本文主要是介绍机器学习每周挑战——信用卡申请用户数据分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!


数据集的截图
# 字段 说明 # Ind_ID 客户ID # Gender 性别信息 # Car_owner 是否有车 # Propert_owner 是否有房产 # Children 子女数量 # Annual_income 年收入 # Type_Income 收入类型 # Education 教育程度 # Marital_status 婚姻状况 # Housing_type 居住方式 # Birthday_count 以当前日期为0,往前倒数天数,-1代表昨天 # Employed_days 雇佣开始日期。以当前日期为0,往前倒数天数。正值意味着个人目前未就业。 # Mobile_phone 手机号码 # Work_phone 工作电话 # Phone 电话号码 # EMAIL_ID 电子邮箱 # Type_Occupation 职业 # Family_Members 家庭人数 # Label 0表示申请通过,1表示申请拒绝# 知道了数据集的情况,我们来看问题 # 问题描述 # 用户特征与信用卡申请结果之间存在哪些主要的相关性或规律?这些相关性反映出什么问题? # # 从申请用户的整体特征来看,银行信用卡业务可能存在哪些风险或改进空间?数据反映出的问题对银行信用卡业务有哪些启示? # # 根据数据集反映的客户画像和信用卡申请情况,如果你是该银行的风控或市场部门负责人,你会提出哪些战略思考或建议? # # 参考分析角度 # 用户画像分析 # # 分析不同人口统计学特征(如性别、年龄、婚姻状况等)对信用卡申请的影响和规律 # 分析不同社会经济特征(如收入、职业、教育程度等)与申请结果的关系 # 特征选取和模型建立 # # 评估不同特征对预测信用卡申请结果的重要性,进行特征筛选 # 建立信用卡申请结果预测模型,评估模型性能 # 申请结果分析 # # 分析不同用户群的申请通过率情况,找到可能的问题原因 # 对申请被拒绝的用户进行细分,寻找拒绝的主要原因# 知道问题后,我们先进行数据预处理
print(data.info()) # 有缺失值
print(data.isnull().sum() / len(data)) # 可以看出有的列缺失值有点多# GENDER 7 Annual_income 23 Birthday_count 22 Type_Occupation 488 # GENDER 0.004522 Annual_income 0.014858 Birthday_count 0.014212 Type_Occupation 0.315245 # Type_Occupation 0.315245 这一列缺失值数据占比有点高了,但是,这一列是职业,跟我们的业务相关性较高,我觉得应该将缺失值单独分为一个属性 # 其他的列的缺失值较少,woe们可以填充,也可以删除,我觉得对于信用卡这种模型精度要求较严的,我们就删除,填充的值不是很准确,可能对模型造成一定的影响 # 观察数据,我们可以发现,ID,电话号,邮箱这种特征对我们来说没有用 ,生日记数我也感觉没用
data['Type_Occupation'] = data['Type_Occupation'].fillna("无")
data = data.dropna()
data = data.drop(['Ind_ID','Mobile_phone','Work_Phone','Phone','EMAIL_ID','Birthday_count'],axis=1)# 分析不同人口统计学特征(如性别、年龄、婚姻状况等)对信用卡申请的影响和规律 # 分析不同社会经济特征(如收入、职业、教育程度等)与申请结果的关系
features = ['GENDER','EDUCATION','Marital_status','Annual_income','Type_Occupation','Type_Income']for i in range(len(features)):# plt.subplot(2,3,i+1)plt.figure()if data[features[i]].dtype == float:data[features[i]] = pd.cut(data[features[i]],bins=10)features_data = data[features[i]].value_counts()plt.bar(features_data.index.astype(str),features_data.values)else:features_data = data.groupby(features[i])['label'].sum()features_data = features_data.sort_values(ascending=False)plt.bar(features_data.index,features_data.values)plt.title(features[i]+"与信用卡申请之间的关系")plt.xlabel(features[i])plt.ylabel("总数量")plt.xticks(rotation=60)plt.tight_layout() 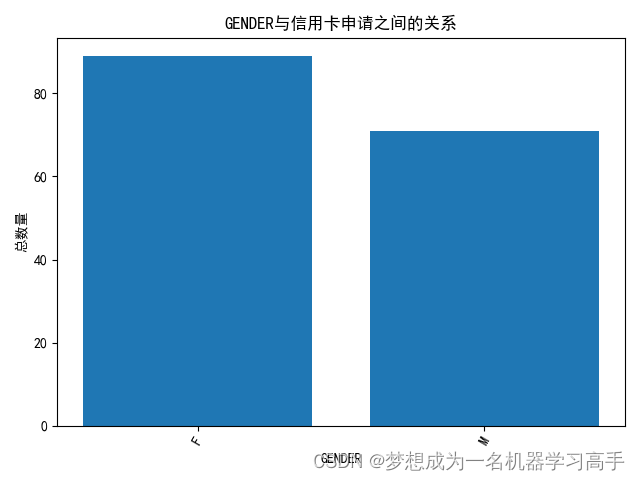


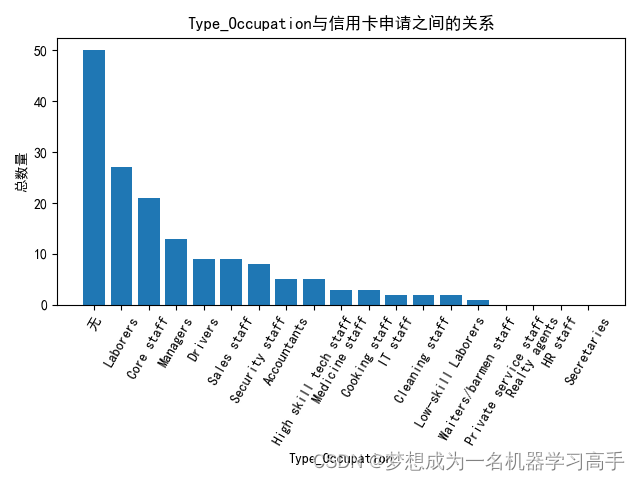
# 这样我们可以看出各个特征列与标签列之间的关系 # 我们看一下标签列的分布情况
labels = data['label'].value_counts()
# print(labels)plt.figure()
plt.bar(labels.index,labels.values)
plt.title("信用卡申请人数比较")
plt.xticks([0,1],['未申请到信用卡','成功申请到信用卡'])
# 由图可以看出,申请到信用卡的人数比没申请到信用卡的人数少,数据存在不均衡,因此我们建立模型时,要注意处理不均横的数据 # 由于计算机只能处理数字,因此我们先将字符型数据转换为数值型,这里我们可以用标签编码或者独热编码。这里我们选择标签编码
data['Annual_income'] = pd.factorize(data['Annual_income'])[0]
data['label'] = data['label'].astype(int)for i in data.columns:if data[i].dtype == object:encode = LabelEncoder()data[i] = encode.fit_transform(data[i])X = data.drop('label',axis=1)
y = data.labelrfc = RandomForestClassifier(n_estimators=100,random_state=42)
rfc.fit(X,y)importance = rfc.feature_importances_
sort_importance = importance.argsort()
feature = X.columnsplt.figure()
plt.barh(range(len(sort_importance)),importance[sort_importance])
plt.yticks(range(len(sort_importance)), [feature[i] for i in sort_importance])
plt.title('特征重要性分析')
plt.xlabel("特征重要性")# plt.show()# 通过特征重要性分析我们可以看出离职天,年收入和职业类型与信用卡的申请有很大的关联X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=42)#分离少数类和多数类
X_minority = X_train[y_train == 1]
y_minority = y_train[y_train == 1]
X_majority = X_train[y_train == 0]
y_majority = y_train[y_train == 0]
X_minority_resampled = resample(X_minority, replace=True, n_samples=len(X_majority), random_state=42)
y_minority_resampled = resample(y_minority, replace=True, n_samples=len(y_majority), random_state=42)
new_X_train = pd.concat([X_majority, X_minority_resampled])
new_y_train = pd.concat([y_majority, y_minority_resampled])rfc = RandomForestClassifier(n_estimators=100,random_state=42)
rfc.fit(new_X_train,new_y_train)
rfc_y_pred = rfc.predict(X_test)class_report_rfc = classification_report(y_test,rfc_y_pred)
print(class_report_rfc)# 有了准确率,F1分数等,我们来绘制混淆矩阵
rfc_corr = confusion_matrix(y_test,rfc_y_pred)
plt.figure()
sns.heatmap(rfc_corr,annot=True,fmt='g')
plt.title('随机森林的混淆矩阵')
# plt.show()
print(rfc.predict_proba(X_test)[:1])
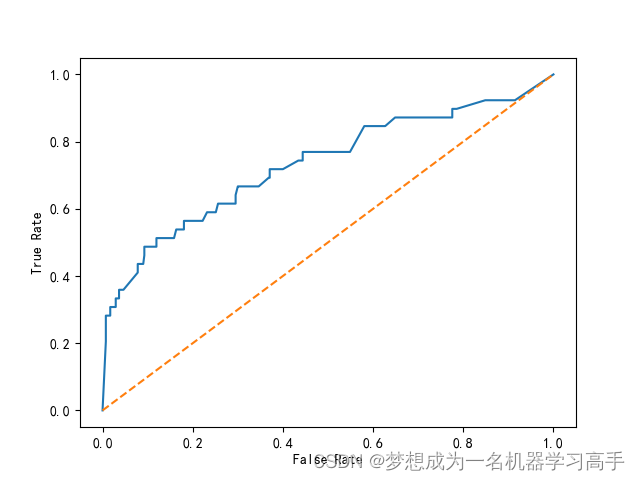
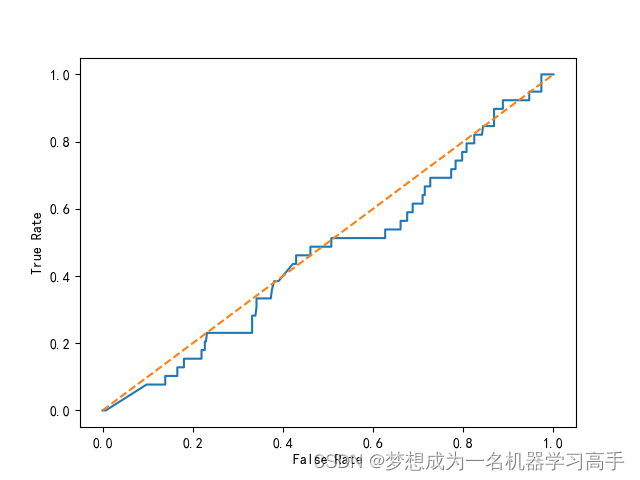
rfc_fpr,rfc_tpr,_ = roc_curve(y_test,rfc.predict_proba(X_test)[:,1])
rfc_roc = auc(rfc_fpr,rfc_tpr)plt.figure()
plt.plot(rfc_fpr,rfc_tpr,label='ROC(area = %0.2f)')
plt.plot([0,1],[0,1],linestyle='--')
plt.xlabel("False Rate")
plt.ylabel("True Rate")svm = SVC(kernel='rbf',probability=True,random_state=42)
svm.fit(new_X_train,new_y_train)
svm_y_pred = svm.predict(X_test)class_report_svm = classification_report(y_test,svm_y_pred)
print(class_report_svm)# 混淆矩阵
svm_corr = confusion_matrix(y_test,svm_y_pred)
plt.figure()
sns.heatmap(svm_corr,annot=True,fmt='g')
plt.title('支持向量机(SVM)的混淆矩阵')svm_fpr,svm_tpr,_ = roc_curve(y_test,svm.predict_proba(X_test)[:,1])
svm_roc = auc(svm_fpr,svm_tpr)plt.figure()
plt.plot(svm_fpr,svm_tpr,label='ROC(area = %0.2f)')
plt.plot([0,1],[0,1],linestyle='--')
plt.xlabel("False Rate")
plt.ylabel("True Rate")Xgb = xgb.XGBClassifier(random_state=42,use_label_encoder=False)
Xgb.fit(new_X_train,new_y_train)
Xgb_y_pred = Xgb.predict(X_test)class_report_Xgb = classification_report(y_test,Xgb_y_pred)
print(class_report_Xgb)# 混淆矩阵
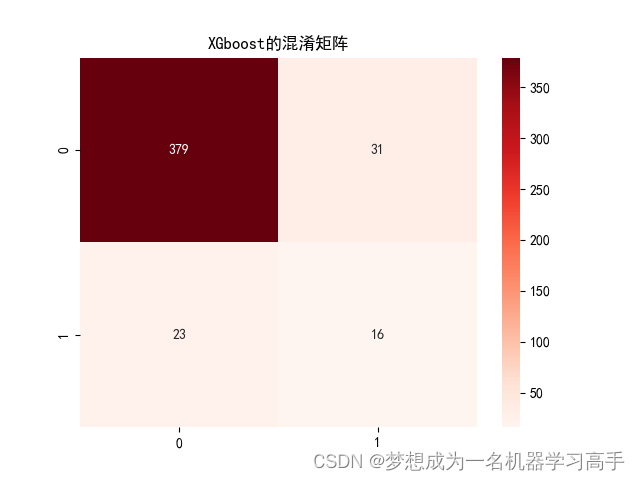
Xgb_corr = confusion_matrix(y_test,Xgb_y_pred)
plt.figure()
sns.heatmap(Xgb_corr,annot=True,fmt='g')
plt.title('XGboost的混淆矩阵')Xgb_fpr,Xgb_tpr,_ = roc_curve(y_test,Xgb.predict_proba(X_test)[:,1])
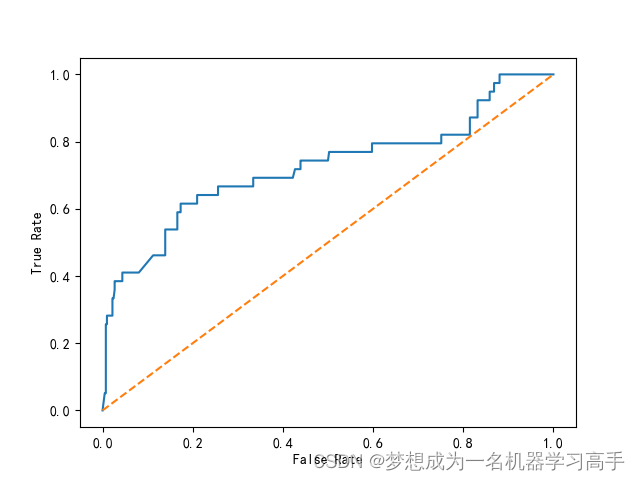
Xgb_roc = auc(Xgb_fpr,Xgb_tpr)plt.figure()
plt.plot(Xgb_fpr,Xgb_tpr,label='ROC(area = %0.2f)')
plt.plot([0,1],[0,1],linestyle='--')
plt.xlabel("False Rate")
plt.ylabel("True Rate")plt.show() 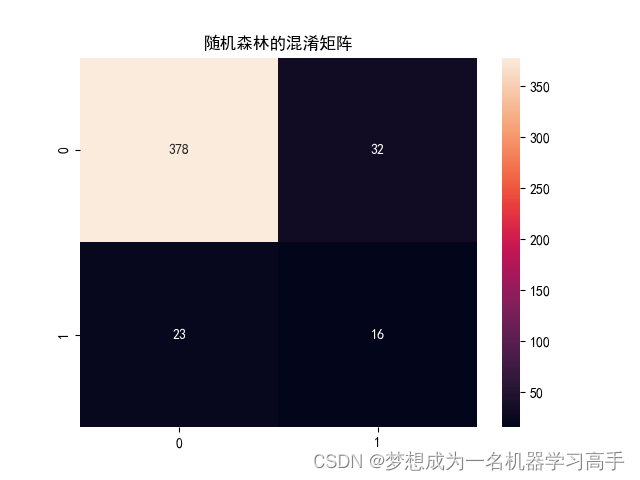

precision recall f1-score support (随机森林)
0 0.94 0.92 0.93 410 (0和1代表着标签列的0和1)
1 0.33 0.41 0.37 39
accuracy 0.88 449
macro avg 0.64 0.67 0.65 449
weighted avg 0.89 0.88 0.88 449
precision recall f1-score support (SVM)
0 0.95 0.05 0.10 410
1 0.09 0.97 0.16 39
accuracy 0.13 449
macro avg 0.52 0.51 0.13 449
weighted avg 0.88 0.13 0.10 449
precision recall f1-score support (XGboost)
0 0.94 0.92 0.93 410
1 0.34 0.41 0.37 39
accuracy 0.88 449
macro avg 0.64 0.67 0.65 449
weighted avg 0.89 0.88 0.88 449
这篇关于机器学习每周挑战——信用卡申请用户数据分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








