本文主要是介绍LeetCode-146. LRU 缓存【设计 哈希表 链表 双向链表】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
LeetCode-146. LRU 缓存【设计 哈希表 链表 双向链表】
- 题目描述:
- 解题思路一:双向链表,函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。一张图:
- 知识点__slots__
- 解题思路二:0
- 解题思路三:0
题目描述:
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
- LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存
- int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
- void put(int key, int value) 如果关键字 key 已经存在,则变更其数据值 value ;如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
示例:
输入
[“LRUCache”, “put”, “put”, “get”, “put”, “get”, “put”, “get”, “get”, “get”]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出
[null, null, null, 1, null, -1, null, -1, 3, 4]
解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
提示:
1 <= capacity <= 3000
0 <= key <= 10000
0 <= value <= 105
最多调用 2 * 105 次 get 和 put
解题思路一:双向链表,函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。一张图:
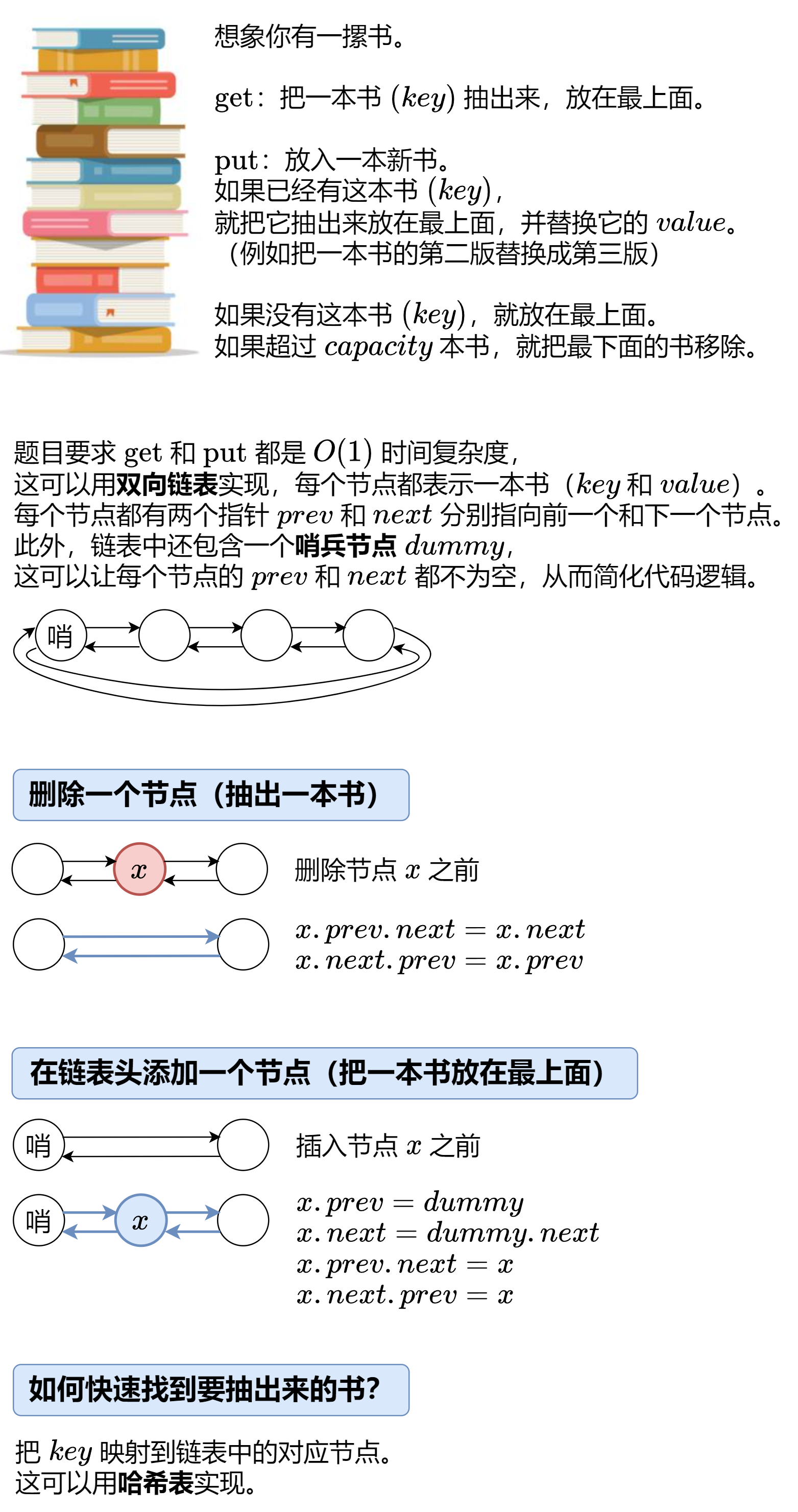
class Node:__slots__ = 'prev', 'next', 'key', 'value' # 提高访问属性的速度,并节省内存def __init__(self, key = 0, value = 0):self.key = keyself.value = valueclass LRUCache:def __init__(self, capacity: int):self.capacity = capacityself.dummy = Node() # 哨兵节点self.dummy.prev = self.dummyself.dummy.next = self.dummyself.key_to_node = dict()def get(self, key: int) -> int:node = self.get_node(key)return node.value if node else -1def put(self, key: int, value: int) -> None:node = self.get_node(key)if node: # 有这本书node.value = value # 更新 valuereturn self.key_to_node[key] = node = Node(key, value) # 新书self.push_front(node) # 放在最上面if len(self.key_to_node) > self.capacity: # 书太多了back_node = self.dummy.prevdel self.key_to_node[back_node.key] # 去掉最后一本书self.remove(back_node) # 去掉最后一本书def get_node(self, key: int) -> Optional[Node]:if key not in self.key_to_node: # 没有这本书return Nonenode = self.key_to_node[key] # 有这本书self.remove(node) # 把这本书抽出来self.push_front(node) # 放在最上面return nodedef remove(self, x: Node) -> None: # 删除一个节点(抽出一本书)x.prev.next = x.nextx.next.prev = x.prevdef push_front(self, x: Node) -> None: # 在链表头添加一个节点(把一本书放在最上面)x.prev = self.dummyx.next = self.dummy.nextx.prev.next = xx.next.prev = x# Your LRUCache object will be instantiated and called as such:
# obj = LRUCache(capacity)
# param_1 = obj.get(key)
# obj.put(key,value)
时间复杂度:O(1)
空间复杂度:O(min(p,capacity)),其中 p 为 put 的调用次数。
知识点__slots__
slots 是 Python 中用于优化类的属性访问和节省内存的特殊属性。当你定义一个类时,通常每个实例对象都会有一个字典来存储其属性和方法,这种灵活性使得可以在运行时动态地添加、修改和删除属性。然而,对于某些需要高性能和节省内存的场景,这种灵活性可能会显得过于浪费资源。
slots 的作用就是告诉解释器:这个类的实例只能拥有 slots 中指定的属性,而不再使用字典来存储属性。这样做的好处有两个:
-
提高访问速度: 由于属性被限定在预定义的集合中,访问这些属性时不再需要通过字典查找,而是可以直接定位到它们,因此访问速度会更快。
-
节省内存: 没有了动态属性字典,实例对象所需的内存空间会更小。这在需要大量创建实例对象的场景中尤为有用,可以有效地节省内存资源。
使用 slots 时,你需要在类中定义一个 slots 属性,这个属性是一个字符串组成的元组,用于指定类的实例可以拥有的属性名称。例如:
class MyClass:__slots__ = ('attr1', 'attr2')def __init__(self, a, b):self.attr1 = aself.attr2 = b在这个例子中,MyClass 的实例只能拥有 attr1 和 attr2 这两个属性,而不能拥有其他动态添加的属性。这样就提高了访问速度和节省了内存。
需要注意的是,使用 slots 也有一些限制:
- 不能动态添加新的属性,因为 slots 指定了固定的属性集合。
- 每个实例只能拥有 slots 中指定的属性,而不能拥有其他属性。
- 继承时如果子类定义了 slots,则父类的 slots 不会被继承。
因此,在需要优化属性访问速度和节省内存的情况下,可以考虑使用 slots。
解题思路二:0
时间复杂度:O(n)
空间复杂度:O(n)
解题思路三:0
时间复杂度:O(n)
空间复杂度:O(n)
这篇关于LeetCode-146. LRU 缓存【设计 哈希表 链表 双向链表】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







