本文主要是介绍Transformer的代码实现 day03(Positional Encoding),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Positional Encoding的理论部分
- 注意力机制是不含有位置信息,这也就表明:“我爱你”,“你爱我”这两者没有区别,而在现实世界中,这两者有区别。
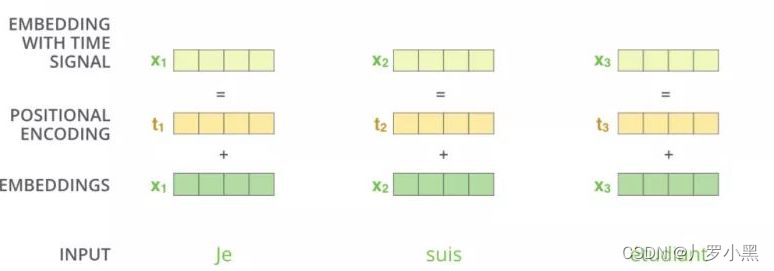
- 所以位置编码是在进行注意力计算之前,给输入加上一个位置信息,如下图:
- 位置编码的公式如下:
- 注意,pos表示该单词在句子中的位置,i表示该单词的输入向量的第i维度
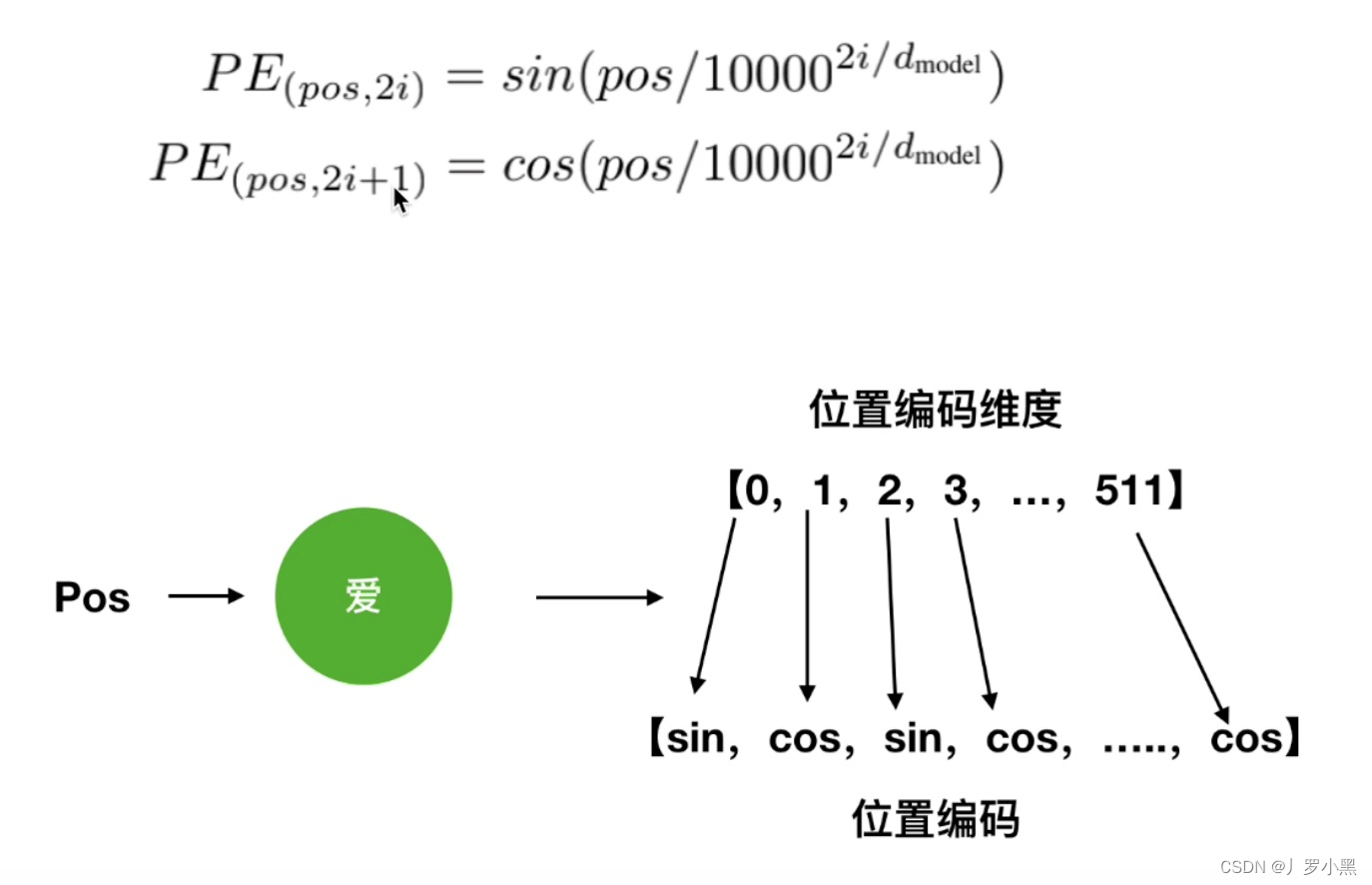
- 注意,pos表示该单词在句子中的位置,i表示该单词的输入向量的第i维度
- 由此我们可以得出不同位置之间的位置编码关系:
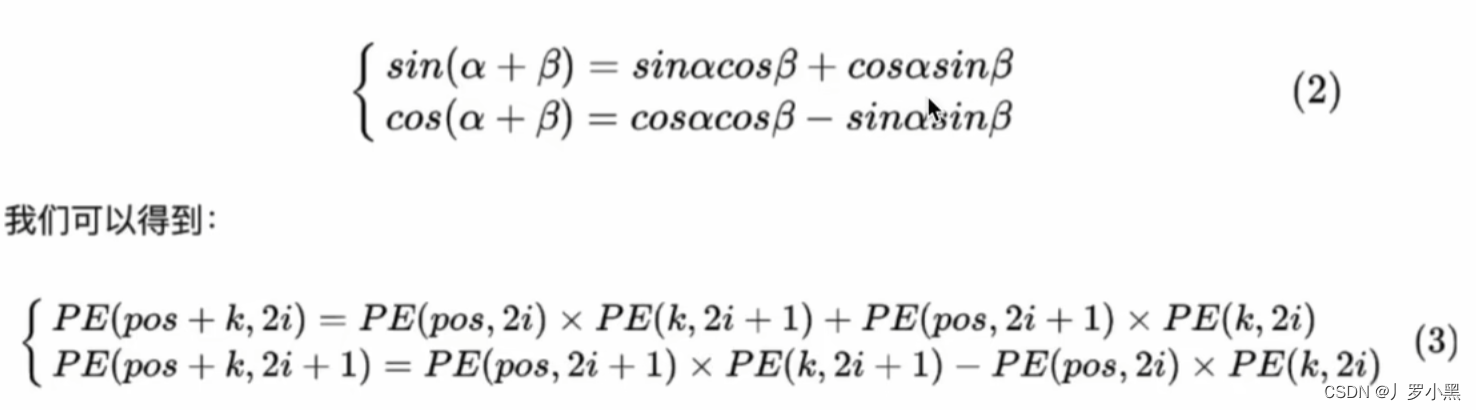
Positional Encoding代码
- 由于位置编码的公式固定,所以对于相同位置的位置编码也固定,即“我爱你”中的我,和“你爱我”中的你的位置编码相同
- 所以我们可以一次将所有要输入信息的位置编码都生成出来,之后需要哪个就传哪个
class PositionalEncoding(nn.Module):def __init__(self, dim, dropout, max_len=5000):super(PositionalEncoding, self).__init__()# 确保每个单词的输入维度为偶数,这样sin和cos能配对if dim % 2 != 0:raise ValueError("Cannot use sin/cos positional encoding with ""odd dim (got dim={:d})".format(dim))"""构建位置编码pepe公式为:PE(pos,2i/2i+1) = sin/cos(pos/10000^{2i/d_{model}})"""pe = torch.zeros(max_len, dim) # max_len 是解码器生成句子的最长的长度,假设是 10,dim为单词的输入维度# 将位置序号从一维变为只有一列的二维,方便与div_term进行运算,# 如将[0, 1, 2, 3, 4]变为:#[ # [0], # [1], # [2], # [3], # [4] #]position = torch.arange(0, max_len).unsqueeze(1)# 这里使用a^b = e^(blna)公式,来简化运算# torch.arange(0, dim, 2, dtype=torch.float)表示从0到dim-1,步长为2的一维张量# 通过以下公式,我们可以得出全部2i的(pos/10000^2i/dim)方便接下来的pe计算div_term = torch.exp((torch.arange(0, dim, 2, dtype=torch.float) *-(math.log(10000.0) / dim)))# 得出的div_term为从0开始,到dim-1,长度为dim/2,步长为2的一维张量# 将position与div_term做张量乘法,得到的张量形状为(max_len,dim/2)# 将结果取sin赋给pe中偶数维度,取cos赋给pe中奇数维度pe[:, 0::2] = torch.sin(position.float() * div_term)pe[:, 1::2] = torch.cos(position.float() * div_term)# 将pe的形状从(max_len,dim)变成(max_len,1,dim),在第二个维度上增加一个大小为1的新维度# 如从原始 pe 张量形状: (5, 4) #[ # [a1, b1, c1, d1], # [a2, b2, c2, d2], # [a3, b3, c3, d3], # [a4, b4, c4, d4], # [a5, b5, c5, d5] #]# 转换为:执行 unsqueeze(1) 后的 pe 张量形状: (5, 1, 4) #[ # [[a1, b1, c1, d1]], # [[a2, b2, c2, d2]], # [[a3, b3, c3, d3]], # [[a4, b4, c4, d4]], # [[a5, b5, c5, d5]] #]pe = pe.unsqueeze(1)# 将pe张量注册为模块的buffer。在PyTorch中,buffer是模型的一部分,但不包含可学习的参数(即不需要梯度)。# 这样做是因为位置编码在训练过程中是固定的,不需要更新。self.register_buffer('pe', pe)self.drop_out = nn.Dropout(p=dropout)self.dim = dimdef forward(self, emb, step=None):# 做乘法是因为在 Transformer 模型中,位置编码被加到输入张量中,而输入张量通常是词嵌入的向量,其值通常在较小的范围内。# 但是,在将位置编码添加到输入张量之前,我们希望将其值扩大到一个较大的范围,以便位置编码对输入的影响更加显著。# 注意:emb为输入张量,形状为(seq_len, dim),seq_len 表示输入的句子的长度,dim为单词的输入维度emb = emb * math.sqrt(self.dim)# 根据step来选择加入pe的哪一部分if step is None:# 如果pe的形状为(max_len, dim),那么pe[:a]表示:取pe的第0行到第a-1行的全部元素,得到的新二维张量的形状为(a, dim)# 而pe[:, a]表示:取pe的第a-1列的全部元素,得到的新一维张量的形状为(max_len)# 而pe[:, :a]表示:取pe的第0列到第a-1列的全部元素,得到的新二维张量的形状为(max_len,a)emb = emb + self.pe[:emb.size(0)]else:emb = emb + self.pe[step]emb = self.drop_out(emb)return emb
参考文献
- 04 Transformer 中的位置编码的 Pytorch 实现
这篇关于Transformer的代码实现 day03(Positional Encoding)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







