本文主要是介绍Struts2、jquery OCUpload、Apache POI、pinyin4J实现excel数据导入功能,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Struts2、jquery OCUpload、Apache POI、pinyin4J实现excel数据导入功能
- 一、前端实现
- 1.1 将js文件引入页面
- 1.2 在页面中提供任意一个元素
- 1.3 调用插件提供的upload方法,动态修改HTML页面元素
- 1.4 效果展示
- 二、服务端实现
- 2.1 接收客户端上传的文件
- 2.2 解析提交的xml文件
excel数据导入,提交图片或文件等式每一个平台必备的功能,本文以导入excel数据为例,将述在ssh框架下的数据导入功能的实现
一、前端实现
前端数据导入功能采用的是jquery OCUpload方法,即基于jQuery的OCUpload(One Click Upload)一键上传插件,优点是简单易实现
1.1 将js文件引入页面
jquery-1.8.3.js
jquery.ocupload-1.1.2.js
1.2 在页面中提供任意一个元素
<input type="button" name="regionFile" id="myButton" value="导入"/>
任意元素即可,不局限于是按钮
1.3 调用插件提供的upload方法,动态修改HTML页面元素
<script type="text/javascript">$(function(){//页面加载完成后,调用插件的upload方法,动态修改了HTML页面元素$("#myButton").upload({action:'xxx.action',name:'myFile'});});
</script>1.4 效果展示
此时可以在浏览器中通过查看页面元素看到自动补充的元素的信息
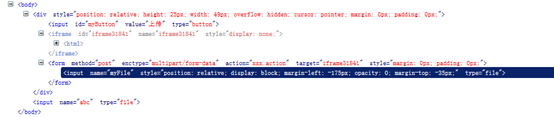
二、服务端实现
2.1 接收客户端上传的文件
Struts2框架可以通过属性驱动直接接收前端页面传递的文件
注意:属性驱动的名称一定要和提交的name属性名一样
//属性驱动,接收上传的文件private File regionFile;public void setRegionFile(File regionFile) {this.regionFile = regionFile;}
2.2 解析提交的xml文件
采用Apache提供的POI技术
Apache POI是Apache软件基金会的开放源码函式库,POI提供API给Java程序对Microsoft Office格式档案读和写的功能
对应的包有:
import org.apache.poi.hssf.usermodel.HSSFSheet;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.ss.usermodel.Row;
实现代码如下:
public String importXls() throws Exception{List<Region> regionList = new ArrayList<Region>();//使用POI解析Excel文件HSSFWorkbook workbook = new HSSFWorkbook(new FileInputStream(regionFile));//根据名称获得指定Sheet对象HSSFSheet hssfSheet = workbook.getSheet("Sheet1");//遍历每一行,取出其中的值,存到list集合中for (Row row : hssfSheet) {int rowNum = row.getRowNum();//第一行为标题行,不要if(rowNum == 0){continue;}//取出每行的数据String id = row.getCell(0).getStringCellValue();String province = row.getCell(1).getStringCellValue();String city = row.getCell(2).getStringCellValue();String district = row.getCell(3).getStringCellValue();String postcode = row.getCell(4).getStringCellValue();//包装一个区域对象Region region = new Region(id, province, city, district, postcode, null, null, null);province = province.substring(0, province.length() - 1);city = city.substring(0, city.length() - 1);district = district.substring(0, district.length() - 1);String info = province + city + district;//pinyin4J可以将汉字生成对应的拼音,简称和全程String[] headByString = PinYin4jUtils.getHeadByString(info);String shortcode = StringUtils.join(headByString);//城市编码---->>shijiazhuangString citycode = PinYin4jUtils.hanziToPinyin(city, "");region.setShortcode(shortcode);region.setCitycode(citycode);regionList.add(region);}//调用service,批量保存regionService.saveBatch(regionList);return NONE;}
扩展:方法中使用了pinyin4J,主要是根据汉字生成对应拼音的全称和简称
简称:
String[] headByString = PinYin4jUtils.getHeadByString(info);
全称:
String citycode = PinYin4jUtils.hanziToPinyin(city, "");
这篇关于Struts2、jquery OCUpload、Apache POI、pinyin4J实现excel数据导入功能的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



