本文主要是介绍一起重新开始学大数据-MySQL篇-Day33-SQL、建库建表、增删查改、聚合函数等,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
| 一起重新开始学大数据-MySQL篇-(1) |

| 什么是数据库 |

数据库是数据的仓库
与普通的数据仓库不同的是,数据库依据数据结构来组织数据,因为数据结构的存在,所以看到的数据时条理化的
数据库和普通文件系统的区别在于:数据库拥有数据结构,能都快速查找对应的数据
常说的XX数据库,其实就是XX数据库管理系统:数据库管理系统是一个软件,是数据库服务的体现
数据库分为关系型数据库和非关系型数据库:
.关系型:以行作为记录,列数相同
.非关系型:以列作为记录,行数随便
什么是关系型数据库
关系型数据库是依据关系模型创建数据库
关系模型就是一对一,一对多,多对多等关系模型,关系模型就是存储格式是以行列组成的二维表格,所以一个关系型数据库就是由二维表之间的联系所组成的一个数据组织
关系型数据库可以很好的存储一些关系模型的数据,比如老师对应学生的数据(“多对多”),一本书对应多个作者(“一对多”),一个人对应一个身份证号码(“一对一”)
什么是非关系型数据库
由于关系型太大和复杂,所以一般使用“非关系型数据”来表示其他类型的数据库
非关系型的模型比如:
列模型:存储的数据是一列一列,关系型数据库以一行作为一个记录,列模型数据库以一列为一个记录
键值对模型:存储的数据是一个个键值对,比如name:lisi
文档类模型:以一个个文档来存储数据,类似于键值对
数据库创建流程
服务器->数据库->表(行列组成的二维表格)->行
lient操作服务器通过命令登录操作:
mysql -u用户名(默认root) -p密码
命令:
SQL语句:每个命令执行结束加分号结束
查询所有数据库:show databases;
切换数据库:use 库命名;
创建数据库:create database [IF NOT EXISTS] 库名;
删除数据库:drop database [IF EXISTS] 库名;
查询数据库创建:show 建库语句;
指定数据库采用的字符集:CHARACTER SET
注意:
不要修改mysql服务器的编码集,表的编码集默认和库一致
建表
格式:
create table [if exists] 表名(
字段1 数据类型 字段属性,
字段2 数据类型 字段属性,
...
字段N 数据类型 字段属性
)engine=引擎 default charset=编码集;
查看当前数据库:select database();

查看建表语句:show create table 表名;

查看表结构:desc 表名;

删除:drop table [if exists] 表名;
OVO不想再添加,懒得
字段属性:
not null:没给值数据为默认值(varchar默认值为空)
AUTO_INCREMENT定义列为自增的属性,一般用于主键,数值会自动加1
PRIMARY KEY关键字用于定义列为主键,您可以使用多列来定义主键,列间以逗号分隔
ENGINE设置存储引擎,CHARSET设置编码
default null:没给值数据就是null
default值:设置字段的默认值
----注意:主键不重复的列
修改表结构:alter table
修改表名:alter table 旧表名 to 新表名;
添加字段:alter table 表名 add 字段 字段数据类型 属性;
修改字段:alter table 表名 change 旧字段 新字段 数据类型 属性;
修改字段:alter table 表名 modify 字段 数据类型 属性;
注意:
change:修改所有(字段名,数据类型,属性)
modify:修改一部分(数据类型,属性)
修改数据类型时,varchar->int原数据会变为0
| 增删改查:字符串全部使用’'包起来 |

insert 增:
格式:
insert into 表名(字段) values(值),(值)...(值);
例如:
insert into stduent(name) values('zs');
insert into stduent(name) values('zs'),('ls');

delete 删
格式:
delete from 表名 where 子句;

update改
格式:
update 表名 set 字段1=值1,字段2=值2...字段N=值N where 子句;

select查
格式:
select 字段 from 表名 where 子句;
注意:
*表示所有字段

| 起别名,子句,分页,去重 |

as 起别名
格式:
字段 as 名称
注意:
as 也加可不加
举例:列别名

举例:表别名

子句:

注意:sql 里 符号<> 与 != 的区别
<> 与!=都是不等于的意思,但是一般都是用<>来代表不等于,因为<>在任何SQL中都起作用,但是!=在sql2000中用到,则是语法错误,不兼容的


limit分页
格式:
语句 limit 开始下标,长度;
注意:
如果数据量不够,显示全部
例如:三条语句①②③
SELECT * FROM student LIMIT 0,10;
SELECT * FROM student LIMIT 2,5;
SELECT * FROM student LIMIT 0,50;
①从位置0开始查找十条数据
②从位置2开始查找五条数据
③从位置0开始查找五十条数据,虽然数据只有十二条(1010被删除了)但是不会报错,输出全部数据



去重
格式:
DISTINCT 字段1,字段2...字段N
注意:
字段不能在DISTINCT之前,只能在DISTINCT后面
DISTINCT之后有多个字段,按照所有字段进行去重
例子
student表数据:
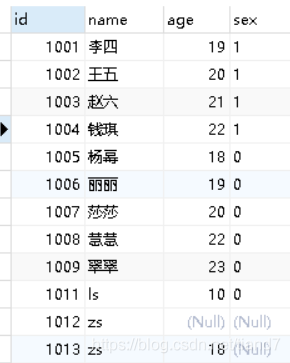
执行如下三条查询语句:
SELECT name,DISTINCT age FROM student;
SELECT DISTINCT name FROM student;
SELECT DISTINCT name,age from student;
第一句:

第二句:重复的zs被只剩一个了

第三句:zs出现了两个,因为姓名和年龄为整体,所以年龄有区别的zs不是重复的
 0
0
| 聚合函数 |

count(字段):求多少行数据
sum(字段):求和
avg(字段):平均数
max(字段):最大值
min(字段):最小值
注意:
varchar能比较大小,不能获取avg(没有任何意义)
如果值为Null不参与计算
sum和avg字段的数据不是数值,结果都是0
例:
student表数据:
count(字段):求多少行数据
SELECT count(*) FROM student;
SELECT count(age) from student;


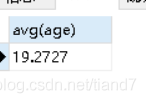
sum(字段):求和
SELECT sum(*) FROM student; /*查询语句一报错,因为名字等参与不了求和*/
SELECT sum(age) from student;
语句一

语句二
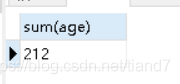
avg(字段):平均数
SELECT avg(age) from student;
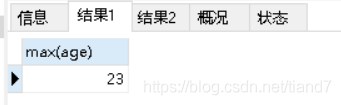
max(字段):最大值
语句①查询年龄最大值
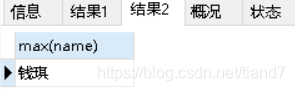
语句②查询名字最大值(结果出来了),说明名字可以比较大小
SELECT max(age) from student;
SELECT max(name) from student;
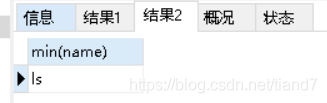
min(字段):最小值
语句①查询年龄最小值
语句②查询名字最小值(结果出来了),说明名字可以比较大小
SELECT min(age) from student;
SELECT min(name) from student;

| 字段运算与拼接 |

字段进行算术运算
格式:
(字段 符号 字段)
例如:
select (name+age) from students;
注意:
字符串参与运算字符串为0参与运算

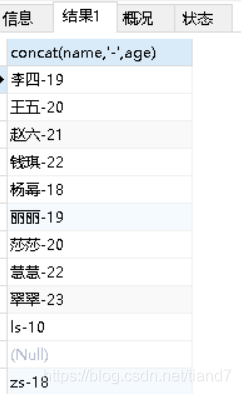
拼接:
格式①:
concat(str1,str2...)
例如:把name和age以-拼接显示
select concat(name,'-',age)from students;
格式②:
concat_WS(separator,str1,str2,...)
例如:把name和age以-拼接显示
SELECT concat_WS('-',name,age) from student;
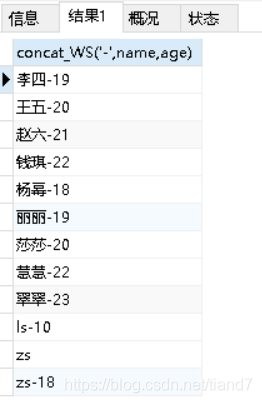
注意:
SELECT concat_WS(id,name,age) from student;
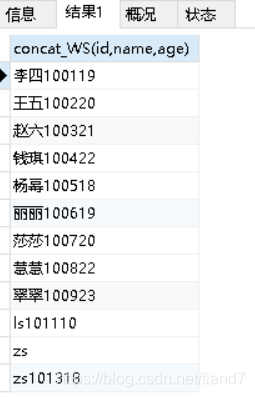
出现如上结果表明这种格式concat_WS(separator,str1,str2,...)固定,第一位始终为分隔符
|
|
|
|
|
| 前面一部分使用的是Linux里MySQL的界面,后面使用的是Navicat Premium远程连接MySQL,因为Navicat Premium的可视化界面确实好用点 |
本人用的Navicat Premium
链接:https://pan.baidu.com/s/1CyFbz1JDlWEooVa5dLL-rg
提取码:q6lg
对应的激活工具(安装好Navicat Premium后先点击激活工具后运行程序)
链接:https://pan.baidu.com/s/1dS6UWM3N0sP6sTjsVRc9aw
提取码:dump
|
|
|
|
|
|
上一章-Linux篇-Day32-shell脚本(2)、时间、定时器、安装MySQL
下一章-MySQL篇-Day34-日期函数、计算、排序分组筛选、连表联查等
|
|
|
| 听说长按大拇指👍会发生神奇的事情呢!好像是下面的画面,听说点过的人🧑一个月内就找到了对象的💑💑💑,并且还中了大奖💴$$$,考试直接拿满分💯,颜值突然就提升了😎,虽然对你好像也不需要,是吧,吴彦祖🤵! |



这篇关于一起重新开始学大数据-MySQL篇-Day33-SQL、建库建表、增删查改、聚合函数等的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





