本文主要是介绍海豚调度任务类型Apache SeaTunnel部署指南,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

Apache DolphinScheduler已支持Apache SeaTunnel任务类型,本文介绍了SeaTunnel任务类型如何创建,任务参数,以及任务样例。
一、Apache SeaTunnel
SeaTunnel 任务类型,用于创建并执行 SeaTunnel 类型任务。worker 执行该任务的时候,会通过 start-seatunnel-spark.sh 、 start-seatunnel-flink.sh 和 seatunnel.sh 命令解析 config 文件。
二、创建任务
- 点击项目管理 -> 项目名称 -> 工作流定义,点击“创建工作流”按钮,进入 DAG 编辑页面;
- 拖动工具栏的 任务节点到画板中。
三、任务参数
- 启动脚本:选择你想要运行任务的启动脚本,包括
seatunnel.sh, start-seatunnel-flink-13-connector-v2.sh, start-seatunnel-flink-15-connector-v2.sh, start-seatunnel-flink-connector-v2.sh, start-seatunnel-flink.sh, start-seatunnel-spark-2-connector-v2.sh, start-seatunnel-spark-3-connector-v2.sh, start-seatunnel-spark-connector-v2.sh, start-seatunnel-spark.sh - FLINK
- 运行模型:支持 run 和 run-application 两种模式
- 选项参数:用于添加 Flink 引擎本身参数,例如 -m yarn-cluster -ynm seatunnel
- SPARK
- 部署方式:指定部署模式,cluster client
- Master:指定 Master 模型,yarn local spark mesos,其中 spark 和 mesos 需要指定 Master 服务地址,例如:127.0.0.1:7077
- SEATUNNEL_ENGINE
- 部署方式:指定部署模式,cluster local
- 自定义配置:支持自定义配置或从资源中心选择配置文件
- 脚本:在任务节点那自定义配置信息,包括四部分:env source transform sink
四、任务样例
该样例演示为使用 Flink 引擎从 Fake 源读取数据打印到控制台。
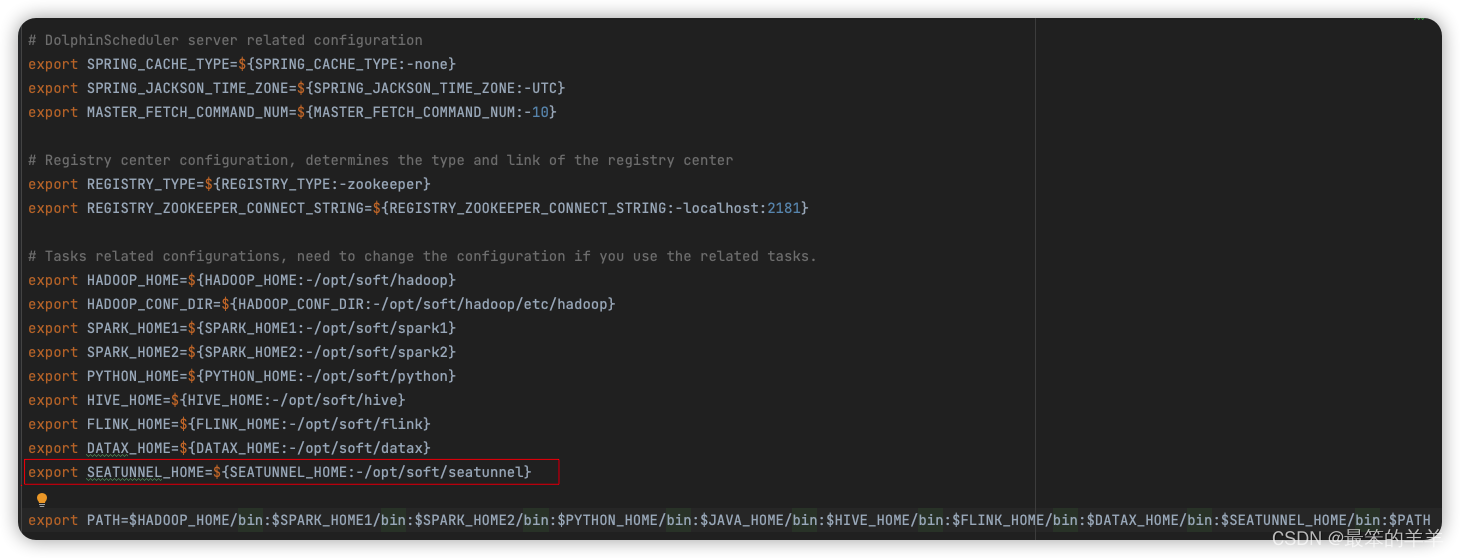
1.在 DolphinScheduler 中配置 SeaTunnel 环境 若生产环境中要是使用到 SeaTunnel 任务类型,则需要先配置好所需的环境,配置文件如下:/dolphinscheduler/conf/env/dolphinscheduler_env.sh。
 2.配置 SeaTunnel 任务节点 根据上述参数说明,配置所需的内容即可。
2.配置 SeaTunnel 任务节点 根据上述参数说明,配置所需的内容即可。
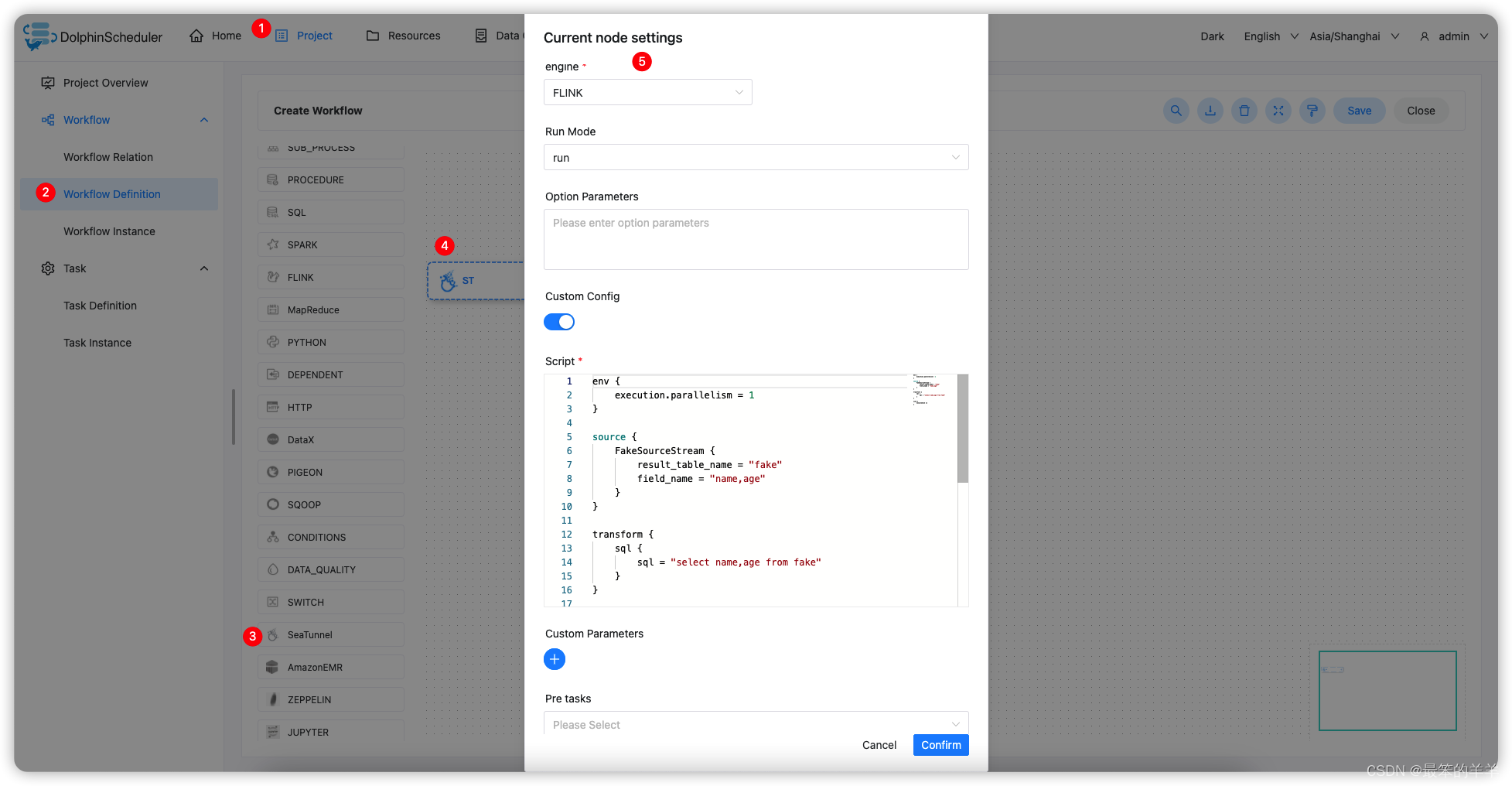
Config 样例
env {execution.parallelism = 1
}source {FakeSource {result_table_name = "fake"field_name = "name,age"}
}transform {sql {sql = "select name,age from fake"}
}sink {ConsoleSink {}
}————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/zhengzaifeidelushang/article/details/136685864
本文由 白鲸开源科技 提供发布支持!
这篇关于海豚调度任务类型Apache SeaTunnel部署指南的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



