本文主要是介绍Redis第11讲——Redis集群脑裂问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、什么是集群脑裂
所谓脑裂,就如同它的名字一样,大脑裂开了,一般来说是指一个分布式系统中有两个子集,然后每个子集都有一个自己的大脑(Leader/Master)。那么整个分布式系统就会存在多个大脑了,而且每个都认为自己是正常的,这就会导致数据不一致或重复写入的问题。
在Redis集群中,每个节点的部署方式一般都是【一主多从】,主节点提供写操作,从节点提供读操作。如果主节点此时发生网络故障,与从节点断开连接了,但主节点与客户端是正常的,客户端依旧向主节点写入数据。
这时哨兵节点发现主节点有故障失联了,于是哨兵节点就会从 从节点选出一个leader作为新主节点,这时脑裂就出现了。
突然这时原主节点网络好了,然而此时故障转移已完毕,已经有新主节点了,那么原主节点就会降级为新主节点的从节点,新主节点会向所有实例发送slave of命令,让所有实例重新全量同步,在全量同步之前,从节点会先清空自己的数据,那么客户端在原主节点故障期间写入的数据就丢失了。

二、脑裂的发生
Redis的脑裂问题可能发生在网络分区或者主节点出现问题的时候:
- 网络分区:网络故障或分区导致了不同子集之间的通信中断。Master、哨兵和Slave节点被分割为了两个网络,此时哨兵发现和Master连接不上,就会发起主从切换,选出一个新的Master,这就出现了两个主节点(如上图)。
- 主节点问题:主节点出现问题,导致不同的子集认为它们是正常的主节点。Master出现问题,哨兵开始主从切换,但在切换过程中主节点又恢复了,这时候可能会导致一部分slave节点认为它是Master,而另一部分新选出了一个Matser(如第五节图)。
三、脑裂导致的问题
从上面图中可以清楚地看到脑裂的危害,这里再总结一下:
- 数据不一致:不同子集之间可能对同一数据进行不同的写入,导致数据不一致。
- 重复写入:在脑裂问题解决后,不同子集可能尝试将相同的写操作应用到主节点上,导致数据重复。
- 数据丢失:新选出来的Matser会向所有的实例发送slave of命令,让所有实例重新进行全量同步,在此之前会先清空实例上的数据,所以在主从切换期间,原Matser上执行的写命令也会被清空。
四、解决方案
脑裂的主要原因其实就是哨兵集群认为主节点出现"假故障"了,于是开始主从切换,选举出了新的主节点,这就导致短暂的出现了两个主节点。
所以应对脑裂的解决办法应该是取限制原主库接收请求,Redis提供了两个配置项(已翻译):
# 如果有少于 N 个从节点连接且滞后时间小于或等于 M 秒,主节点可以停止接受写入操作。
# 这些 N 个从节点需要处于“在线”状态。
# 滞后时间必须小于或等于指定值,以秒为单位,是从上次接收到的从节点ping的时间计算出来的,
# 通常每秒发送一次。
# 此选项不能保证 N 个副本会接受写入操作,但会限制在不足够的从节点可用时丢失写入的暴露窗口# 到指定的秒数。
# 例如,要求至少有 3 个滞后时间小于或等于 10 秒的从节点,请使用:
min-slaves-to-write 3
min-slaves-max-lag 10再解释下:
- min-slaves-to-write:主库能进行数据同步的最少从库数量。
- min-slaves-max-lag:主从进行数据复制时,从库给主库发送ACK消息的最大延迟秒数。
这两项必须同时满足,不然主节点会禁止写入操作,这就解决了因脑裂导致数据丢失的问题。
举个例子,我们把min-slaves-to-write设置为1,把min-slaves-max-lag设置为10。
如果Master节点因为某些原因挂了12s,导致哨兵判断主节点客观下线,开始主从切换。
同时,因为原Master宕机了12s,没有一个(min-slaves-to-write)从节点与主节点之间的数据复制在10s(min-slaves-max-lag)内,不满足配置要求,原Master就无法执行写操作了。
五、为什么不能彻底解决脑裂问题
我们来看一个场景:
我们把min-slaves-to-write设置为1,把min-slaves-max-lag设置为10,同时把down-after-milliseconds设置为8s,也就是如果8秒连不上主节点,哨兵就会进行主从切换。
假设Matser节点宕机8s,哨兵会判为客观下线,开始主从切换,但是这个过程一共需要5秒。那如果主从切换过程中,主节点在第9秒恢复运行了,而min-slaves-max-lag 10s那么主节点还是可以写的。
那么在9s~12秒期间原主节点还是可以接收客户端传的写命令并且执行,新主节点执行slave of命令后,这个期间写的数据就会丢失。
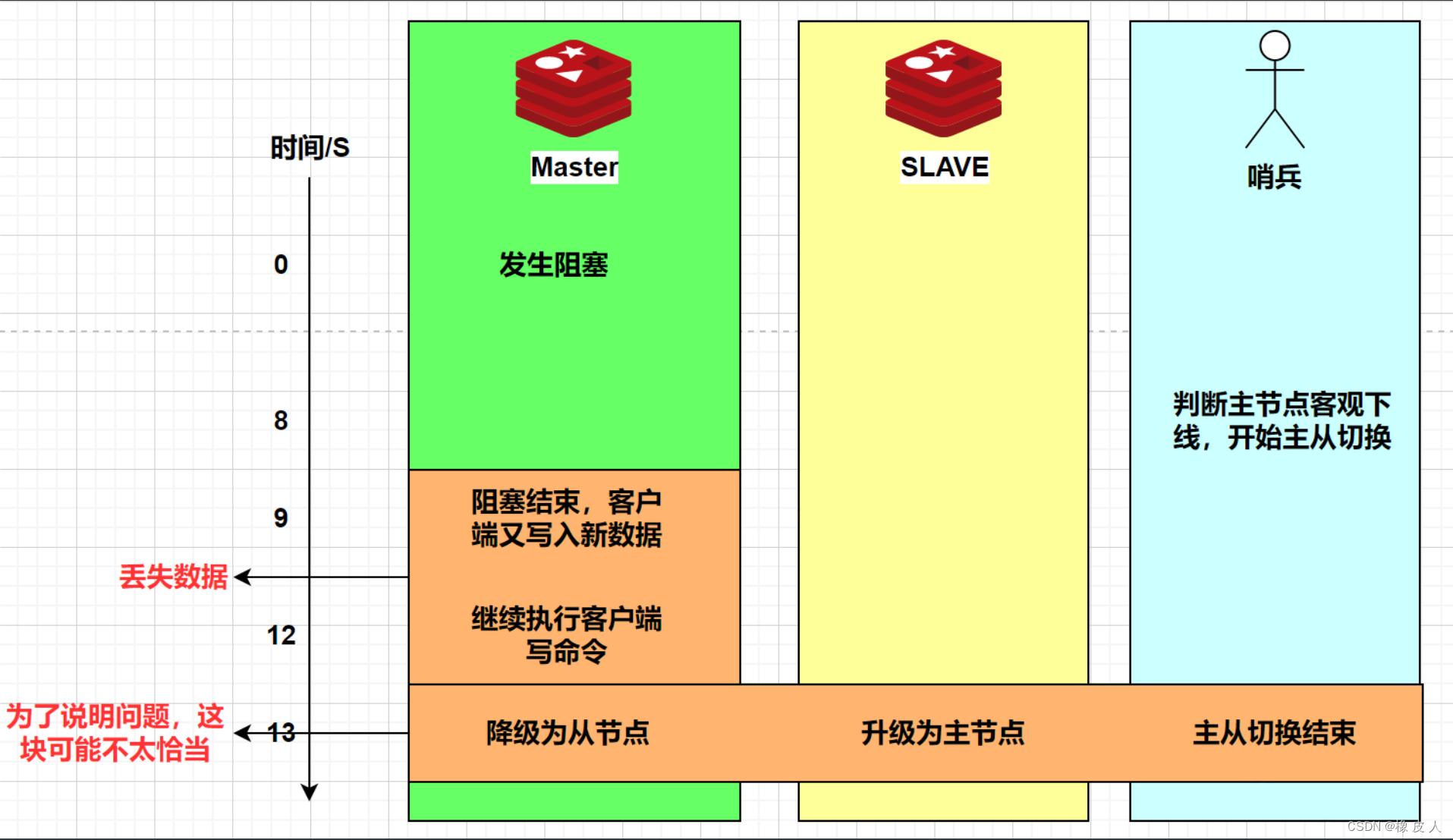
所以Redis脑裂可以采用min-slaves-to-write和min-slaves-max-lag合理配置尽量规避,但无法彻底解决。
End:希望对大家有所帮助,如果有纰漏或者更好的想法,请您一定不要吝啬你的赐教🙋。
这篇关于Redis第11讲——Redis集群脑裂问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









