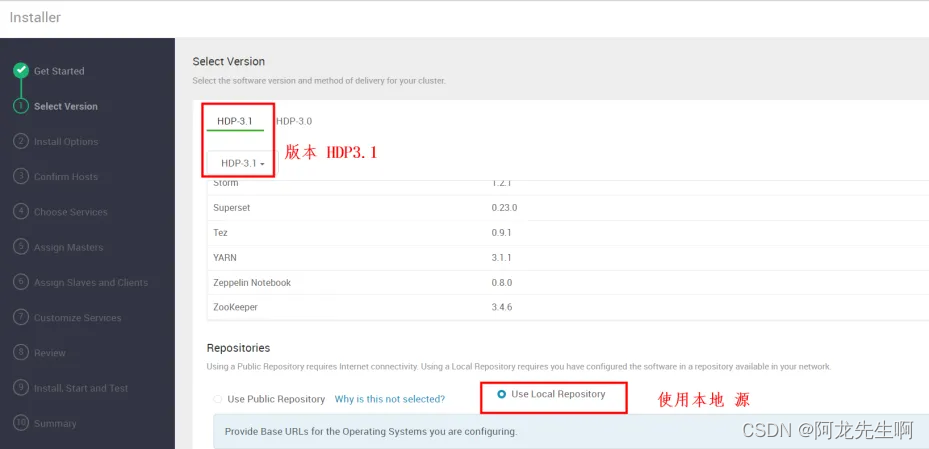
保留redhat7的地址 栏,其它系统选择“Remove”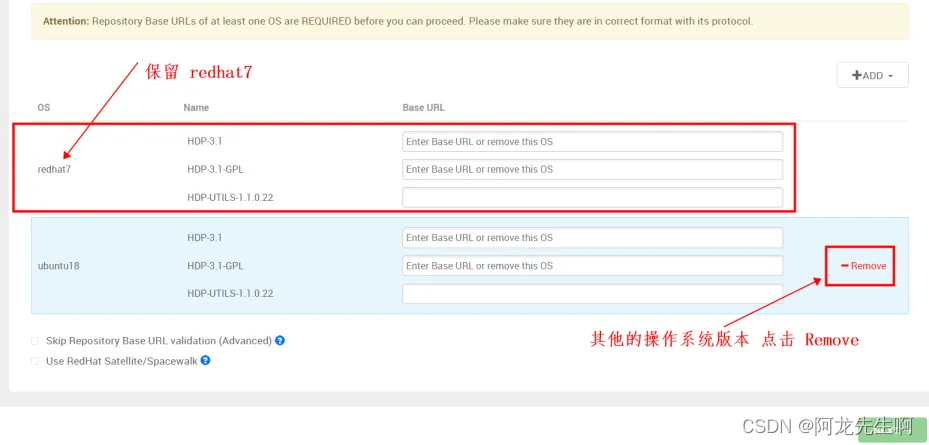
主机名需要修改,然后将如下URL 依次复制到Base URL 地址栏中,然后下一步
http://hdp-node1/HDP/centos7/3.1.4.0-315
http://hdp-node1/HDP-GPL/centos7/3.1.4.0-315
http://hdp-node1/HDP-UTILS/centos7/1.1.0.22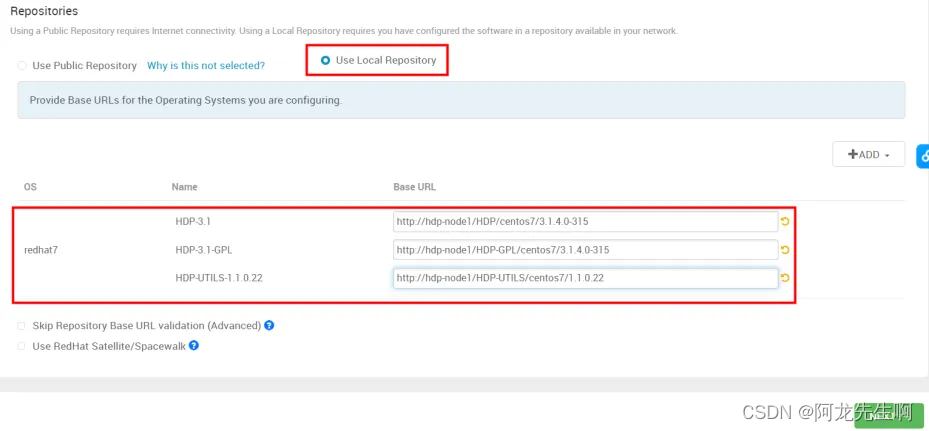 Install Options
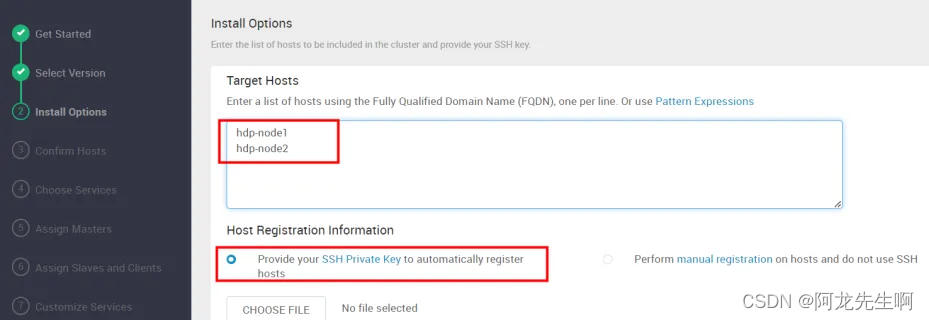
Install Options
- Target Hosts :
hdp-node1
hdp-node2
- Host Registration Information: 选择红框Provide your SSH Private Key to automatically register hosts
在Linux服务器上执行如下命令将私钥下载到Windows本地
sz /root/.ssh/id_rsa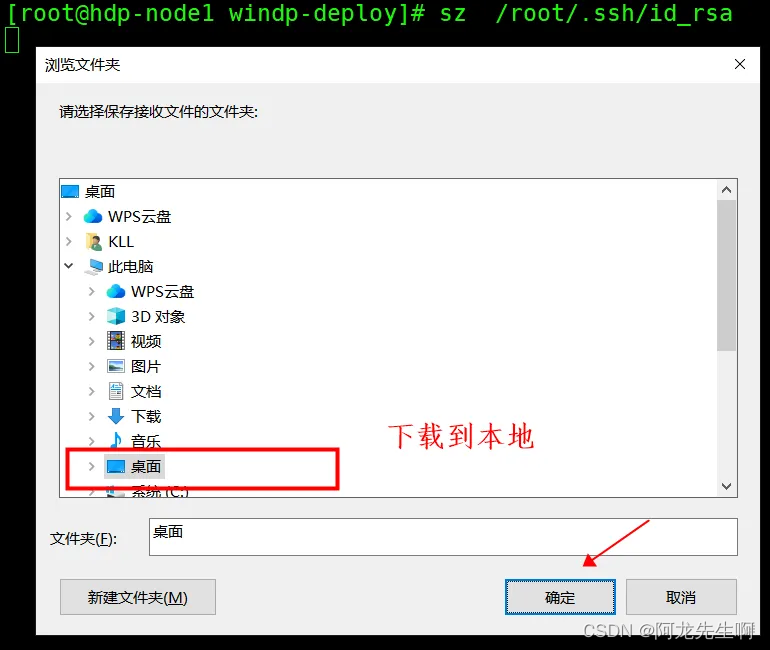 将下载的私钥文件从本地上传,点击选择“CHOOSE FILE”,选中“id_rsa”文件后选择打开。
将下载的私钥文件从本地上传,点击选择“CHOOSE FILE”,选中“id_rsa”文件后选择打开。
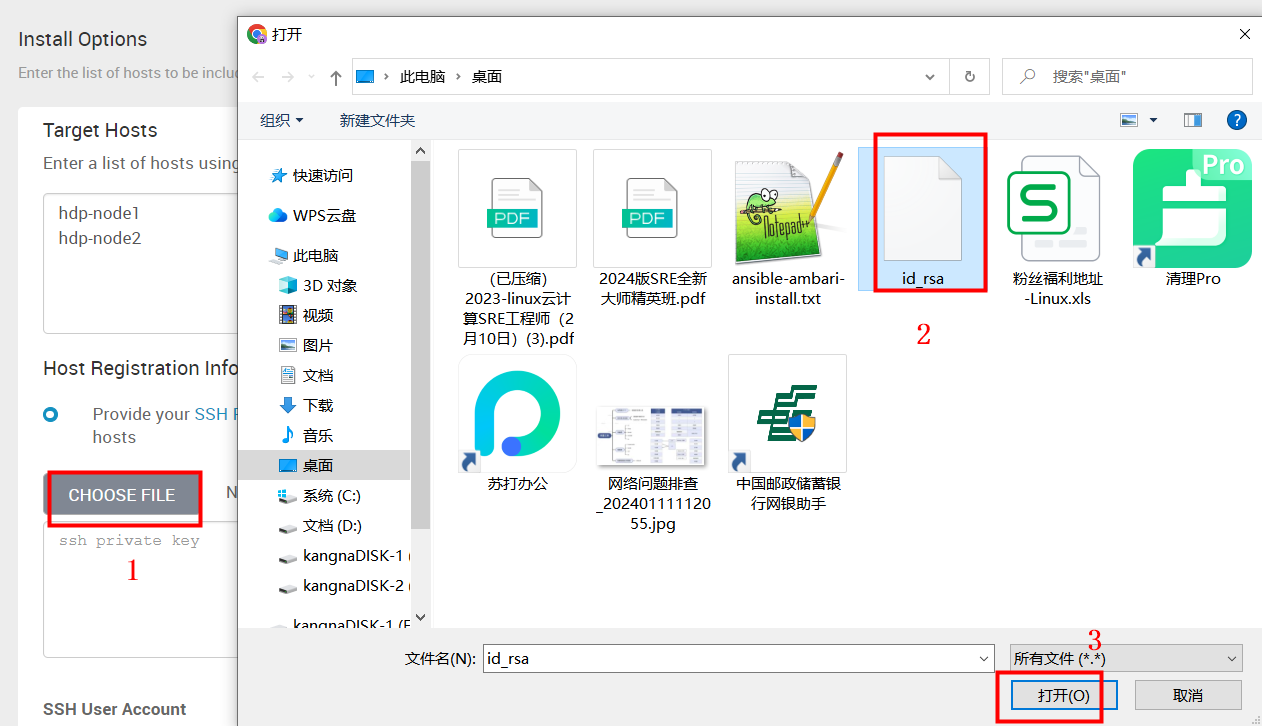
如下图私钥文件上传完成,ssh的用户和端口采用默认root,我们选择下一步
- SSH User Account: root
- SSH Port Number: 22
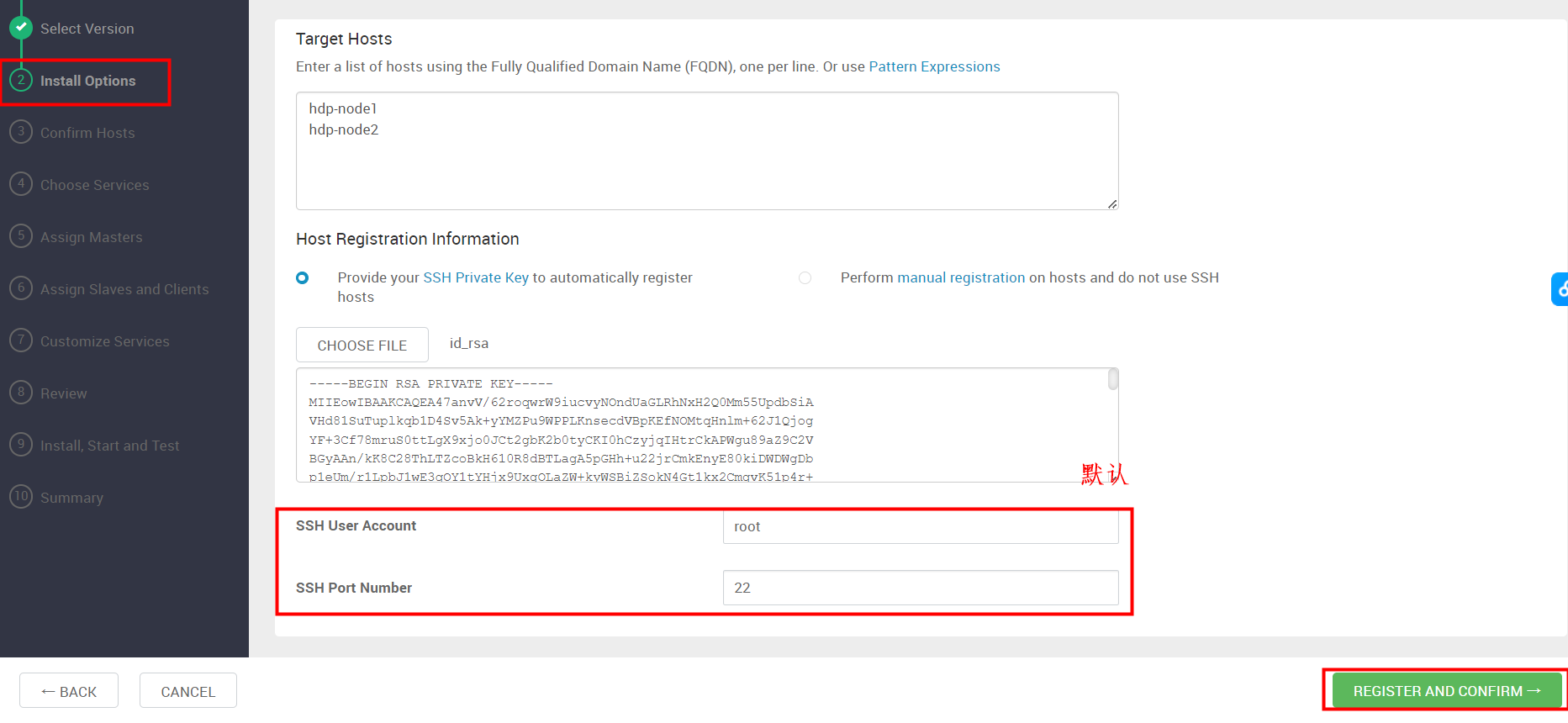
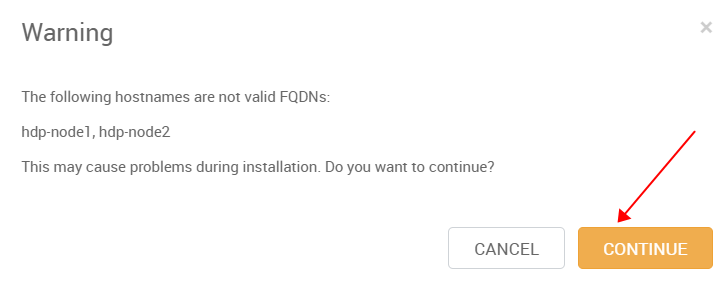
弹出Warning(一般是主机名不符合规范),可以忽略。
Confirm Hosts
等待服务器注册,如下的 check信息要检查通过才行,可能会检查出问题,需要解决后然后下一步。
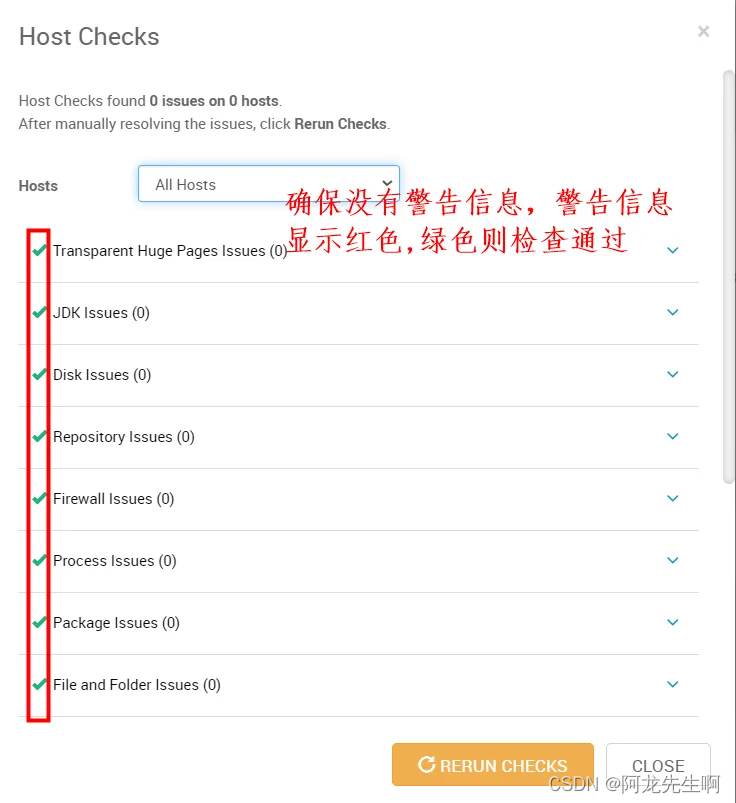
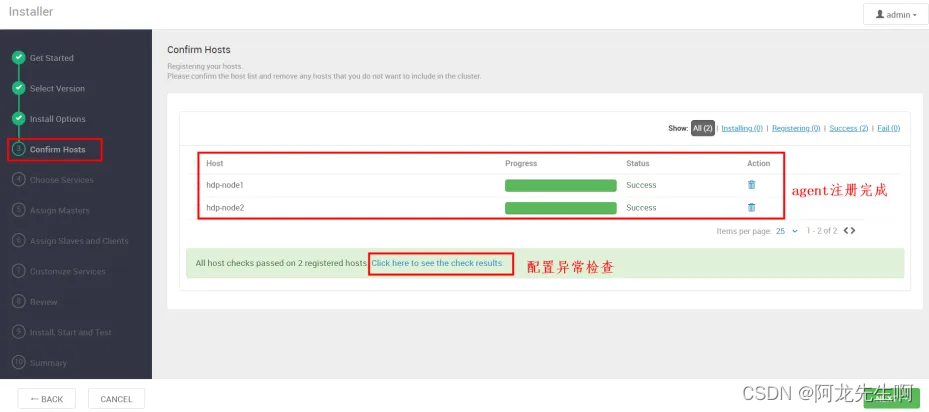 点击进入 “ Click here to see the check results.” 可以检查主机检查项是否通过
点击进入 “ Click here to see the check results.” 可以检查主机检查项是否通过
,如果有问题说明基础环境配置有问题,如果没有问题,选择“CLOSE”,下一步
Choose Services
选择要安装的组件: HDFS、YARN + MapReduce2、Tez、Hive、HBase、ZooKeeper、Infra Solr、Ambari Metrics、Ranger、Spark2, 默认就是勾选的,选择完成后下一步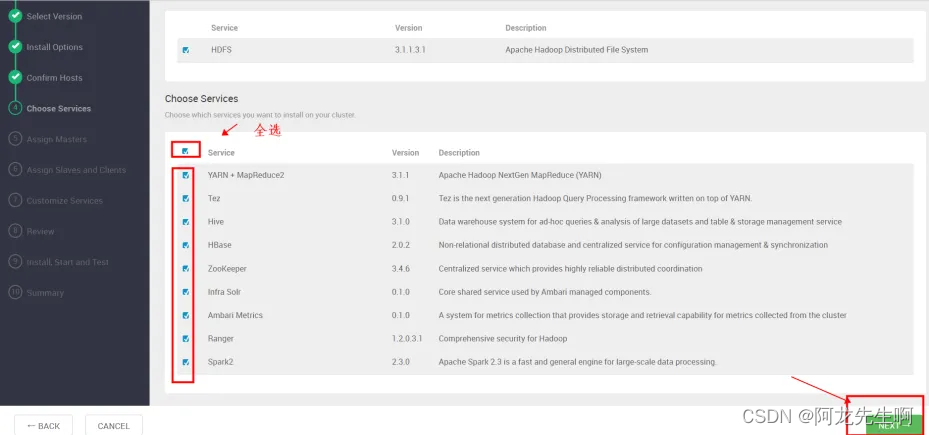
如果有Warning 直接忽略安装

Assign Masters
这一步我们根据服务器资源合理规划服务,不能将很多服务放在一台服务器,也要将高可用服务分配在不用的服务器上。
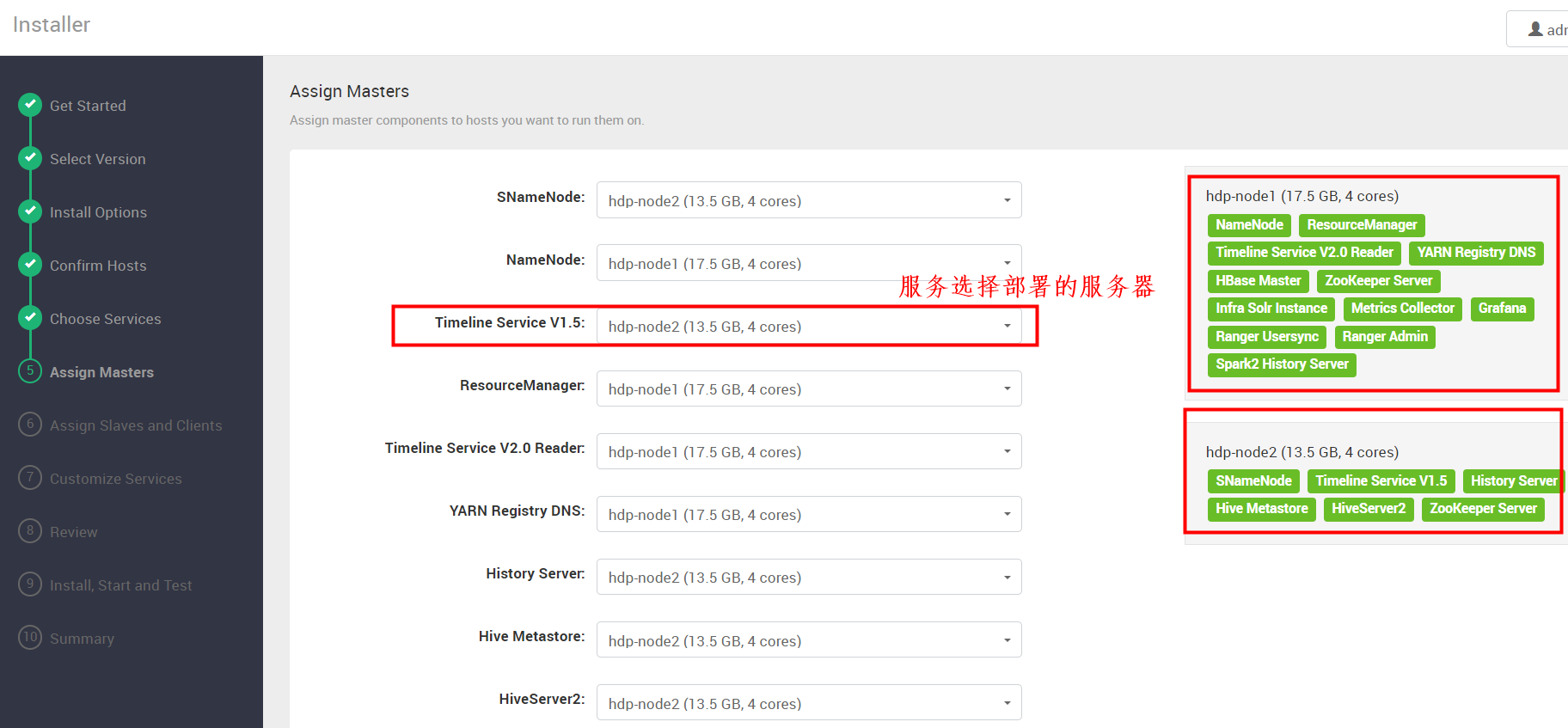
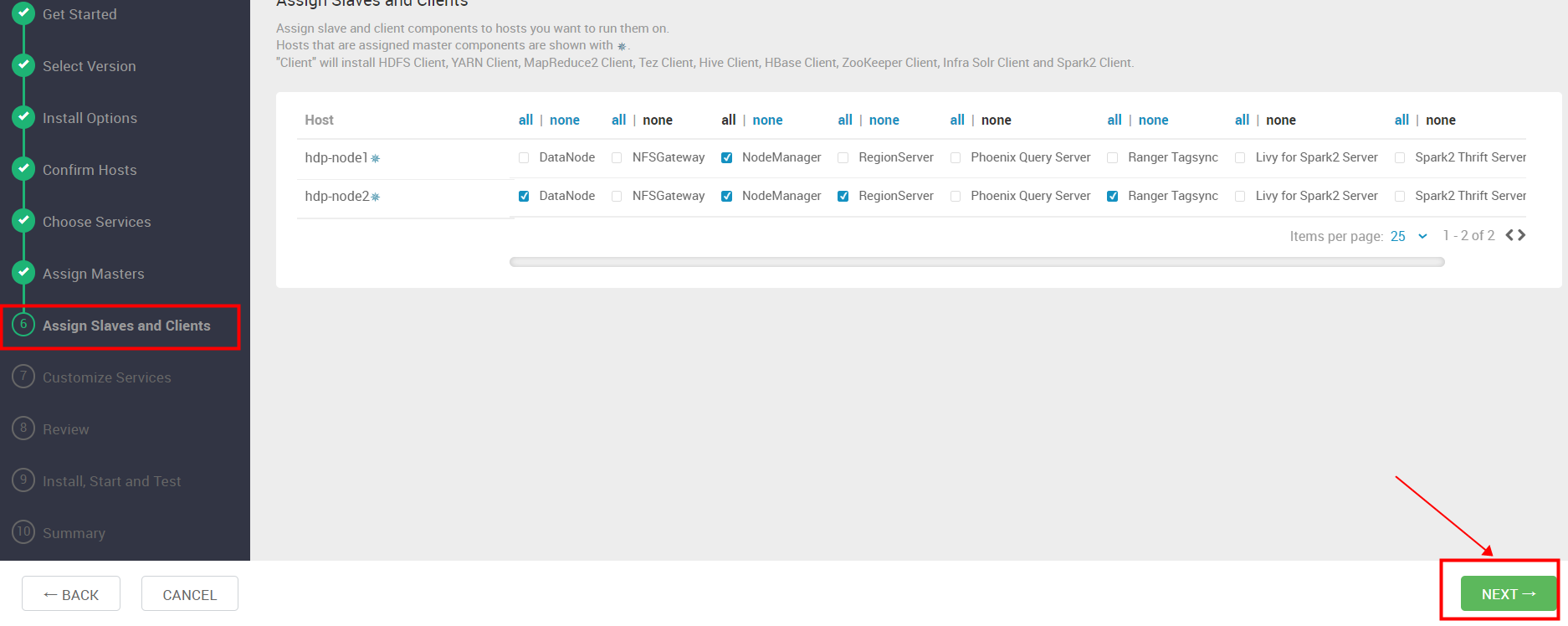
Assign Slaves and Clients
选择服务器上安装客户端和服务组件,默认已选择,下一步
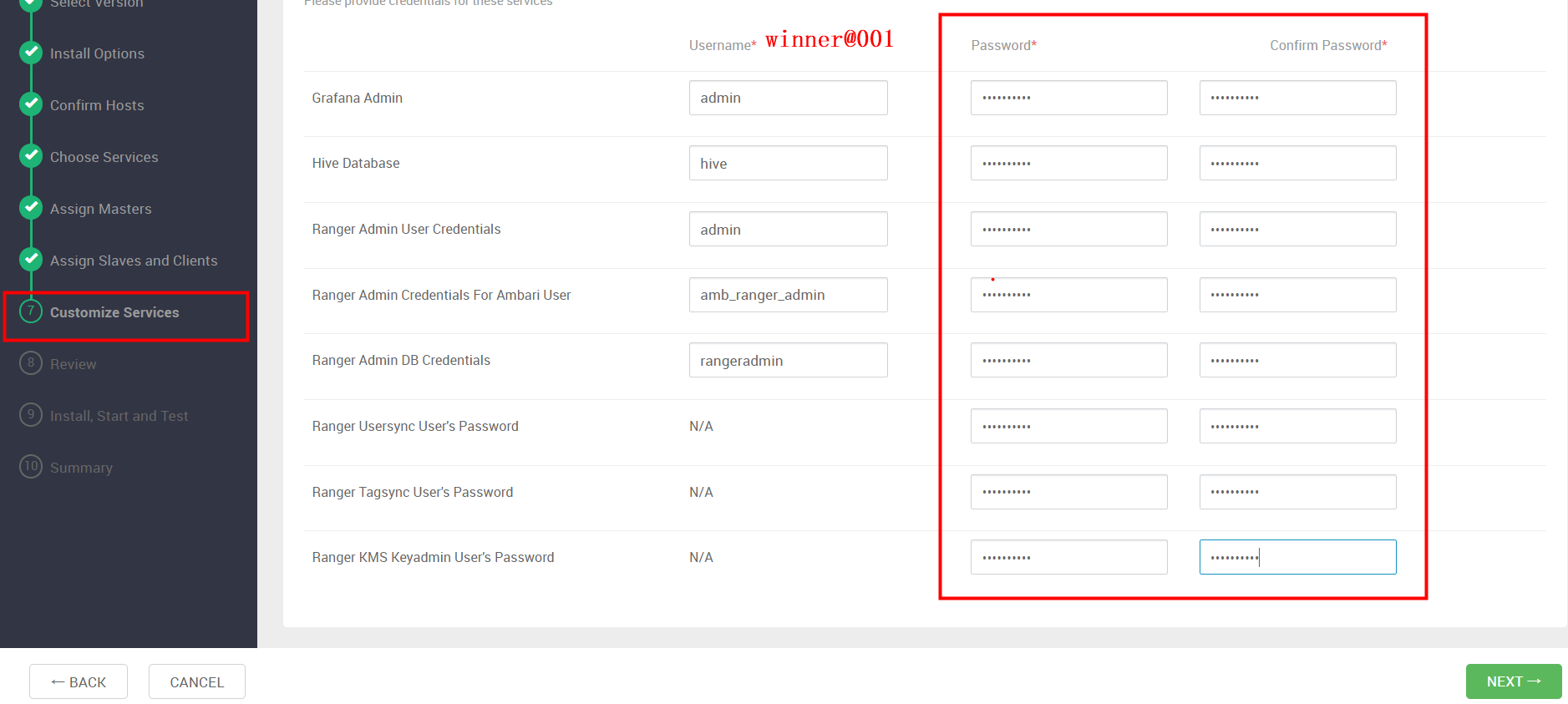
Customize Services
CREDENTIALS
配置WEB登录密码, 我们统一使用 “winner@001”,密码复制到所有的“password”框中,密码已存在的框采用覆盖。完成后下一步
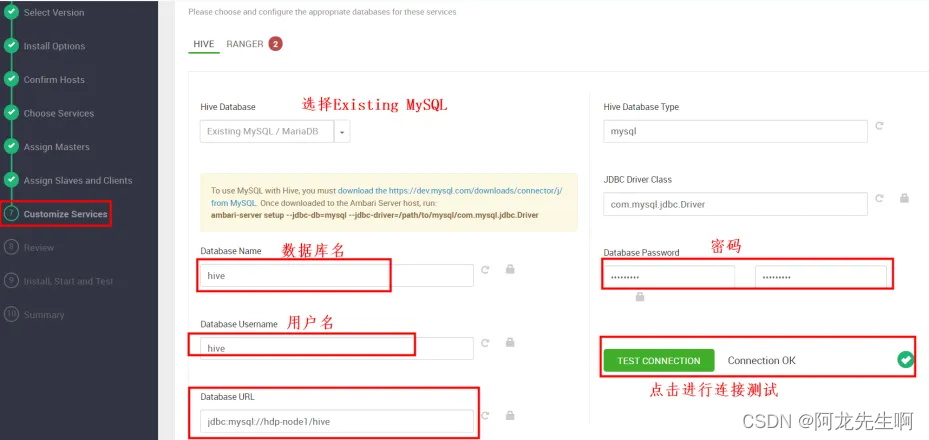
DATABASES
点击选择database,配置hive数据库,确保测试通过,Hive Database 选择 Existing MySQL / MariaDB
- DatabaseName: hive
- Uesr: hive
- Database Password: Winner001
- DatabaseURL: jdbc:mysql://hdp-node1/hive
 注意:测试连接不通过可以按照提示, 命令行手动设置驱动包的位置,执行如下命令后尝试再次测试连接:
注意:测试连接不通过可以按照提示, 命令行手动设置驱动包的位置,执行如下命令后尝试再次测试连接:
ambari-server setup --jdbc-db=mysql --jdbc-driver=/usr/share/java/mysql-connector-java.jar
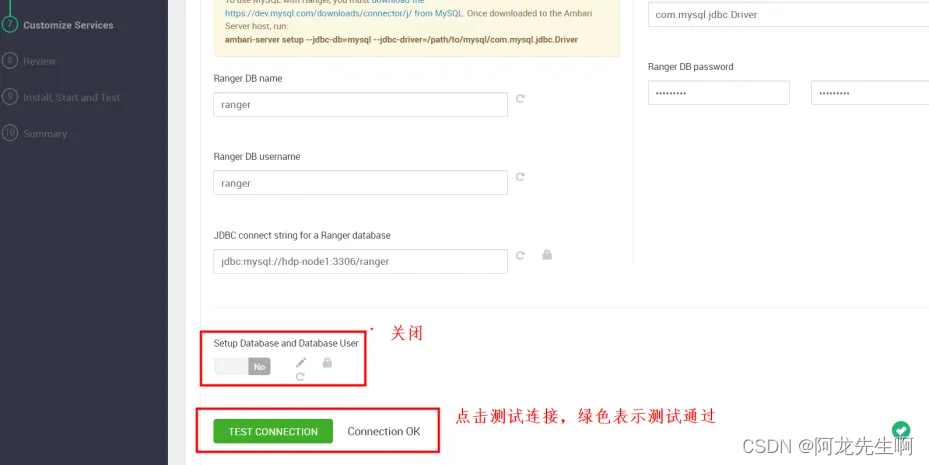
点击选中 “RANGER”,进行ranger数据库配置,确保测试通过
- DatabaseName: ranger
- Uesr: ranger
- Database Password: Winner001
- DatabaseURL: jdbc:mysql://hdp-node1:3306/ranger
- Ranger DB host:hdp-node1

 设置完成后,下一步
设置完成后,下一步
DIRECTORIES
一般存储数据和日志路径要配置为数据盘目录,需要提前规划挂载数据盘。
如下是HDFS服务: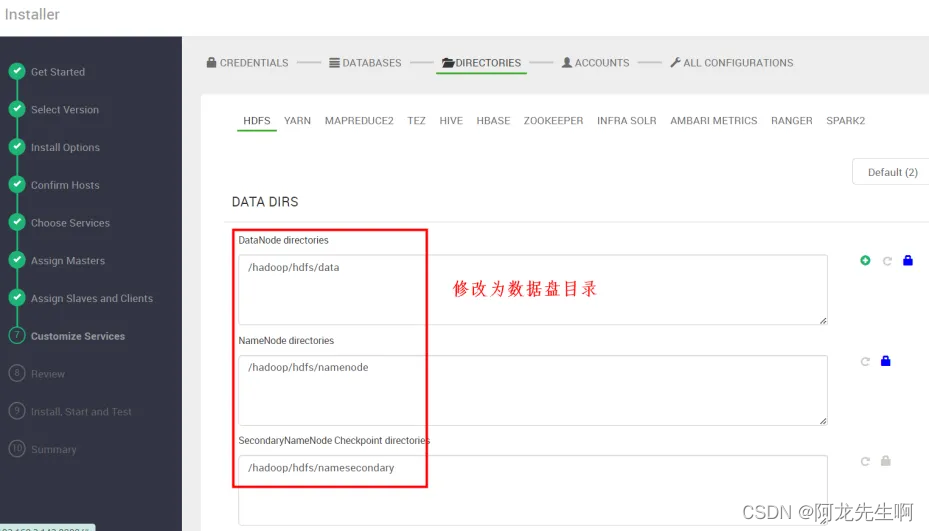
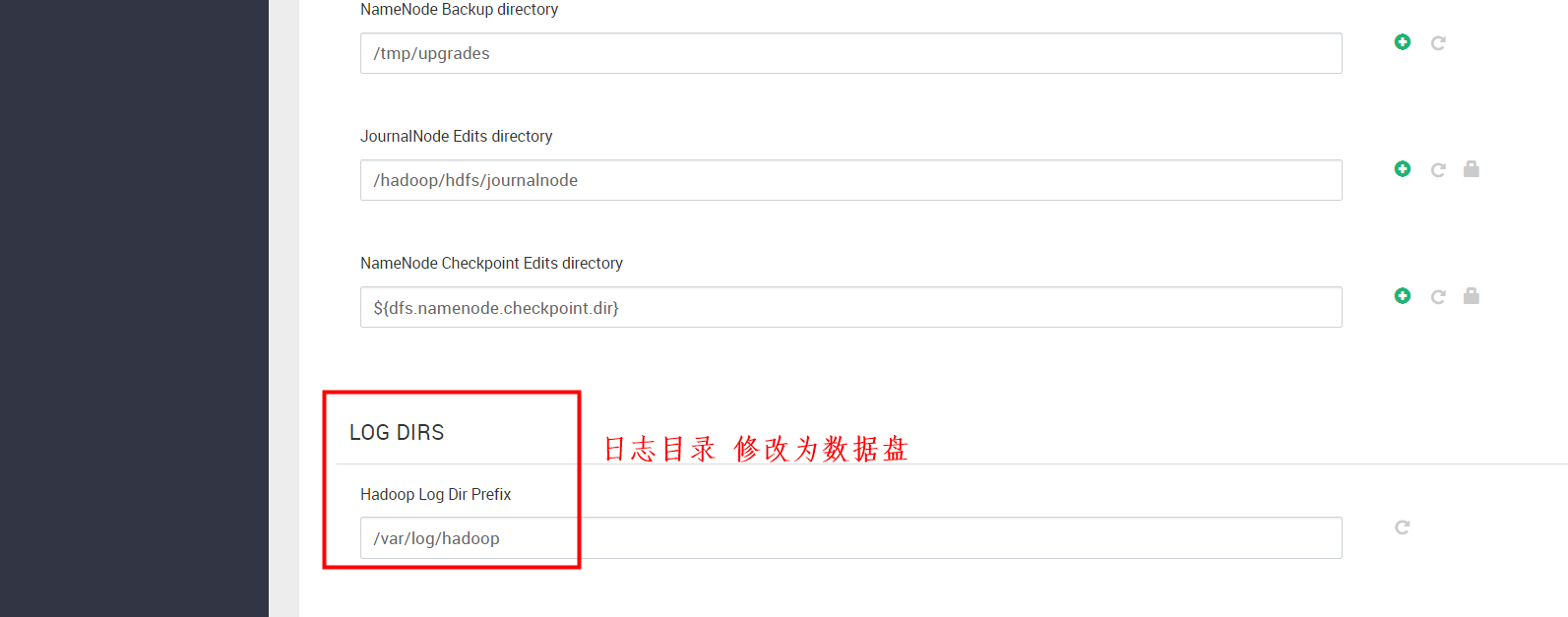
HDFS、YARN 、 MapReduce2、Tez、Hive、HBase、ZooKeeper、Infra Solr、Ambari Metrics、Ranger、Spark2 等日志的路径都要修改。修改完成后下一步。
ACCOUNTS
账号信息确定,使用默认配置,直接下一步
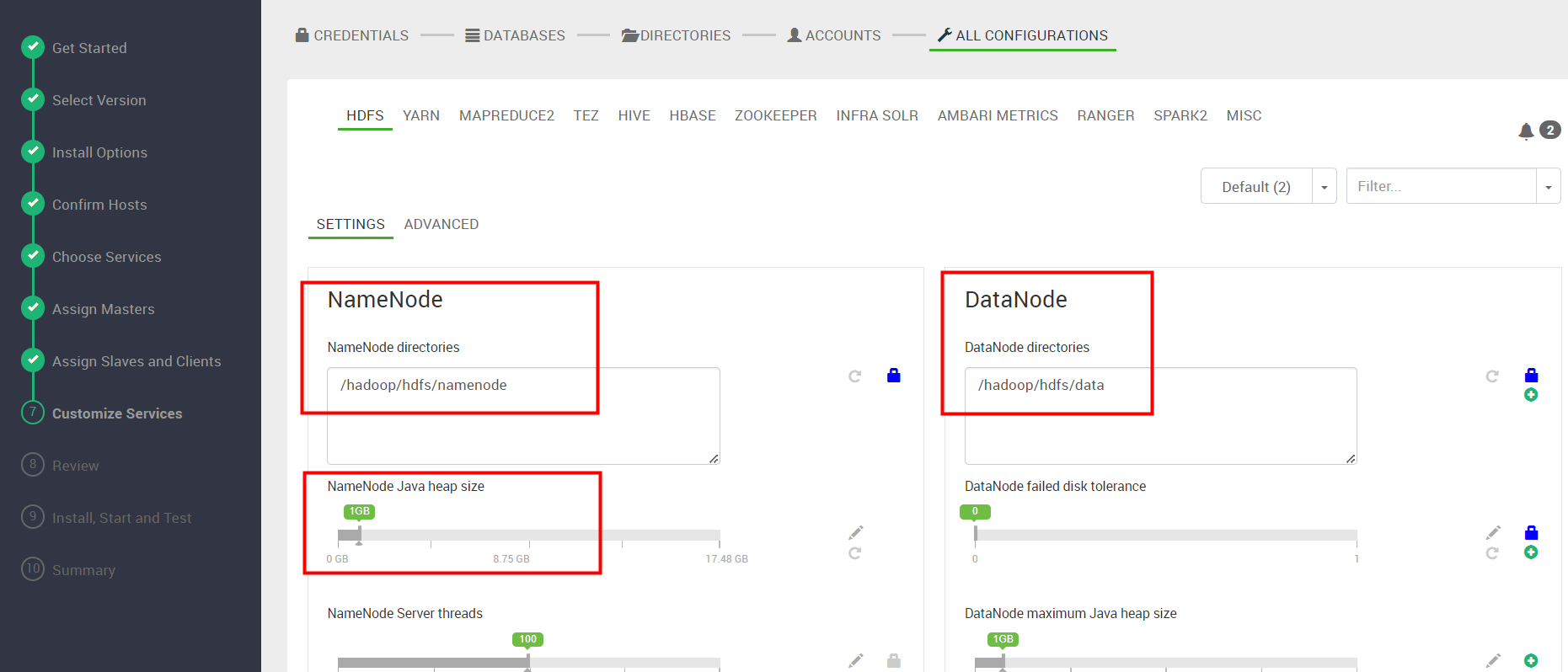
ALL CONFIGURATIONS
组件参数修改,根据资源大小自行修改,像NameNode ,HBase Master默认都是1G ,根据生产环境资源情况自行修改,我们采用默认,下一步。
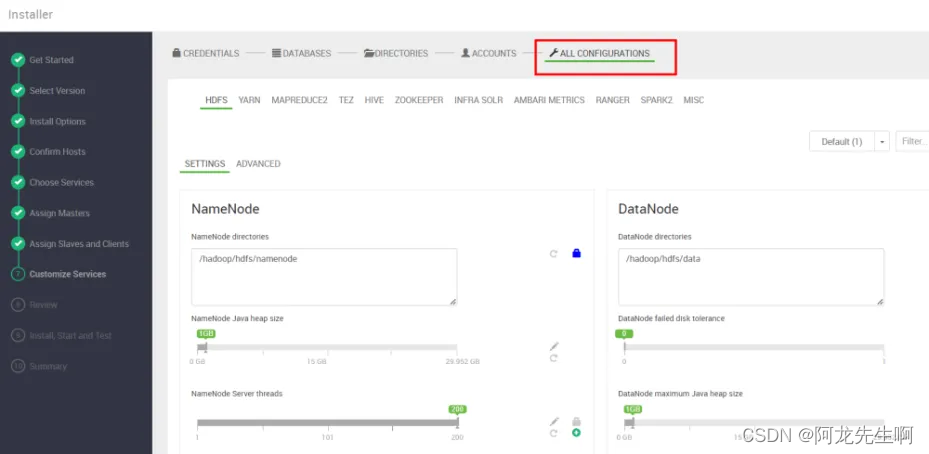
此步骤我们也可以完成HDFS数据目录和日志目录修改。
确认下一步
Review
点击DEPLOY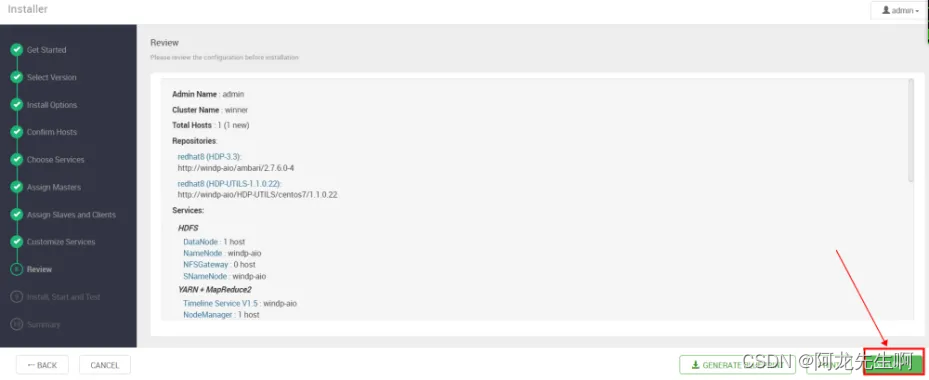
组件安装中,安装大概需要50分钟左右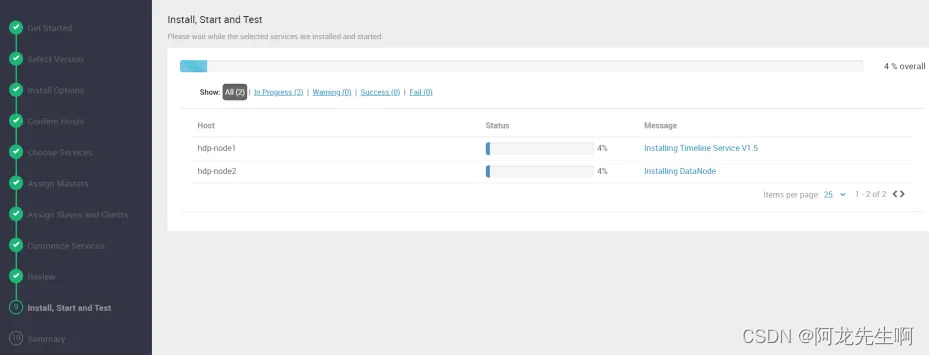
安装完成,下一步, 如果某些组件安装失败我们需要查看日志分析原因。
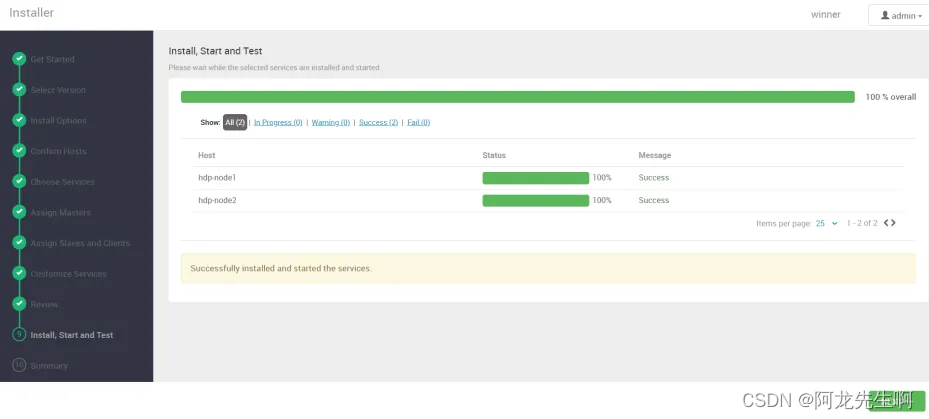
点击 COMPLETE
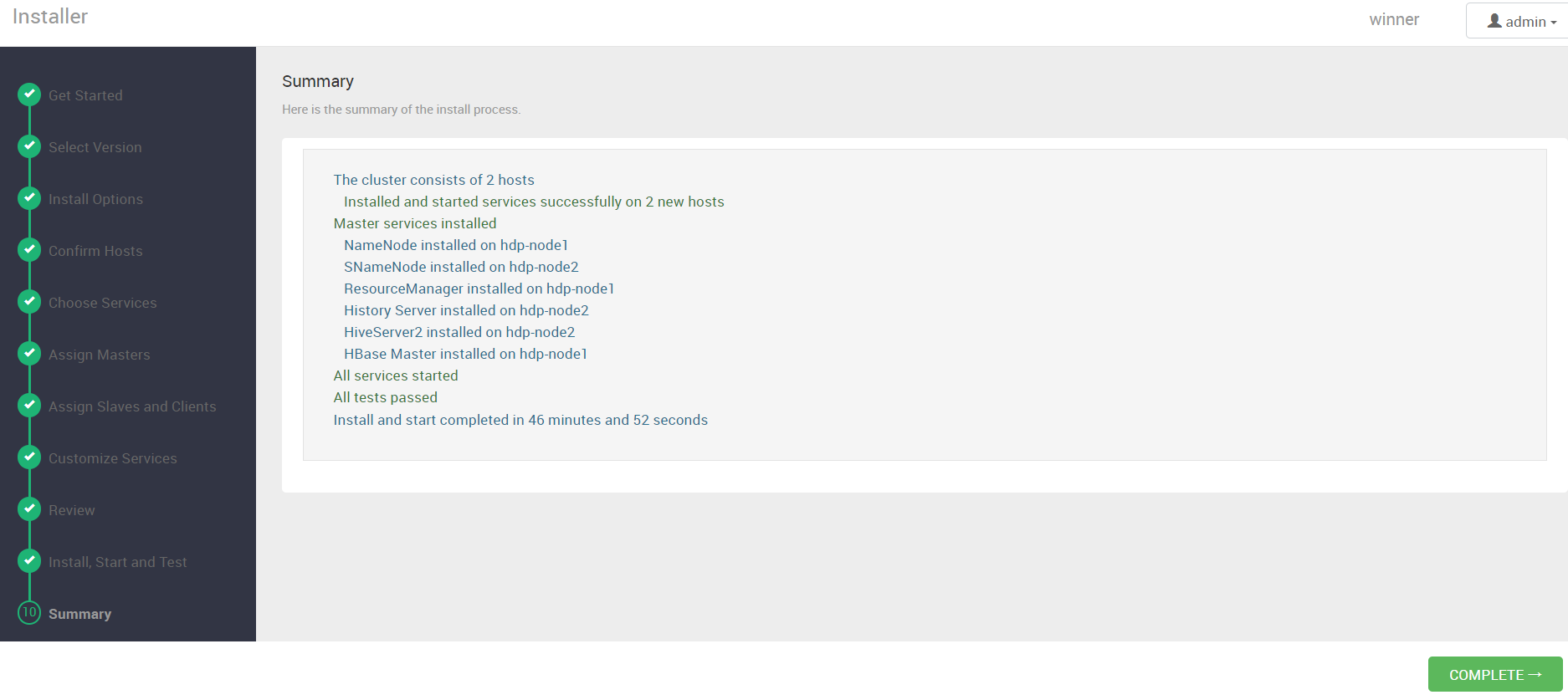
安装完成,启动失败的组件我们逐个查找原因解决就行。
六、开启Kerberos
6.1 kerberos服务检查
执行如下命令,查看krb5kdc,kadmin服务是否启动成功,显示如图“running”则启动成功。
cd /opt/windp-deploy/
systemctl status krb5kdc.service
systemctl status kadmin.servicekrb5kdc,kadmin检查这两个服务为 running 状态,如果没有启动成功尝试重启。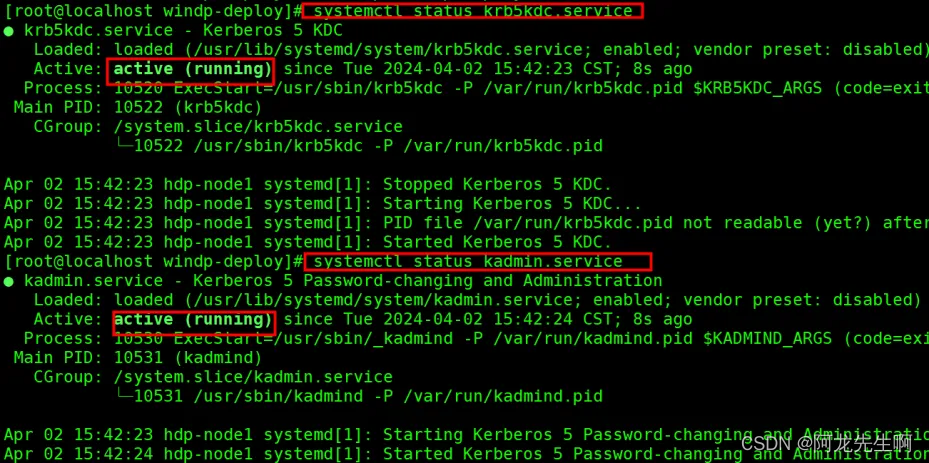
如果没有启动,尝试重启服务命令如下:
cd /opt/windp-deploy/
systemctl restart krb5kdc.service
systemctl restart kadmin.service6.2 Ambari启动kerberos
进入Ambari 管理界面,选中启用Kerberos,点击“ENABLE KERBEROS”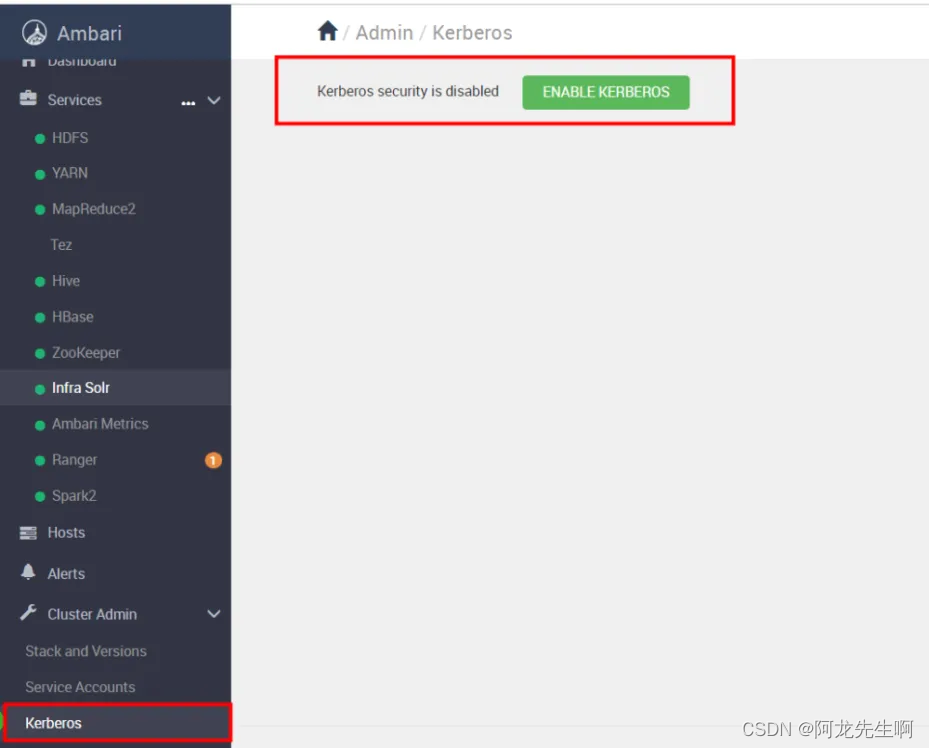
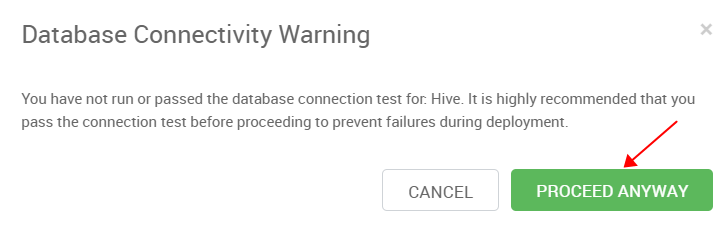
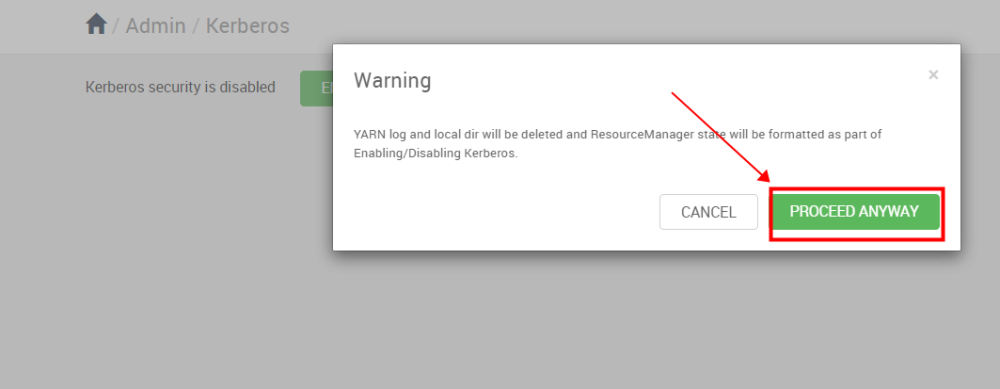
Warning 不用理会,点击“PROCEED ANYWAY”
Get Started
如下图选MIT KDC, 下面的三个框我们都要选上,下一步

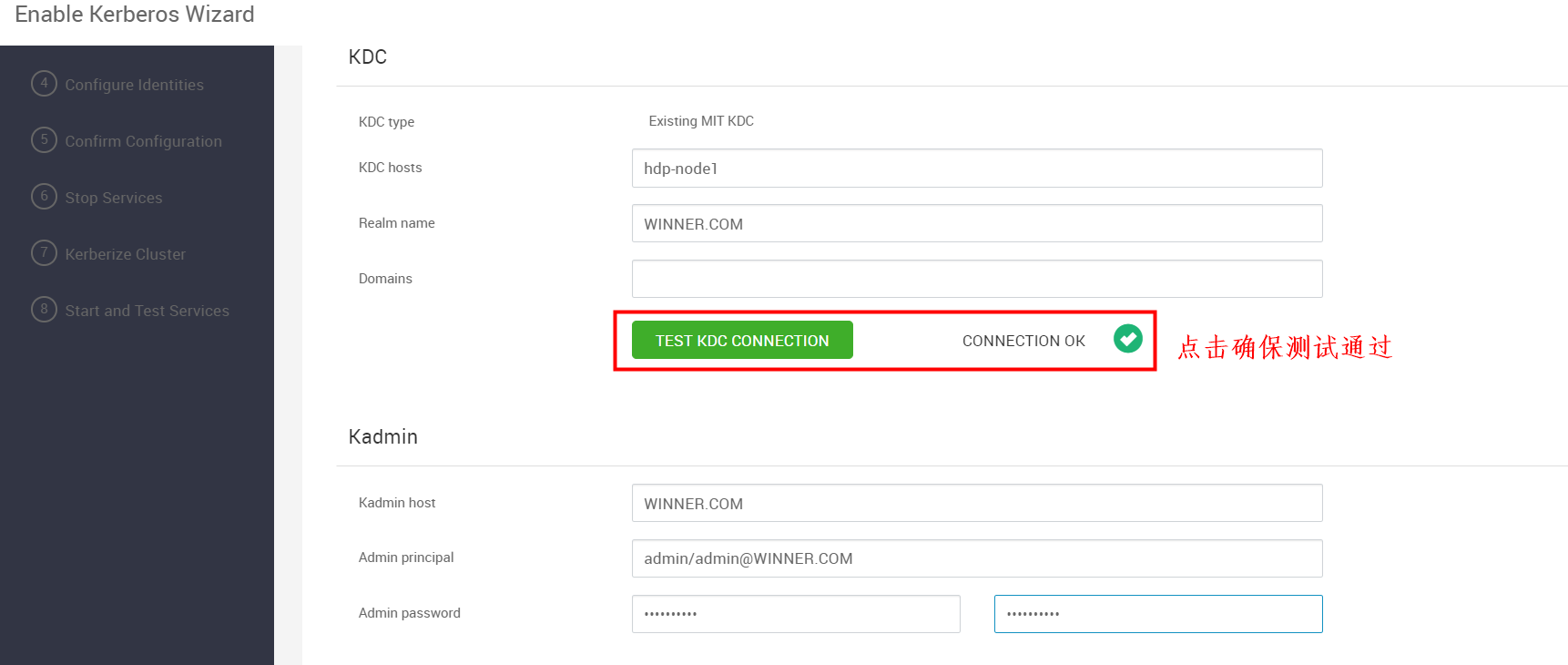
Configure Kerberos
将如下配置复制到对应的位置,确保测试通过,填好之后下一步(修改部分已标红)
- Kadmin host: hdp-node1
- Realm name: WINNER.COM
- Admin principal: admin/admin@WINNER.COM
- Admin password: winner@001
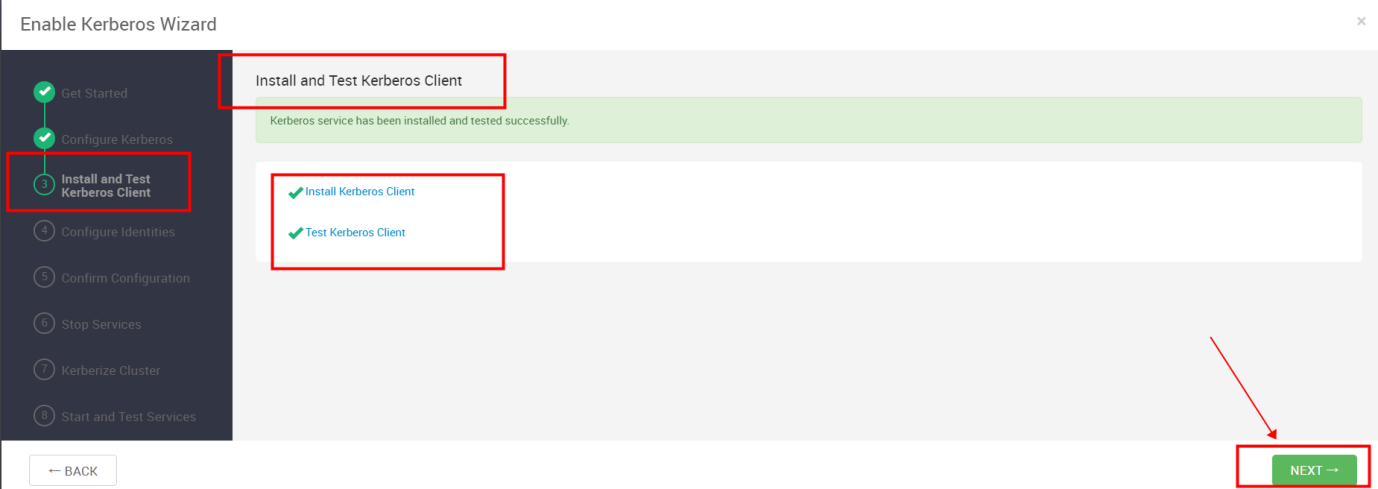
Install and Test Kerberos Client
Kerberos Client 安装和测试完成之后,下一步
Configure Identities
默认 直接下一步
Confirm Configuration
默认直接下一步
Stop Services
停止所有服务,等待执行完成后下一步
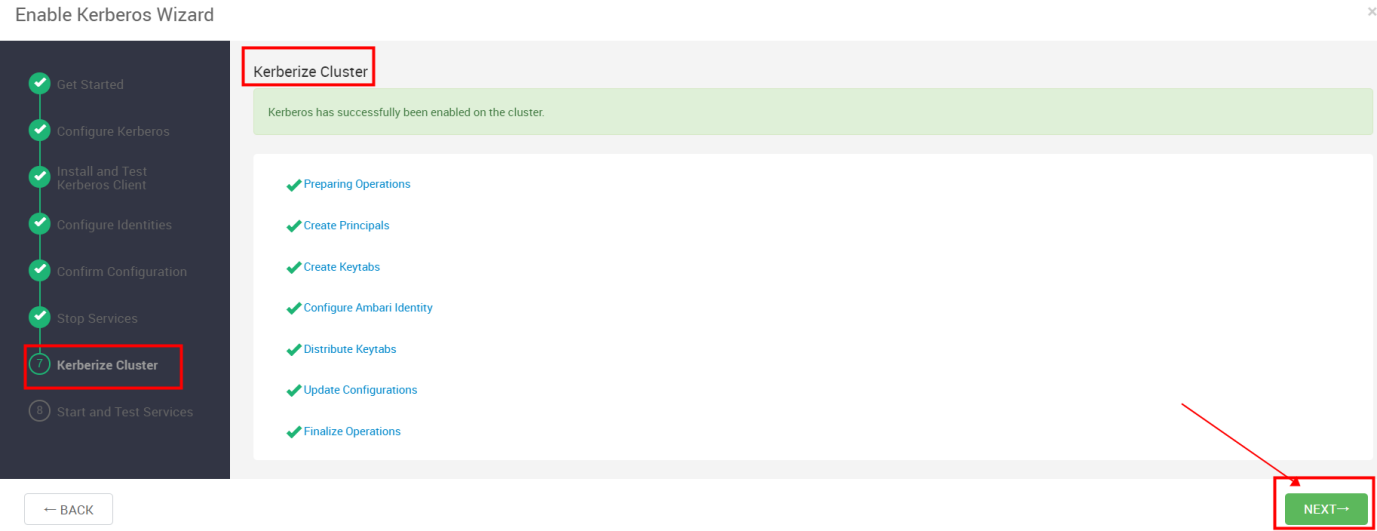
Kerberize Cluster
全部通过后下一步 ,如若失败尝试重试解决问题。
Start and Test Services
启动全部服务并进行测试,全部启动成功需要10分钟左右

启动完成需要10分钟左右,启动完后下一步
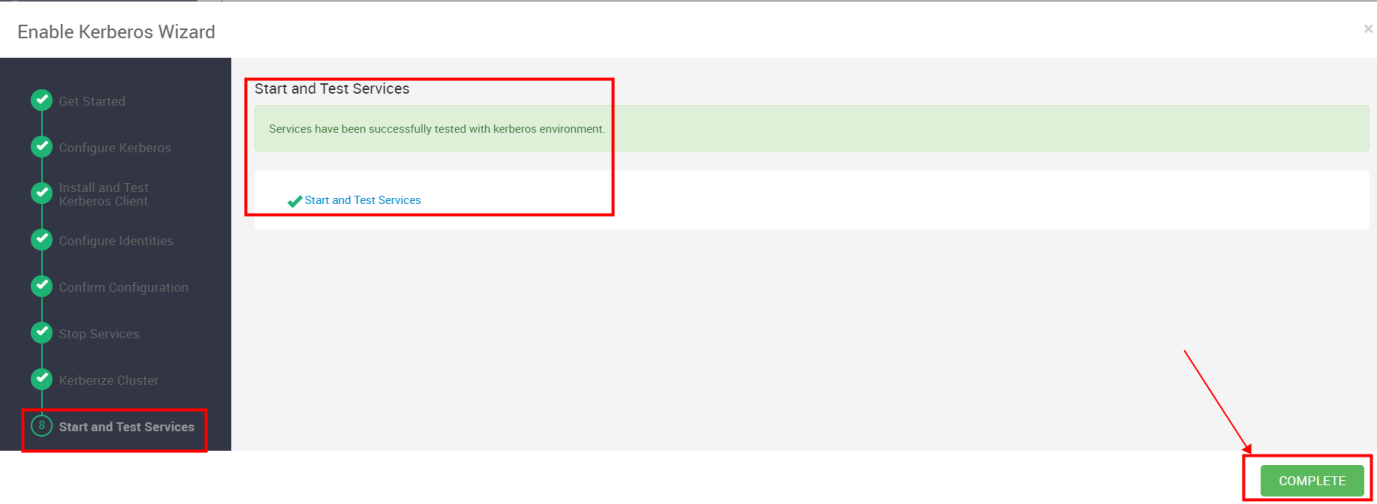
如果启动失败进行启动尝试,或者没有关系直接点击COMPLETE ,然后查看启动不了的组件,逐个解决。
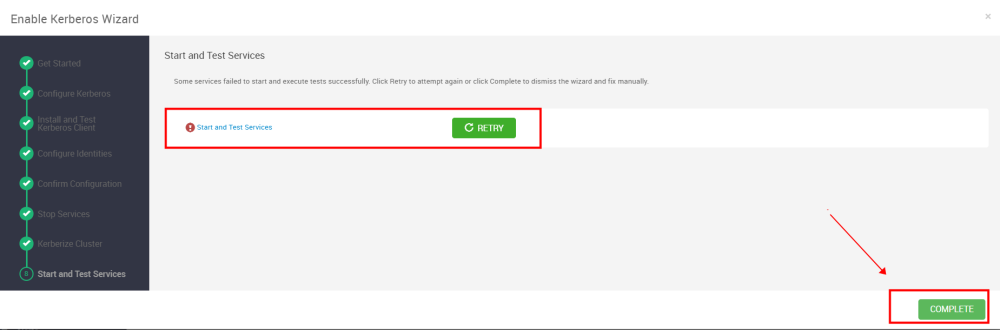
启动完成
七、开启服务高可用
YARN和NameNode的高可用开启至少需要 3个zookeeper Server。也就是说需要3台服务器,否则我们也可以选择不开启服务高可用。
7.1 HBaseMaster高可用开启
在ambari页面上找到hbase的配置页面点击 add HBase Master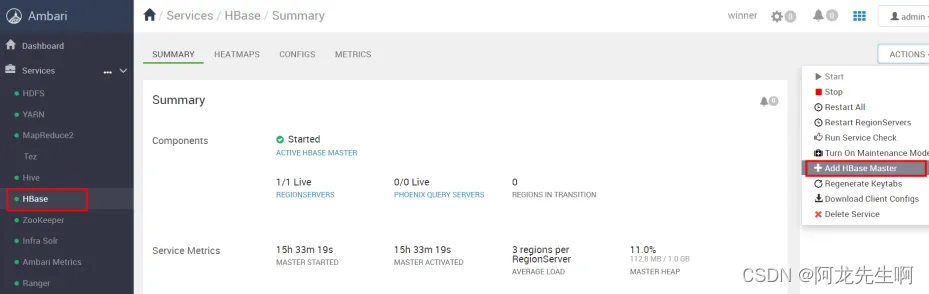
- Admin principal: admin/admin@WINNER.COM
- Admin password: winner@001
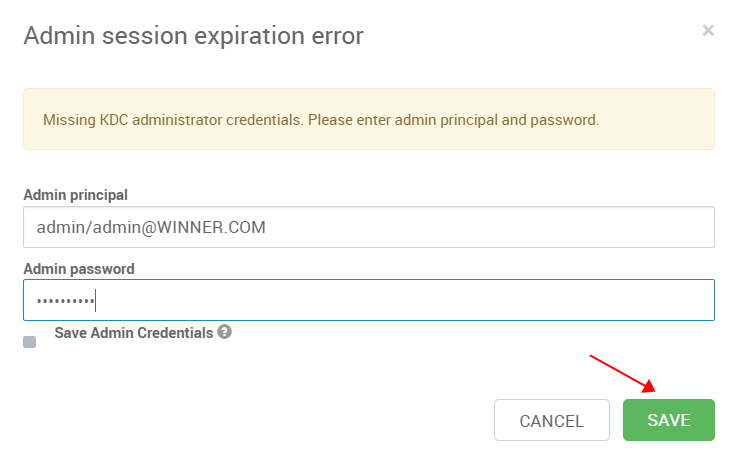
选择新加的HBaseMaster的主机
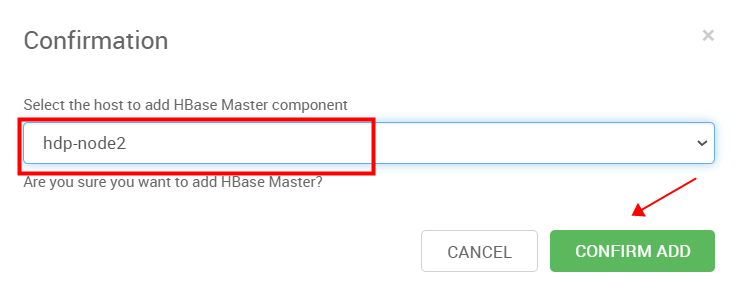
安装中,安装完成后我们选择OK
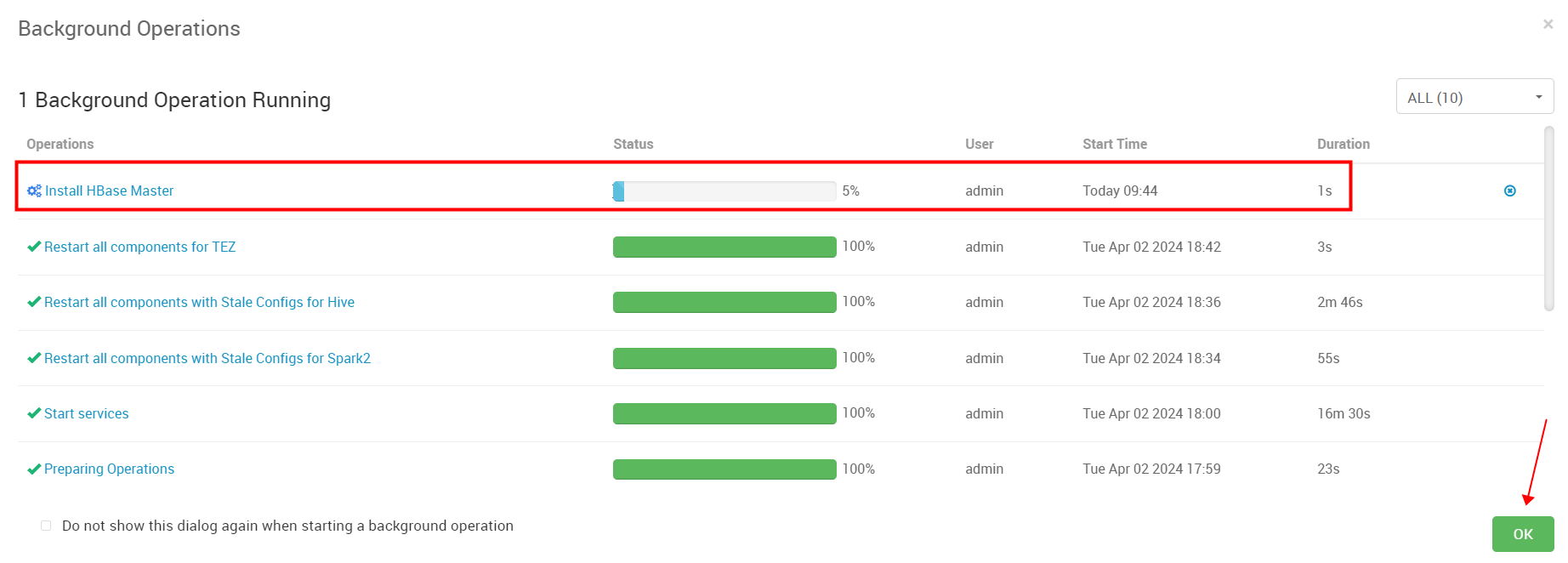
在HBase页面选择Restart All 重启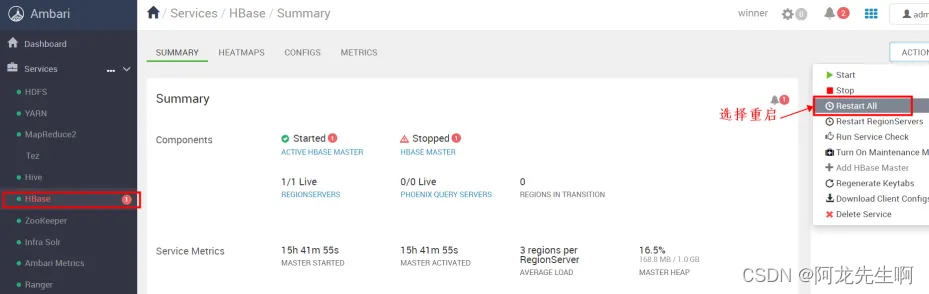
如下图可以看到 两个HBASE MASTER,状态分别是STANDBY和ACTIVE 表示 HBASE MASTER高可用开启成功。
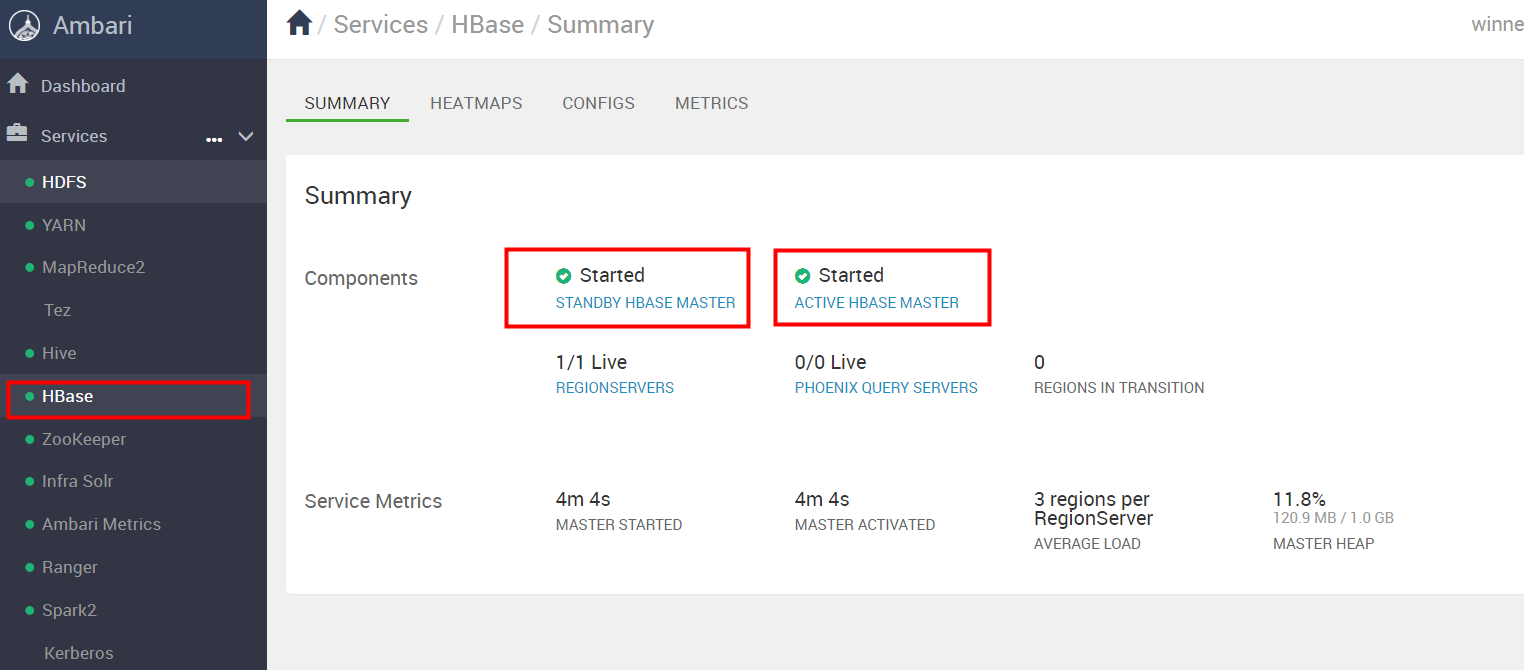
7.2 ResourceManager高可用开启
yarn高可用配置,在ambari上找到yarn管理界面,点击Enable ResourceManager HA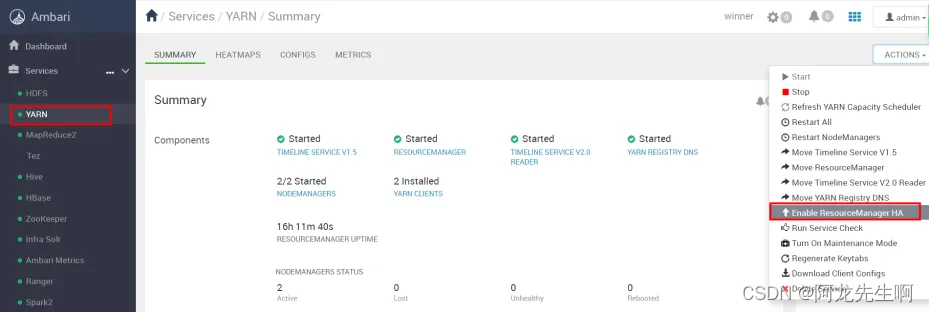
选择下一步
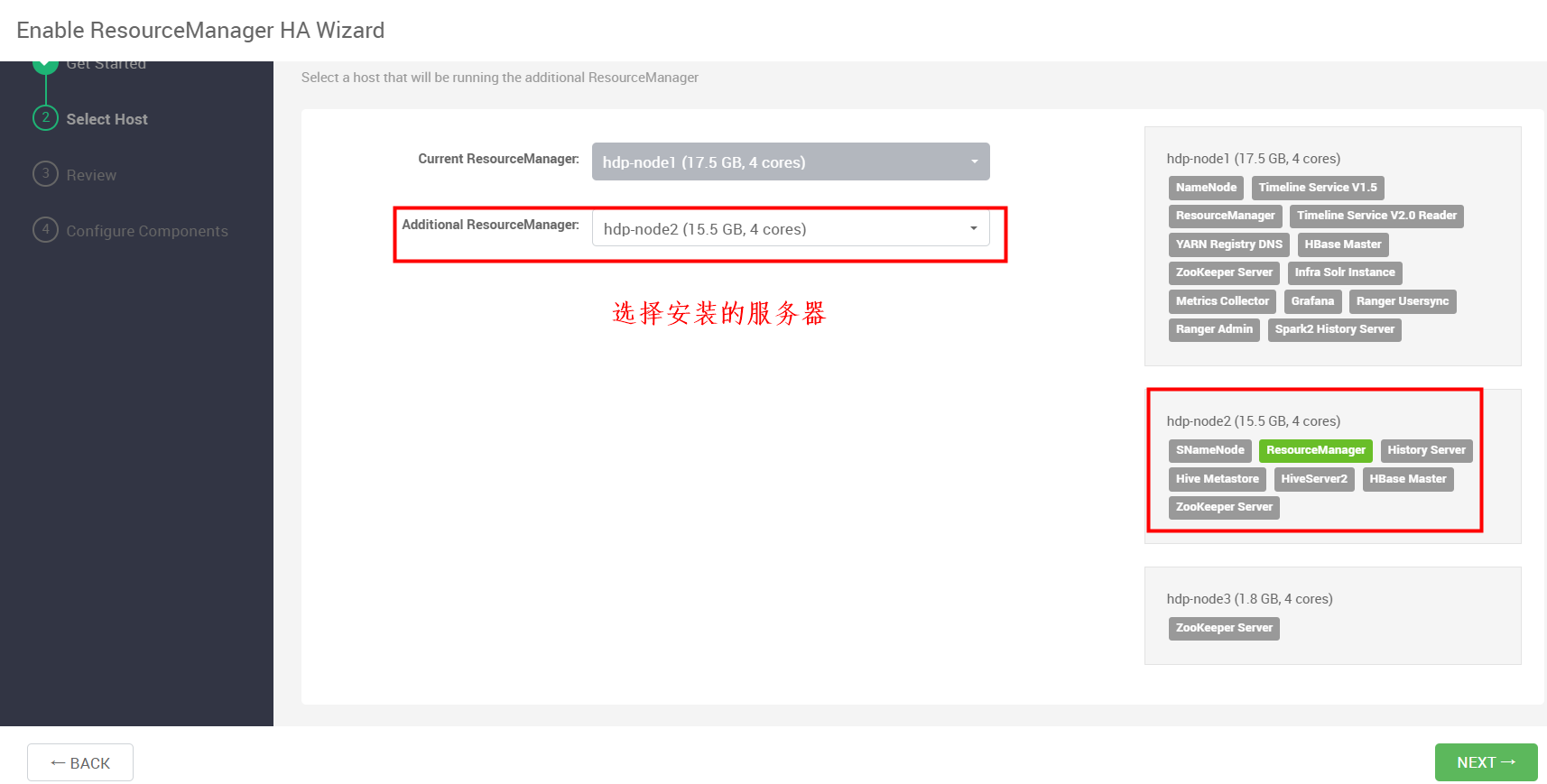
选择高可用开启的另一台服务器,我们选择hdp-node2,然后下一步
REVIEW直接下一步
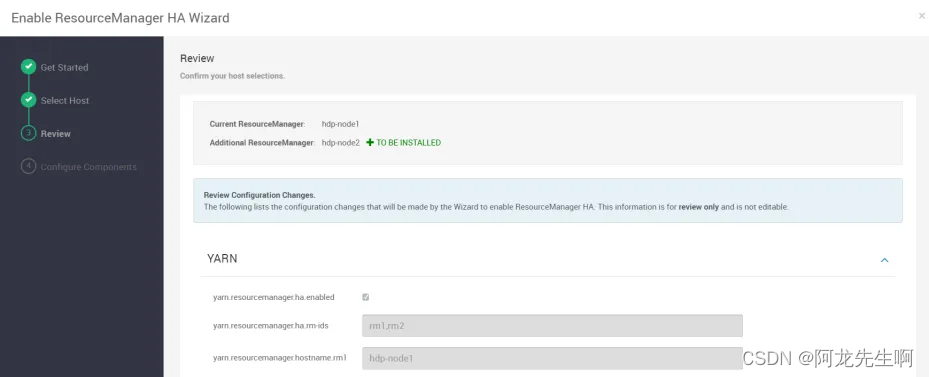
如上内容填好后选择 save
- Admin principal: admin/admin@WINNER.COM
- Admin password: winner@001

等待配置安装完成,需要20分钟左右,启动完成后选择COMPLETE
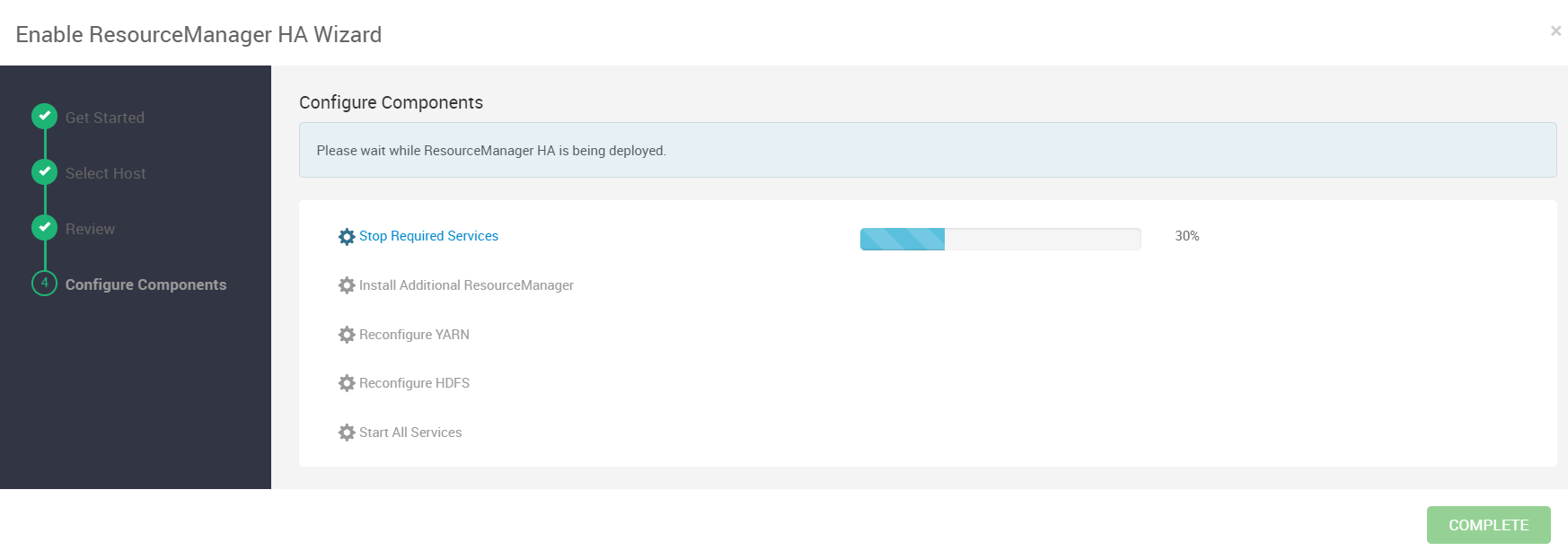
如下图可以看到启动全部完成

如图RESOURCEMANAGER 状态一个是STADDBY 另一个是ACTIVE。
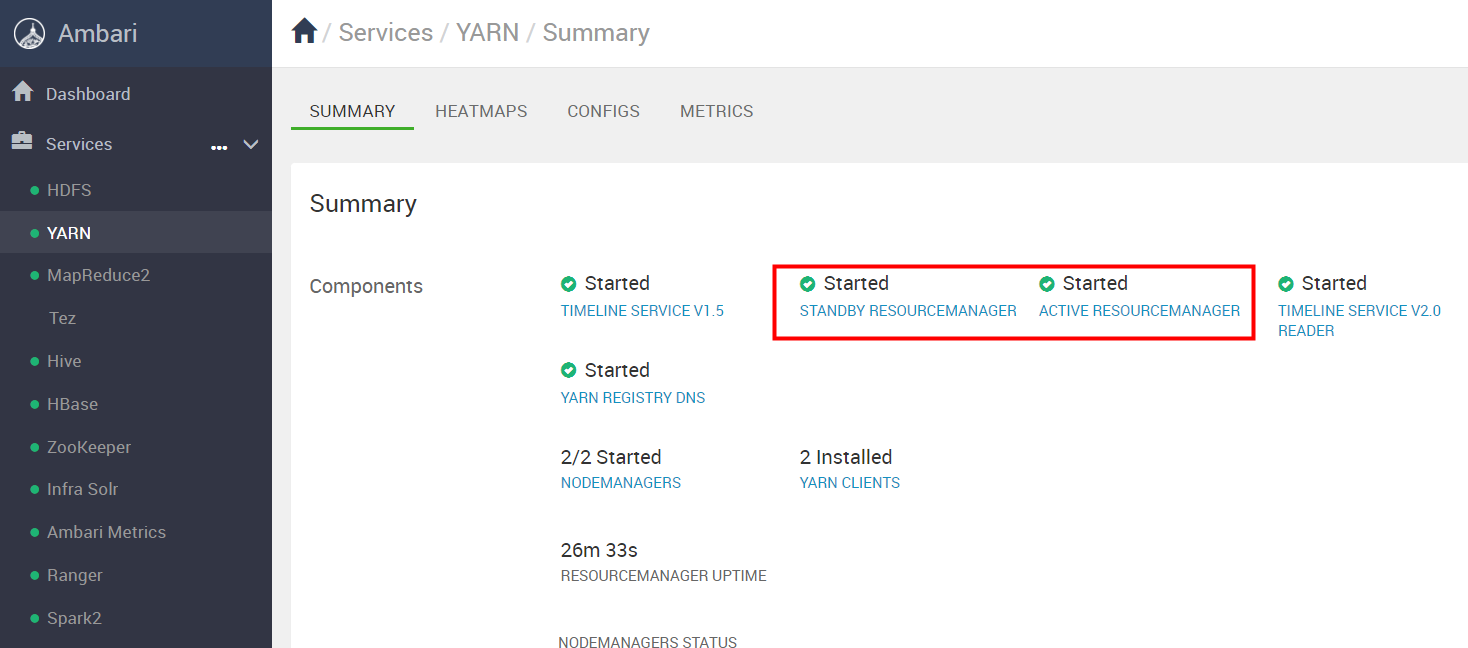
7.3 NameNode高可用开启
HDFS高可用配置,在ambari页面上找到hdfs服务,点击actions ,选择 Enable Namenode HA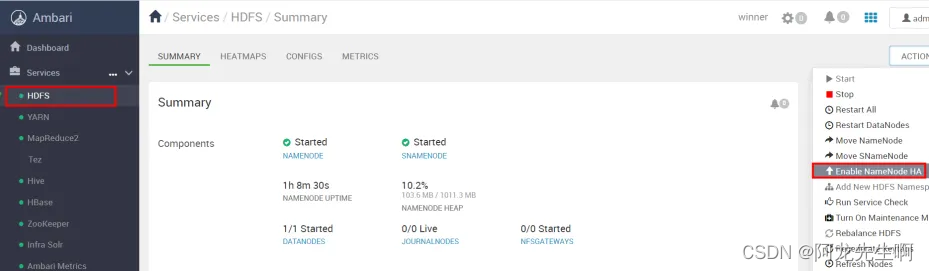
填写hdfs的namespace:winnercluster,确认无误后点击next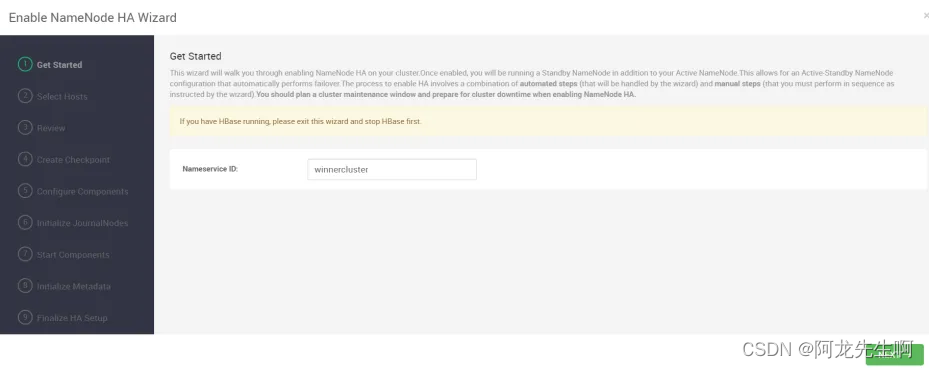
选择namenode和journalNode运行的主机,确认无误后点击next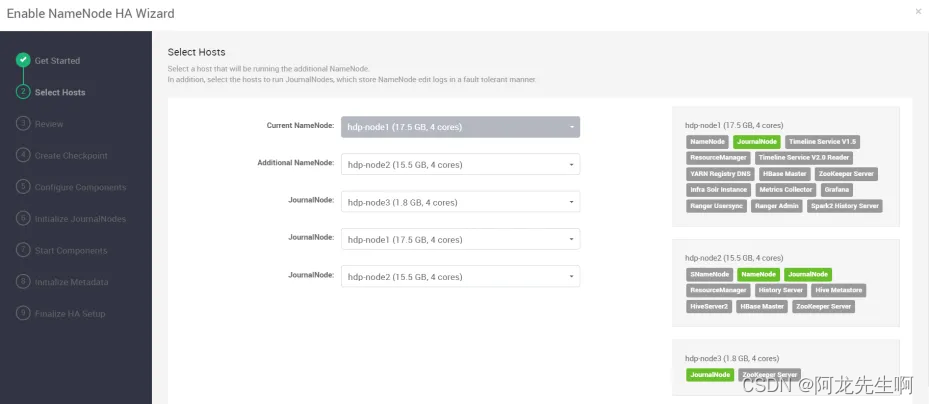
Review下hdfs高可用的配置,点击Next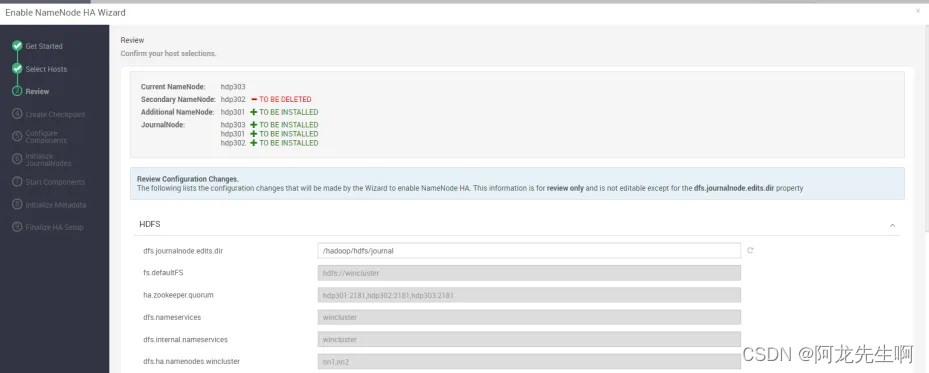
按照提示需要先给hdfs做一下checkpoint,这个时候next 按钮是灰色的,等做完下面的操作后,点击next按钮即可。注意:切记看正确操作的服务器。

如下配置填入页面表格
- Admin principal: admin/admin@WINNER.COM
- Admin password: winner@001
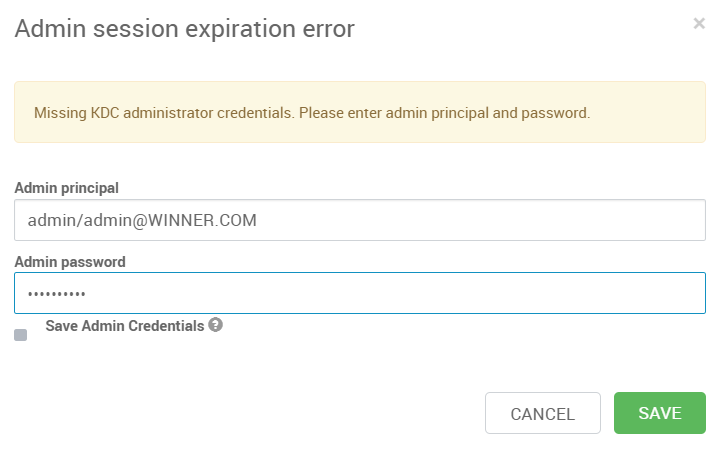
开始安装等待安装完成,然后下一步,大概需要15分钟左右。如若失败我们可以选择重试。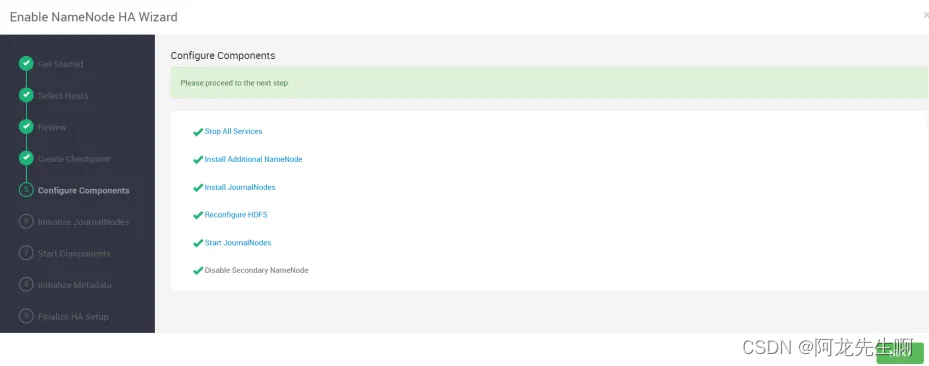
按照提示在服务器上执行命令初始化journalNode,完成后点击next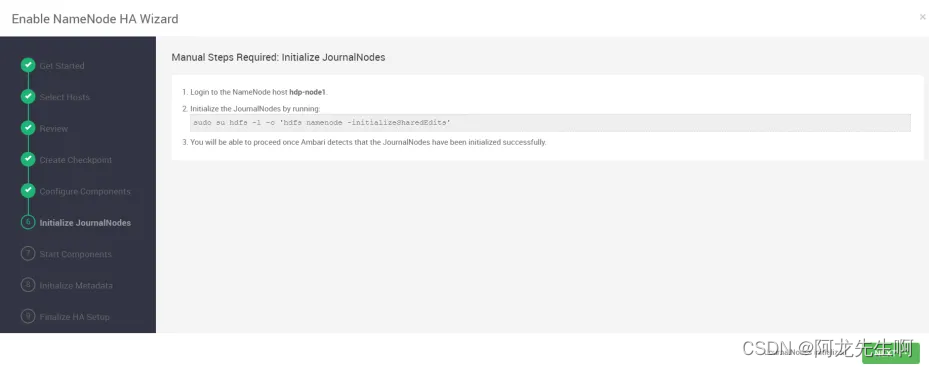

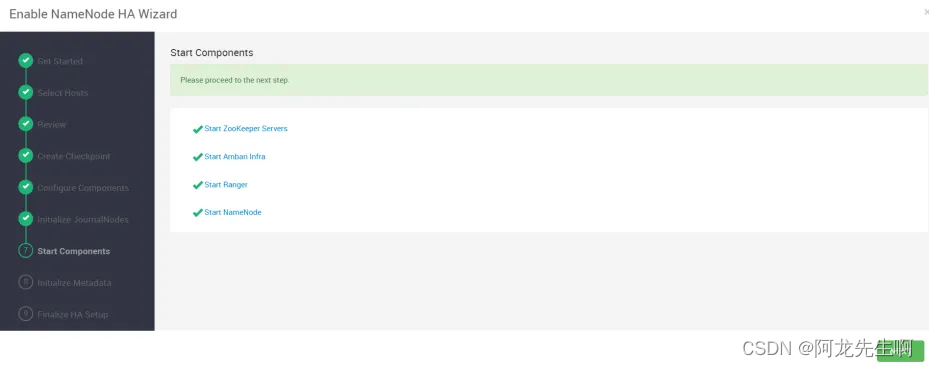
Ambari启动所有相关的组件,启动完成后下一步。大概需要10分钟左右。
按照下图所示初始化元数据信息,执行完成后下一步。注意:切记看正确操作的服务器,是在两台服务器完成命令执行。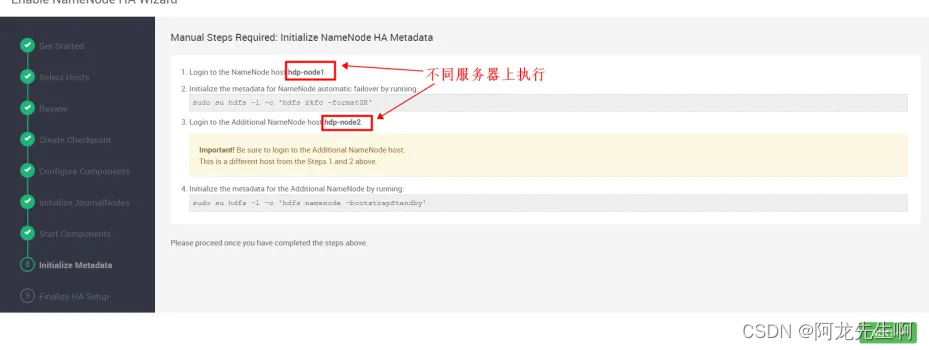
确认操作完后,选择OK

启动所有组件,大概需要15分钟左右,有可能启动失败,我们可以选择重试或者定位具体启动失败原因。
如下图可以看到两个NAMENODE,状态分别是STANDBY和ACTIVE 表示 NAMENODE高可用开启成功。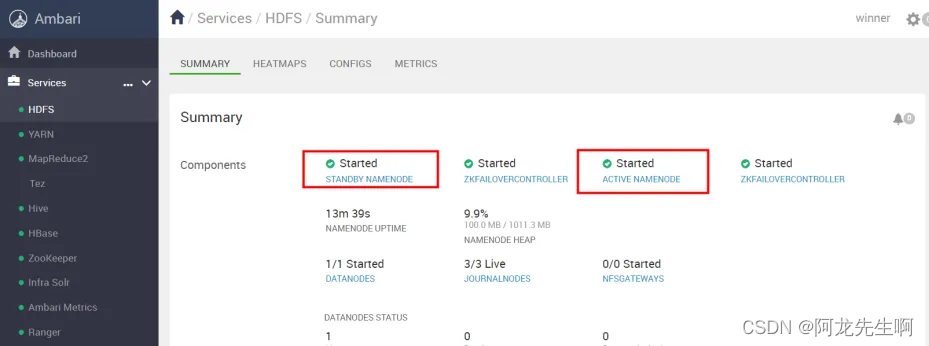
八、ranger权限开启
8.1 ranger登录
访问图中链接会跳转到ranger登录页面,登录失败可能需要将主机名换成IP。
登录ranger web页面,用户名:admin ,密码:winnerxxxx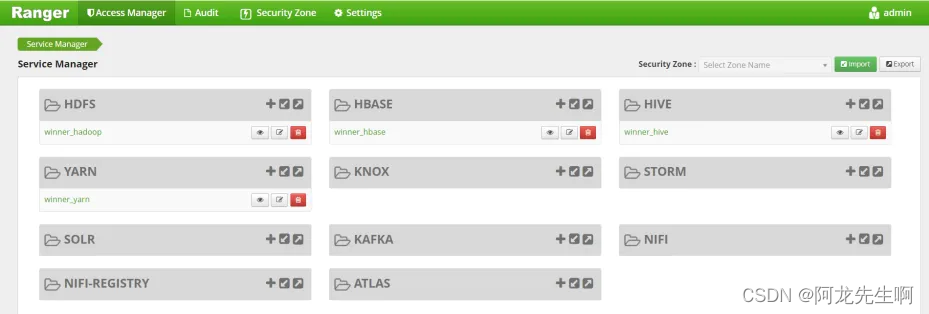
登录后的页面如下
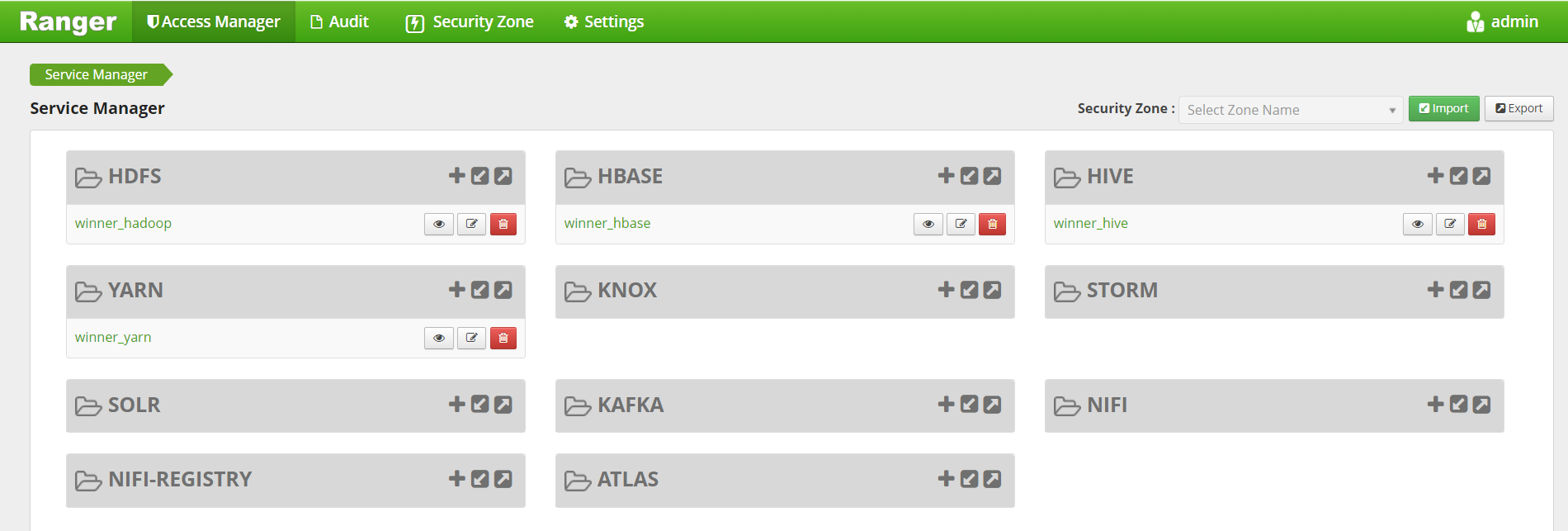
我们需要添加winner_spark的服务组件操作权限。
8.2 HDFS权限控制
点击进入默认的service设置页面
点击进入Policy ID为1 的策略进入编辑
添加winner_spark用户
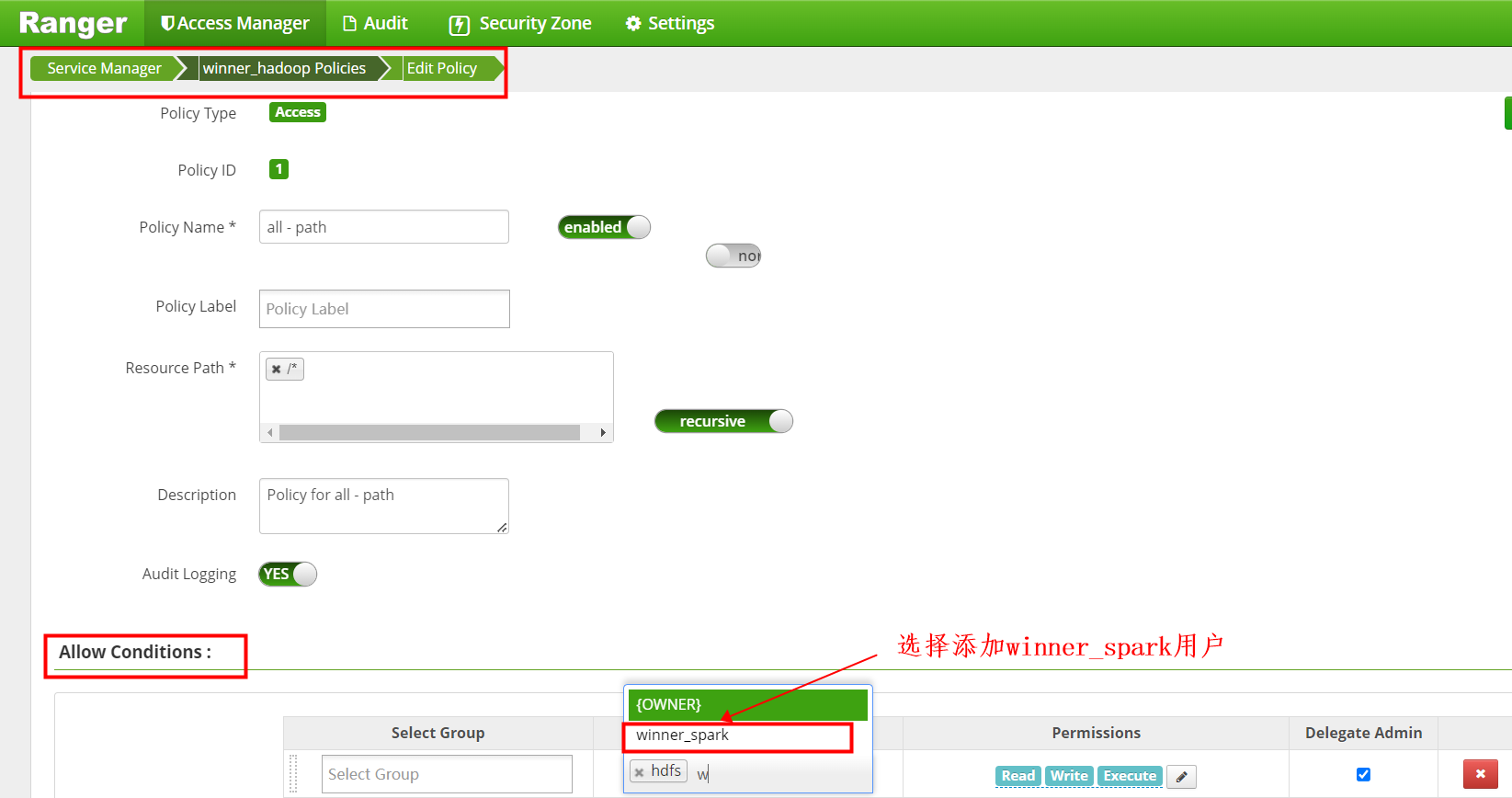
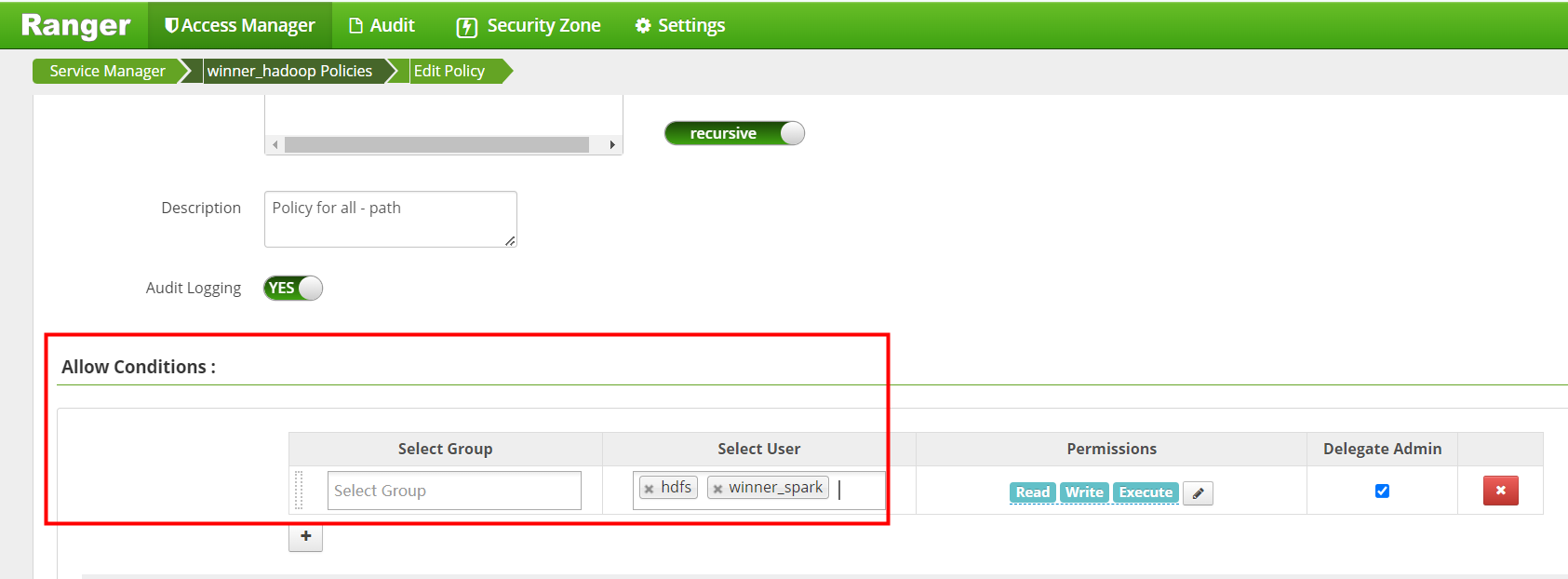
添加完成后 save保存。
Policy ID为2的策略也是编辑添加winner_spark 后 保存。winner_spark 用户添加HDFS操作权限完成后如下图

我们需要Policy ID 为1 策略中添加hive 用户对HDFS操作权限,完成后如下图
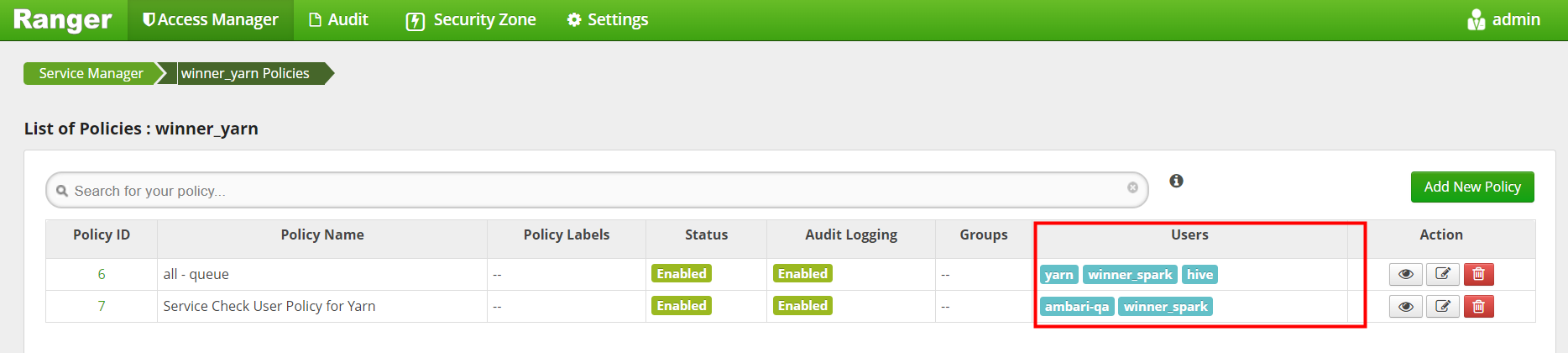
8.3 HBase权限控制
点击进入默认的service设置页面
点击进入Policy ID为4 的策略进入编辑
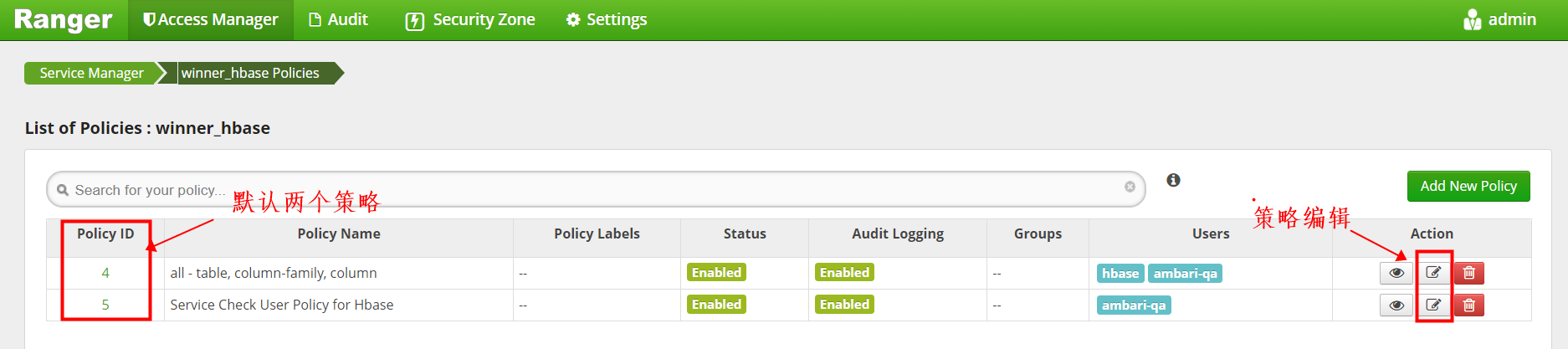
添加winner_spark用户
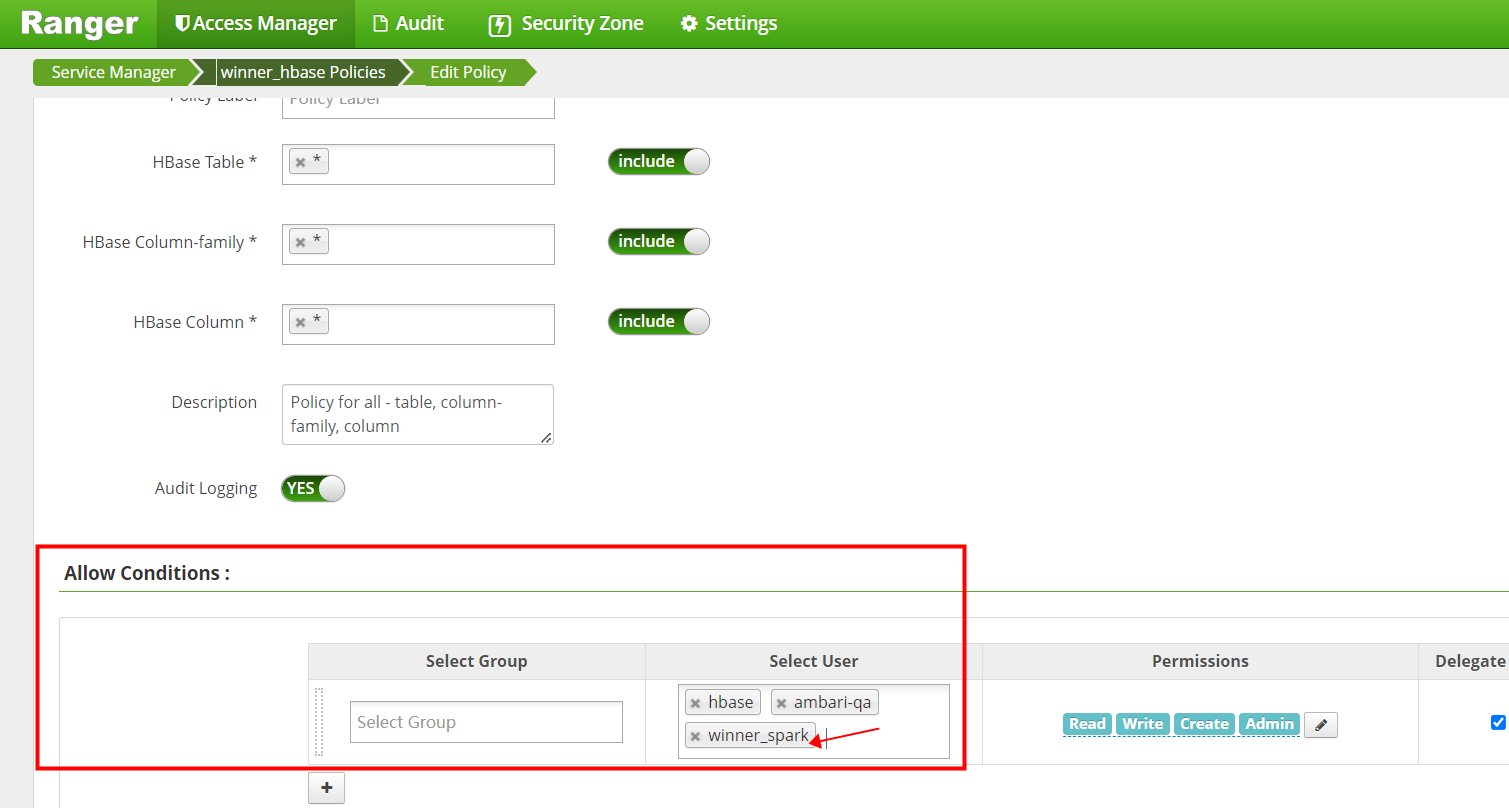
添加完成后 save保存。Policy ID为5的策略也是编辑添加winner_spark 后 保存。
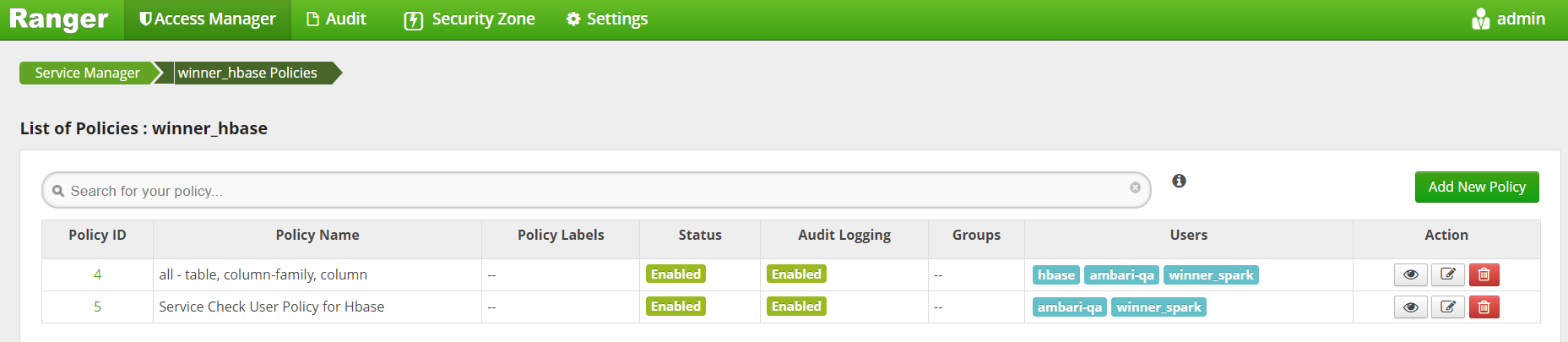
winner_spark 用户添加HBase操作权限完成后如下图
8.4 Hive权限控制
点击进入默认的service设置页面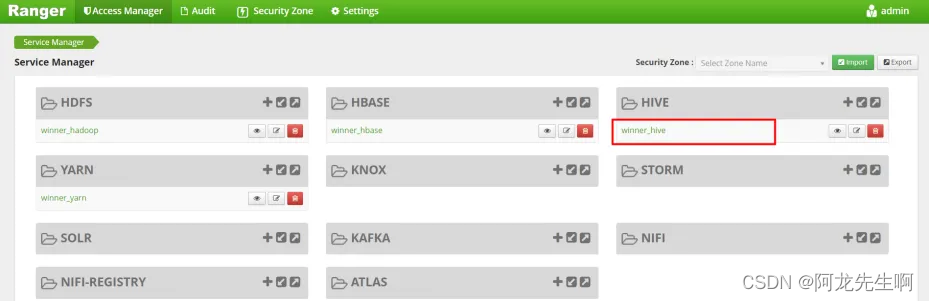
点击进入Policy ID为8 的策略进入编辑
添加winner_spark用户权限完成后 save保存。
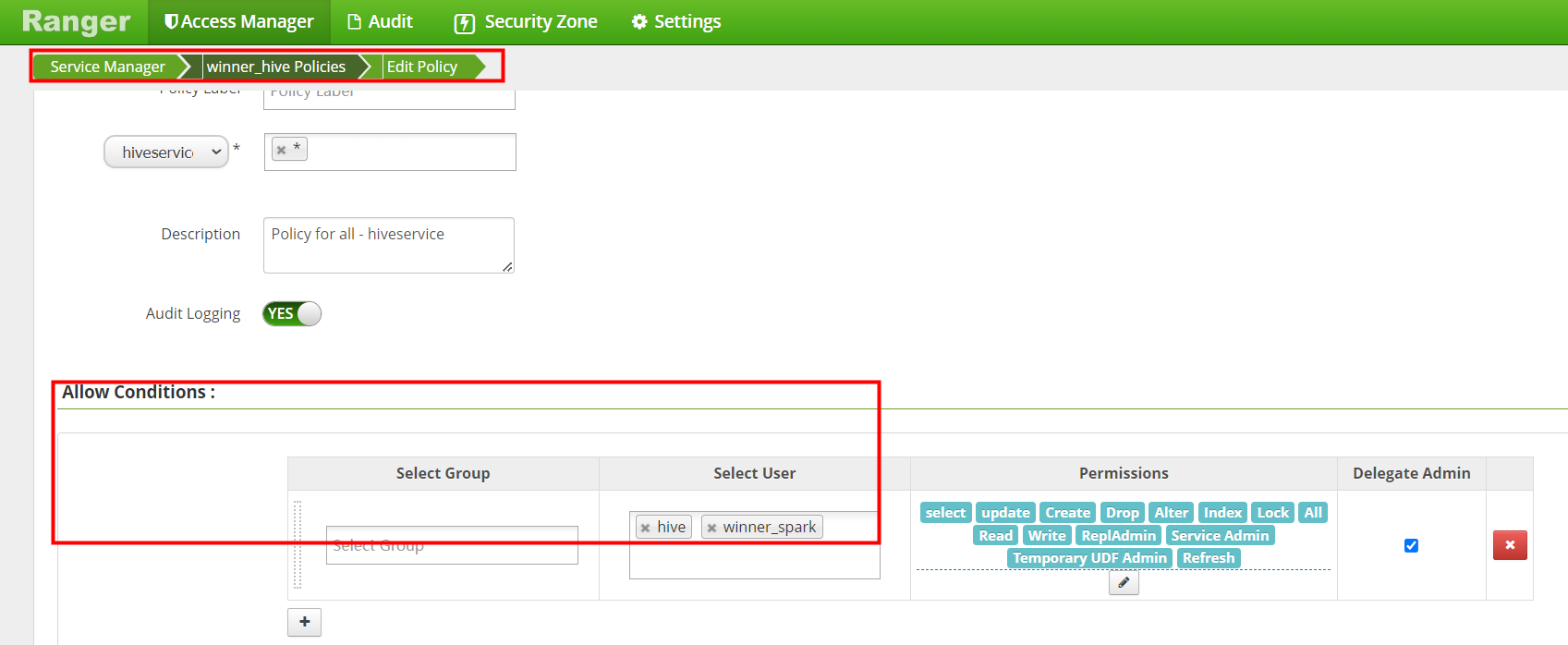
剩下的Policy 策略也是编辑添加winner_spark 后 保存。
winner_spark 用户添加Hive操作权限完成后如下图
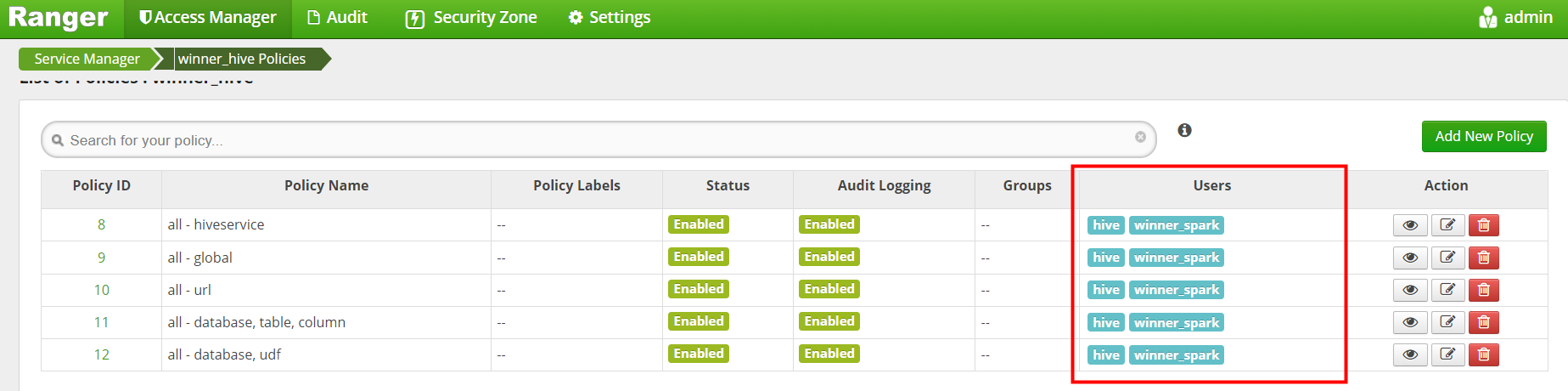
8.5 Yarn权限控制
点击进入默认的service设置页面
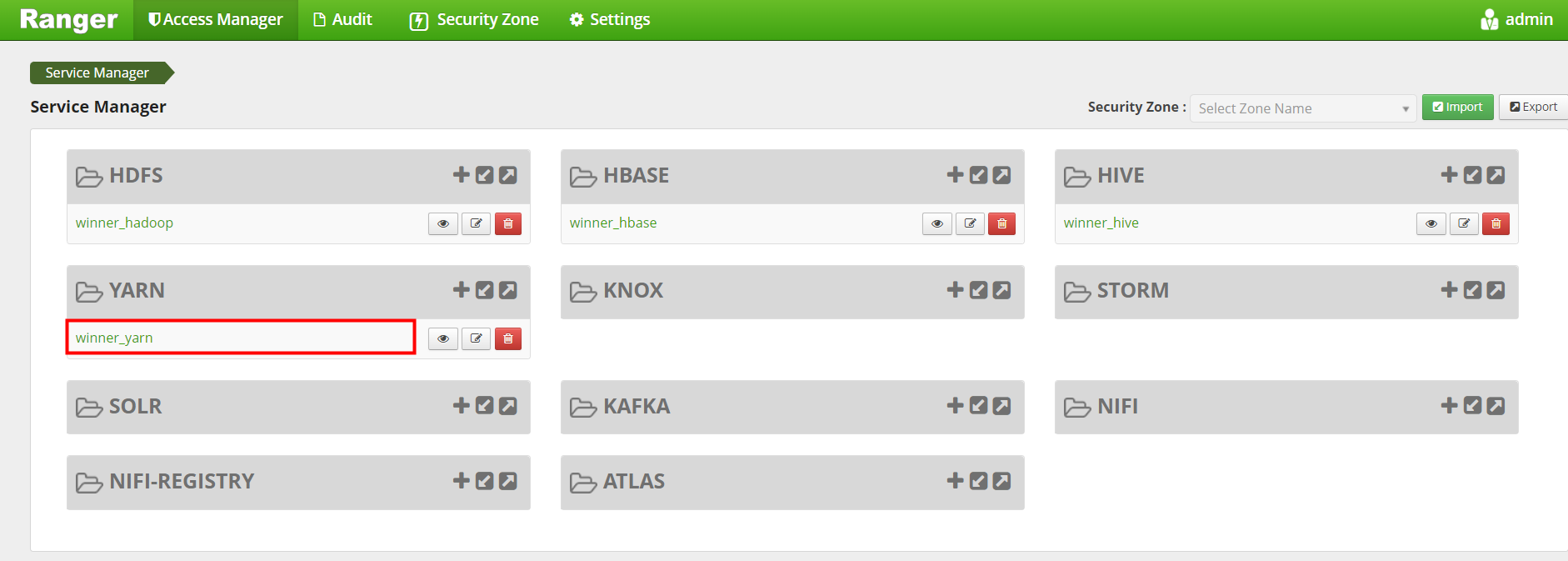
点击进入Policy ID为6 的策略进入编辑

添加winner_spark用户
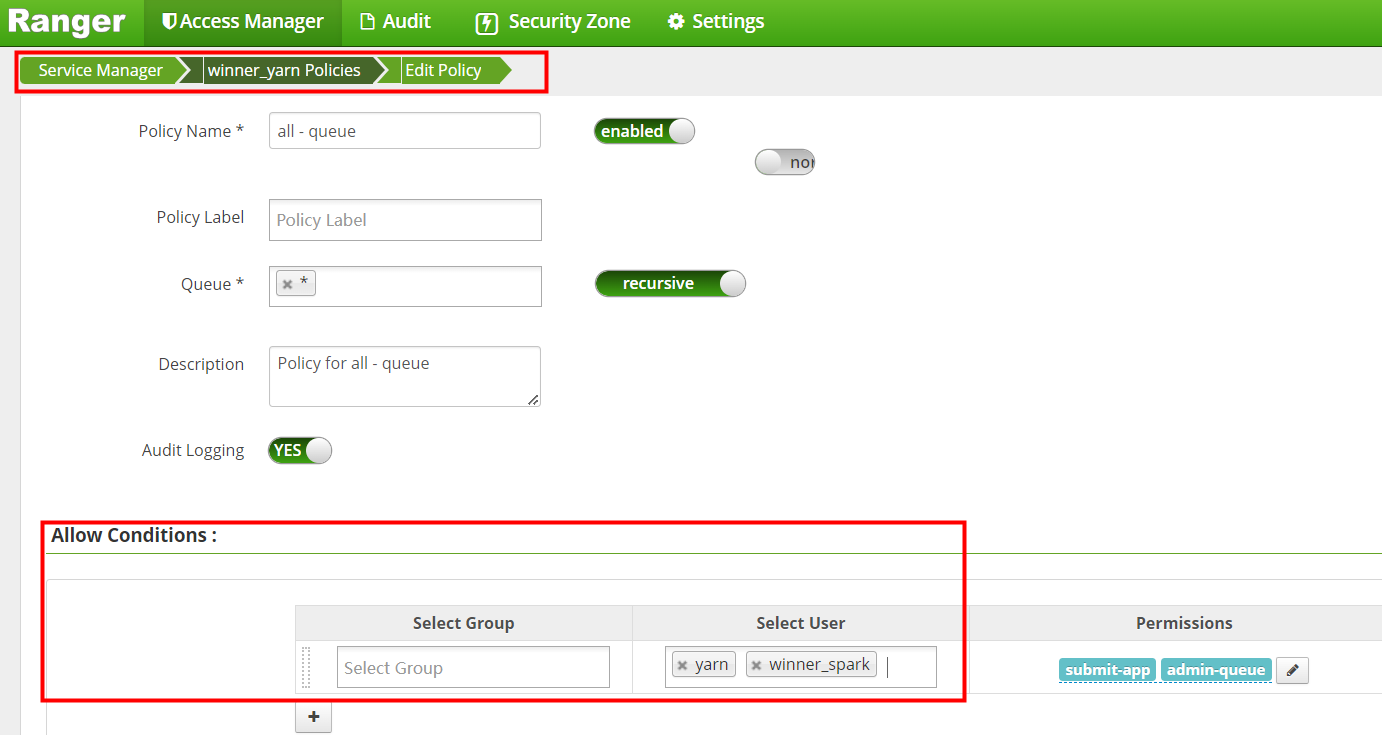
剩下的Policy 策略也是编辑添加winner_spark 后 保存。
winner_spark 用户添加Yarn操作权限完成后如下图

九、Ansible自动化安装脚本
说明:脚本可以在博客资源中可以下载,如下是部署目录结构。
 脚本入口 installDeployAmbari.sh
脚本入口 installDeployAmbari.sh
#!/bin/bash
#
# 脚本功能: 配置初始化,完成ambari-server安装启动
# 作 者: kangll
# 创建时间: 2024-03-29
# 修改时间: 2024-03-29
# 当前版本: 1.0v
# 调度周期: 一次性任务
# 脚本参数: 无
#
#
. /etc/profile > /dev/null 2>&1
set -x
#set -e
# 请确保已经按照部署文档中事先配置好了, ./autoDeployFiles/scripts/hostlist.txt中的内容以及temphosts.txt
# ./config/global.shBASEDIR=$(cd "$(dirname "$0")"; pwd)
scriptsDir=$BASEDIR/autoDeployFiles/scripts
cd ${scriptsDir}if [ `rpm -qa |grep expect > /dev/null 2>&1;echo $?` -ne 0 ]; thensudo yum install -y expect
fiif [ `rpm -qa |grep ansible > /dev/null 2>&1;echo $?` -ne 0 ]; thensudo yum install epel-release -ysudo yum install ansible -y
ficat ${scriptsDir}/temphosts.txt |awk '{print $1,$2}' | while read vIP vHost
doif [ `grep ${vHost} /etc/hosts > /dev/null 2>&1;echo $?` -ne 0 ]; thenecho "${vIP} ${vHost}" >> /etc/hostsfi
done# linux 免密
sh $scriptsDir/batchSendKey.sh# linux hosts
for i in `cat ${scriptsDir}/temphosts.txt |awk '{print $2}' |grep -v \`hostname\`|xargs `
doscp /etc/hosts $i:/etc/
done# linux hosts
for i in `cat ${scriptsDir}/temphosts.txt |awk '{print $2}' |xargs `
dossh $i "sudo hostnamectl set-hostname $i"
donesource /etc/profileambari_server_source=`hostname`
sudo sed -i 's/windp-aio/'"${ambari_server_source}"'/g' $BASEDIR/ambari.yml# ansible hosts
echo [all_node] > /etc/ansible/hosts
cat ${scriptsDir}/temphosts.txt |awk '{print $2}' >> /etc/ansible/hosts
echo "" >> /etc/ansible/hosts# 默认安装ambariserver的服务器为控制端,也就是master节点
echo [master] >> /etc/ansible/hosts
echo `hostname` >> /etc/ansible/hosts
echo "" >> /etc/ansible/hosts# 除当前服务器的其他服务器为agent
echo [slave] >> /etc/ansible/hosts
cat ${scriptsDir}/temphosts.txt |awk '{print $2}' |grep -v `hostname` >> /etc/ansible/hostscd $BASEDIR
ansible-playbook ambari.ymlambari.yml
---# author: kangll
# date: 2024-04-03
# funtion: 离线自动化部署ambari-server
# 版本要求:
# OS: Redhat7.2-CentOS7.9(仅支持该操作系统版本)
# ambari-2.7.4
# MySQL 5.7+/Python3+
# - hosts: all_nodegather_facts: Fvars:paths:scriptsDir: /opt/windp-deploy/autoDeployFiles/scriptsJDKDir: ./autoDeployFiles/JDKJAVA_HOME_PATH: /usr/javapackages:jdk: jdk-8u162-linux-x64.tar.gztasks:- include: ./component/setup_base_env.yml # 设置基础环境- include: ./component/setup_java_env.yml # 设置JAVA_HOMEremote_user: roottags: jdk_base_env- hosts: mastergather_facts: Fvars:local_ambari_os_yum_repo: hdp-node1paths:MySQLDir: ./autoDeployFiles/MySQLinstallScriptDir: /opt/windp-deployMySQLConfDir: ./autoDeployFiles/configFilesdriverDir: /usr/share/javaconfDir: ./autoDeployFiles/configFilespassword:mysql: Winner001ambari: Winner001hive: Winner001packages:mysql_driver: mysql-connector-java.jartasks:- include: ./component/setup_mysql_server.yml # 创建用户解压MySQL包于/usr/local/mysql、MySQL初始化、修改root密码- include: ./component/setup_kdc_server.yml # 安装配置kerberos- include: ./component/setup_ambari_server.yml # 安装并启动Ambari-serverremote_user: roottags: mysql- hosts: slavegather_facts: Fvars:paths:repoTmpDir: ./config/reporepoDir: /etc/yum.repos.dkrb5File: /etc/keytabFile: /etc/security/keytabstasks:- include: ./component/setup_hdp_repo.yml # repo,kerberos配置同步remote_user: roottags: repo
install_base_kdc.sh
#! /bin/bash
#
# Author: kangll
# CreateTime: 2024-03-10
# Desc: kerberos配置
##set -x
BASEDIR=$(cd "$(dirname "$0")"; pwd)
# 加载配置
source $BASEDIR/config/global.sh# global.sh 配置文件中获取
ssh_passwd="winner@001"
kerberos_user=winner_sparkhostName=`hostname`
########################
# 配置kerberos,安装启动
########################
config_krb5() {# kerberos server and clientsudo yum install krb5-server krb5-libs krb5-workstation -y# config filesudo cat $BASEDIR/config/krb5.conf > /etc/krb5.conf# 修改为 kdc serve hostnamesudo sed -i 's/windp-aio/'"${hostName}"'/g' /etc/krb5.confsudo cat $BASEDIR/config/kdc.conf > /var/kerberos/krb5kdc/kdc.confsudo cat $BASEDIR/config/kadm5.acl > /var/kerberos/krb5kdc/kadm5.aclecho "******* 创建kdc数据库 *********"/usr/bin/expect << eof# 设置捕获字符串后,期待回复的超时时间set timeout 30spawn kdb5_util create -s -r WINNER.COM $1@$2## 开始进连续捕获expect {"Enter KDC database master key:" { send "${ssh_passwd}\n"; exp_continue }"master key to verify:" { send "${ssh_passwd}\n"; exp_continue }}
eofecho "******** 创建admin实例 *********"/usr/bin/expect << eof# 设置捕获字符串后,期待回复的超时时间set timeout 30spawn kadmin.local ## 开始进连续捕获expect {"kadmin.local:" { send "addprinc admin/admin\n"; exp_continue }"Enter password for principal" { send "${ssh_passwd}\n"; exp_continue }"Re-enter password for principal" { send "${ssh_passwd}\n"; }}expect "kadmin.local:" { send "quit\r"; }
eof# start kdc and kadmin sudo systemctl restart krb5kdcsudo systemctl enable krb5kdcsudo systemctl restart kadminsudo systemctl enable kadmin# add linux user sudo useradd winner_spark# keytabs file pathsudo mkdir -p /etc/security/keytabs/echo "********** kerberos installation completed **********"
}##################################
# 配置kerberos用户: winner_spark
# 生成keytab 文件
##################################
config_kerberos_user() {echo "******** 创建winner_spark用户实例 ********"/usr/bin/expect << eof# 设置捕获字符串后,期待回复的超时时间set timeout 30spawn kadmin.local ## 开始进连续捕获expect {"kadmin.local:" { send "addprinc ${kerberos_user}\n"; exp_continue }"Enter password for principal" { send "${ssh_passwd}\n"; exp_continue }"Re-enter password for principal" { send "${ssh_passwd}\n"; }}expect "kadmin.local:" { send "quit\r"; }
eofecho "******** winner_spark用户生成keytab文件 ********"/usr/bin/expect << eof# 设置捕获字符串后,期待回复的超时时间set timeout 30spawn kadmin.local ## 开始进连续捕获expect {"kadmin.local:" { send "xst -k /etc/security/keytabs/${kerberos_user}.keytab ${kerberos_user}@WINNER.COM\n"; }}expect "kadmin.local:" { send "quit\r"; }
eofsleep 2s# modify keytab file privilege sudo chown ${kerberos_user}:${kerberos_user} /etc/security/keytabs/${kerberos_user}.keytabecho "********** kerberos user winner_spark add completed **********"
}# 配置kerberos,并启动
config_krb5# 配置kerberos用户: winner_spark, 生成keytab 文件
config_kerberos_userinstall_mysql.sh
#! /bin/bash
#
# Author: kangll
# CreateTime: 2023-11-10
# Desc: install mysql5.7
#
set -x
echo "******** INSTALL MYSQL *********"
####################################
BASEDIR=$(cd "$(dirname "$0")"; pwd)
# 加载数据库默认连接信息
source $BASEDIR/config/global.sh
install_path=$mysql_install_path
hostname=`"hostname"`###################################### 卸载原有的mariadb
OLD_MYSQL=`rpm -qa|grep mariadb`
profile=/etc/profile
for mariadb in $OLD_MYSQL
dorpm -e --nodeps $mariadb
done# 删除原有的my.cnf
sudo rm -rf /etc/my.cnf#添加用户组 用户
sudo groupadd mysql
sudo useradd -g mysql mysql# 解压mysql包并修改名称
tar -zxvf $BASEDIR/autoDeployFiles/MySQL/mysql-5.7.44-el7-x86_64.tar.gz -C $install_path
sudo mv $install_path/mysql-5.7.44-el7-x86_64 $install_path/mysql# 更改所属的组和用户
sudo chown -R mysql $install_path/mysql
sudo chgrp -R mysql $install_path/mysqlsudo mkdir -p $install_path/mysql/data
sudo mkdir -p $install_path/mysql/log
sudo chown -R mysql:mysql $install_path/mysql/data# 粘贴配置文件my.cnf 内容见八 中的 my.cnf
cp -f $BASEDIR/config/my.cnf $install_path/mysql/# 安装mysql
$install_path/mysql/bin/mysql_install_db --user=mysql --basedir=$install_path/mysql/ --datadir=$install_path/mysql/data/# 设置文件及目录权限:
cp $install_path/mysql/support-files/mysql.server /etc/init.d/mysqld
sudo chown 777 $install_path/mysql/my.cnf
sudo chmod +x /etc/init.d/mysqldsudo mkdir /var/lib/mysql
sudo chmod 777 /var/lib/mysql# 启动mysql
/etc/init.d/mysqld start# 设置开机启动
chkconfig --level 35 mysqld on
chmod +x /etc/rc.d/init.d/mysqld
chkconfig --add mysqld# 修改环境变量
ln -s $install_path/mysql/bin/mysql /usr/bin
ln -s /var/lib/mysql/mysql.sock /tmp/
cat > /etc/profile.d/mysql.sh<<EOFexport PATH=$PATH:$install_path/mysql/bin
EOFmysqlPw=`sed -n 2p /root/.mysql_secret`
mysqlPwTMP=`sed -n 2p /root/.mysql_secret`1mysql -u$myuser -p$mysqlPw --connect-expired-password -e "SET PASSWORD = PASSWORD('${mypwd}');"echo "******** MYSQL installation completed ********"
install_repo.sh
#! /bin/bash
#
# Author: kangll
# CreateTime: 2024-03-10
# Desc: 配置HDP repo
#set -x
BASEDIR=$(cd "$(dirname "$0")"; pwd)
#
source $BASEDIR/config/global.sh
# HDP tar install path
config_path=$install_path
tar_name=$hdp_tar_namesource /etc/profile > /dev/null 2>&1#ambari server源地址if [ $# -eq 1 ] ;thenambari_server_source=$1
elseambari_server_source=`hostname`
fi###########################
# 配置 HDP repo
###########################
config_repo() {mkdir -p $config_pathif [ ! -d $config_path/hdp ];thensudo mv $BASEDIR/autoDeployFiles/HDP/hdp $config_pathfisudo ln -s $config_path/hdp/ambari /var/www/html/ambarisudo ln -s $config_path/hdp/HDP /var/www/html/HDPsudo ln -s $config_path/hdp/HDP-GPL /var/www/html/HDP-GPLsudo ln -s $config_path/hdp/HDP-UTILS /var/www/html/HDP-UTILSsudo cp -f $BASEDIR/config/repo/*.repo /etc/yum.repos.d/sudo sed -i 's/windp-aio/'"${ambari_server_source}"'/g' /etc/yum.repos.d/*.reposudo yum clean allsudo yum makecachesudo yum repolistecho "********** repo installation completed **********"
}###########################
# 初始化db
###########################
config_db() {mysql -h${myurl} -u${myuser} -p${mypwd} < $BASEDIR/config/init_db.sql mysql -h${myurl} -u${myuser} -p${mypwd} ambari < $BASEDIR/config/Ambari-DDL-MySQL-CREATE.sql
}###########################
# install ambari
###########################
install_ambari() {sudo yum install ambari-server -ysudo mkdir -p /usr/share/java/sudo cp -f $BASEDIR/config/mysql-connector-java.jar /usr/share/java/sudo cat $BASEDIR/config/ambari.properties > /etc/ambari-server/conf/ambari.propertiessudo sed -i 's/localhost/'"${ambari_server_source}"'/g' /etc/ambari-server/conf/ambari.propertiessudo cp -f $BASEDIR/config/password.dat /etc/ambari-server/conf/ambari-server restartambari-server status
}######################################################
# 修改服务 ambari,在安装页面隐藏 无需安装的服务组件
######################################################
config_metainfo_modify(){stack_path=/var/lib/ambari-server/resources/stacks/HDPcat $BASEDIR/config/repo/services/ACCUMULO/metainfo.xml > $stack_path/3.0/services/ACCUMULO/metainfo.xmlcat $BASEDIR/config/repo/services/KAFKA/metainfo.xml > $stack_path/3.1/services/KAFKA/metainfo.xmlcat $BASEDIR/config/repo/services/PIG/metainfo.xml > $stack_path/3.1/services/PIG/metainfo.xmlcat $BASEDIR/config/repo/services/DRUID/metainfo.xml > $stack_path/3.0/services/DRUID/metainfo.xmlcat $BASEDIR/config/repo/services/LOGSEARCH/metainfo.xml > $stack_path/3.0/services/LOGSEARCH/metainfo.xmlcat $BASEDIR/config/repo/services/SUPERSET/metainfo.xml > $stack_path/3.0/services/SUPERSET/metainfo.xmlcat $BASEDIR/config/repo/services/ATLAS/metainfo.xml > $stack_path/3.1/services/ATLAS/metainfo.xmlcat $BASEDIR/config/repo/services/ZEPPELIN/metainfo.xml > $stack_path/3.0/services/ZEPPELIN/metainfo.xml cat $BASEDIR/config/repo/services/STORM/metainfo.xml > $stack_path/3.0/services/STORM/metainfo.xmlcat $BASEDIR/config/repo/services/RANGER_KMS/metainfo.xml > $stack_path/3.1/services/RANGER_KMS/metainfo.xmlcat $BASEDIR/config/repo/services/OOZIE/metainfo.xml > $stack_path/3.0/services/OOZIE/metainfo.xmlcat $BASEDIR/config/repo/services/KNOX/metainfo.xml > $stack_path/3.1/services/KNOX/metainfo.xmlcat $BASEDIR/config/repo/services/SQOOP/metainfo.xml > $stack_path/3.0/services/SQOOP/metainfo.xmlcat $BASEDIR/config/repo/services/SMARTSENSE/metainfo.xml > $stack_path/3.0/services/SMARTSENSE/metainfo.xmlambari-server restart
}
config_repo
config_db
install_ambari
config_metainfo_modify
这篇关于【Ambari】Ansible自动化部署大数据集群的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







