本文主要是介绍SpringBoot 使用sharding jdbc进行分库分表,基于4.0版本,Springboot2.1,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
之前写过一篇使用sharding-jdbc进行分库分表的文章,https://blog.csdn.net/tianyaleixiaowu/article/details/70242971,当时的版本还比较早,现在已经不能用了。这一篇是基于最新版来写的。新版已经变成了shardingsphere了,https://shardingsphere.apache.org/。
有点不同的是,这一篇,我们是采用多数据源,仅对一个数据源进行分表。也就是说在网上那些jpa多数据源的配置,用sharding jdbc一样能完成。
也就是说我们有两个库,一个库是正常使用,另一个库其中的一个表进行分表。
老套路,我们还是使用Springboot进行集成,在pom里确保有如下引用。
<sharding-sphere.version>4.0.0-RC1</sharding-sphere.version><!-- 分库分表--><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>${sharding-sphere.version}</version></dependency><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-core-common</artifactId><version>${sharding-sphere.version}</version></dependency><!-- 分库分表 end--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency>spring:application:name: t3ccprofiles:active: sharding-databases-tables
# datasource:
# primary:
# jdbc-url: jdbc:mysql://${MYSQL_HOST:localhost}:${MYSQL_PORT:3306}/${DB_NAME:dmp_t3cc}?useUnicode=true&characterEncoding=UTF8&serverTimezone=Hongkong
# username: ${MYSQL_USER:root}
# password: ${MYSQL_PASS:root}
# secondary:
# jdbc-url: jdbc:mysql://xxxxxxxxxxxxx/xxxxxx?useUnicode=true&characterEncoding=UTF8&serverTimezone=Hongkong
# username: xxxxx
# password: xxxxxxxjpa:database: mysqldatabase-platform: org.hibernate.dialect.MySQL5InnoDBDialect #不加这句则默认为myisam引擎hibernate:ddl-auto: nonenaming:physical-strategy: org.springframework.boot.orm.jpa.hibernate.SpringPhysicalNamingStrategyopen-in-view: trueproperties:enable_lazy_load_no_trans: trueshow-sql: trueyml里还是老套路,大家注意,我把之前的多数据源的配置给注释掉了,改成使用sharding来完成多数据源。
里面我profiles.active了另一个sharding-databases-tables.yml
db:one: primarytwo: secondary
spring:shardingsphere:datasource:names: ${db.one},${db.two}primary:type: com.zaxxer.hikari.HikariDataSourcejdbc-url: jdbc:mysql://${MYSQL_HOST:localhost}:${MYSQL_PORT:3306}/${DB_NAME:dmp_t3cc}?useUnicode=true&characterEncoding=UTF8&serverTimezone=Hongkongusername: ${MYSQL_USER:root}password: ${MYSQL_USER:root}max-active: 16secondary:type: com.zaxxer.hikari.HikariDataSourcejdbc-url: jdbc:mysql://xxxxxxx:3306/t3cc?useUnicode=true&characterEncoding=UTF8&serverTimezone=Hongkongusername: xxxpassword: xxxxxxmax-active: 16sharding:tables:pt_call_info:actual-data-nodes: ${db.one}.pt_call_info_$->{1..14}table-strategy:inline:sharding-column: todayalgorithm-expression: pt_call_info_$->{today}key-generator:column: idtype: SNOWFLAKEpre_cc_project:actual-data-nodes: ${db.two}.pre_cc_projectpre_cc_biztrack:actual-data-nodes: ${db.two}.pre_cc_biztrack可以看到datasource里,定义了2个数据源,names=primary,secondary,这个名字随便起。之后分别对每个数据源配置了type、url等基本信息。
在sharding里,我针对要被分表的pt_call_info表做了配置,分为14个表pt_call_info_1到pt_call_info_14,分表的原则是根据today这个字段,today为1就分到pt_call_info_1这个表。这也是我这个数据源,唯一要做配置的表。
另外,secondary这个数据源里,也有两个表,但我不想分表,只是当成普通的数据源进行操作。所以,我只是单独列出来他们的表名,并指定actual-data-nodes为第二个数据源的表名。这里是必须要列出来所有表的,无论是否需要分表,不然对表操作时,会报错找不到表。所以需要手工指定。
配完这个yml就ok了,别的什么都不用配了。也不需要像之前的多数据源时,像如下的配置都不用了。不需要指定model和repository的包位置什么的。

当yml配置好后,就可以把两个数据源的model和Repository放在任意的包下,不影响。
无论是对哪个表进行分表,都还是正常定义这个entity就行了。譬如下面就是我用来分表的model,就是个普通的entity。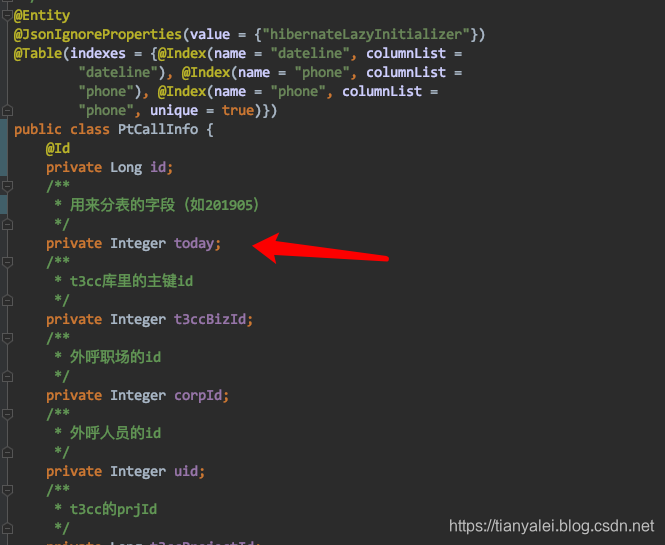
之后手工把表都建好。然后就可以像平时一样操作这个model类了。

@RunWith(SpringRunner.class)
@SpringBootTest
public class T3ccApplicationTests {@Resourceprivate ProjectManager projectManager;@Resourceprivate PtCallInfoManager ptCallInfoManager;@Testpublic void contextLoads() {List<PreCcProject> preCcProjectList = projectManager.findAll();System.out.println(preCcProjectList.size());for (int i = 1; i <= 14; i++) {PtCallInfo ptCallInfo = new PtCallInfo();ptCallInfo.setId((Long) new SnowflakeShardingKeyGenerator().generateKey());ptCallInfo.setToday(i);ptCallInfoManager.add(ptCallInfo);}}}写个测试代码,分别从第二个数据源取值,从第一个数据源插入值,查看分表情况。注意,id是使用特定的算法生成的,避免分表后的主键冲突。
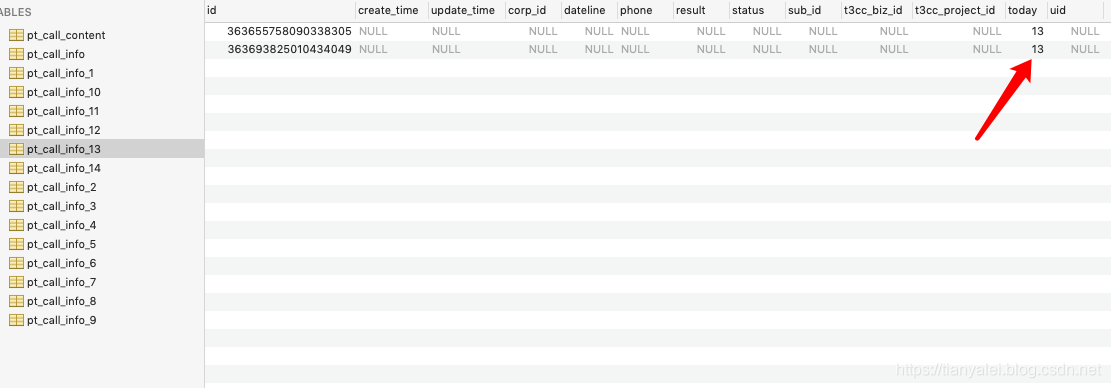
运行后,可以看到分表成功。
需要注意一个坑:不要使用jpa的saveAll功能,在sharding-jdbc中,用单条去添加,如果你用了saveAll,则会失败,插入错误的数据。
这篇关于SpringBoot 使用sharding jdbc进行分库分表,基于4.0版本,Springboot2.1的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





