脑裂专题

面试题:Zookeeper是如何解决脑裂问题
前言 这是分布式系统中一个很实际的问题,书上说的不是很详细,整理总结一下。 1、脑裂和假死 1.1 脑裂 官方定义:当一个集群的不同部分在同一时间都认为自己是活动的时候,我们就可以将这个现象称为脑裂症状。通俗的说,就是比如当你的 cluster 里面有两个结点,它们都知道在这个 cluster 里需要选举出一个 master。那么当它们两之间的通信完全没有问题的时候,就会达成共识,选出其中
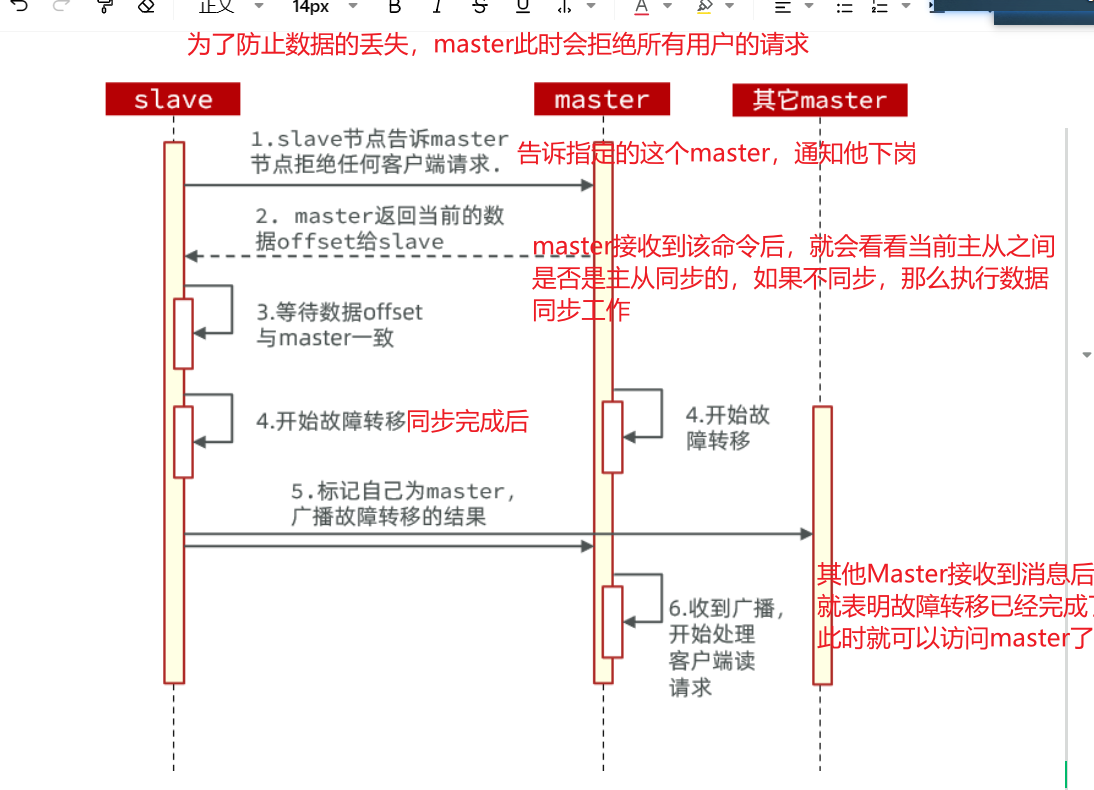
Redis高级----主从、哨兵、分片、脑裂原理
目前已更新系列: 当前:Redis高级----主从、哨兵、分片的原理 计算机网络--面试知识总结一 计算机网络-----面试知识总结二 计算机网络--面试总结三(Http与Https) 计算机网络--面试总结四(HTTP、RPC、WebSocket、SSE)-CSDN博客 知识积累之ThreadLocal---InheritableThreadLocal总结 本次Redis的

Redis缓存雪崩(主从复制、哨兵模式(脑裂)、分片集群)
缓存雪崩: 在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。 方法一: 给不同key的TTL添加随机值,以此避免同一时间大量key失效。(用于解决同一时间大量key过期,后面的方法用于解决redis宕机) 方法二: 使用Redis集群提高服务可用性(哨兵模式、分片集群) 主从复制(解决高并发读): 在讲哨兵模式之前,我们需要先了解一

Redis——Redis集群脑裂问题
Redis集群的脑裂问题(Split-Brain)是一个在分布式系统中可能发生的严重问题,特别是在基于主从复制和哨兵(Sentinel)机制的Redis集群环境中。以下是对Redis集群脑裂问题的详细阐述: 定义 Redis集群脑裂问题指的是在网络分区或其他故障的情况下,Redis集群的多个节点之间失去通信,导致它们各自形成独立的、都认为自己是主节点的分区。这时,每个分区都可以接受写请求,从而

让我们聊聊脑裂这事情
摘要: 分布式系统很难,为什么难,其实还是数据一致性的问题。最近在看Erlang中和Mnesia相关的一些东西,想起了这个话题来了。 万事皆有因 最近IM云平台也好,社交应用也好,大量的使用ejabberd的厂商涌现出来了。不过所有使用ejabberd厂商可能都会遇到Mnesia脑裂的问题。在这里打算简单的谈谈脑裂这个事情。 什么是脑裂 我在这里面给个非官方的定义吧。当一个
面试题:Kafka中Controller的作用是什么?选举流程是怎样的?以及如何避免脑裂问题?
题目来源 网上冲浪:还不懂分布系统,速看深度剖析Kafka Controller选举过程 在查找关于Kafka单机分区的上限以及分区多了会有怎样的问题的时候,发现了这个比较有趣的问题,就记录了下来。 一般所有的分布式系统,都会涉及到这个问题:脑裂、以及如何避免脑裂问题。 题目描述 Kafka中Controller的作用是什么?Kafka中Controller的选举流程是什么?Kafka脑裂是
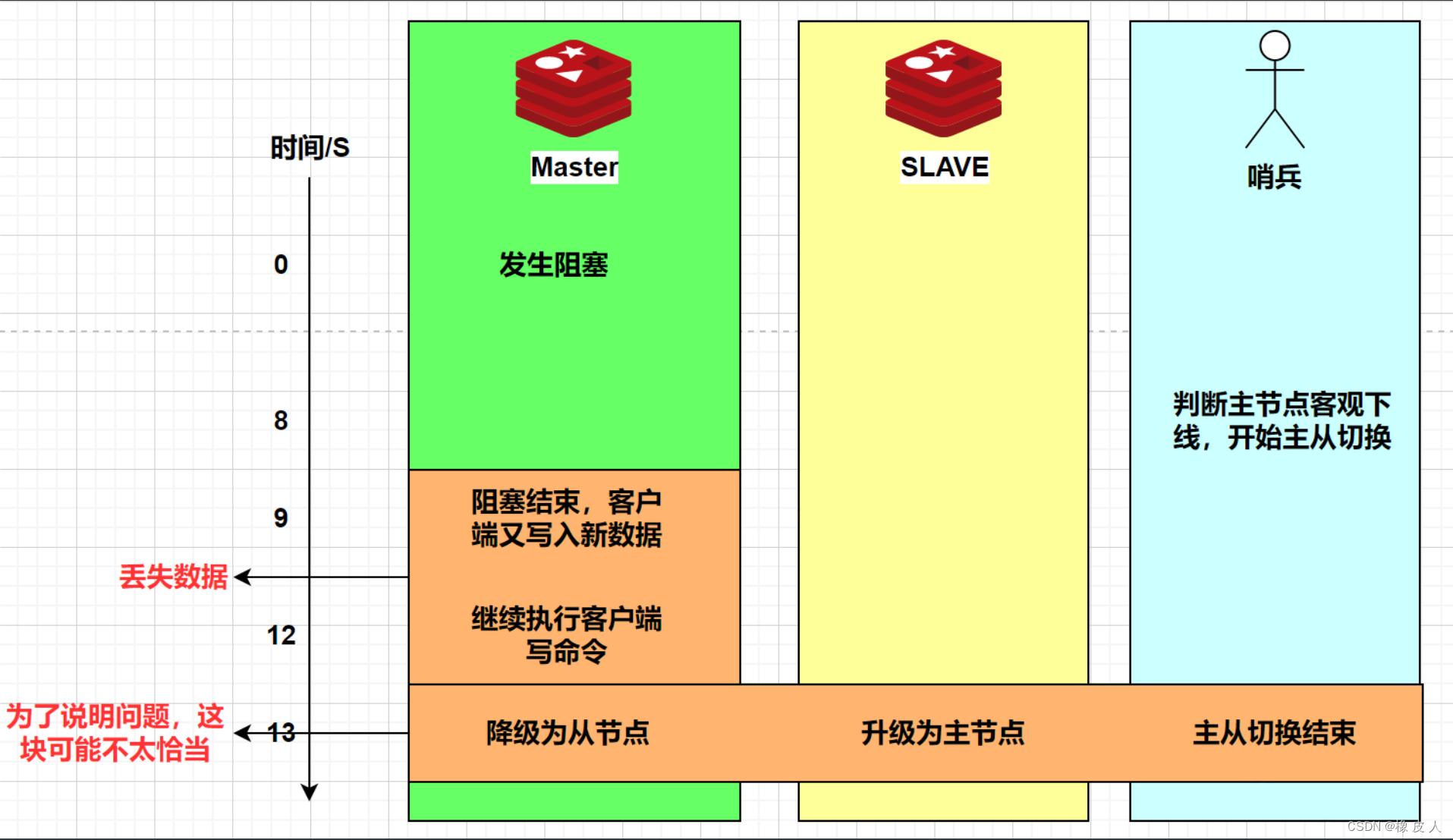
Redis第11讲——Redis集群脑裂问题
一、什么是集群脑裂 所谓脑裂,就如同它的名字一样,大脑裂开了,一般来说是指一个分布式系统中有两个子集,然后每个子集都有一个自己的大脑(Leader/Master)。那么整个分布式系统就会存在多个大脑了,而且每个都认为自己是正常的,这就会导致数据不一致或重复写入的问题。 在Redis集群中,每个节点的部署方式一般都是【一主多从】,主节点提供写操作,从节点提供读操作。如果主节点此时发生网络故
Zookeeper中的脑裂
简单点来说,脑裂(Split-Brain) 就是比如当你的 cluster 里面有两个节点,它们都知道在这个cluster 里需要选举出一个 master。那么当它们两个之间的通信完全没有问题的时候,就会达成共识,选出其中一个作为 master。但是如果它们之间的通信出了问题,那么两个结点都会觉得现在没有 master,所以每个都把自己选举成 master,于是 cluster 里面就会有两个 m
Redis的脑裂问题
Redis 脑裂(Split-brain)问题是指在分布式系统中,特别是基于主从复制和哨兵(Sentinel)模式的Redis集群中,由于网络分区(network partition)而导致部分节点组成了独立可用的服务,它们各自认为自己是唯一合法的服务提供者,这样就会出现多个独立的“主节点”,进而可能引发数据不一致的问题。 具体来说,在Redis环境下,当主节点与一部分从节点之间因网络问题而失去

Split Brain Resolver-akka集群脑裂问题解决
Split Brain Resolver-akka集群脑裂问题解决 Akka集群脑裂_akka脑裂-CSDN博客 操作 Akka 集群时必须考虑如何处理网络分区(又称裂脑场景)和机器崩溃(包括 JVM 和硬件)失败)。如果您使用集群单例或集群分片,这对于正确行为至关重要,特别是与 Akka Persistence 一起使用。 使用 Akka Split Brai

什么是脑裂?Zookeeper怎么解决脑裂问题的?
什么是脑裂 脑裂(split-brain)就是“大脑分裂”,也就是本来一个“大脑”被拆分了两个或多个“大脑”,我们都知道,如果一个人有多个大脑,并且相互独立的话,那么会导致人体“手舞足蹈”,“不听使唤”。 脑裂通常会出现在集群环境中,比如ElasticSearch、Zookeeper集群,而这些集群环境有一个统一的特点,就是它们有一个大脑,比如ElasticSearch集群中有Master节点,

【LVS实战】05 keepalived脑裂问题解决方案
Keepalived的作用是检测服务器的状态,如果有一台web服务器宕机,或工作出现故障,Keepalived将检测到,并将有故障的服务器从系统中剔除,同时使用其他服务器代替该服务器的工作,当服务器工作正常后Keepalived自动将服务器加入到服务器群中,这些工作全部自动完成,不需要人工干涉,需要人工做的只是修复故障的服务器。 什么是脑裂 脑裂(split-brain):指在一个高可用(HA

zookeeper脑裂问题(无法自动解决,只能重启解决)
A、B、C三个节点,A为leader,BC为follower 一、A和BC断开 1、当B、C都与A断开时,A连接不到其他服务节点,认为其他节点都宕机了,此时A仍然认为自己是leader,继续提供服务,读服务没问题,可继续;当使用写服务时,由于提交事物无法获得过半保证,事物无法提交,所以不能提供写服务; 2、而B、C是可以连通的,BC两个节点过半,可以重新选主,假如B选为leader,则B读写
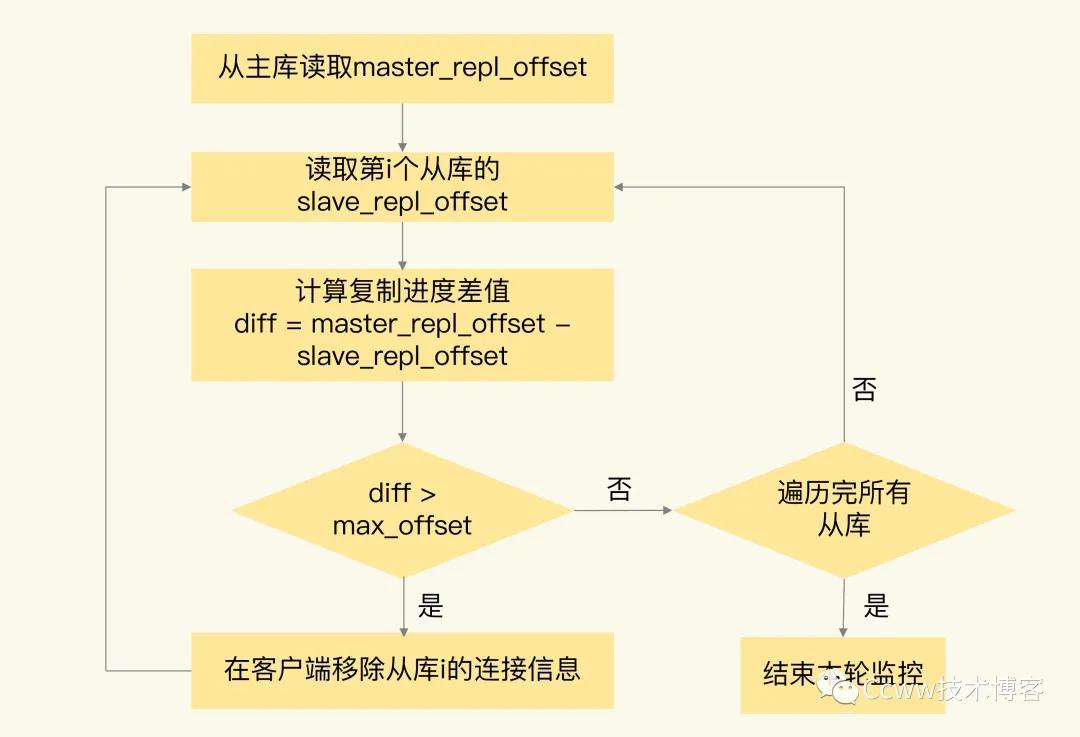
Redis高可用总结:Redis主从复制、哨兵集群、脑裂
在实际的项目中,服务高可用非常重要,如,当Redis作为缓存服务使用时, 缓解数据库的压力,提高数据的访问速度,提高网站的性能 ,但如果使用Redis 是单机模式运行 ,只要一个服务器宕机就不可以提供服务,这样会可能造成服务效率低下,甚至出现其相对应的服务应用不可用。 因此为了实现高可用,Redis 提供了哪些高可用方案? Redis主从复制Redis持久化哨兵集群... Redis
MongoDB脑裂恢复
MongoDB脑裂恢复 故障现象故障处理 故障现象 此环境为3台MongoDB搭建副本集,其中两台mongodb由于外部原因导致服务异常,目前副本集只存活一台,且为从库。 故障处理 将已经宕机或暂时无法恢复的mongodb节点,优先级和投票权都设置为0,然后执行下面命令强制重新更新集群配置。 或者执行rs.conf 输出集群配置内容,拷贝到本地文档,从members中去掉已经
ZK和redis中是否会发生脑裂问题?
首先介绍一下什么是脑裂? 简单的说,就好比一个人有两个大脑,这种情况下,就不知道应该受那个大脑控制了。 在redis或者zk集群中,就是主从结构中出现了多个master。 zk中会出现脑裂现象吗? 不会:因为zk集群中,leader的选举有一个过半机制。 一个集群的机器分布在AB两个机房,每个机房的数量是相同的: 正常情况下,zk会选举出一个leader,假设在A机房,如果某个时间,
集群脑裂导致数据丢失怎么办?
什么是脑裂? 先来理解集群的脑裂现象,这就好比一个人有两个大脑,那么到底受谁控制呢? 那么在 Redis 中,集群脑裂产生数据丢失的现象是怎样的呢? 在 Redis 主从架构中,部署方式一般是「一主多从」,主节点提供写操作,从节点提供读操作。 如果主节点的网络突然发生了问题,它与所有的从节点都失联了,但是此时的主节点和客户端的网络是正常的,这个客户端并不知道 Redis 内部已经出现了问题
mysql热备脑裂问题补充
当其中一台网络断了(自动退出集群节点,standalone),重新连网后:(需要重新加入集群) 对这台服务器操作: umount /drbddata drbdadm secondary r0 drbdadm disconnect r0 drbdadm -- --discard-my-data connect r0 cat /proc/drbd 对正在运行的服务器操作: drbdadm