本文主要是介绍基于keepalived+gtid+双vip半同步主从复制的MySQL高性能集群,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
项目名称:基于keepalived+gtid+双vip半同步主从复制的MySQL高性能集群
目录
项目名称:基于keepalived+gtid+双vip半同步主从复制的MySQL高性能集群
项目规划图
1.配置4台MySQL服务器(1台master,2台slave,1台backup),安装好MySQL软件,安装好半同步相关的插件
2.配置好ansible服务器,定义好主机清单,在master和ansible服务器之间建立双向免密通道
3.在master上使用mysqldump,将数据冷备到anaible中控机上,然后ansible下发到所有的slave服务器上(其实也可以使用ansible批量进行mysql安装)
4.所有mysql机器开启gtid功能,启动主从复制服务,配置bakcup服务器上从master上拿二进制日志,设置延迟300秒.
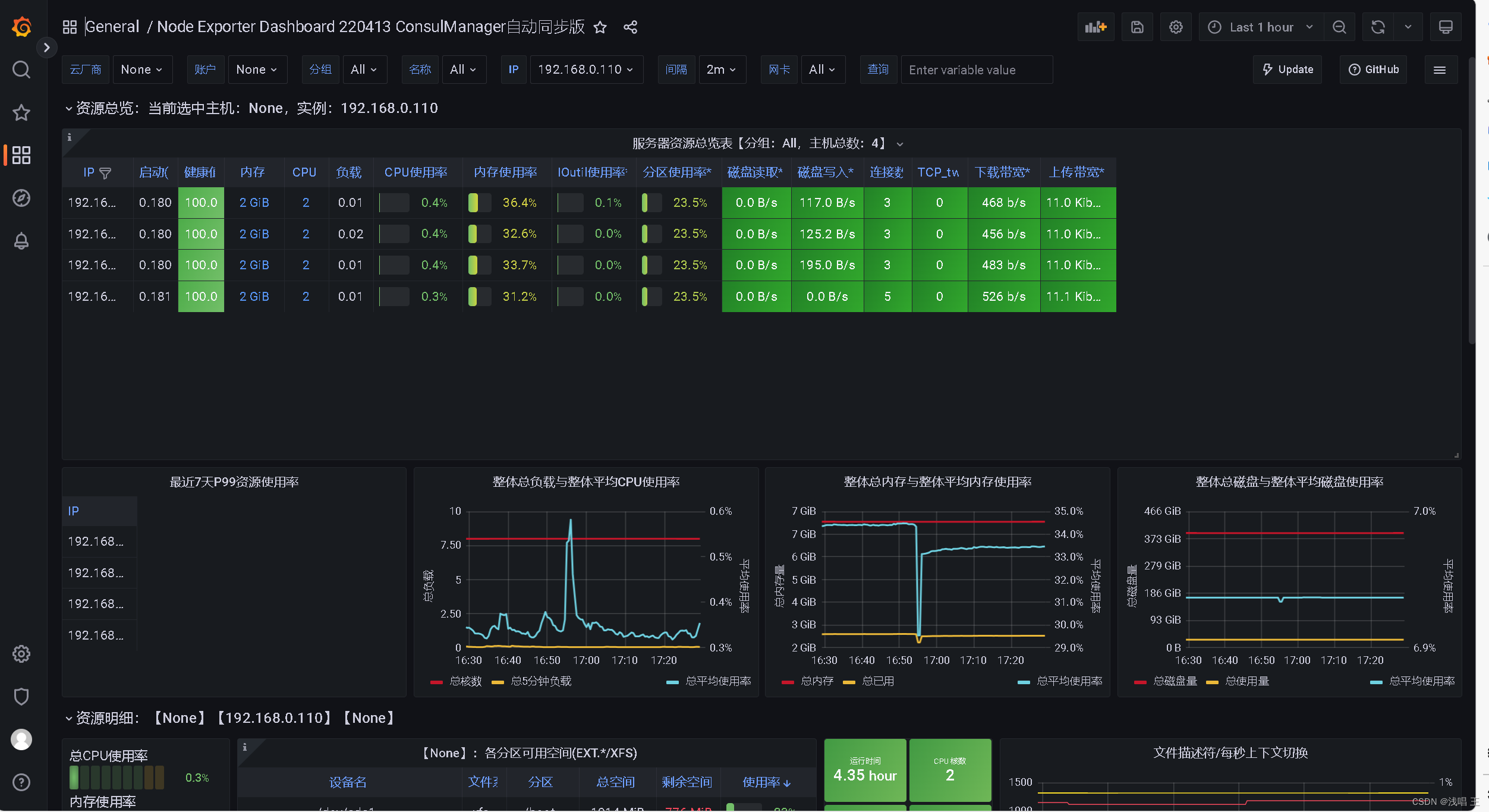
5.安装prometheus监控系统服务器,同时配置grafana,使用美观的图表监控我们的mysql集群
6.将所有的mysql服务器上安装node_exporter,采集数据进行数据监控
7.在master上创建一个计划任务每天定时进行master数据库的备份,编写备份脚本每天备份数据,备份文件包含当前的日期,scp远程同步到ansible服务器(相当于一台异地备份服务器),保障业务的稳定
8.在2台服务器安装部署了mysqlrouter中间件软件,实现读写分离
9.安装keepalived实现高可用,配置2个vrrp实例实现双vip的高可用功能
10.进行压力测试,使用sysbench进行测试
项目环境:9台服务器(2G,2核),centos7.8 mysql5.7.30 mysqlrouter8.0.21 keepalived2.0.10 prometheus grafana ansible mysqlrouter
项目描述:
本项目的目的是模拟企业构建一个高可用的能实现读写分离的高效的MySQL集群,确保业务的稳定,能沟通方便的监控整个集群,同时能批量的去部署和管理整个集群。
项目规划图

项目IP地址具体规划:
master 192.168.0.110
salve 192.168.0.111
salve3 192.168.0.112
delay-backup 192.168.0.113
mysql-router2 192.168.0.202 vip1:192.168.0.187
mysql-router2 192.168.0.202 vip2:192.168.0.186
ansible 192.168.0.205
prometheus 192.168.0.204
clinet 192.168.0.10
一定要关闭selinux和firewalld
1.配置4台MySQL服务器(1台master,2台slave,1台backup),安装好MySQL软件,安装好半同步相关的插件
#准备好实验的环境安装包
[root@master ~]# ls
install_exporter.sh mha4mysql-node-0.58.tar.gz onekey_install_mha_node.sh mha4mysql-node-0.58 mysql-5.7.38-linux-glibc2.12-x86_64.tar.gz node_exporter-1.4.0-rc.0.linux-amd64.tar.gz onekey_instalmysql一键安装脚本
[root@master ~]# cat onekey_install_mysql_binary.sh
#!/bin/bash
#解决软件的依赖关系
yum install cmake ncurses-devel gcc gcc-c++ vim lsof bzip2 openssl-devel ncurses-compat-libs -y#解压mysql二进制安装包
tar xf mysql-5.7.38-linux-glibc2.12-x86_64.tar.gz#移动mysql解压后的文件到/usr/local下改名叫mysql
#/usr/local/mysql 是mysql的安装目录--》门店
mv mysql-5.7.38-linux-glibc2.12-x86_64 /usr/local/mysql#新建组和用户 mysql
groupadd mysql
#mysql这个用户的shell 是/bin/false 属于mysql组
useradd -r -g mysql -s /bin/false mysql#关闭firewalld防火墙服务,并且设置开机不要启动
service firewalld stop
systemctl disable firewalld#临时关闭selinux
setenforce 0
#永久关闭selinux
sed -i '/^SELINUX=/ s/enforcing/disabled/' /etc/selinux/config#新建存放数据的目录--》仓库
mkdir /data/mysql -p
#修改/data/mysql目录的权限归mysql用户和mysql组所有,这样mysql用户启动mysql进程可以对这个文件夹进行读写了
chown mysql:mysql /data/mysql/
#只是允许mysql这个用户和mysql组可以访问,其他人都不能访问
chmod 750 /data/mysql/#进入/usr/local/mysql/bin目录
cd /usr/local/mysql/bin/#初始化mysql
./mysqld --initialize --user=mysql --basedir=/usr/local/mysql/ --datadir=/data/mysql &>passwd.txt#让mysql支持ssl方式登录的设置
./mysql_ssl_rsa_setup --datadir=/data/mysql/#获得临时密码
tem_passwd=$(cat passwd.txt |grep "temporary"|awk '{print $NF}')#$NF表示最后一个字段# abc=$(命令) 优先执行命令,然后将结果赋值给abc # 修改PATH变量,加入mysql bin目录的路径
#临时修改PATH变量的值
export PATH=/usr/local/mysql/bin/:$PATH
#重新启动linux系统后也生效,永久修改
echo 'PATH=/usr/local/mysql/bin:$PATH' >>/root/.bashrc#复制support-files里的mysql.server文件到/etc/init.d/目录下叫mysqld
cp ../support-files/mysql.server /etc/init.d/mysqld#修改/etc/init.d/mysqld脚本文件里的datadir目录的值
sed -i '70c datadir=/data/mysql' /etc/init.d/mysqld#生成/etc/my.cnf配置文件
cat >/etc/my.cnf <<EOF
[mysqld_safe][client]
socket=/data/mysql/mysql.sock[mysqld]
socket=/data/mysql/mysql.sock
port = 3306
open_files_limit = 8192
innodb_buffer_pool_size = 512M
character-set-server=utf8[mysql]
auto-rehash
prompt=\\u@\\d \\R:\\m mysql>
EOF#修改内核的open file的数量
ulimit -n 1000000
#设置开机启动的时候也配置生效
echo "ulimit -n 1000000" >>/etc/rc.local
chmod +x /etc/rc.d/rc.local#将mysqld添加到linux系统里服务管理名单里
/sbin/chkconfig --add mysqld
#设置mysqld服务开机启动
/sbin/chkconfig mysqld on#启动mysqld进程
service mysqld start#初次修改密码需要使用--connect-expired-password 选项
#-e 后面接的表示是在mysql里需要执行命令 execute 执行
#set password='123456'; 修改root用户的密码为123456
mysql -uroot -p$tem_passwd --connect-expired-password -e "set password='123456';"#检验上一步修改密码是否成功,如果有输出能看到mysql里的数据库,说明成功。
mysql -uroot -p'123456' -e "show databases;"
#其他的slave机器都安装好mysql就行
2.配置好ansible服务器,定义好主机清单,在master和ansible服务器之间建立双向免密通道
生成好密钥对,一直回车,都按照默认的就好
[root@ansible ~]# ssh-keygen
将ansible的公钥发送的mysql集群
[root@ansible ~]# ssh-copy-id root@192.168.0.110
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host '192.168.0.10 (192.168.0.10)' can't be established.
ECDSA key fingerprint is SHA256:xactOuiFsm9merQVjdeiV4iZwI4rXUnviFYTXL2h8fc.
ECDSA key fingerprint is MD5:69:58:6b:ab:c4:8c:27:e2:b2:7c:31:bb:63:20:81:61.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@192.168.0.110's password:
#这里填好你的密码
#提示这个就是你的成功
Now try logging into the machine, with: "ssh 'root@192.168.0.110'"
and check to make sure that only the key(s) you wanted were added.
##同样,将ansible的公钥发送给目标主机上,实现ansible对整个mysql集群的管理
192.168.0.111
192.168.0.112
192.168.0.113
mysql-router2 192.168.0.202
mysql-router2 192.168.0.202
prometheus 192.168.0.204
#配置ansible里面的hosts配置文件
[root@ansible ~]# vim /etc/ansible/hosts
#将需要管理的主机添加到mysql-servers组
#默认端口号就是22
#如果通过ssh登录的端口不是22端口,就需要在配置文件里面指明端口号
[mysql]
192.168.0.110 #master
192.168.0.111 #slave1
192.168.0.112 #slave2
192.168.0.113 #delay-backup[mysql-slave]
192.168.0.111 #salve1
192.168.0.112 #slave2
192.168.0.113 #delay_bakcup[mysql-master]
192.168.0.110 #master[mysql-router]
192.168.0.201 #router1
192.168.0.202 #router2
3.在master上使用mysqldump,将数据冷备到anaible中控机上,然后ansible下发到所有的slave服务器上(其实也可以使用ansible批量进行mysql安装)
#这里给出了批量安装的yaml文件
[root@ansible ~]# cat software_install.yaml
- hosts: mysqlremote_user: roottasks:- name: copy file #上传本地源码包到mysql主机组copy: src=/root/mysql-5.7.38-linux-glibc2.12-x86_64.tar.gz dest=/root/- name: one key binary install mysql #调用本地二进制安装脚本,远程执行安装mysqlscript: /root/onekey_install_mysql_binary_v5.7.38.sh- name: alter path #确保mysql命令加入环境变量shell: export PATH=/usr/local/mysql/bin/:$PATH
#将master上的数据冷备到其他的mysql服务器上
注意备份之前需要将gtid功能关闭
#开启gtid
#gtid-mode=ON
#enforce-gtid-consistency=ON
log-slave-updates数据热备--》注意要是出现我这个样是没有什么影响的
[root@master backup]# mysqldump -uroot -p'1232456' --all-databases >/backup/data.sql
mysqldump: [Warning] Using a password on the command line interface can be insecure.
[root@master backup]# ls
20240319130622_all_db.SQL passwd
all_backup_db.sh position.sh
data.sql 复制数据到ansible上,然后在通过ansible下发到其他的机器
[root@master backup]# scp ./data.sql ansible:/backup/
The authenticity of host 'ansible (192.168.0.205)' can't be established.
ECDSA key fingerprint is SHA256:pRY8ueQygPcheh2SCJd8V9PBhT7RlgDADPMzY82Fd4o.
ECDSA key fingerprint is MD5:02:ca:7e:56:d1:f9:e5:9c:83:3f:67:ee:9f:2c:38:20.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'ansible' (ECDSA) to the list of known hosts.
all_data.sql 100% 203 89.1KB/s 00:00 [root@slave backup]# ls
data.sql
[root@slave3 backup]# ls
data.sql
[root@delay-backup backup]# ls
data.sql##其他机器也有这个,表示ansible 下发任务成功#编写yaml文件,将数据全部热备到mysql集群上
[root@ansible backup]# cat copy_data.yaml
- name: Upload all_data.sql to MySQL slave servershosts: mysql-slavetasks:- name: Run script to upload all_data.sqlscript: /backup/backup.sh # 替换为你的上传脚本路径
[root@ansible backup]# ansible-playbook copy_data.yaml
[WARNING]: Invalid characters were found in group names but not replaced, use -vvvv to see details
PLAY [Upload all_data.sql to MySQL slave servers] *****************************************************************************
TASK [Gathering Facts] ********************************************************************************************************
ok: [192.168.0.113]
ok: [192.168.0.112]
ok: [192.168.0.111]
TASK [Run script to upload all_data.sql] **************************************************************************************
changed: [192.168.0.113]
changed: [192.168.0.112]
changed: [192.168.0.111]
PLAY RECAP ********************************************************************************************************************
192.168.0.111 : ok=2 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.0.112 : ok=2 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.0.113 : ok=2 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
4.所有mysql机器开启gtid功能,启动主从复制服务,配置bakcup服务器上从master上拿二进制日志,设置延迟300秒.
#开启之后gtid---》所有机器上都要开启
[root@master backup]# vim /etc/my.cnf[mysqld_safe][client]
socket=/data/mysql/mysql.sock[mysqld]
socket=/data/mysql/mysql.sock
port = 3306
open_files_limit = 8192
innodb_buffer_pool_size = 512M
character-set-server=utf8mb4#二进制日志
log_bin
server_id=1#开启半同步
rpl_semi_sync_master_enabled=1
rpl_semi_sync_master_timeout=1000 #1秒#开启gtid
gtid-mode=ON
enforce-gtid-consistency=ON
log-slave-updates[mysql]
auto-rehash
prompt=\u@\d \R:\m mysql>#刷新服务 ---》所有mysql机器
[root@master backup]# service mysqld restart
Shutting down MySQL.. SUCCESS!
Starting MySQL. SUCCESS! #防止出错重置所有机器上的master和slave
root@(none) 15:41 mysql>reset master;
root@(none) 15:43 mysql>reset slave all;#重新指认master
CHANGE MASTER TO MASTER_HOST='192.168.0.110',MASTER_USER='wylwrite',MASTER_PASSWORD='123456',MASTER_PORT=3306,MASTER_AUTO_POSITION=1;
####注意!!!这里我是之前创建了一个用户
create user 'wylwrite'@'%' identified by '123456';
grant all on *.* to 'wylwrite'@'%';
FLUSH PRIVILEGES; ##刷新权限#开启所有的从服务器上开启slave
root@(none) 15:43 mysql>start slave;
root@(none) 15:43 mysql>show slave status\G;
#查看状态
*************************** 1. row ***************************Slave_IO_State: Waiting for master to send eventMaster_Host: 192.168.0.110Master_User: wylwriteMaster_Port: 3306Connect_Retry: 60Master_Log_File: master-bin.000002Read_Master_Log_Pos: 154Relay_Log_File: slave-relay-bin.000004Relay_Log_Pos: 369Relay_Master_Log_File: master-bin.000002Slave_IO_Running: Yes ## #这个是io线程,就是帮你去master的二进制日志的Slave_SQL_Running: Yes ## 这个表示是本机的mysql进程Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0Last_Error: Skip_Counter: 0Exec_Master_Log_Pos: 154Relay_Log_Space: 791Until_Condition: NoneUntil_Log_File: Until_Log_Pos: 0Master_SSL_Allowed: NoMaster_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: NoLast_IO_Errno: 0Last_IO_Error: Last_SQL_Errno: 0Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 1 ##这个id绝对是不可以一样的Master_UUID: e1ae3fd1-db8f-11ee-859f-000c2974ba51Master_Info_File: /data/mysql/master.infoSQL_Delay: 0SQL_Remaining_Delay: NULLSlave_SQL_Running_State: Slave has read all relay log; waiting for more updatesMaster_Retry_Count: 86400Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 1 ##表示gtid功能开启了Replicate_Rewrite_DB: Channel_Name: Master_TLS_Version:
部署MHA,实现mysql集群的高可用,当master宕机,是能够自动将master的数据转移到候选master(slave1)上,实现集群的高可用
出现的问题刚开始我的ansible无法对mha进行环境部署,发现是两个机器之间没有配置免密通道,后面解决了
ssh-copy-id 目标主机ip
[root@ansible ~]# ansible-playbook mha_install.yaml PLAY [mha_node] ***************************************************************************TASK [Gathering Facts] ********************************************************************
fatal: [192.168.0.203]: UNREACHABLE! => {"changed": false, "msg": "Failed to connect to the host via ssh: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).", "unreachable": true}
ok: [192.168.0.112]
ok: [192.168.0.111]
ok: [192.168.0.113]
ok: [192.168.0.110]TASK [copy file] **************************************************************************
ok: [192.168.0.112]
ok: [192.168.0.111]
ok: [192.168.0.110]
ok: [192.168.0.113]TASK [install mha_node] *******************************************************************
changed: [192.168.0.113]
changed: [192.168.0.110]
changed: [192.168.0.111]
changed: [192.168.0.112]PLAY [mha_manager] ************************************************************************PLAY RECAP ********************************************************************************
192.168.0.110 : ok=3 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.0.111 : ok=3 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.0.112 : ok=3 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.0.113 : ok=3 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
192.168.0.203 : ok=0 changed=0 unreachable=1 failed=0 skipped=0 rescued=0 ignored=0
部署过程
[root@ansible ~]# cat mha_install.yaml
- hosts: mha_noderemote_user: roottasks: - name: copy filecopy: src=/root/mha4mysql-node-0.58.tar.gz dest=/root/- name: install mha_nodescript: /root/onekey_install_mha_node.sh
- hosts: mha_managerremote_user: roottasks:- name: copy filecopy: src=/root/mha4mysql-manager-0.58.tar.gz dest=/root/- name: install mha_managerscript: /root/onekey_install_mha_manager.sh
[root@ansible ~]# cat /etc/ansible/hosts
#将需要管理的主机添加到mysql-servers组
#默认端口号就是22
#如果通过ssh登录的端口不是22端口,就需要在配置文件里面指明端口号
[mysql]
192.168.0.110 #master
192.168.0.111 #slave1
192.168.0.112 #slave2
192.168.0.113 #delay-backup[mysql_slave]
192.168.0.111 #salve1
192.168.0.112 #slave2
192.168.0.113 #delay_bakcup[mysql_master]
192.168.0.110 #master[mysql_router]
192.168.0.201 #router1
192.168.0.202 #router2[mha_manager]
192.168.0.203 #mha manager[mha_node]
192.168.0.203 #mha manager
192.168.0.110 #master
192.168.0.111 #slave1
192.168.0.112 #slave3
192.168.0.113 #delay-backup安装mha_manager的脚本
[root@ansible ~]# cat onekey_install_mha_manager.sh
#软件包mha4mysql-manager-0.58.tar.gz放入/root目录下
tar zxvf mha4mysql-manager-0.58.tar.gz
cd mha4mysql-manager-0.58
#编译安装
perl Makefile.PL
make && make install.编写playbook,上传源码包到家目录下,调用本地脚本,远程安装部署mha相关软件环境
[root@ansible ansible]# cat mha_install.yaml
- hosts: mha_noderemote_user: roottasks: - name: copy filecopy: src=/root/mha4mysql-node-0.58.tar.gz dest=/root/- name: install mha_nodescript: /root/onekey_install_mha_node.sh
- hosts: mha_managerremote_user: roottasks:- name: copy filecopy: src=/root/mha4mysql-manager-0.58.tar.gz dest=/root/- name: install mha_managerscript: /root/onekey_install_mha_manager.sh 执行playbook
[root@ansible ansible]# ansible-playbook mha_install.yaml 所有服务器互相建立免密通道
mha manager对所有mysql服务器建立免密通道
#使用
ssh-copy-id IP地址创建用户
授权
查看用户表 mysql.user
修改master_ip_failover文件内容,配置vip(只配置vip相关参数,其他默认不修改)
.复制自动切换时vip管理的脚本到/usr/local/bin下
[root@mha_manager scripts]# cp /usr/local/bin/scripts/master_ip_failover /usr/local/bin/
修改master_ip_failover文件内容,配置vip(只配置vip相关参数,其他默认不修改)
[root@mha_manager scripts]# >/usr/local/bin/master_ip_failover #清空文件内容,复制以下内容
[root@mha_manager scripts]# vim /usr/local/bin/master_ip_failover
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';use Getopt::Long;my (
$command, $ssh_user, $orig_master_host, $orig_master_ip,
$orig_master_port, $new_master_host, $new_master_ip, $new_master_port
);
#############################添加内容部分#########################################
my $vip = '192.168.0.200'; #指定vip的地址,自己指定
my $brdc = '192.168.0.255'; #指定vip的广播地址
my $ifdev = 'ens33'; #指定vip绑定的网卡
my $key = '1'; #指定vip绑定的虚拟网卡序列号
my $ssh_start_vip = "/sbin/ifconfig ens33:$key $vip"; #代表此变量值为ifconfig ens33:1 192.168.31.200
my $ssh_stop_vip = "/sbin/ifconfig ens33:$key down"; #代表此变量值为ifconfig ens33:1 192.168.31.200 down
my $exit_code = 0; #指定退出状态码为0
#my $ssh_start_vip = "/usr/sbin/ip addr add $vip/24 brd $brdc dev $ifdev label $ifdev:$key;/usr/sbin/arping -q -A -c 1 -I $ifdev $vip;iptables -F;";
#my $ssh_stop_vip = "/usr/sbin/ip addr del $vip/24 dev $ifdev label $ifdev:$key";
##################################################################################
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
);exit &main();sub main {print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";if ( $command eq "stop" || $command eq "stopssh" ) {my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
## A simple system call that disable the VIP on the old_master
sub stop_vip() {
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}##注意注释最好不要,这里只是做解释使用
[root@mha_manager scripts]# mkdir /etc/masterha [root@mha_manager scripts]# cp /root/mha4mysql-manager-0.58/samples/conf/app1.cnf /etc/masterha/ [root@mha_manager scripts]# cd /etc/masterha/ [root@mha_manager masterha]# ls app1.cnf [root@mha_manager masterha]# >app1.cnf #清空原有内容 [root@mha_manager masterha]# vim app1.cnf [server default] manager_log=/var/log/masterha/app1/manager.log #manager日志 manager_workdir=/var/log/masterha/app1.log #manager工作目录 master_binlog_dir=/data/mysql/ #master保存binlog的位置,这里的路径要与master里配置的binlog的路径一致,以便MHA能找到 master_ip_failover_script=/usr/local/bin/master_ip_failover #设置自动failover时候的切换脚本,也就是上面的那个脚本 master_ip_online_change_script=/usr/local/bin/master_ip_online_change #设置手动切换时候的切换脚本 user=mha #设置监控用户mha password=123456 #设置mysql中mha用户的密码,这个密码是前文中创建监控用户的那个密码 ping_interval=1 #设置监控主库,发送ping包的时间间隔1秒,默认是3秒,尝试三次没有回应的时候自动进行failover remote_workdir=/tmp #设置远端mysql在发生切换时binlog的保存位置 repl_user=slave #设置复制用户的用户slave repl_password=123456 #设置复制用户slave的密码 report_script=/usr/local/send_report #设置发生切换后发送的报警的脚本 secondary_check_script=/usr/local/bin/masterha_secondary_check -s 192.168.31.222 -s 192.168.31.223 #指定检查的从服务器IP地址 shutdown_script="" #设置故障发生后关闭故障主机脚本(该脚本的主要作用是关闭主机防止发生脑裂,这里没有使用) ssh_user=root #设置ssh的登录用户名[server1] #master hostname=192.168.31.221 port=3306[server2] #slave1 hostname=192.168.31.222 port=3306 candidate_master=1 #设置为候选master,设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中最新的slavecheck_repl_delay=0 #默认情况下如果一个slave落后master 超过100M的relay logs的话,MHA将不会选择该slave作为一个新的master, 因为对于这个slave的恢复需要花费很长时间;通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master[server3] #slave2 hostname=192.168.31.223 port=3306
在master上手工开启vip
[root@master mysql]# ifconfig ens33:1 192.168.0.200/24
测试环节
[root@mha masterha]# masterha_check_repl -conf=/etc/masterha/app1.cnf
Fri Apr 5 23:47:12 2024 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Fri Apr 5 23:47:12 2024 - [info] Reading application default configuration from /etc/masterha/app1.cnf..
Fri Apr 5 23:47:12 2024 - [info] Reading server configuration from /etc/masterha/app1.cnf..
Fri Apr 5 23:47:12 2024 - [info] MHA::MasterMonitor version 0.58.
Fri Apr 5 23:47:13 2024 - [info] GTID failover mode = 1
Fri Apr 5 23:47:13 2024 - [info] Dead Servers:
Fri Apr 5 23:47:13 2024 - [info] Alive Servers:
Fri Apr 5 23:47:13 2024 - [info] 192.168.0.110(192.168.0.110:3306)
Fri Apr 5 23:47:13 2024 - [info] 192.168.0.111(192.168.0.111:3306)
Fri Apr 5 23:47:13 2024 - [info] 192.168.0.112(192.168.0.112:3306)
Fri Apr 5 23:47:13 2024 - [info] 192.168.0.113(192.168.0.113:3306)
Fri Apr 5 23:47:13 2024 - [info] Alive Slaves:
Fri Apr 5 23:47:13 2024 - [info] 192.168.0.111(192.168.0.111:3306) Version=5.7.38-log (oldest major version between slaves) log-bin:enabled
Fri Apr 5 23:47:13 2024 - [info] GTID ON
Fri Apr 5 23:47:13 2024 - [info] Replicating from 192.168.0.110(192.168.0.110:3306)
Fri Apr 5 23:47:13 2024 - [info] Primary candidate for the new Master (candidate_master is set)
Fri Apr 5 23:47:13 2024 - [info] 192.168.0.112(192.168.0.112:3306) Version=5.7.38-log (oldest major version between slaves) log-bin:enabled
Fri Apr 5 23:47:13 2024 - [info] GTID ON
Fri Apr 5 23:47:13 2024 - [info] Replicating from 192.168.0.110(192.168.0.110:3306)
Fri Apr 5 23:47:13 2024 - [info] 192.168.0.113(192.168.0.113:3306) Version=5.7.38-log (oldest major version between slaves) log-bin:enabled
Fri Apr 5 23:47:13 2024 - [info] GTID ON
Fri Apr 5 23:47:13 2024 - [info] Replicating from 192.168.0.110(192.168.0.110:3306)
Fri Apr 5 23:47:13 2024 - [info] Current Alive Master: 192.168.0.110(192.168.0.110:3306)
Fri Apr 5 23:47:13 2024 - [info] Checking slave configurations..
Fri Apr 5 23:47:13 2024 - [info] read_only=1 is not set on slave 192.168.0.111(192.168.0.111:3306).
Fri Apr 5 23:47:13 2024 - [info] read_only=1 is not set on slave 192.168.0.112(192.168.0.112:3306).
Fri Apr 5 23:47:13 2024 - [info] read_only=1 is not set on slave 192.168.0.113(192.168.0.113:3306).
Fri Apr 5 23:47:13 2024 - [info] Checking replication filtering settings..
Fri Apr 5 23:47:13 2024 - [info] binlog_do_db= , binlog_ignore_db=
Fri Apr 5 23:47:13 2024 - [info] Replication filtering check ok.
Fri Apr 5 23:47:13 2024 - [info] GTID (with auto-pos) is supported. Skipping all SSH and Node package checking.
Fri Apr 5 23:47:13 2024 - [info] Checking SSH publickey authentication settings on the current master..
Fri Apr 5 23:47:13 2024 - [info] HealthCheck: SSH to 192.168.0.110 is reachable.
Fri Apr 5 23:47:13 2024 - [info]
192.168.0.110(192.168.0.110:3306) (current master)+--192.168.0.111(192.168.0.111:3306)+--192.168.0.112(192.168.0.112:3306)+--192.168.0.113(192.168.0.113:3306)Fri Apr 5 23:47:13 2024 - [info] Checking replication health on 192.168.0.111..
Fri Apr 5 23:47:13 2024 - [info] ok.
Fri Apr 5 23:47:13 2024 - [info] Checking replication health on 192.168.0.112..
Fri Apr 5 23:47:13 2024 - [info] ok.
Fri Apr 5 23:47:13 2024 - [info] Checking replication health on 192.168.0.113..
Fri Apr 5 23:47:13 2024 - [info] ok.
Fri Apr 5 23:47:13 2024 - [warning] master_ip_failover_script is not defined.
Fri Apr 5 23:47:13 2024 - [warning] shutdown_script is not defined.
Fri Apr 5 23:47:13 2024 - [info] Got exit code 0 (Not master dead).MySQL Replication Health is OK.
[root@mha masterha]# masterha_check_ssh -conf=/etc/masterha/app1.cnf
Sat Apr 6 00:00:32 2024 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Sat Apr 6 00:00:32 2024 - [info] Reading application default configuration from /etc/masterha/app1.cnf..
Sat Apr 6 00:00:32 2024 - [info] Reading server configuration from /etc/masterha/app1.cnf..
Sat Apr 6 00:00:32 2024 - [info] Starting SSH connection tests..
Sat Apr 6 00:00:33 2024 - [debug]
Sat Apr 6 00:00:32 2024 - [debug] Connecting via SSH from root@192.168.0.110(192.168.0.110:22) to root@192.168.0.111(192.168.0.111:22)..
Sat Apr 6 00:00:32 2024 - [debug] ok.
Sat Apr 6 00:00:32 2024 - [debug] Connecting via SSH from root@192.168.0.110(192.168.0.110:22) to root@192.168.0.112(192.168.0.112:22)..
Sat Apr 6 00:00:32 2024 - [debug] ok.
Sat Apr 6 00:00:32 2024 - [debug] Connecting via SSH from root@192.168.0.110(192.168.0.110:22) to root@192.168.0.113(192.168.0.113:22)..
Sat Apr 6 00:00:33 2024 - [debug] ok.
Sat Apr 6 00:00:33 2024 - [debug]
Sat Apr 6 00:00:32 2024 - [debug] Connecting via SSH from root@192.168.0.111(192.168.0.111:22) to root@192.168.0.110(192.168.0.110:22)..
Sat Apr 6 00:00:33 2024 - [debug] ok.
Sat Apr 6 00:00:33 2024 - [debug] Connecting via SSH from root@192.168.0.111(192.168.0.111:22) to root@192.168.0.112(192.168.0.112:22)..
Sat Apr 6 00:00:33 2024 - [debug] ok.
Sat Apr 6 00:00:33 2024 - [debug] Connecting via SSH from root@192.168.0.111(192.168.0.111:22) to root@192.168.0.113(192.168.0.113:22)..
Sat Apr 6 00:00:33 2024 - [debug] ok.
Sat Apr 6 00:00:34 2024 - [debug]
Sat Apr 6 00:00:33 2024 - [debug] Connecting via SSH from root@192.168.0.112(192.168.0.112:22) to root@192.168.0.110(192.168.0.110:22)..
Sat Apr 6 00:00:33 2024 - [debug] ok.
Sat Apr 6 00:00:33 2024 - [debug] Connecting via SSH from root@192.168.0.112(192.168.0.112:22) to root@192.168.0.111(192.168.0.111:22)..
Sat Apr 6 00:00:33 2024 - [debug] ok.
Sat Apr 6 00:00:33 2024 - [debug] Connecting via SSH from root@192.168.0.112(192.168.0.112:22) to root@192.168.0.113(192.168.0.113:22)..
Sat Apr 6 00:00:34 2024 - [debug] ok.
Sat Apr 6 00:00:35 2024 - [debug]
Sat Apr 6 00:00:33 2024 - [debug] Connecting via SSH from root@192.168.0.113(192.168.0.113:22) to root@192.168.0.110(192.168.0.110:22)..
Sat Apr 6 00:00:34 2024 - [debug] ok.
Sat Apr 6 00:00:34 2024 - [debug] Connecting via SSH from root@192.168.0.113(192.168.0.113:22) to root@192.168.0.111(192.168.0.111:22)..
Sat Apr 6 00:00:34 2024 - [debug] ok.
Sat Apr 6 00:00:34 2024 - [debug] Connecting via SSH from root@192.168.0.113(192.168.0.113:22) to root@192.168.0.112(192.168.0.112:22)..
Sat Apr 6 00:00:34 2024 - [debug] ok.
Sat Apr 6 00:00:35 2024 - [info] All SSH connection tests passed successfully
都是ok,说明成功了manager节点后台开启MHA
.manager节点后台开启MHA
[root@mha masterha]# nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/masterha/app1.log 2>&1 &
[1] 4811
现在的master是192.168.0.110
[root@mha masterha]# masterha_check_status --conf=/etc/masterha/app1.cnf
app1 (pid:4832) is running(0:PING_OK), master:192.168.0.110
模拟测试master宕机
#同时注意看mha日志文件
当前vip 是在master上192.168.0.200
[root@master ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope host valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000link/ether 00:0c:29:74:ba:51 brd ff:ff:ff:ff:ff:ffinet 192.168.0.110/24 brd 192.168.0.255 scope global ens33valid_lft forever preferred_lft foreverinet 192.168.0.200/24 brd 192.168.0.255 scope global secondary ens33:1valid_lft forever preferred_lft foreverinet6 fe80::20c:29ff:fe74:ba51/64 scope link valid_lft forever preferred_lft forever
模拟关闭
[root@master ~]# service mysqld stop
Shutting down MySQL............ SUCCESS!
#查看mhamanager的进程是否启动
[root@mha masterha]# ps aux|grep manager
root 4832 0.1 1.9 299868 22184 pts/0 S 00:11 0:00 perl /usr/local/bin/masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover
root 4967 0.0 0.0 108092 620 pts/0 S+ 00:12 0:00 tail -f /var/log/masterha/app1/manager.log
root 5326 0.0 1.6 299868 18616 pts/0 S 00:18 0:00 perl /usr/local/bin/masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover
root 5327 0.0 1.6 299868 18628 pts/0 S 00:18 0:00 perl /usr/local/bin/masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover#测试效果
[root@mha app1]# tail -f manager.log
Selected 192.168.0.111(192.168.0.111:3306) as a new master.
192.168.0.111(192.168.0.111:3306): OK: Applying all logs succeeded.5.安装prometheus监控系统服务器,同时配置grafana,使用美观的图表监控我们的mysql集群
[root@prometheus prom]# lsnode_exporter-1.4.0-rc.0.linux-amd64.tar.gz prometheus-2.43.0.linux-amd64.tar.gz
grafana-enterprise-9.1.2-1.x86_64.rpm prometheus[root@prometheus ansible]# mkdir /prom
[root@prometheus ansible]# cd /prom
[root@prometheus prom]# ls
grafana-enterprise-9.1.2-1.x86_64.rpm prometheus-2.43.0.linux-amd64.tar.gz
node_exporter-1.4.0-rc.0.linux-amd64.tar.gz
[root@nfs-ansible-prom prom]#
2.解压源码包
[root@ prometheu prom]# tar xf prometheus-2.43.0.linux-amd64.tar.gz
[root@prometheus prom]# ls
grafana-enterprise-9.1.2-1.x86_64.rpm prometheus-2.43.0.linux-amd64
node_exporter-1.4.0-rc.0.linux-amd64.tar.gz prometheus-2.43.0.linux-amd64.tar.gz
修改解压后的压缩包名字prometheus
[root@promethues prom]# mv prometheus-2.43.0.linux-amd64 prometheus
[root@promethues prom]# ls
grafana-enterprise-9.1.2-1.x86_64.rpm prometheus
node_exporter-1.4.0-rc.0.linux-amd64.tar.gz prometheus-2.43.0.linux-amd64.tar.gz
[root@promethues prom]#
临时和永久修改PATH变量,添加prometheus的路径
[root@promethues prom]#PATH=/prom/prometheus:$PATH
[ [root@promethues prom]# echo 'PATH=/prom/prometheus:$PATH' >>/etc/profile
[root@promethues prom]#which prometheus ##查看命令在哪里
/prom/prometheus/prometheus
[root@promethues prom]#
把prometheus做成一个服务来进行管理,非常方便日后维护和使用
[root@promethues prom]#vim /usr/lib/systemd/system/prometheus.service
[Unit]
Description=prometheus
[Service]
ExecStart=/prom/prometheus/prometheus --config.file=/prom/prometheus/prometheus.yml
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=on-failure
[Install]
WantedBy=multi-user.target
重新加载systemd相关的服务,识别Prometheus服务的配置文件
[root@promethues prom]# systemctl daemon-reload
启动Prometheus服务
[root@promethues prom]#systemctl start prometheus
[root@promethues prom]#systemctl restart prometheus
[root@promethues prom]#ps aux|grep prome
root 2740 2.7 0.9 798956 37312 ? Ssl 14:57 0:00 /prom/prometheus/prometheus --config.file=/prom/prometheus/prometheus.yml
root 2748 0.0 0.0 112824 976 pts/0 S+ 14:57 0:00 grep --color=auto prome
设置开机启动
[root@promethues prom]# systemctl enable prometheus
Created symlink from /etc/systemd/system/multi-user.target.wants/prometheus.service to /usr/lib/systemd/system/prometheus.service.
##这里面的文档是需要到官方下载
6.将所有的mysql服务器上安装node_exporter,采集数据进行数据监控
在整个mysql集群上安装node_exporter
exporter 是Prometheus的客户端的数据采集工具--》go语言编写的
可以通过scp 命令传到其他机器
也可以通过ansible命令传到其他机器,也可以写yaml文件
#编写好一键安装文档
[root@nfs-ansible-prom prom]# vim install_node_exporter.sh
#!/bin/bashtar xf /root/node_exporter-1.4.0-rc.0.linux-amd64.tar.gz -C /
cd /
mv node_exporter-1.4.0-rc.0.linux-amd64/ node_exporter
cd /node_exporter/
echo 'PATH=/node_exporter/:$PATH' >>/etc/profile#生成nodeexporter.service文件
cat >/usr/lib/systemd/system/node_exporter.service <<EOF
[Unit]
Description=node_exporter
[Service]
ExecStart=/node_exporter/node_exporter --web.listen-address 0.0.0.0:9090
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF#让systemd进程识别node_exporter服务
systemctl daemon-reload
#设置开机启动
systemctl enable node_exporter
#启动node_exporter
systemctl start node_exporter##都安装好之后可以进行查看端口和进程号
[root@prometheus prom]# ps -aux| grep prometheus
root 703 0.1 2.1 1136324 82212 ? Ssl 13:09 0:14 /prom/prometheus/prometheus --config.file=/prom/prometheus/prometheus.yml
root 1702 0.0 0.0 112828 976 pts/0 S+ 16:12 0:00 grep --color=auto prometheus
##查看端口号
[root@prometheus prom]# netstat -anplut|grep prom
tcp 0 0 192.168.0.204:38750 192.168.0.110:9090 ESTABLISHED 703/prometheus
tcp 0 0 192.168.0.204:44714 192.168.0.111:9090 ESTABLISHED 703/prometheus
tcp 0 0 192.168.0.204:52838 192.168.0.112:9090 ESTABLISHED 703/prometheus
tcp 0 0 192.168.0.204:37038 192.168.0.113:9090 ESTABLISHED 703/prometheus
tcp6 0 0 :::9090 :::* LISTEN 703/prometheus
tcp6 0 0 ::1:41556 ::1:9090 ESTABLISHED 703/prometheus
tcp6 0 0 ::1:9090 ::1:41556 ESTABLISHED 703/prometheus #登录自己的prometheus的端口一般是9090。
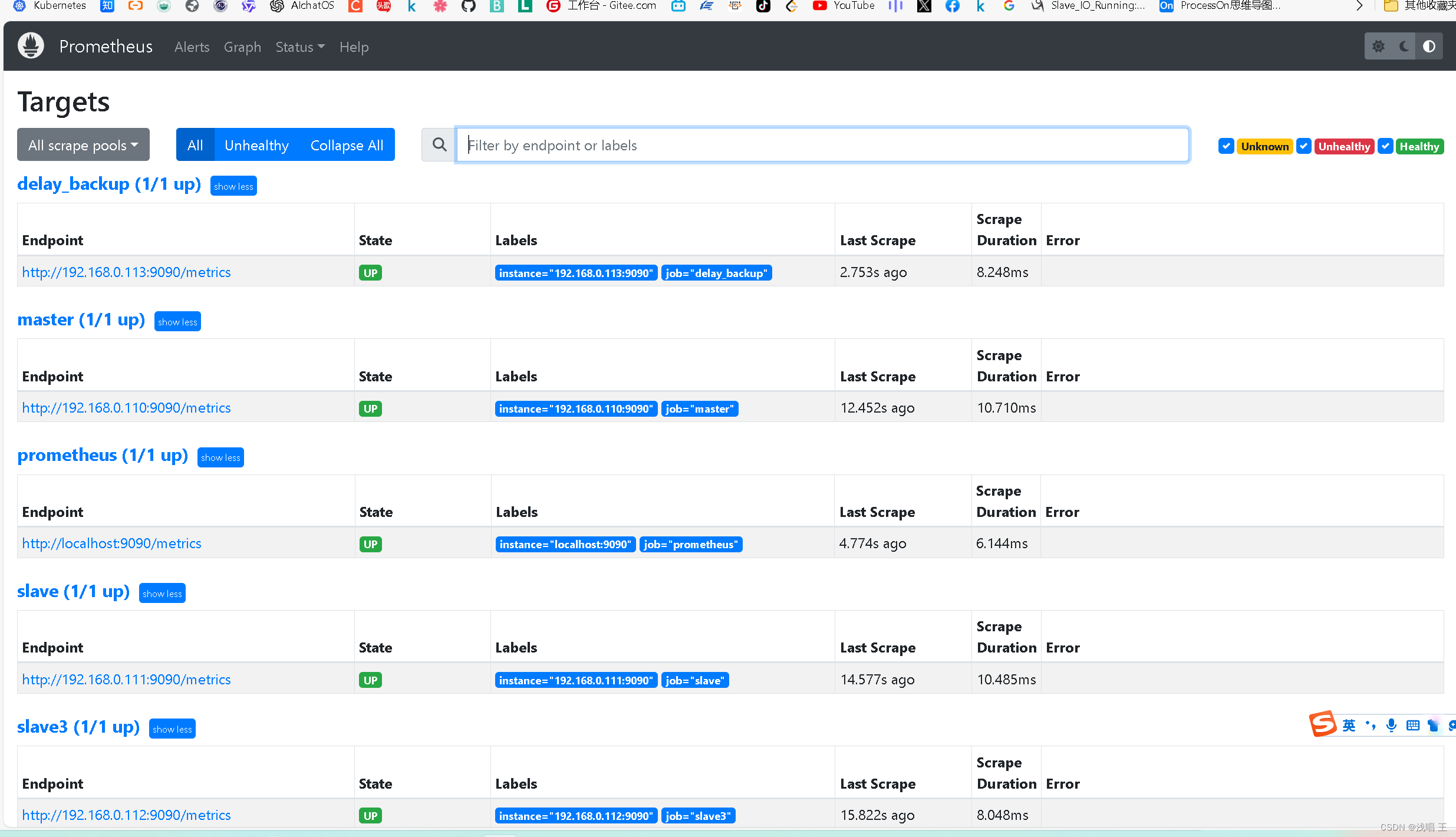
7.在master上创建一个计划任务每天定时进行master数据库的备份,编写备份脚本每天备份数据,备份文件包含当前的日期,scp远程同步到ansible服务器(相当于一台异地备份服务器),保障业务的稳定
##编辑计划任务
crontab -e#每天2点30分,备份数据库信息
30 2 * * * bash /backup/all_backup_db.sh 脚本内容
[root@master backup]# cat all_backup_db.sh
mysqldump -uroot -p'123456' --all-databases > "$(date +"%Y-%m-%d_%H-%M-%S")_database_backup.sql"
#也可以设置计划任务将数据远程备份到ansible中控机上,实现异地备份
[root@master backup]# crontab -l
#每天2点30分,备份数据到远程ansible中控机上
30 2 * * * scp ./"$(date +"%Y-%m-%d_%H-%M-%S")8.在2台服务器安装部署了mysqlrouter中间件软件,实现读写分离
#安装好--》可以去官方文档,或者查资料
[root@mysql-router1 ~]# ls
anaconda-ks.cfg mysql-router-community-8.0.21-1.el7.x86_64.rpm.1
mysql-router-community-8.0.21-1.el7.x86_64.rpm node_exporter-1.4.0-rc.0.linux-amd64.tar.gz
[root@mysql-router1 ~]# rpm -ivh mysql-router-community-8.0.23-1.el7.x86_64.rpm
警告:mysql-router-community-8.0.23-1.el7.x86_64.rpm: 头V3 DSA/SHA1 Signature, 密钥 ID 5072e1f5: NOKEY
准备中... ################################# [100%]
正在升级/安装...1:mysql-router-community-8.0.23-1.e################################# [100%]
[root@mysql-router1 ~]#
3.修改配置文件
[root@mysql-router1 ~]# cd /etc/mysqlrouter/ 进入存放配置文件的目录
[root@mysql-router1 mysqlrouter]# ls
mysqlrouter.conf
[root@mysql-router1 mysqlrouter]# vim mysqlrouter.conf[root@mysql-router1 mysqlrouter]# cat mysqlrouter.conf |grep -v "^#"[DEFAULT]
logging_folder = /var/log/mysqlrouter
runtime_folder = /var/run/mysqlrouter
config_folder = /etc/mysqlrouter[logger]
level = INFO[keepalive]
interval = 60[routing:slaves]
bind_address = 192.168.0.187:7001 #虚拟vip1
destinations = 192.168.0.111:3306,192.168.0.112:3306,192.168.0.113:3306
mode = read-only
connect_timeout = 1 [routing:masters]
bind_address = 192.168.0.187:7002 #虚拟vip1
destinations = 192.168.0.110:3306
mode = read-write
connect_timeout = 1 #链接超时时间
##同理配置mysqlrouter24.启动MySQL router服务
[root@mysql-router1 ~]# service mysqlrouter start
Redirecting to /bin/systemctl start mysqlrouter.service
[root@mysql-router1 ~]#
mysqlrouter监听了7001和7002端口
[root@mysql-router1 ~]# netstat -anplut|grep mysql
tcp 0 0 192.168.2.106:7001 0.0.0.0:* LISTEN 2258/mysqlrouter
tcp 0 0 192.168.2.106:7002 0.0.0.0:* LISTEN 2258/mysqlrouter
[root@mysql-router1 ~]# 5.在master上创建2个测试账号,一个是读的,一个是写的root@(none) 15:34 mysql>grant all on *.* to 'wylwrite'@'%' identified by '123456';
Query OK, 0 rows affected, 1 warning (0.00 sec)root@(none) 15:35 mysql>grant select on *.* to 'wylread'@'%' identified by '123456';
Query OK, 0 rows affected, 1 warning (0.01 sec)root@(none) 15:35 mysql>
6.在客户端上测试读写分离的效果,使用2个测试账号
[root@master backup]# mysql -uwylwrite -p'123456' wylwrite@(none) 16:49 mysql>create database teswyl;
Query OK, 1 row affected (0.01 sec)wylwrite@(none) 16:49 mysql>show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| 123w |
| TENNIS |
| XIESHAN |
| hepeng123 |
| hunan |
| jioajiao |
| liangliang |
| mysql |
| performance_schema |
| sbtest |
| sys |
| tanxue |
| teswyl |
| wang123 |
| wangshuai |
+--------------------+
16 rows in set (0.00 sec)
##从服务器
root@(none) 16:49 mysql>show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| 123w |
| TENNIS |
| XIESHAN |
| hepeng123 |
| hunan |
| jioajiao |
| liangliang |
| mysql |
| performance_schema |
| sbtest |
| sys |
| tanxue |
| teswyl |
| wang123 |
| wangshuai |
+--------------------+
16 rows in set (0.01 sec)
主从复制同步了
##同理测试读的用户
wylread@(none) 16:57 mysql>create database nihaao;
ERROR 1044 (42000): Access denied for user 'wylread'@'%' to database 'nihao'
##没有权限建库
wylread@hunan 16:59 mysql>select * from width;
+----+-----------+
| id | name |
+----+-----------+
| 18 | 王老板 |
| 19 | 王老板 |
| 20 | 关牛马 |
| 22 | 关牛马 |
+----+-----------+
4 rows in set (0.00 sec)
读写分离的关键点:其实是用户的权限,让不同的用户连接不同的端口,最后任然要到后端的mysql服务器里去验证是否有读写的权限
mysqlrouter只是做了读写的分流,让应用程序去连接不同的端口--》mysqlrouter只是一个分流的工具
主要是用户权限的控制,有写权限的用户走读的通道也可以写,读的用户走写的通道只能读
7001 -->read-->wylread
7002 -->write/read -->wylwrite
9.安装keepalived实现高可用,配置2个vrrp实例实现双vip的高可用功能
keepalived :
官方网站:https://www.keepalived.org/
Keepalived 是一个用 C 语言编写的路由软件。这个项目的主要目标是为 Linux 系统和基于 Linux 的基础设施提供简单而强大的负载均衡和高可用性功能。
Keepalived 开源并且免费的软件。
Keepalived 的2大核心功能:
1.loadbalance 负载均衡 LB:ipvs--》lvs软件在linux内核里已经安装,不需要单独安装
2. high-availability 高可用 HA : vrrp协议
=====
vrrp协议:虚拟路由器冗余协议
一组路由器协同工作,担任不同的角色,有master角色,也有backup角色
master角色的路由器(的接口)承担实际的数据流量转发任务
Backup路由器侦听Master路由器的状态,并在Master路由器发生故障时,接替其工作,从而保证业务流量的平滑切换。 随时候命,是备胎
选举:
vip: 虚拟ip
在一个VRRP 组内的多个路由器接口共用一个虚拟IP地址,该地址被作为局域网内所有主机的缺省网关地址。
VRRP协议报文使用固定的组播地址224.0.0.18进行发送
vrrp协议工作在哪层?
网络层
vrrp协议的组播地址:
封装角度:
帧: 源mac,目的mac
vrrp协议: 封装
ip协议
vrrp协议的工作原理:
选举的过程:
1.所有的路由器或者服务器发送vrrp宣告报文,进行选举,必须是相同vrid和认证密码的,优先级高的服务器或者路由器会被选举为master,其他的机器都是backup
2.master定时(Advertisement Interval)发送VRRP通告报文,以便向Backup路由器告 知自己的存活情况。 默认是间隔1秒
3.接收Master设备发送的VRRP通告报文,判断Master设备的状态是否正常。 如果超过1秒没有收到vrrp报文,就认为master挂了,开始重新选举新的master,vip会漂移到新的master上
====
安装keepalived软件,在2台MySQLrouter上都安装
1.[root@mysql-router-1 keepalived]# yum install keepalived -y2.修改配置文件
[root@mysql-router1 ~]# cd /etc/keepalived/
[root@mysql-router1 keepalived]# ls
keepalived.conf
[root@mysql-router1 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalivedglobal_defs {notification_email {acassen@firewall.locfailover@firewall.locsysadmin@firewall.loc}notification_email_from Alexandre.Cassen@firewall.locsmtp_server 192.168.200.1smtp_connect_timeout 30router_id LVS_DEVELvrrp_skip_check_adv_addr#vrrp_strictvrrp_garp_interval 0vrrp_gna_interval 0
}
vrrp_script send_mail {script "/mail/sendmail.sh"interval 3
}vrrp_instance VI_1 {state MASTERinterface ens33virtual_router_id 80priority 200advert_int 1authentication {auth_type PASSauth_pass 1111}
track_script {send_mail
}virtual_ipaddress {192.168.0.187}
}vrrp_instance VI_2 {state backupinterface ens33virtual_router_id 81priority 100advert_int 1authentication {auth_type PASSauth_pass 1111}
track_script {send_mail
}virtual_ipaddress {192.168.0.186}
}
##配置mysql-router2
[root@mysql-router2 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalivedglobal_defs {notification_email {acassen@firewall.locfailover@firewall.locsysadmin@firewall.loc}notification_email_from Alexandre.Cassen@firewall.locsmtp_server 192.168.200.1smtp_connect_timeout 30router_id LVS_DEVELvrrp_skip_check_adv_addr#vrrp_strictvrrp_garp_interval 0vrrp_gna_interval 0
}
vrrp_script send_mail {script "/mail/sendmail.sh"interval 3
}vrrp_instance VI_1 {state MASTERinterface ens33virtual_router_id 80priority 100advert_int 1authentication {auth_type PASSauth_pass 1111}
track_script {send_mail
}virtual_ipaddress {192.168.0.187}
}vrrp_instance VI_2 {state backupinterface ens33virtual_router_id 81priority 200advert_int 1authentication {auth_type PASSauth_pass 1111}
track_script {send_mail
}virtual_ipaddress {192.168.0.186}
}
#查看是否启动了vip
[root@mysql-router1 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope host valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000link/ether 00:0c:29:70:16:6f brd ff:ff:ff:ff:ff:ffinet 192.168.0.201/24 brd 192.168.0.255 scope global noprefixroute ens33valid_lft forever preferred_lft foreverinet 192.168.0.187/32 scope global ens33valid_lft forever preferred_lft foreverinet6 fe80::20c:29ff:fe70:166f/64 scope link valid_lft forever preferred_lft forever[root@mysql-router2 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope host valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000link/ether 00:0c:29:48:ab:6e brd ff:ff:ff:ff:ff:ffinet 192.168.0.202/24 brd 192.168.0.255 scope global noprefixroute ens33valid_lft forever preferred_lft foreverinet 192.168.0.186/32 scope global ens33valid_lft forever preferred_lft foreverinet6 fe80::20c:29ff:fe48:ab6e/64 scope link valid_lft forever preferred_lft forever
10.进行压力测试,使用sysbench进行测试
测试前的
##我这个使用的sysbench压力测试
[root@clinet ~]# sysbench --mysql-host=192.168.0.110 --mysql-port=3306 --mysql-user=wylwrite --mysql-password='123456' /usr/share/sysbench/oltp_read_write.lua --tables=10 --table_size=10000 prepare##/usr/share/sysbench/oltp_read_write.lua --》这个脚本的路径一定是要正确!!![root@clinet ~]# sysbench --mysql-host=192.168.0.110 --mysql-port=3306 --mysql-user=wylwrite --mysql-password='123456' /usr/share/sysbench/oltp_read_write.lua --tables=10 --table_size=100000 prepare
sysbench 1.0.17 (using system LuaJIT 2.0.4)
Creating table 'sbtest1'...
Inserting 100000 records into 'sbtest1'
Creating a secondary index on 'sbtest1'...
Creating table 'sbtest2'...
Inserting 100000 records into 'sbtest2'
Creating a secondary index on 'sbtest2'...
Creating table 'sbtest3'...
Inserting 100000 records into 'sbtest3'
Creating a secondary index on 'sbtest3'...
Creating table 'sbtest4'...
Inserting 100000 records into 'sbtest4'
Creating a secondary index on 'sbtest4'...
Creating table 'sbtest5'...
Inserting 100000 records into 'sbtest5'
Creating a secondary index on 'sbtest5'...
Creating table 'sbtest6'...
Inserting 100000 records into 'sbtest6'
Creating a secondary index on 'sbtest6'...
Creating table 'sbtest7'...
Inserting 100000 records into 'sbtest7'
Creating a secondary index on 'sbtest7'...
Creating table 'sbtest8'...
Inserting 100000 records into 'sbtest8'
Creating a secondary index on 'sbtest8'...
Creating table 'sbtest9'...
Inserting 100000 records into 'sbtest9'
Creating a secondary index on 'sbtest9'...
Creating table 'sbtest10'...
Inserting 100000 records into 'sbtest10'
Creating a secondary index on 'sbtest10'...
wylwrite@sbtest 17:35 mysql>show tables;
+------------------+
| Tables_in_sbtest |
+------------------+
| sbtest1 |
| sbtest10 |
| sbtest2 |
| sbtest3 |
| sbtest4 |
| sbtest5 |
| sbtest6 |
| sbtest7 |
| sbtest8 |
| sbtest9 |
测试后的数据
也可以使用top或者glances等性能监控命令,进行监控
项目心得:
1.需要提前规划好整个集群的架构,防火墙和selinux要记得关闭,配置要细心
2.对MySQL的集群和高可用有了深入的理解,加深了处理大并发的理解
3.对自动化批量部署和监控有了更加多的应用和理解
4.进一步理解双vip+keepaliveds的高性能mysql集群,实现负载均衡有一定的理解
5.加深了对prometheus和grafana等监控工具的使用
6. mysqlrouter中间件软件,实现读写分离,让我更加明白读写分离的作用

这篇关于基于keepalived+gtid+双vip半同步主从复制的MySQL高性能集群的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








