本文主要是介绍深入理解Armv9 DSU-110中的L3 cache,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
快速链接:
- 【精选】ARMv8/ARMv9架构入门到精通-[目录] 👈👈👈
关键词: DynamIQ cluster、DSU-110、DSU-120、DSU、cache、mmu、缓存、高速缓存、内存管理、MPAM
思考:
1、L1、L2、L3 cache的替换策略是怎样的?
2、什么类型的内存永远不会进L3 cache?
3、L3 cache一般都是多大?
4、L3 cache的组织形式一般是怎样的?
5、什么是cache partitioning?
6、DSU、DSU-110、DSU-120有什么区别?
7、什么MPAM? 有什么作用?
8、什么是Cache stashing?
9、什么是Cache slices? 有什么好处?
在共享DSU-110 DynamIQ cluster中,所有core共享L3缓存。
注意:以下功能在此版本中不受支持,计划在后续版本中支持:
- 从CHI接口和加速器一致性端口(ACP)接口进行的缓存存储(stashing)。
DSU-110的共享L3缓存提供以下功能:
- (1)动态优化的缓存分配策略,通常是互斥的。这种缓存分配策略意味着在正常使用中,一行数据要么位于一个或多个核心(或complexes)的缓存中,要么位于L3缓存中,但不会同时存在于两个缓存中。只有可缓存的、可共享的内存位置才会被分配到L3缓存中。不可共享的内存位置不会被分配到L3缓存中。
- (2)可以通过内存系统资源分区和监视(MPAM)体系结构扩展将缓存路组分区并分配给进程。缓存分区确保每个进程不会主导缓存的使用,以不利于其他进程。
- (3)支持来自ACP和CHI接口的存储请求。这些存储请求也可以针对集群中核心或complexes的任何L2缓存。
- (4)对缓存数据和标签RAM提供纠错码(ECC)保护。
- (5)缓存可以实现最多八个缓存切片( cache slices),取决于指定的L3缓存大小。缓存切片可以增加L3缓存的带宽并改善物理布局。每个缓存切片包括数据、标签、牺牲和嗅探过滤器RAM以及相关的逻辑(data, tag, victim, and snoop filter RAMs and associated logic)。
在关机时,DSU-110会自动执行cache cleaning操作,无需进行由软件控制的缓存清理。
1 L3 cache allocation policy
DSU-110 L3缓存只允许存储可缓存的、可共享的内存位置。Non-shareable的内存不能被分配到L3缓存中。
DSU-110 L3缓存采用动态优化的缓存分配策略,通常是互斥的。这种缓存分配策略意味着在正常使用中,一行数据要么位于一个或多个核心(或complexes)的缓存中,要么位于L3缓存中,但不会同时存在于两个缓存中。
当数据只分配给一个核心或complexes时,使用独占分配。有时,当数据在多个核心或complexes之间共享时,会使用Inclusive分配。
- 来自core0的初始请求将数据分配到L1或L2缓存,但不分配到L3缓存。
- 当从core0驱逐数据时,被驱逐的数据会分配到L3缓存。这个缓存行的分配策略仍然是独占的。
- 如果core0重新获取该行,它将分配到核心0的L1或L2缓存中,并从L3缓存中删除。这个缓存行的分配策略仍然是独占的。
- 如果core1访问该行以进行读取,那么它仍然分配给核心0。它还会分配到核心1和L3缓存中。在这种情况下,该行采用Inclusive分配,因为它在多个核心之间共享。
2 可用的缓存路组数量
每个缓存切片中可用的缓存路组数量取决于您选择实现的L3缓存大小。
当选择2的幂次方L3缓存大小,如256KB、512KB、1024KB、2MB、4MB、8MB或16MB时,每个缓存切片具有16个缓存路组。
当选择非2的幂次方L3缓存大小,如1536KB、3MB、6MB或12MB时,每个缓存切片仅具有12个缓存路组。
3 L3缓存分区(partitioning)
L3缓存支持一种分区方案,可以改变替换(victim)选择策略,以防止进程占用整个L3缓存,对其他进程造成不利影响。
缓存分区适用于特殊的软件,其中有不同缓存访问模式的不同类别进程在运行。例如,两个进程A和B在同一个cluster的不同核心上运行,因此共享L3缓存。如果进程A比进程B更具数据密集性,那么进程A可能导致进程B分配的所有缓存行都被驱逐。驱逐这些已分配的缓存行可能降低进程B的性能。
DynamIQ Shared Unit-110(DSU-110)使用Memory System Resource Partitioning and
Monitoring(MPAM)体系结构扩展来分区L3缓存。MPAM是一种旨在将内存系统性能划分给软件的体系结构扩展。因此,MPAM提供了广泛的可选功能,如缓存分区、带宽分区和进程监视。DSU-110仅使用MPAM来分区L3缓存。
MPAM要求系统传递MPAM ID,各core绑定到每个内存系统事务(transaction)。虽然MPAM ID的结构是架构性的,但其组件的配置是实现定义的。DSU-110使用以下MPAM ID结构:
• MPAM_NS字段,1 BIT,指示此事务是否安全或非安全。
• PARTID,6 BIT,是当前事务的软件分配的分区标识符。这支持在非安全空间中最多64个PARTID,在安全空间中最多8个PARTID。虽然单个进程最多可以使用2个PARTID,一个用于指令获取,一个用于数据访问,但也可以由多个进程共享单个PARTID。MPAM_NS位指示此事务是否需要安全或非安全PARTID。如果此事务需要安全PARTID,则仅使用PARTID的低3位。
• PMG,1 BIT,标识性能监视组(Performance Monitoring Group),用于MPAM提供分区的细粒度监视,DSU-110不使用此功能。
当启用L3_MPAM_STORAGE参数时,L3缓存存储此MPAM ID信息,可以在驱逐时检索。
注意:通常,只有在存在下游缓存(downstream cach),如系统缓存,也支持MPAM时才需要此设置。
如果未存储MPAM ID,则任何L3驱逐都将使用引起驱逐的事务的MPAM ID。
注意:如果将事务映射到未设置MPAMCFG_CPBM设置的分区,则不会将此事务分配到L3缓存中。
L3缓存的分区是通过缓存路组的方式进行的,对于DSU-110,每个组包含两个路组,因此最多支持8个分区。
- 不是2的幂次方的缓存大小(1.5MB、3MB、6MB和12MB)支持的缓存路组较少,因为它们具有较少的可用路组。
- 如果某些缓存路组被关闭(更多细节请参见第58页的5.4.1节L3缓存RAM关机),则每个L3缓存分区中的路组数量会减少。这种缓存路组的减少可能会降低性能,当进程没有足够的路组可用时。因此,Arm建议在使用缓存分区时谨慎关闭缓存路组。
MPAM作为一种架构扩展的优点之一是它定义了一种通用机制,用于分割L3缓存,因此可以很容易地通过标准软件进行交互和配置。
缓存分区允许您将L3缓存分割为最多8个独立的分区。然而,您可以自由地定义所需的分区数量,也可以重叠分区。例如,您可以将路组0到4分配给分区0,然后将路组0到8分配给分区1。这意味着分配给分区1的进程可以使用所有路组,而分配给分区0的进程只能使用一半的路组。
4 缓存存储
缓存存储允许外部代理请求将一行数据带入(或存储)到簇中的缓存中。
DynamIQ™ Shared Unit-110(DSU-110)不能执行cache stashing部分,响应如下:
- DSU-110永远不会发送SnpResp*_Read响应。
- 对于SnpMakeInvalidStash,DSU-110将以SnpResp_I响应。
- 对于SnpStashUnique和SnpStashShared,DSU-110将以SnpResp_I、SnpResp_SC或SnpResp_UC之一响应。
- 对于SnpUniqueStash,DSU-110将在需要的情况下返回数据。因此,它将返回SnpRespData_I或SnpResp_I。
DSU-110不执行加速器一致性端口(ACP)事务的缓存存储部分。这些事务被视为等效的非缓存存储事务。
5 L3缓存数据RAM延迟
DSU-110 L3数据RAM接口可以实现在输入和输出路径上具有可配置的延迟。
以下选项可供选择:
- 输入路径到L3数据RAM的写入延迟可以是1个周期(默认)或2个周期。
- 从L3数据RAM的输出路径到达的读取延迟可以是2个周期(默认)或3个周期。
- 当配置了输出路径上的3个周期读取延迟时,输入路径上可以选择2p的写入延迟选项。
这个2p的写入延迟还可以使RAM输入信号在额外的周期内保持稳定,允许在RAM输入上进行额外的保持时间。 - L3数据RAM的输出端口上可以选择一个可选的寄存器切片。
在输入路径上,如果请求了2或2p的写入延迟,则RAM时钟使能会进行流水线处理,并且对所有其他RAM输入信号应用多周期路径。
在输出路径上,2个周期的读取延迟和3个周期的读取延迟会对所有RAM输出信号应用多周期路径。可选寄存器切片的输出是单周期的,绝不能应用多周期路径。
下图显示了L3数据RAM的时序图。
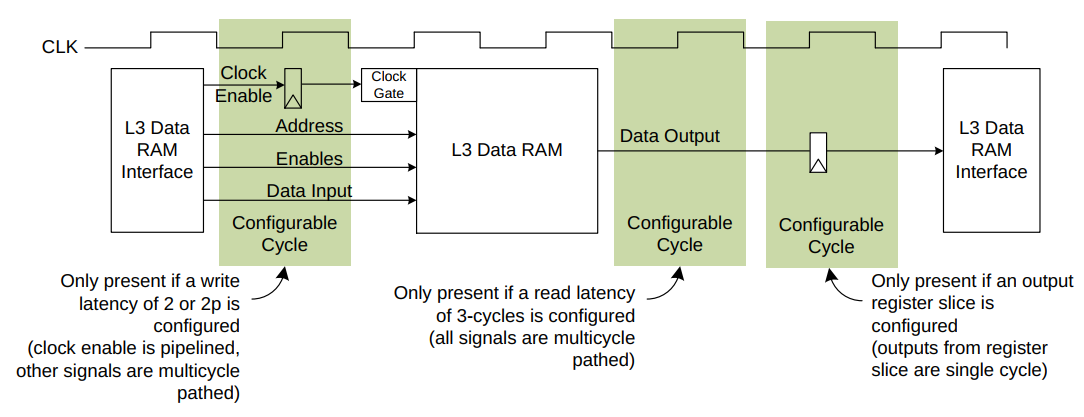
RAM延迟的增加会增加L3命中延迟,从而降低性能。因此,只有在RAM无法满足2个周期延迟的时序要求时才使用3个周期读取延迟选项。但是,如果仅仅是从RAM到SCU逻辑的导线路由延迟无法满足这个时序要求,那么应该使用寄存器切片。
延迟选项仅针对L3数据RAM进行了指定,因为L3标签RAM和SCU嗅探过滤器RAM满足1个周期的输入和1个周期的输出时序要求。
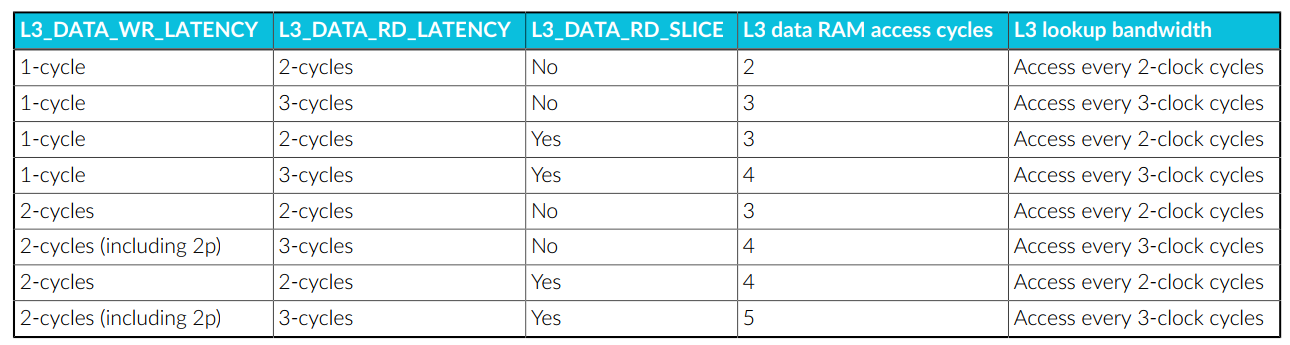
以下表格描述了不同延迟配置参数对L3数据RAM性能的影响:
6 缓存切片和分区
DynamIQ™ Shared Unit-110(DSU-110)的L3缓存可以分为最多八个相同的切片,每个切片包含256KB到2MB的缓存。一个缓存切片包括数据RAM、tag RAM、替换RAM和snoop RAM以及相关逻辑。一个分区是对缓存切片中的RAM的进一步细分。
对于每个缓存切片,数据RAM和标签RAM都被细分为两个分区。
下图显示了单个和双缓存切片配置之间的差异。
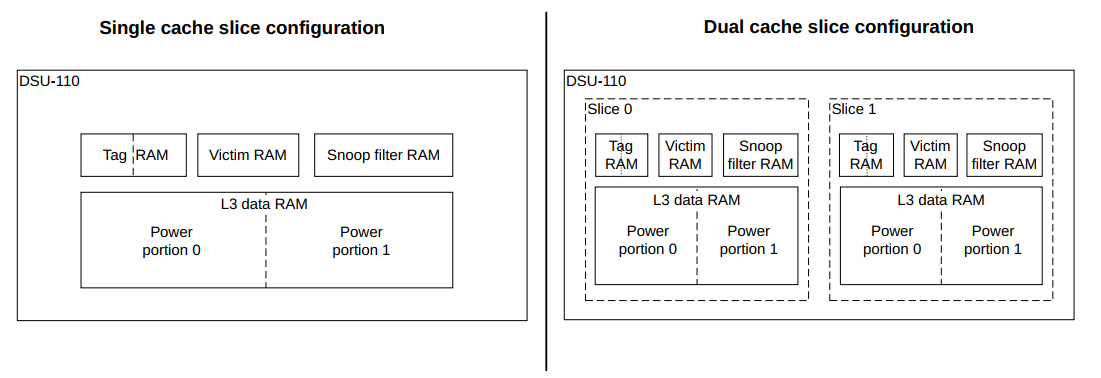
将L3缓存分割成切片提供了以下优点:
- 在实现宏单元时改善物理布局,通过确保RAM位于控制它们的逻辑附近。
- 增加带宽,因为可以并行访问这些切片。
6.1 Cache slice and master port selection
对于具有多个缓存切片的实现,请求会根据地址和内存属性发送到特定的切片。
地址到切片的映射不可配置,但地址到master port的映射是可配置的,并且可以独立于切片映射。
关注"Arm精选"公众号,备注进ARM交流讨论区。

这篇关于深入理解Armv9 DSU-110中的L3 cache的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







