本文主要是介绍TransE模型:知识图谱特征经典学习算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转载自: https://zhuanlan.zhihu.com/p/133532605
需要知道的东西
什么是知识图谱,一种定义是“知识图谱是语义网络上的知识库”,也就是个多关系图。他的目的就是要表示出实体与实体之间的关系,实体指的是现实世界中的事物比如人、地名、概念、药物、公司等,关系则用来表达不同实体之间的某种联系,比如人-“居住在”-北京、张三和李四是“朋友”、逻辑回归是深度学习的“先导知识”等等。又比如人和人之间的关系可以是“朋友”,也可以是“同事”关系。构建这样的一个知识图谱就获得了一个结构化的知识库,当我们执行搜索的时候,就可以通过关键词提取("张三", "李四", "朋友")以及知识库上的匹配可以直接获得最终的答案[^fn:1]。
多关系数据的有向图里面的节点就是实体Entities,而边则象征着这样一个三元组(h, l, t),(head, label, tail),每个边表示的就是在实体head和tail之间有着名为label的关系。我们要做的是要学习出实体与关系之间的表示。
方法
文章强调使用了embedding 空间的translation来表示关系,从而得到了很好的效果,那么为什么“翻译”能够表示关系呢?实际上我觉得这里的translation表达的应该是转移。也就是说从一个向量转移到另一个向量,而转移的过程就是两个向量的关系,使用null转移向量就可以表示实体之间的等价关系了,所以看起来,用转移是可以表示的。
那么怎么表示转移呢?数轴中,a+b可以表示a向右移动了b个单位,那么h+l也可表示h移动了l个单位,因此答案呼之欲出,要使得h+l=t。
简单来说,TransE就是讲知识图谱中的实体和关系看成两个Matrix。实体矩阵结构为 ,其中n表示实体数量,d表示每个实体向量的维度,矩阵中的每一行代表了一个实体的词向量;而关系矩阵结构为 ,其中r代表关系数量,d表示每个关系向量的维度。TransE训练后模型的理想状态是,从实体矩阵和关系矩阵中各自抽取一个向量,进行L1或者L2运算,得到的结果近似于实体矩阵中的另一个实体的向量,从而达到通过词向量表示知识图谱中已存在的三元组 的关系。

TransE图示
TransE的算法过程如下:

这里注意,entity需要在每次更新前进行归一化,这是通过人为增加embedding的norm来防止Loss在训练过程中极小化。
TransE的Loss function (Hinge Loss Function) 为:
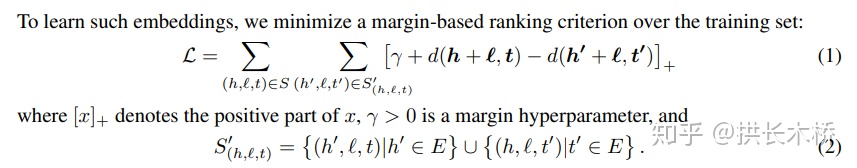
其中 表示x最小值为0, 即 , 表示负例的集合。
因此以norm = L2范数为例,求解正确三元组的h的相对于hinge loss function的梯度:
而L1范数的梯度则以[1,1,-1,1.....]形式出现。
对于模型中Margin的个人理解如下:margin 的作用相当于是一个正确triple与错误triple之前的间隔修正,margin越大,则两个triple之前被修正的间隔就越大,则对于词向量的修正就越严格。
开始阅读论文的时候在纠结一个问题,”这个模型的参数是什么?如何更新?“。后来通过读原文发现其实文章后续中有说明,第3章提到了参数的总量为 ,也就是说Loss更新的参数,是所有entities和relations的Embedding数据,每一次SGD更新的参数就是一个Batch中所有embedding的值。TransE里面SGD和一般机器学习方法或者深度学习中SGD中的参数还是有些区别的。
另外,距离公式 可以取L1 或者 L2 范数。 对于L1 范数, d()是求绝对值结果 ;而对于L2范数, d()有 。其中要注意的是,L1 范数在x = 0处不可导,所以需要使用次微分概念。另一方面,Loss function 希望达到的理想情况是,正确的triple的d(h + r , t) 尽可能的小,而错误triple的 尽可能大,这样才能让总体的loss趋向于0。因此在SGD的update过程中,正例中h 和r 逐渐减小,但t要逐渐增大;反例中 和 要增大,但 要减小。
测试环节中,可将测试集分为Raw及Filter两种情况,Filter是指过滤corrupted triplets中在training, validation,test三个数据集中出现的正确的三元组。这是因为只是图谱中存在1对N的情况,当在测试一个三元组的时,用其他实体去替换头实体或者尾实体,这个新生成的反例corrupted triple确可能是一个正确triple,因此当遇见这种情况时,将这个triple从测试中过滤掉,从而得到Filter测试结果。
这篇关于TransE模型:知识图谱特征经典学习算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





