本文主要是介绍卫星遥感影像统计农业产量、作物分类及面积,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
卫星遥感技术的广泛应用为农业领域带来了巨大的变革,其中,卫星遥感影像在农业产量估算方面的应用正成为一项关键技术。通过高分辨率的遥感数据,农业生产者可以更准确、及时地了解农田状况,实现精准农业管理,提高产量和经济效益。
**1. 影像获取与数据处理**
卫星遥感影像作为获取农田信息的工具,具有全球覆盖、高时空分辨率的特点。农业产量估算通常以多光谱和高光谱影像为基础,这些影像能够捕捉植被的光谱特征,提供关键的农田信息。通过卫星影像数据的预处理、几何校正和大气校正等步骤,确保数据的质量和可用性。
**2. 植被指数与生长监测**
植被指数(如NDVI)是衡量植被健康和生长状态的关键指标。利用卫星遥感影像,可以计算植被指数并监测植被的生长变化。这为农业产量估算提供了有力的支持,因为植被的健康状态直接关系到作物的生长和产量。
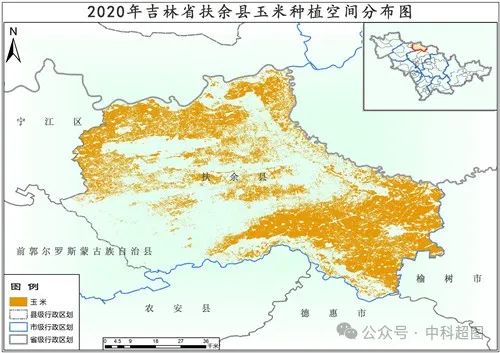
**3. 作物分类与面积统计**
卫星遥感影像处理中的作物分类技术能够将农田中的不同植被类型进行区分,从而准确估算各类作物的种植面积。结合地理信息系统(GIS)技术,可以实现对不同地块的面积统计,为产量估算提供空间分布信息。
**4. 时序影像分析**
通过获取多个时期的卫星遥感影像,可以进行时序影像分析,了解作物在不同生长阶段的发育情况。这种时间序列的监测使农业生产者能够更好地掌握作物的生长趋势,及时调整农业管理措施,最大限度地提高产量。
**5. 遥感数据与气象数据融合**
将卫星遥感数据与气象数据融合,可以更全面地了解影响农业产量的因素,如降水、温度等。这种综合分析有助于建立产量模型,为农业生产提供科学依据。
**6. 精准施肥和灌溉管理**
卫星遥感影像不仅能够提供作物生长状态信息,还可以指导精准施肥和灌溉管理。通过对不同地块的植被指数分析,农业生产者可以有针对性地调整施肥和灌溉策略,避免资源浪费,提高产量。

看更多优质内容,享更多地理资源
关注中科超图 星标我们!🌟
这篇关于卫星遥感影像统计农业产量、作物分类及面积的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







