本文主要是介绍【python】python大学排名数据分析可视化(源码+报告+数据集)【独一无二】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化【获取源码+商业合作】
👉荣__誉👈:阿里云博客专家博主、51CTO技术博主
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。

python大学排名数据分析可视化(源码+报告+数据集)【独一无二】
目录
- python大学排名数据分析可视化(源码+报告+数据集)【独一无二】
- 一、设计要求
- 二、分析展示
- 2.1. 分析中国城市的高校数量分布:
- 2.2.研究内容主要聚焦于学校类型的分布
- 2.3.研究内容聚焦于高等教育中的软科领域排名
- 2.4.研究内容集中于探索学校层次与QS世界排名之间的关系
- 2.5.研究内容聚焦于分析学校的武书连排名与QS世界排名之间的关系
- 2.6.研究内容集中在展示和分析大学数量最多的前十个城市
- 2.7.研究内容专注于分析和展示不同层次的学校在总体中的分布
- 2.8.研究内容集中于分析和展示各个大学校友会的排名情况
- 三、代码讲解
一、设计要求
本课题的研究旨在全面分析中国高等教育的现状和发展,为提升中国高等教育的质量和影响力做出贡献。具体的研究目标包括:
- 高等教育资源分布分析: 通过对中国各个城市的大学数量进行分析,了解中国高等教育资源的地理分布,为教育资源配置和区域教育发展提供数据支持。
- 高校综合实力评估: 分析中国高校的综合排名,揭示各高校在教学、科研、社会服务等方面的综合实力,为相关政策制定和学校发展提供参考。
- 学科领域排名研究: 通过对各大学软科的排名分析,评估中国高校在人文学科、社会科学等领域的研究水平和教育质量,为学科建设和人才培养提供依据。
- 国际合作与发展调查: 探究中国高校的国际合作数量及质量,分析高校在全球学术社区中的地位,为促进国际教育合作和交流提供策略建议。
- 学术论文产出分析: 对中国高校的学术论文数量和质量进行评估,以了解其在推动学术进步和知识创新方面的贡献。
- 校友网络评估: 分析各大学校友会的排名,了解校友网络的强度和活跃度,以评估校友资源对高校发展的潜在贡献。
- 学生质量与成果评价: 通过学生的入学成绩、毕业质量和就业情况,评估中国高等教育在人才培养方面的效果。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 大学排名 ” 获取。👈👈👈
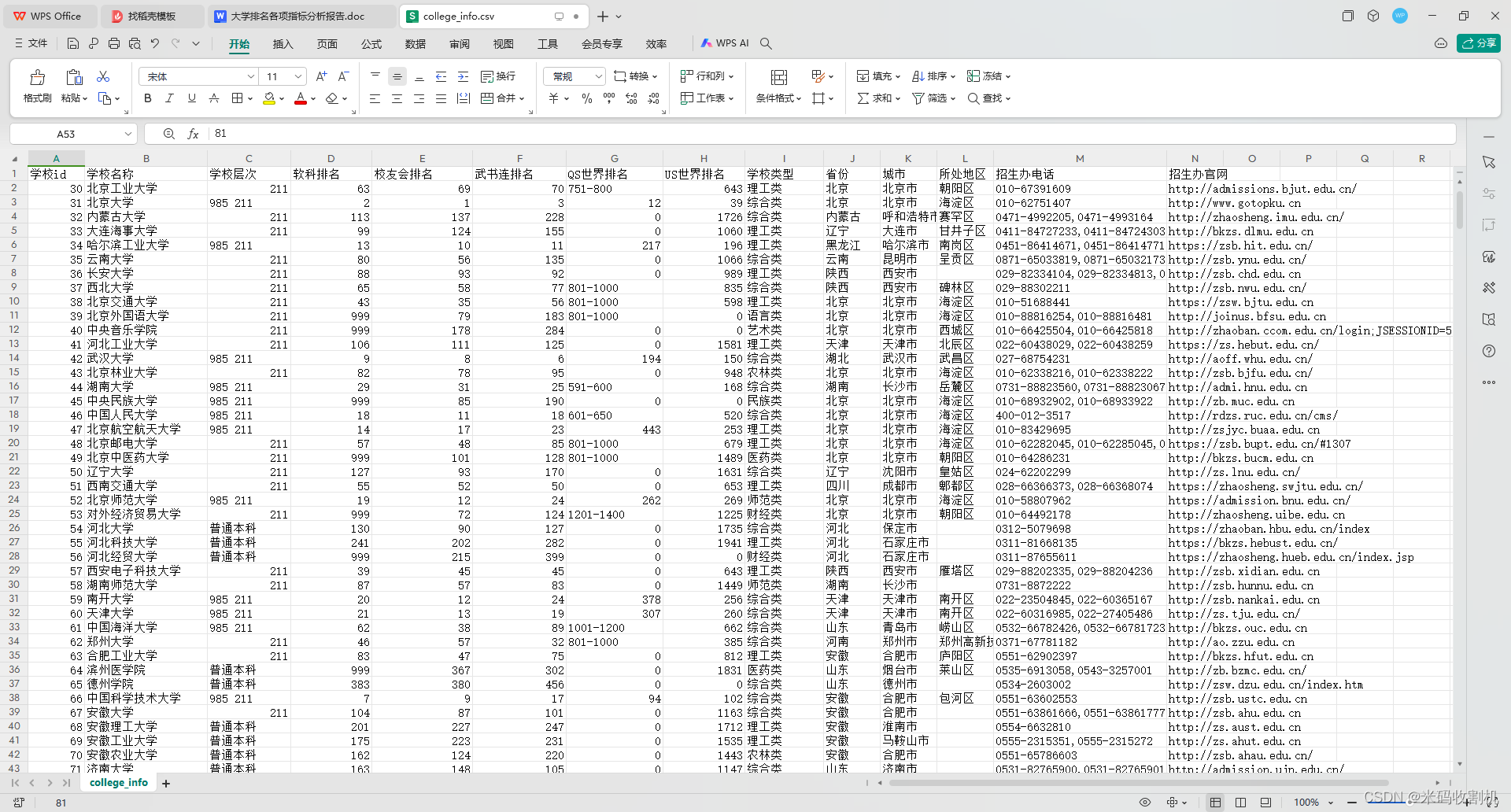
数据集如下:
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 大学排名 ” 获取。👈👈👈
二、分析展示
2.1. 分析中国城市的高校数量分布:
- 通过收集和整理中国各个城市的高校数量数据,编制列表,特别关注大学数量最多的前十个城市。
- 对这些城市的经济、人口、地理位置等基本信息进行探讨,以了解可能影响高校分布的因素。

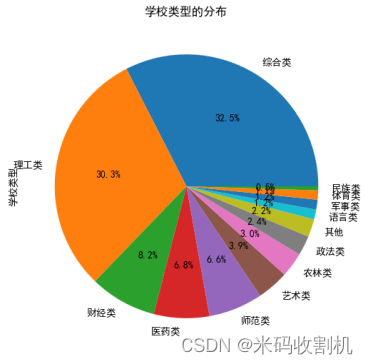
2.2.研究内容主要聚焦于学校类型的分布
在高等教育中,学校类型的多样性是一项重要的资源。不同类型的学校通常具有不同的教育目标,课程设置,和学术研究方向,因此,了解学校类型的分布对于理解整个高等教育系统的多样性和丰富性具有重要意义。
在这个角度,我们使用饼图来展示数据。饼图是一种直观的方式,可以清晰地展示各种类型在总体中所占的比例。每个饼图的切片代表一个特定类型的学校,切片的大小表示该类型学校的数量在总数中所占的比例。
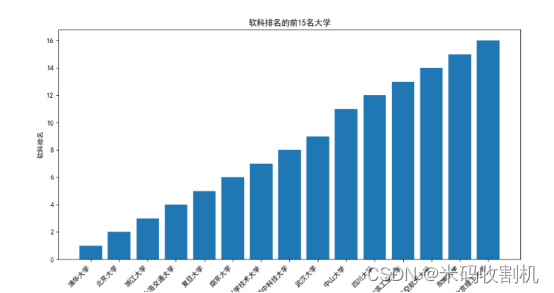
2.3.研究内容聚焦于高等教育中的软科领域排名
特别是软科排名前15名的大学。软科通常包括人文学科和社会科学,这些学科对于培养具有批判性思维、沟通技巧和社会责任感的毕业生至关重要。
在这一角度中,我们使用条形图来展示软科排名前15名的大学。条形图是一种有效的图形表示方式,可以清晰地比较不同项目的数量或者水平。在这个情况下,我们用条形图来展示各大学在软科领域的排名情况。
通过条形图,我们可以清楚地看到每所大学在软科领域的排名,条形的长度表示排名的高低。排名较高的大学条形较长,而排名较低的则较短。这为我们提供了一个直观的视觉比较,能够迅速识别在软科领域表现出色的大学。
此外,通过对比条形图中的条形,我们可以观察到各大学之间在软科排名上的差距。这对于了解不同大学在人文和社会科学领域的实力和声望非常有帮助。对于学生来说,这些信息对于选择适合自己的大学非常重要;而对于教育工作者和政策制定者,了解这些排名可以帮助他们制定更加有效的教育政策和战略。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 大学排名 ” 获取。👈👈👈
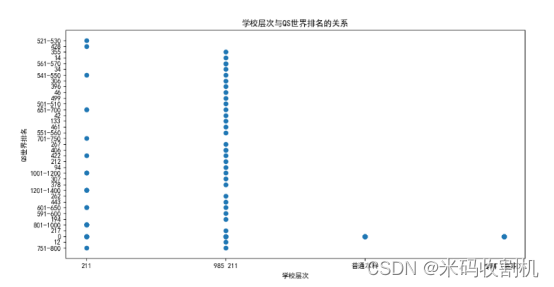
2.4.研究内容集中于探索学校层次与QS世界排名之间的关系
学校层次在中国通常是根据一系列政府支持的项目(如985工程、211工程等)来划分的,这些项目的目标是提升高等教育的质量和国际竞争力。而QS世界排名则是国际上广泛认可的大学排名,它根据学术声誉、雇主声誉、师生比等因素对全球高等教育机构进行排名。
在这个角度中,使用散点图来分析学校的层次与QS世界排名之间的关系。散点图是一种非常有效的图表,它通过在二维空间中表示数据点来展示两个变量之间的关系。在这里,一个轴表示学校层次,另一个轴表示QS世界排名。
通过分析散点图,我们可以探寻学校层次与QS世界排名之间是否存在某种关联。例如,如果985工程的学校在图上聚集在QS排名的较高位置,那么这可能意味着985工程的学校在国际上有更高的声誉和表现。
2.5.研究内容聚焦于分析学校的武书连排名与QS世界排名之间的关系
武书连排名是中国大陆的一种大学排名,而QS世界排名是国际上广泛认可的大学排名。武书连排名主要关注中国大陆的大学,侧重于学术研究、社会服务和就业情况,而QS世界排名则更加全面地考虑全球高等教育机构的学术声誉、雇主声誉、师生比等因素。
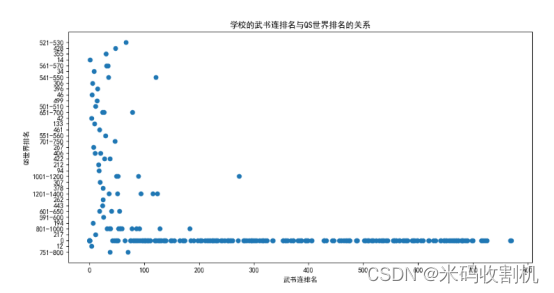
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 大学排名 ” 获取。👈👈👈
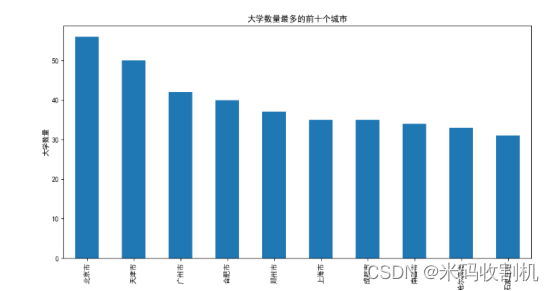
2.6.研究内容集中在展示和分析大学数量最多的前十个城市
为了直观地展示这些数据,我们使用条形图作为图表类型。条形图能够清晰地展示每个城市的大学数量,使读者能够快速比较和判断哪些城市在高等教育领域的集聚程度较高。
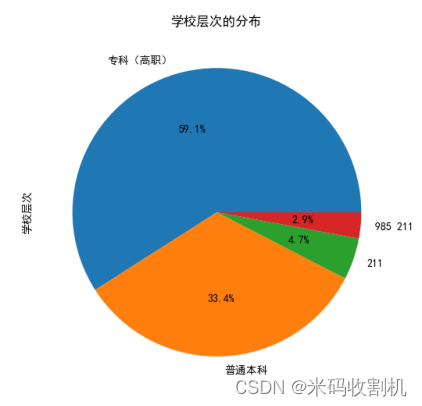
2.7.研究内容专注于分析和展示不同层次的学校在总体中的分布
为了使数据可视化更为直观和易于理解,我们选择使用饼图来展示这些信息。饼图是一种常见的图表类型,适用于展示各个类别在总体中的相对比例。
在饼图中,每个层次的学校(如985工程、211工程、普通本科等)被表示为饼图的一个扇区。扇区的面积与该类别在总体中所占的比例成正比。通过观察各个扇区的大小,我们可以直观地了解各个学校层次在总体中的分布情况。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 大学排名 ” 获取。👈👈👈
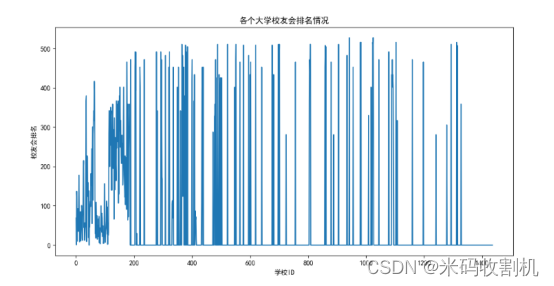
2.8.研究内容集中于分析和展示各个大学校友会的排名情况
为了更加直观地表现校友会排名的变化和差异,我们选择使用折线图来呈现这些数据。折线图是一种常见的图表类型,适合用于展示数据点之间的趋势和关系。
在折线图中,横轴表示不同的大学,而纵轴表示校友会的排名。每个大学的校友会排名以数据点的形式表示,数据点之间通过线段相连。这样的展示方式便于观察各个大学校友会排名的变化和趋势。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 大学排名 ” 获取。👈👈👈
三、代码讲解
使用Python进行数据分析和可视化的工程,专注于对大学相关信息的分析。它使用了matplotlib和pandas等三方。具体来说,各个代码块的功能如下:
-
导入库:
import matplotlib.pyplot as plt import pandas as pd这部分代码导入了matplotlib(一个绘图库)和pandas(一个数据处理库),用于后续的数据处理和图形绘制。
-
读取CSV文件:
data = pd.read_csv("college_info.csv")使用pandas读取名为"college_info.csv"的文件,这个文件可能包含了大学的各种信息,如省份、学校类型、排名等。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 大学排名 ” 获取。👈👈👈
-
解决中文显示问题:
plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False设置matplotlib参数,以确保图表中可以正常显示中文和负号。
-
角度1 - 各个省份的大学数量:
data['省份'].value_counts().plot(kind='bar')统计每个省份的大学数量,并通过条形图展示。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 大学排名 ” 获取。👈👈👈
-
角度2 - 学校类型的分布:
data['学校类型'].value_counts().plot(kind='pie', autopct='%1.1f%%')展示不同学校类型的分布情况,使用饼图并显示每个类型的百分比。
-
角度3 - 各大学软科排名的前15名:
top_15_soft_ranking = data.sort_values(by='软科排名').head(15)对数据按照“软科排名”进行排序,并提取排名前15的大学,之后通过条形图显示。
-
角度4 - 学校层次与QS世界排名的关系:
plt.scatter(data['学校层次'], data['QS世界排名'])通过散点图探索学校层次与QS世界排名之间的关系。
-
角度5 - 学校的武书连排名与QS世界排名的关系:
plt.scatter(data['武书连排名'], data['QS世界排名'])类似于角度4,这部分探索武书连排名和QS世界排名之间的关系。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 大学排名 ” 获取。👈👈👈
-
角度6 - 大学数量最多的前十个城市:
data['城市'].value_counts().head(10).plot(kind='bar')显示拥有最多大学的前十个城市,通过条形图表示。
-
角度7 - 学校层次的分布:
data['学校层次'].value_counts().plot(kind='pie', autopct='%1.1f%%')通过饼图展示不同学校层次的分布情况。
-
角度8 - 各个大学校友会排名情况:
data['校友会排名'].plot(kind='line')使用折线图显示不同大学的校友会排名情况。
整体来看,通过不同的视角和图形展示了关于大学的多维度数据,有助于对大学的各种属性进行深入分析。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “ 大学排名 ” 获取。👈👈👈
这篇关于【python】python大学排名数据分析可视化(源码+报告+数据集)【独一无二】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








