本文主要是介绍探寻大数据思想的主要贡献者与核心内容,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言:
在当今数字化时代,大数据已成为企业和科学研究的关键要素。其背后的思想和概念不仅引领了数据处理和分析的革新,也推动了人类对于信息时代的理解与认知。
大数据思想的起源:
在信息爆炸的时代背景下,大数据思想应运而生。我们将追溯大数据思想的起源,探讨信息技术的发展如何催生了对于大数据处理的需求,以及这一需求如何引发了大数据思想的诞生。
主要贡献者介绍:
Douglas Laney
Douglas Laney是一位资深的信息技术和数据管理专家,以其在数据管理和大数据领域的研究和贡献而闻名。他最著名的贡献之一是提出了“3V模型”来描述大数据的特征,这成为了大数据领域的经典概念。
他在2001年首次提出了“3V模型”,将大数据的特征概括为三个方面:Volume(数据量)、Velocity(数据速度)和Variety(数据多样性)。这个模型帮助人们理解了大数据的特点,即大数据不仅仅是数据量的增加,还包括了数据产生的速度快以及数据的多样性。
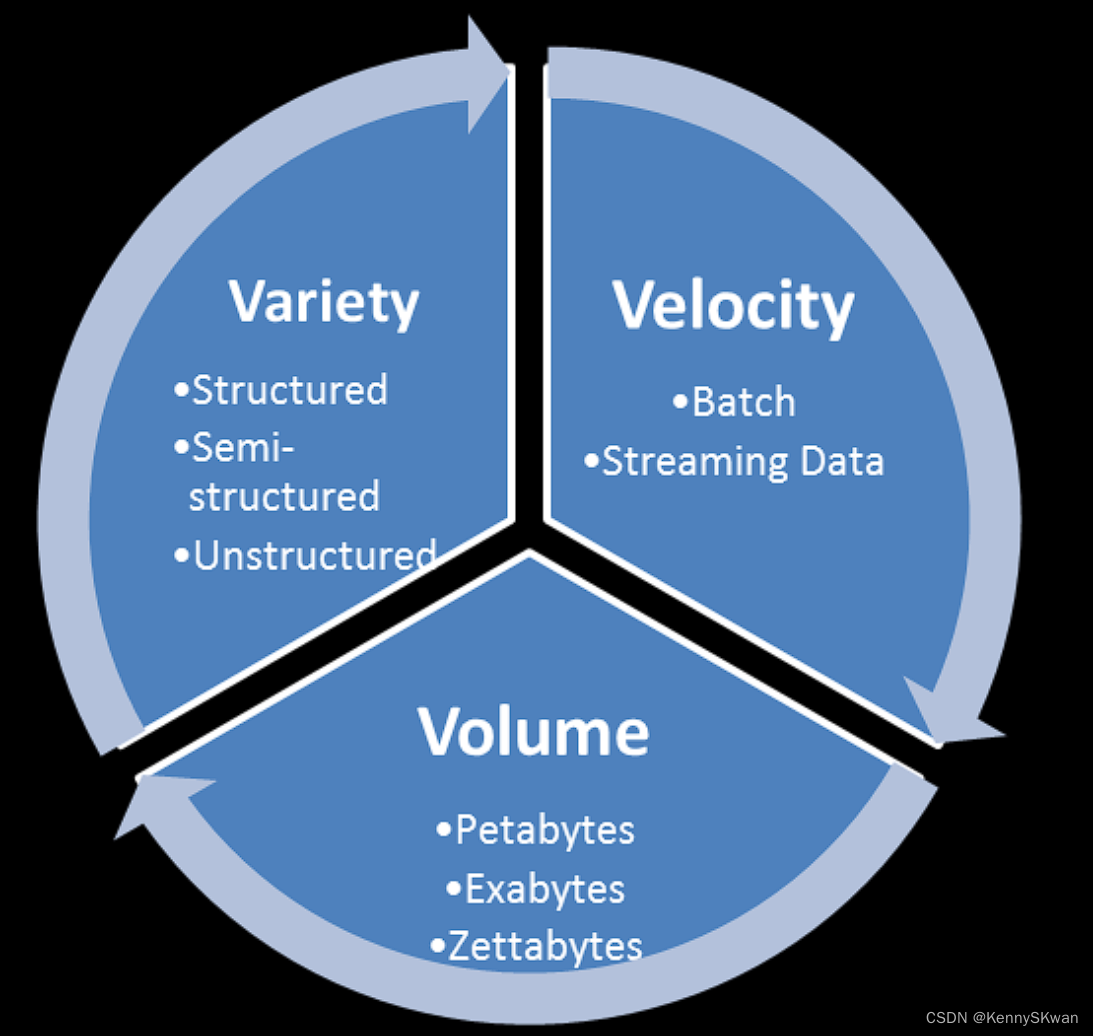
- Volume(数据量):指的是数据的规模之大。在传统数据处理中,数据量通常是有限的,而在大数据时代,数据量已经呈现出指数级增长的趋势。大数据处理需要能够有效地处理海量的数据,这就需要强大的存储和计算能力。
- Velocity(数据速度):指的是数据产生、传输和处理的速度之快。随着互联网和物联网技术的普及,数据的产生速度呈现出爆炸性增长的趋势,数据在网络中的传输速度也越来越快。大数据处理需要能够实时地获取、传输和处理数据,以满足实时性要求。
- Variety(数据多样性):指的是数据的多样性和多种来源。传统数据处理主要是结构化数据,如数据库中的表格数据,而在大数据时代,数据的类型非常多样化,包括文本、图像、音频、视频等各种非结构化数据,以及来自不同来源和格式的数据。大数据处理需要能够处理和分析各种类型和格式的数据。
Jeff Hammerbacher
Jeff Hammerbacher曾在Facebook担任数据团队的负责人,是早期负责构建Facebook数据基础设施的关键人物之一。他在Facebook期间,致力于建立数据分析和数据科学团队,并领导了众多数据相关项目,为Facebook的成功发展和用户增长提供了关键的数据支持。
在离开Facebook之后,Jeff Hammerbacher创立了Cloudera公司,这是一家专注于提供大数据解决方案和服务的公司。Cloudera致力于帮助企业利用和管理大规模数据,通过提供Hadoop和其他大数据技术的商业化支持和解决方案,推动了大数据技术的发展和应用。
在大数据领域有着重要的贡献,主要体现在以下几个方面:
-
数据驱动文化的推动:作为Facebook早期的数据团队负责人之一,Jeff Hammerbacher致力于建立和推动数据驱动的文化。他意识到数据对于企业决策和产品优化的重要性,并致力于将数据分析和数据科学应用于业务中。他在Facebook的工作为数据驱动型公司的发展提供了重要经验和案例。
-
构建数据基础设施:在Facebook任职期间,Jeff Hammerbacher是构建Facebook数据基础设施的关键人物之一。他领导团队开发了包括Hive等数据处理工具,帮助Facebook有效地处理和分析海量数据。他的工作使得Facebook能够应对日益增长的用户数据,为公司的快速发展提供了关键支持。
-
Cloudera的创立:作为Cloudera公司的创始人之一,Jeff Hammerbacher致力于推动大数据技术的商业化和推广。Cloudera是一家提供大数据解决方案和服务的公司,致力于帮助企业利用和管理大规模数据。他的工作使得大数据技术更加普及和商业化,为企业应对大数据挑战提供了解决方案。
Doug Cutting

Doug Cutting通过创建Hadoop项目、推动分布式计算与存储技术的发展以及参与开源社区的活动,为大数据技术的发展和应用做出了重要贡献。
在大数据领域有着重要的贡献,主要体现在以下几个方面:
-
Hadoop项目:Doug Cutting是Apache Hadoop项目的共同创始人之一。在2004年,他与Mike Cafarella一起创建了Hadoop项目,最初是为了支持Nutch搜索引擎项目的数据处理需求而设计的。Hadoop是一个开源的分布式数据处理框架,它能够可靠地存储和处理大规模数据集,成为了大数据处理的核心技术之一。
-
分布式计算领域:在分布式计算领域有着丰富的经验和深入的见解。他的工作重点包括分布式文件系统、分布式计算模型和大规模数据处理等方面。通过他的努力,分布式计算技术得以快速发展,并为大数据时代的到来奠定了重要基础。
-
开源社区的活跃参与:是开源社区的积极推动者和贡献者。除了Hadoop项目之外,他还参与了许多其他开源项目,如Lucene、Nutch等。他通过开源社区的合作和贡献,推动了大数据技术的开放和共享,促进了技术的进步和创新。
Michael Stonebraker
Michael Stonebraker是数据库领域的杰出人物,他通过在关系数据库系统、新型数据库技术和ACID事务处理等方面的研究和创新,为数据库技术的发展和大数据时代的数据管理提供了重要贡献。
在大数据领域有着重要的贡献,主要体现在以下几个方面:
-
关系数据库系统的先驱:他在该领域的研究和开发工作为现代数据库技术的发展奠定了基础。他是Ingres和Postgres等早期关系数据库系统的设计者之一,在关系数据库系统的设计和实现方面做出了重要贡献。
-
新型数据库技术的倡导者:他提出了许多创新的数据库理念和技术,如对象关系数据库、并行数据库、列式数据库、流式处理数据库等。他的工作推动了数据库技术的不断进步和创新,为大数据时代的数据管理提供了新的思路和解决方案。
-
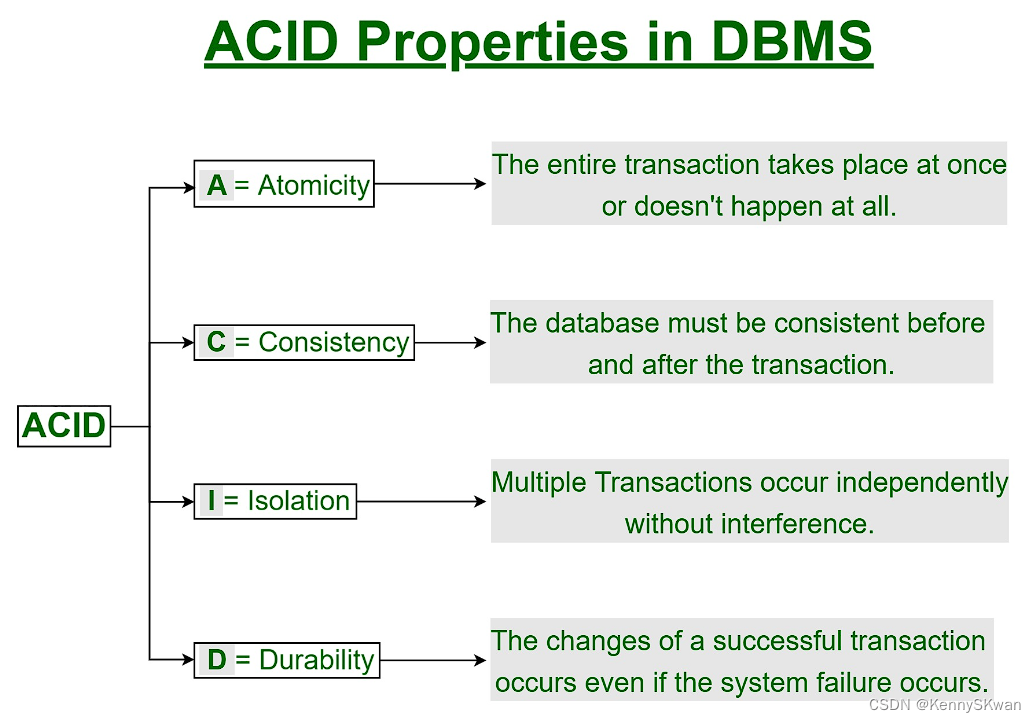
ACID事务处理的提倡者:提出了ACID(原子性、一致性、隔离性、持久性)事务处理的概念,这是关系数据库系统中确保数据一致性和可靠性的重要原则之一。他的工作对于数据库系统的设计和实现具有重要指导意义,为数据管理和处理提供了可靠的基础。
-
数据库创业者:除了在学术界的工作外,Michael Stonebraker还是一位成功的企业家,他创立了多家数据库公司,如Ingres Corporation、StreamBase Systems等。他通过创业活动将自己的研究成果转化为商业产品,推动了数据库技术在商业应用中的应用和发展。
Jeff Dean 和 Sanjay Ghemawat
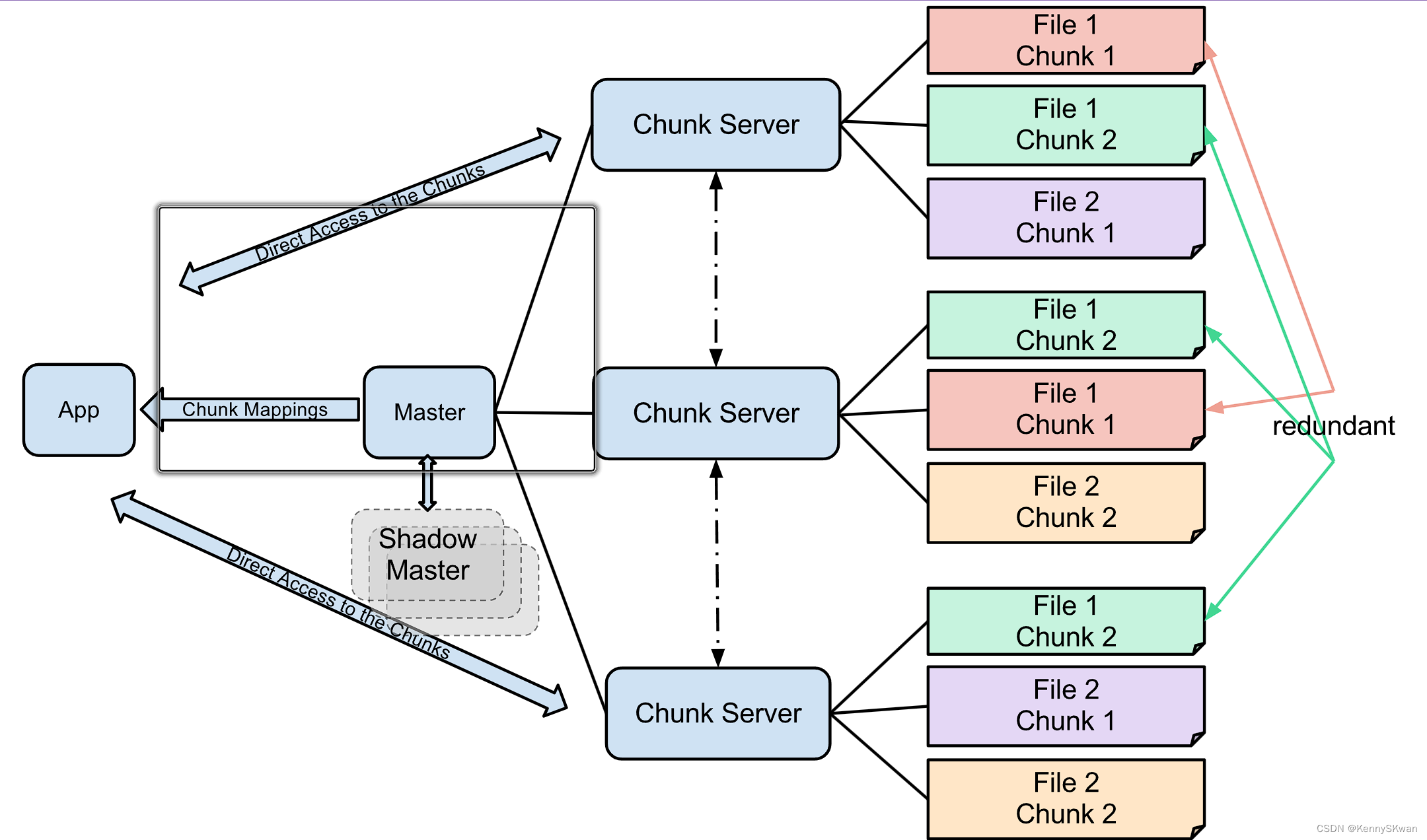
Google File System
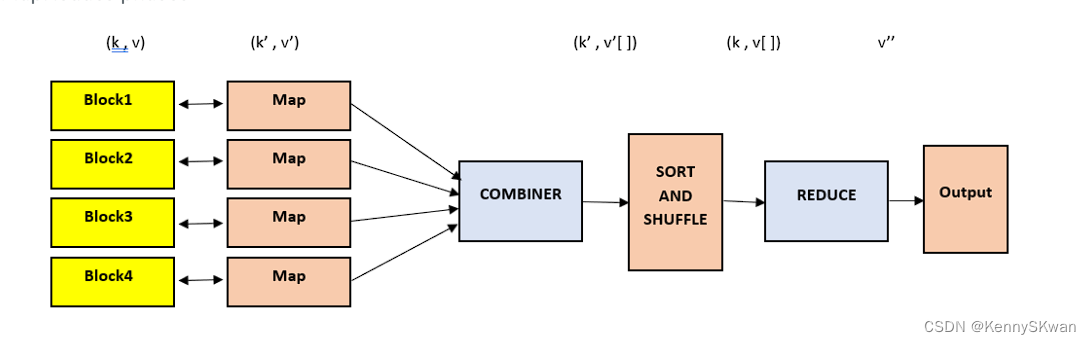
MapReduce编程模型
Jeff Dean和Sanjay Ghemawat是谷歌公司的两位资深工程师,他们在2004年发表了一篇名为《MapReduce: Simplified Data Processing on Large Clusters》的论文,提出了MapReduce编程模型和Google File System(GFS)分布式文件系统,这两个技术成为了谷歌处理大规模数据的核心基础。
Jeff Dean在谷歌担任了多个重要职务,他是谷歌的资深软件工程师和谷歌大脑(Google Brain)项目的领导者之一。他在分布式系统、大规模数据处理、机器学习和人工智能等领域有着丰富的经验和深厚的造诣。在谷歌,他参与了许多重要项目的设计和开发,如MapReduce、Bigtable、Spanner等,这些项目对于谷歌处理大规模数据和提供互联网服务起到了关键作用。
Sanjay Ghemawat也是谷歌公司的资深工程师,他和Jeff Dean共同发表的《MapReduce: Simplified Data Processing on Large Clusters》论文成为了大数据领域的重要里程碑之一。在谷歌,他主要负责设计和优化分布式系统和大规模数据处理系统。他在谷歌的工作重点包括构建高效的分布式文件系统和数据处理框架,为谷歌的产品和服务提供可靠的基础设施支持。
这篇关于探寻大数据思想的主要贡献者与核心内容的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








