本文主要是介绍Azkaban集群模式部署详细教程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
序言
Azkaban是一个用于工作流程调度和任务调度的开源工具,它可以帮助用户轻松地管理和监控复杂的工作流程。Azkaban的架构设计旨在提供高度可扩展性和可靠性,同时保持易用性和灵活性。
Azkaban的架构可以分为三个主要组件:Executor、Web Server和db数据库。Executor是执行实际工作的节点,WebServer是用于用户交互的接口,数据库用于存储工作流程和任务的元数据信息。
(1)Executor
Executor是Azkaban的工作节点,负责执行工作流程中定义的任务。每个Executor节点可以同时执行多个任务,通过与Web Server的通信来获取任务的执行信息和结果,Executor节点可以根据需要动态扩展,以满足不同规模和性能需求。同时,Executor节点可以配置不同的资源限制,以确保任务执行的稳定性和可靠性。
(2)Web Server
Web Server是Azkaban的用户界面,用户可以通过Web界面来管理和监控工作流程。Web Server提供了创建、编辑、删除工作流程的功能,同时也可以查看任务的执行情况和日志信息。 Web Server与Executor节点之间通过HTTP协议进行通信,通过RESTAPI来传递任务的执行信息和结果。Web Server还可以通过WebSocket实时监控任务的执行进度和状态。
(3)db数据库
数据库是Azkaban的元数据存储,用于保存工作流程和任务的定义信息。数据库中包含了工作流程的依赖关系、任务的执行状态和日志信息等。
Azkaban支持多种数据库,如MySQL、PostgreSQL等,用户可以根据自己的需求选择合适的数据库存储方式。数据库的高可用性和性能也是保证系统稳定性的重要因素。
1. 集群模式设计
准备4台服务器 hadoop101、hadoop102、hadoop103、hadoop104
4台服务器的分工:
hadoop101: Web Server、Executor Server
hadoop102: Executor Server
hadoop103:Executor Server
hadoop104:MySQL数据库
2. Azkaban安装文件的准备
包含:azkaban-db、azkaban-web-server、azkaban-exec-server 三个模块的安装文件,例如:

上述对用三个文件的创建方式,请参考如下连接:
Azkaban下载/安装及单机版配置详细教程-CSDN博客
2.1 在hadoop101服务器上创建/usr/local/software/azkaban 目录,将以上相关的三个文件下载到此目录下:

2.2 解压三个文件并重命名
 3. 配置MySQL数据库
3. 配置MySQL数据库
3.1 MySQL数据库安装,请参考如下连接:
CentOS7下MySQL-8.1.0 数据库下载及安装_centosxiazaishujvku-CSDN博客
3.2 登录MySQL数据库,创建azkaban数据库
create database azkaban;

3.3 创建azkaban用户并设置权限
create user 'azkaban'@'%' identified by '123456';
Grant SELECT,INSERT,UPDATE,DELETE ON azkaban.* to 'azkaban'@'%' WITH GRANT OPTION;

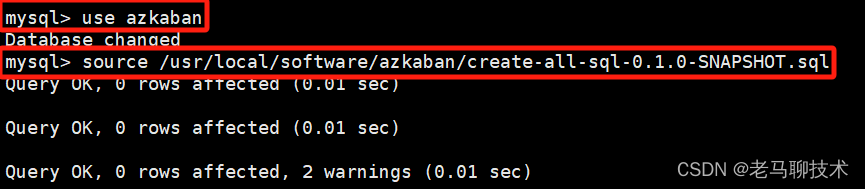
3.4 切换 azkaban数据库,并在数据库中导入azkaban表(create-all-sql-xxx.sql)
备注:create-all-sql-xxx.sql 文件 在 azkaban-db 文件夹中,如下: 
 3.5. 更改MySQL包大小:防止Azkaban连接MySQL阻塞
3.5. 更改MySQL包大小:防止Azkaban连接MySQL阻塞
修改 /etc/my.cnf 文件,在[mysqld] 下面添加 max_allowed_packet = 1024M
3.6. 重启MySQL数据库
systemctl restart mysqld
4. 配置Executor Server
Azkaban Executor Server 处理工作流和作业的实际执行
4.1 修改:/azkaban-executor/conf/azkaban.properties ,修改内容如下:
default.timezone.id=Asia/Shanghai
azkaban.webserver.url=http://hadoop101:8081
executor.port=12321
database.type=mysql
mysql.port=3306
mysql.host=192.168.170.100
mysql.database=azkaban
mysql.user=azkaban
mysql.password=123456
mysql.numconnections=100
备注:executor.port 设置 executor server的端口号,因为executor.port不指定的话,每次executor.port 会随机生成,使用时特别不方便
4.2 将配置好的 azkaban-executor 文件,复制到 hadoop102、hadoop103 服务器上
scp -r azkaban-exec/ root@192.168.170.102:/usr/local/software/azkaban/
scp -r azkaban-exec/ root@192.168.170.103:/usr/local/software/azkaban/
4.3 分别启动三台服务器的 executor server,进入到 azkaban-exector 根目录,进行执行:
bin/start-exec.sh
并通过jps 查看进程 
备注:(1) azkaban-exec 项目中自带的是mysql 5.x 的驱动,如果你使用的mysql版本是8.x 的版本,则需要将 mysql 8.x的驱动包,复制到 azkaban-exec/lib 目录下,并将自带的mysql5.x 版本的驱动包删除掉
(2)azkaban-exec 启动成功之后,在azkaban-exec目录下生成 executor.port 文件
4.4 激活每台executor服务器
分别在三台服务器上执行如下命令:
curl -G "hadoop101:12321/executor?action=activate" && echo
curl -G "hadoop102:12321/executor?action=activate" && echo
curl -G "hadoop103:12321/executor?action=activate" && echo
效果如下:
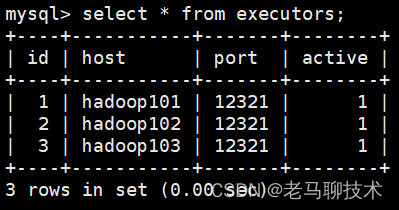
![]()
激活之后,可以在azkaban对应的数据库中的executors表中查看到激活的executor节点的信息,active 表示该节点服务器是否被激活,其实只要当你的executor 服务器启动之后,该表就会添加一条对应的信息,只不过active的数据是0,未激活的状态,激活之后active的数据变为1.
到此 Azkaban的Executor Server 已经配置与启动成功。
关闭服务使用的是:bin/shutdown-exec.sh
5. 配置 Web Server
Azkaban Web Server 是处理项目管理、身份验证、计划和执行触发。
当前案例 Web Server只是在 hadoop101 上进行配置
5.1 配置/修改 azkaban.properties 文件
default.timezone.id=Asia/Shanghai
mysql.port=3306
mysql.host=192.168.170.100
mysql.database=azkaban
mysql.user=azkaban
mysql.password=123456
azkaban.executorselector.filters=StaticRemainingFlowSize,CpuStatus
备注:azkaban.executorselector.filters 表示执行选择器的过滤器
StaticRemainingFlowSize:正在排队的任务数
CpuStatus:CPU占用情况
MininumFreeMemory:内存占用情况。测试环境,必须将MininumFreeMemory删除掉,否则它会认为集群资源不够,不执行。
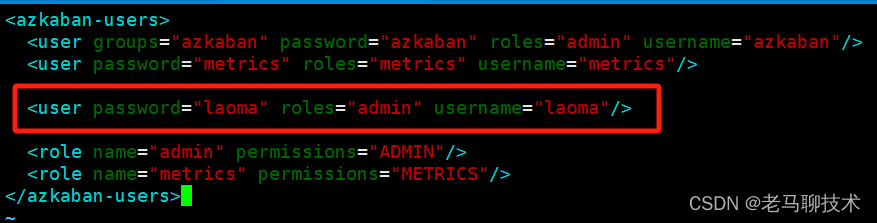
5.2 修改azkaban-users.xml 文件
添加 laoma 用户 并设置密码为 laoma,角色设置为 admin
5.3 azkaban-web 项目中自带的是mysql 5.x 的驱动,如果你使用的mysql版本是8.x 的版本,则需要将 mysql 8.x的驱动包,复制到 azkaban-web/lib 目录下,并将自带的mysql5.x 版本的驱动包删除掉
5.4 启动 Web Server
进入到 azkaban-web 的根目录下执行:bin/start-web.sh 并通过 jps 查看进程

5.5 通过浏览器访问azkaban web服务
http://192.168.170.101:8081

登录刚才设置的用户,例如我刚才设置的用户名:laoma 密码:laoma
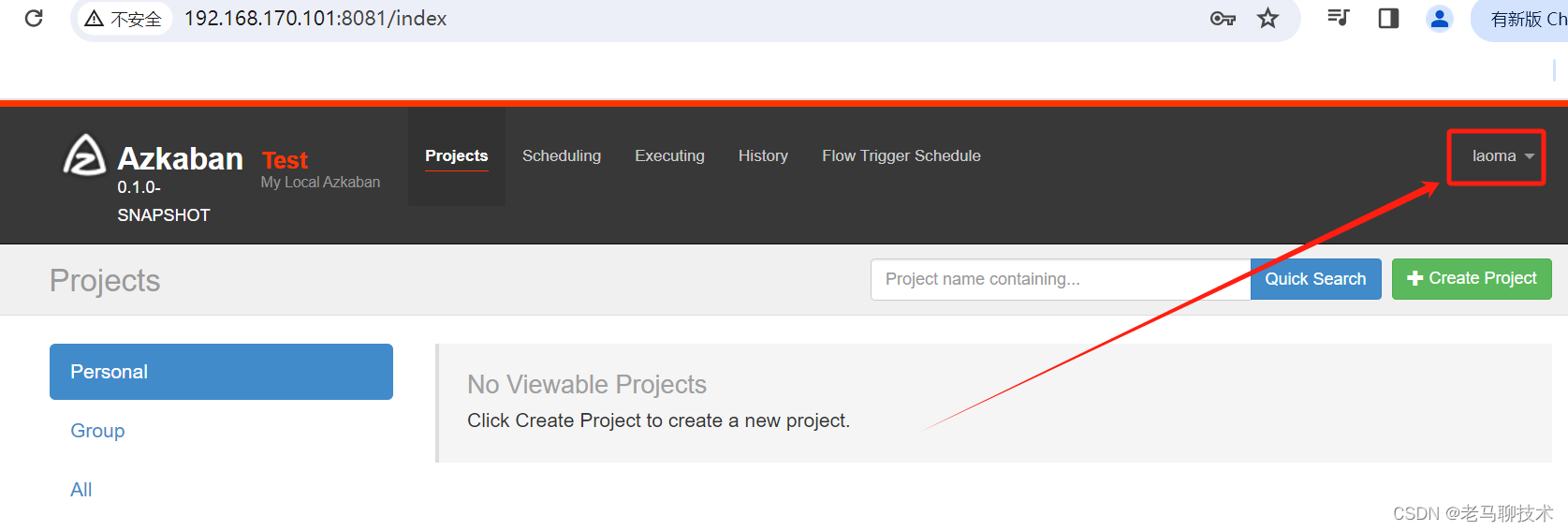
登录成功!
5.6 关闭web Server 命令
bin/shutdown-web.sh
至此 Web Server 配置成功!
至此,Azkaban集群模式配置完美结束!
这篇关于Azkaban集群模式部署详细教程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






